这篇文章讲述了SQL中的子函数,如有错误或者不妥之处,还请各位大佬批评指正。
什么是子查询?
把一个查询的结果在另一个查询中使用就叫做子查询
初始数据
有五个表:学生表,老师表,课程表,学院表,课程成绩表。
表结构
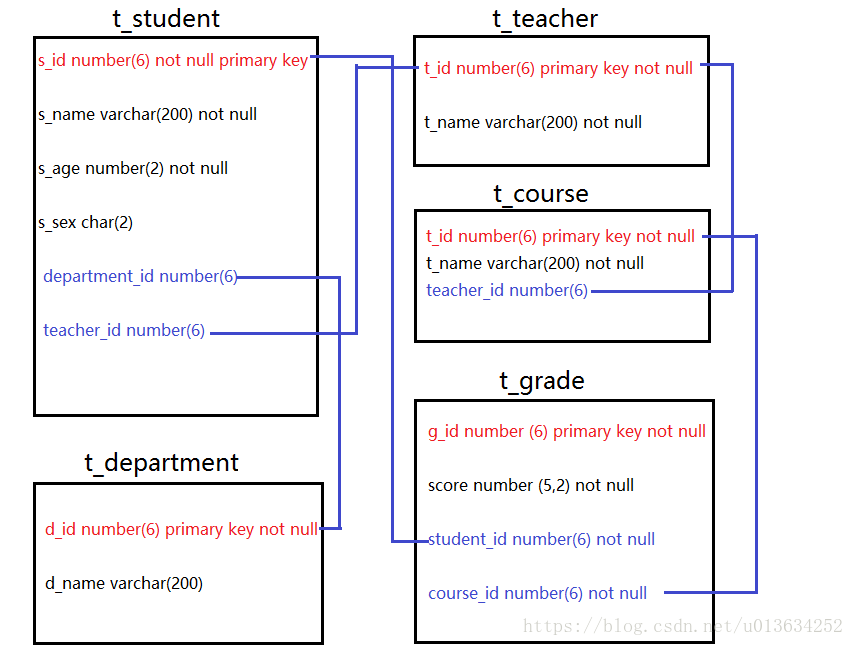
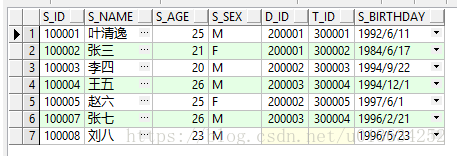
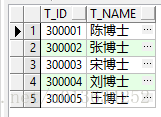
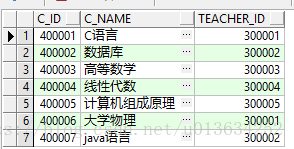
初始数据
- 学生表
- 老师表
- 课程表
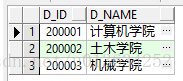
- 学院表
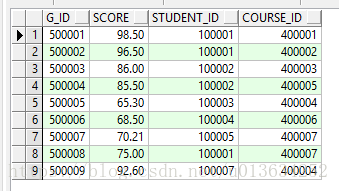
- 课程成绩表
单行子查询
返回的结果集为单个的子查询,叫做单行子查询。单行比较符有 >、>=、<、<=、!=。
- 查询平均成绩比‘王五’大的学生id,姓名,平均成绩
select s.s_id , s.s_name , avg(score)
from t_student s join t_grade g on s.s_id = g.s_id
group by s.s_id , s.s_name
having avg(score) > (select avg(score)
from t_student s join t_grade g on s.s_id = g.s_id
where s.s_name = '王五'
group by s.s_id) 查询结果:

注:子查询中可以嵌套函数,多行子查询不能使用单行比较符。
多行子查询
返回的结果集为多个的子查询,为多行子查询,多行子比较符有 IN(等于列中任意一个)、ANY(和子查询返回的某个值比较),ALL(和子查询返回的所有值比较)。
- 查询其他课程中比课程id为‘400004’课程的任一分数低的学生的学号、姓名、课程号、课程名、分数(ANY)
select s.s_id , s_name , c.c_id , c_name , score
from t_grade g join t_student s on g.s_id = s.s_id
join t_course c on g.c_id = c.c_id
having c.c_id != 400004 and avg (score) < any (
select avg(score)
from t_grade
where c_id = 400004
group by (c_id)
)
group by c.c_id , s.s_id , s.s_name , c_name ,score查询结果:

- 查询其他课程中比课程id为‘400004’课程的所有分数高的学生的学号、姓名、课程号、课程名、分数(ALL)
select s.s_id , s_name , c.c_id , c_name , score
from t_grade g join t_student s on g.s_id = s.s_id
join t_course c on g.c_id = c.c_id
having c.c_id != 400004 and score > all (
select score
from t_grade
where c_id = 400004
)
group by c.c_id , s.s_id , s.s_name , c_name ,score查询结果:

总结:ANY相当于和结果集中的任一一个作比较、若满足则返回,ALL相当于和结果集中的所有结果作比较,若满足则返回。