Linux进程概念
前文我们了解了,进程的基本概念,在课本上被描述为,正在执行的程序,在linux内核上,认为进程是担当分配系统资源(CPU时间,内存)的实体。
进程=内核描述数据结构(PCB)+代码和数据
在Linux中,PCB为task_struct,它会被装载到RAM(内存)里并且包含着进程的信息。
本文我们主要是了解进程的部分概念。
查看进程
查看进程的方式有很多种,前文我们介绍了在/proc 系统文件中查看,在该文件目录下,进程就是一个又有一个数字目录。
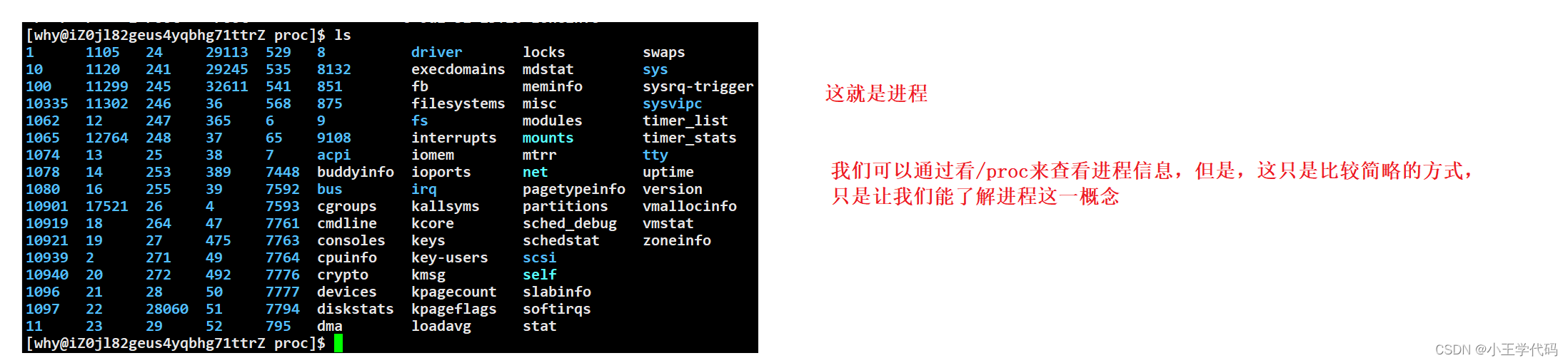
ps的使用
语法:ps ajx 可以查看当前所有进程
ps ajx | grep 程序/文件名 来查看程序/文件的进程信息
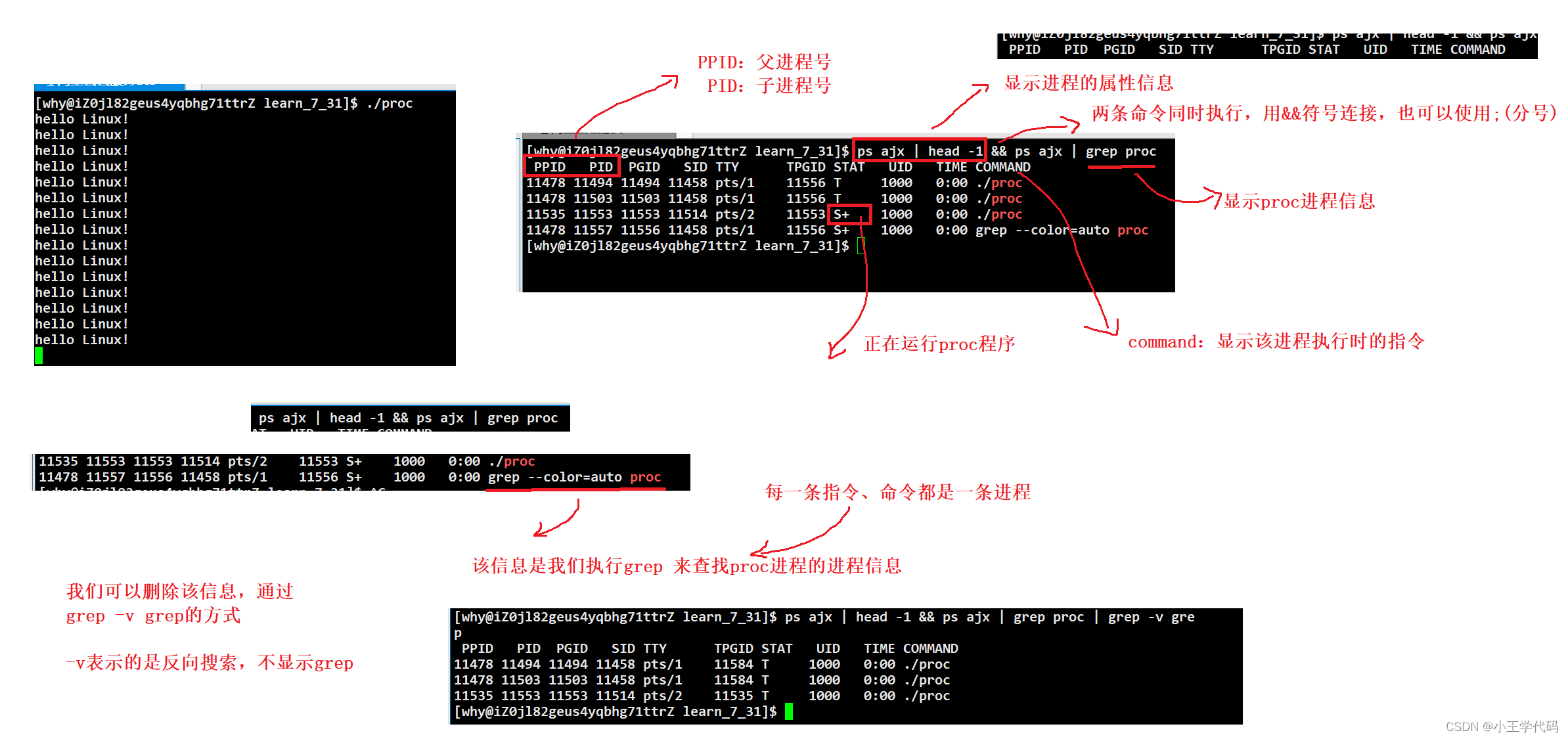
解释:
ps ajx | grep proc 可以在所有进程信息中,查找到proc的进程信息
ps ajx | head -1 表示将进程的属性的描述信息显示
ps ajx | head -1 && ps ajx | grep proc 显示进程proc的相关信息,并带上进程属性的描述
ps ajx | head -1 && ps ajx | grep proc | grep -v grep 不显示grep的进程信息
&&可以用分号代替,使得两条指令能一起执行,将执行的结果一并展示出来。
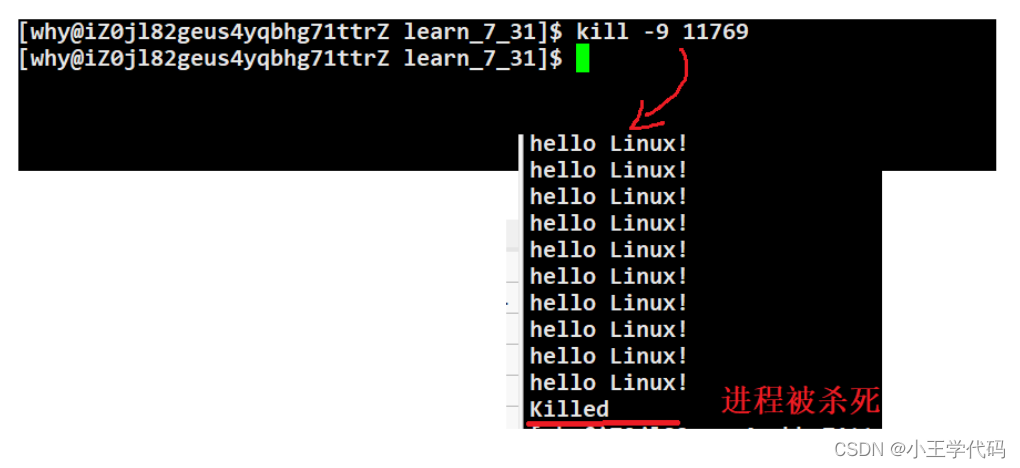
杀死进程
语法:kill -9 PID
向执行的PID进程发送9号信号,正在运行的PID进程显示killed,被杀死
进程标识符
PID:进程ID
PPID:父进程ID
获取标识符的方式:getpid()、getppid()
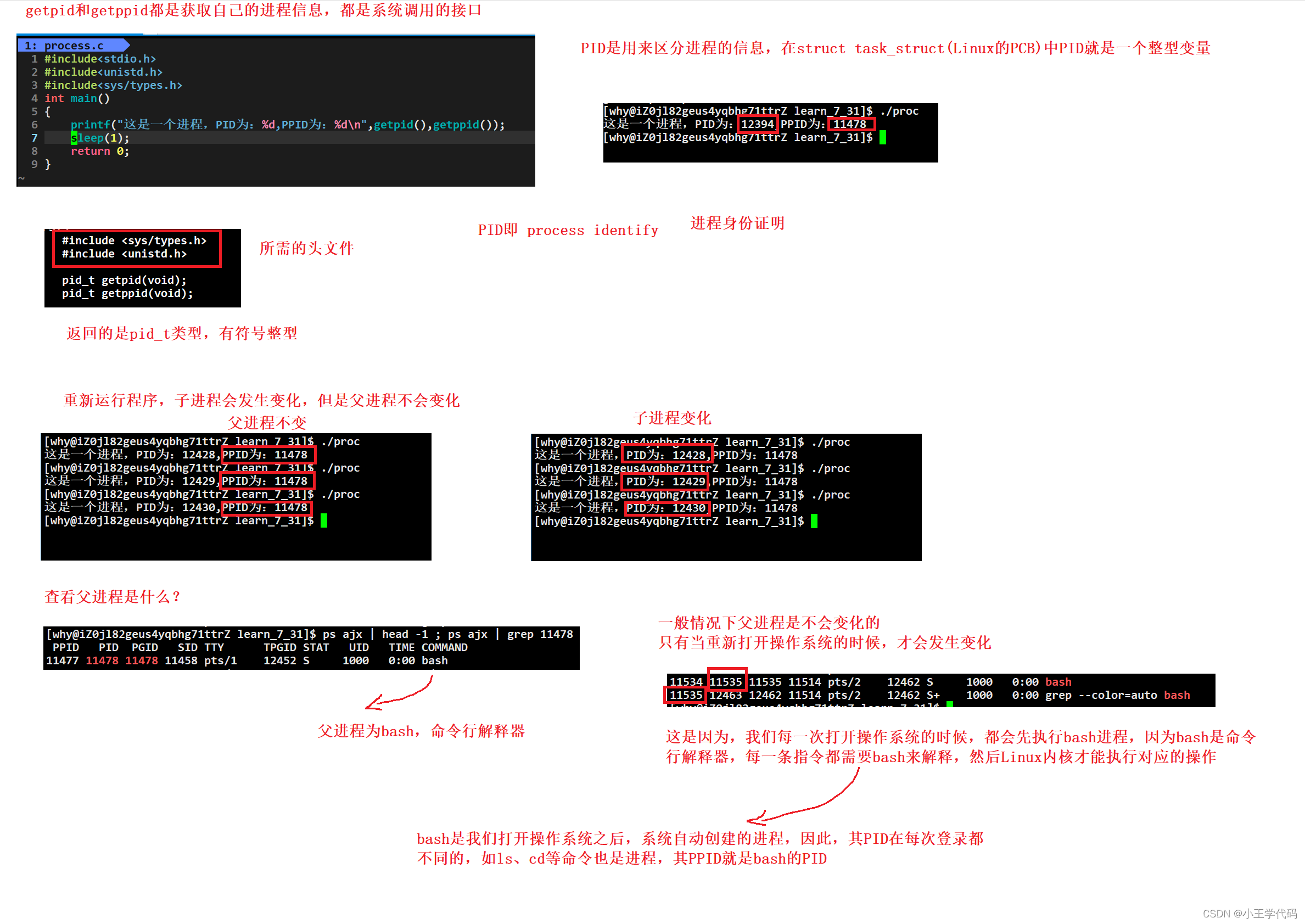
注意:getpid()和getppid()都是系统调用函数,来通过该函数来访问操作系统,得到自己的进程信息,重新运行程序子进程的PID会发生变化,但是父进程ID不会发生变化。
bash是所有程序的父进程,将其他程序作为其的子进程,子只有一个父,但是父可有多个子
手动创建进程的方式
我们知道两种创建进程的方式,第一种就是./proc执行程序,以此来创建进程,第二种,使用fork函数来创建进程。
创建进程的方式,有以下两种
- ./运行程序 指令级别
- fork函数 代码级别
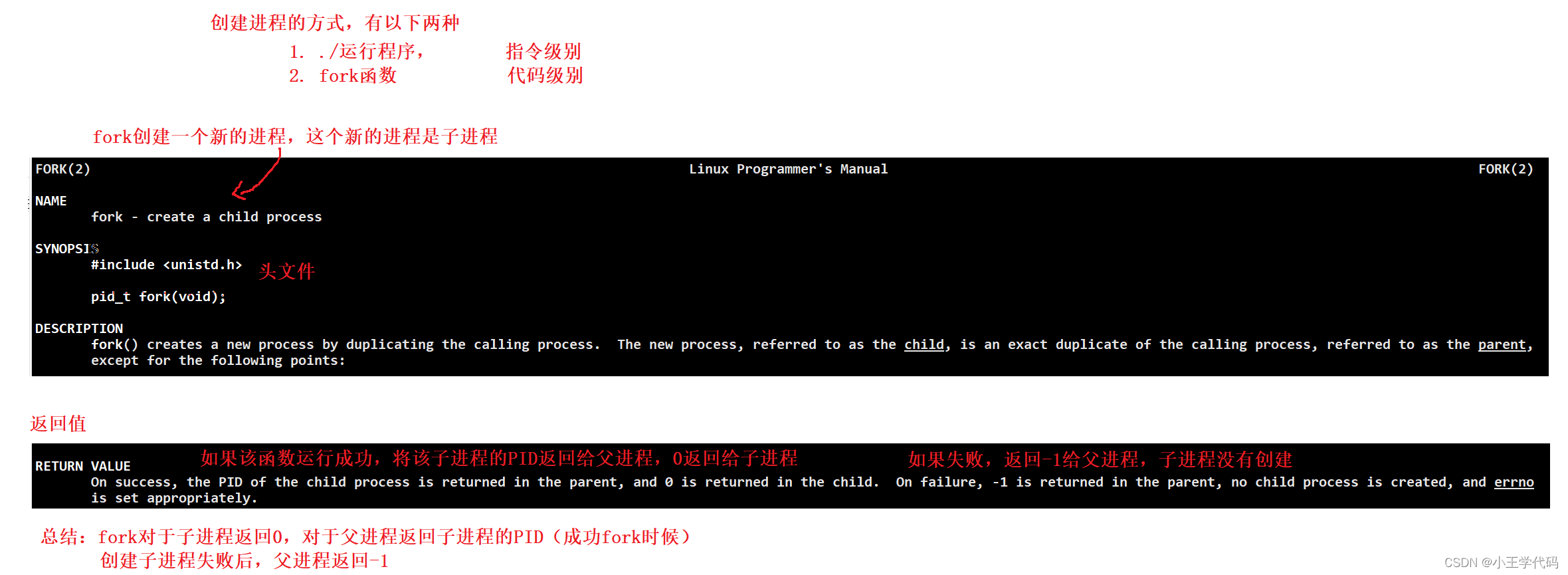
fork函数创建进程
fork函数用来创建子进程。
两种结果
- 成功创建子进程,子进程返回0,父进程返回的是子进程的PID
- 创建失败,父进程返回-1
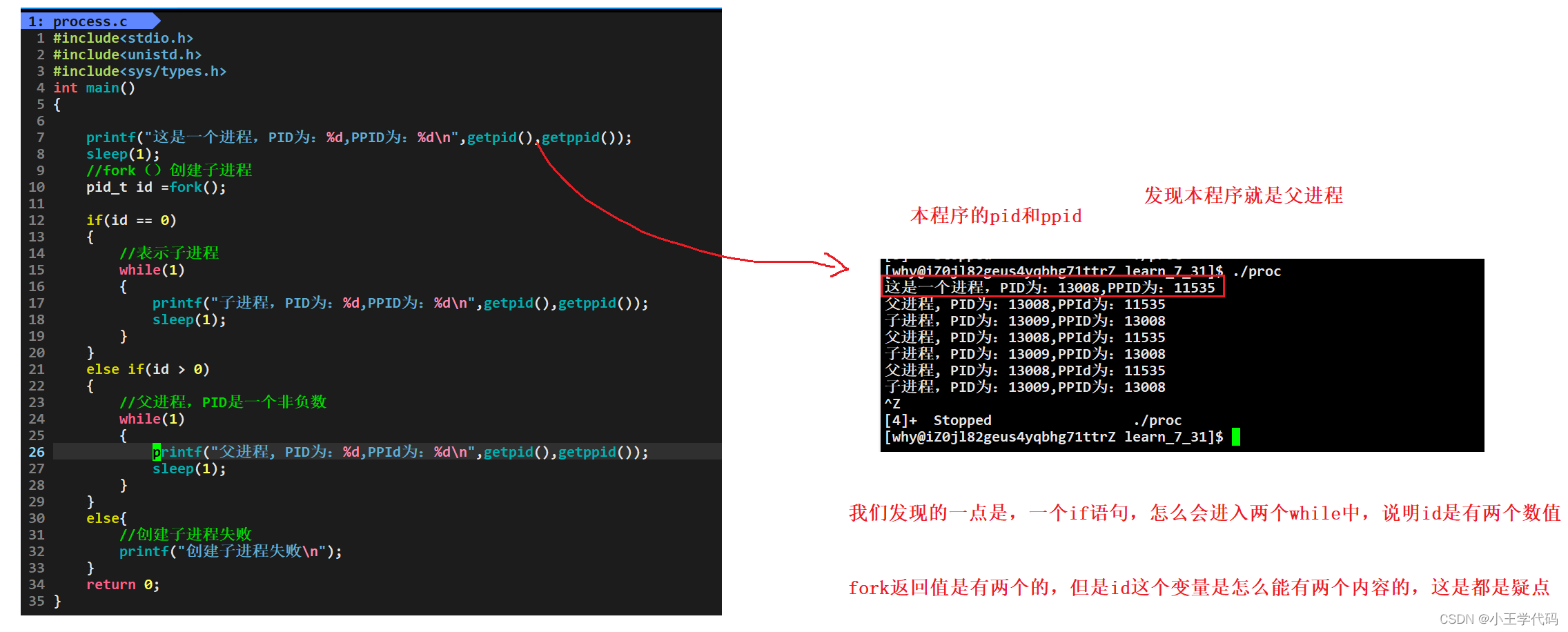
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
int main()
{
printf("这是一个进程,PID为:%d,PPID为:%d\n",getpid(),getppid());
sleep(1);
//fork()创建子进程
pid_t id =fork();
if(id == 0)
{
//表示子进程
while(1)
{
printf("子进程,PID为:%d,PPID为:%d\n",getpid(),getppid());
sleep(1);
}
}
else if(id > 0)
{
//父进程,PID是一个非负数
while(1)
{
printf("父进程, PID为:%d,PPId为:%d\n",getpid(),getppid());
sleep(1);
}
}
else{
//创建子进程失败
printf("创建子进程失败\n");
}
return 0;
}
问题:
- 为什么fork要给子进程返回0,给父进程返回子进程的PID?
- 一个函数是如何做到返回两次的?如何理解?
- 一个变量怎么会有不同的内容?如何理解?
- fork函数到底在干什么?干了什么?
- 进程调用的顺序
- bash是如何创建的,以及与fork的关系
为什么fork要给子进程返回0,给父进程返回子进程的PID?
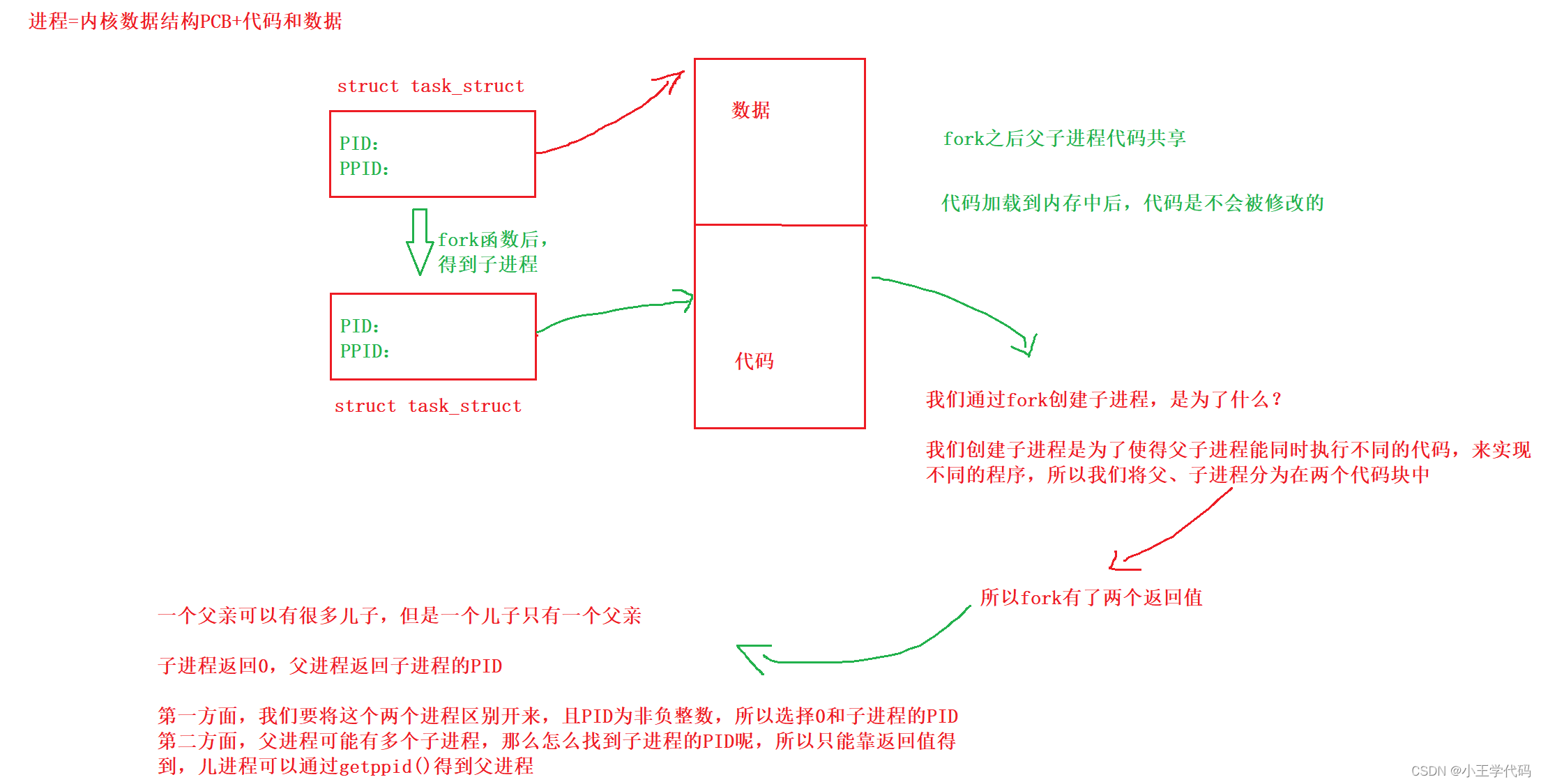
总结:返回不同的返回值,是为了区分父子进程,使得执行不同的代码块
一个函数是如何做到返回两次的?如何理解?
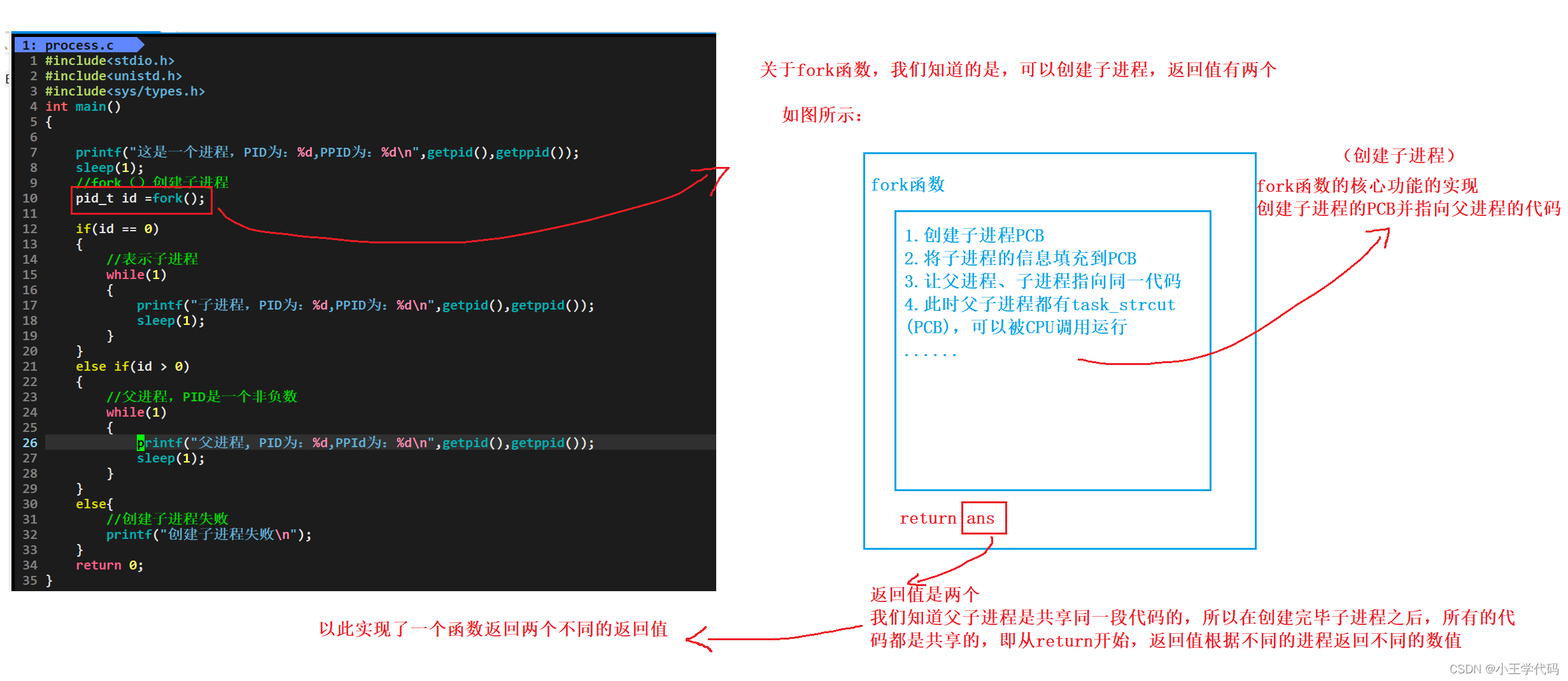
两个返回值的实现依赖于,在创建子进程之后,父子进程共享代码
一个变量怎么会有不同的内容?如何理解?
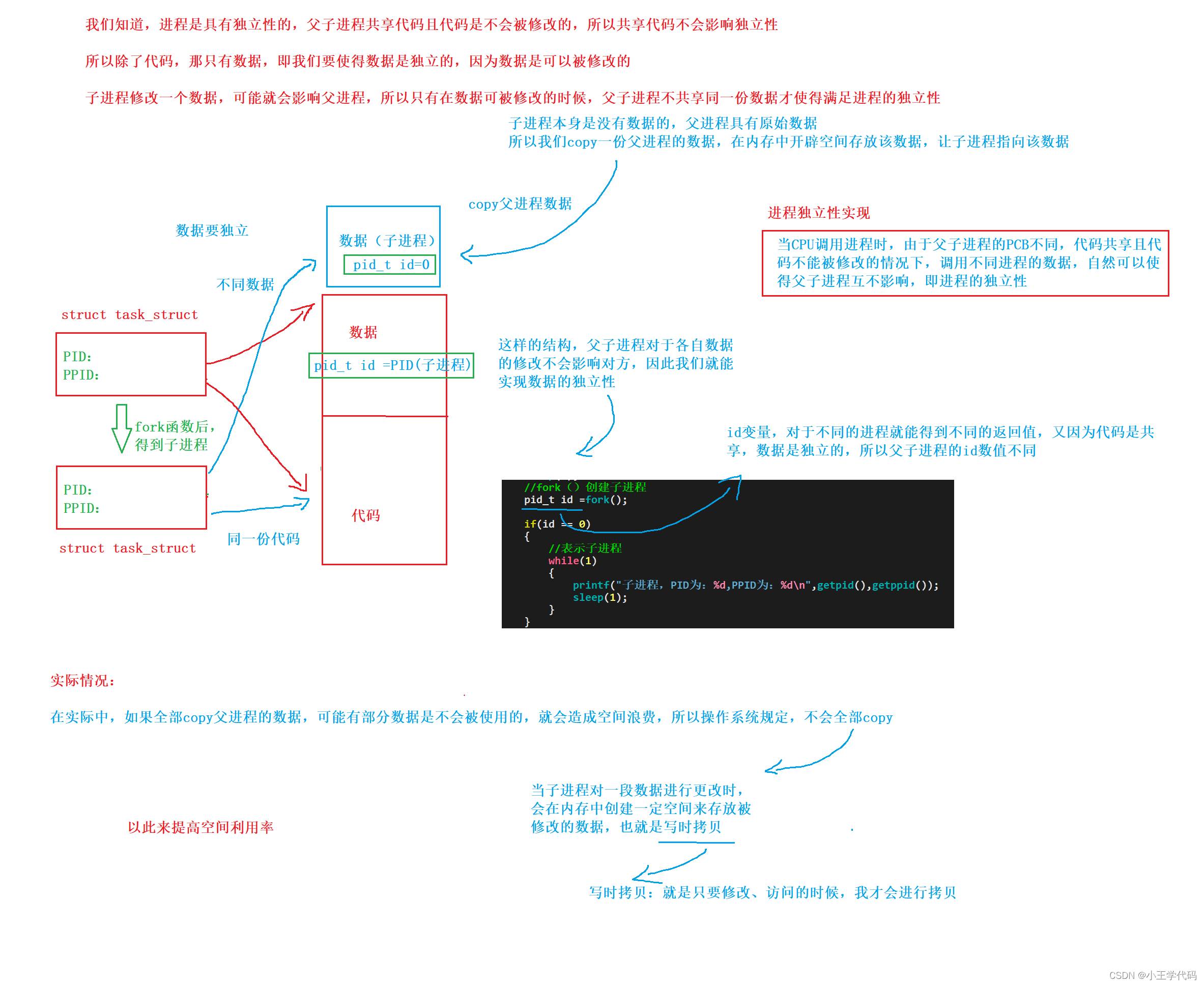
在任何平台,进程在运行的时候,都是具有独立性的,子进程是和父进程开始指向同一数据的,但是如果子进程修改某一数据,就会发生写时拷贝,指向开辟的空间。
fork函数到底在干什么?干了什么?
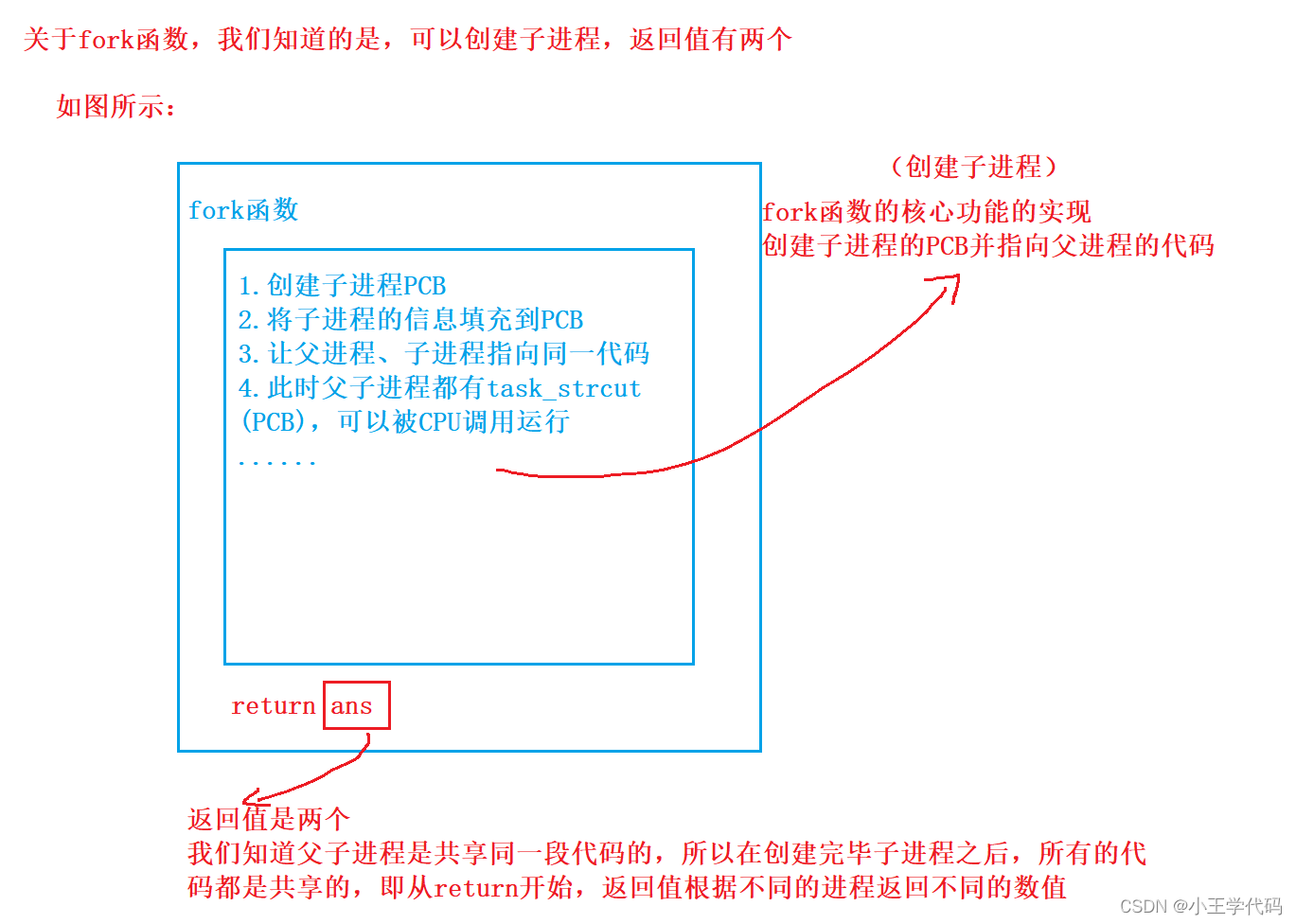
fork函数就是创建子进程,然后根据进程的不同返回不同的数据。
进程调用的顺序
调度器:是一种执行选取进程的算法,决定选取哪一个进程放在CPU上执行。
父子进程创建完毕之后,谁先运行是由调度器来决定的,所以不知道谁先被执行
bash是如何创建的,以及与fork的关系

进程状态
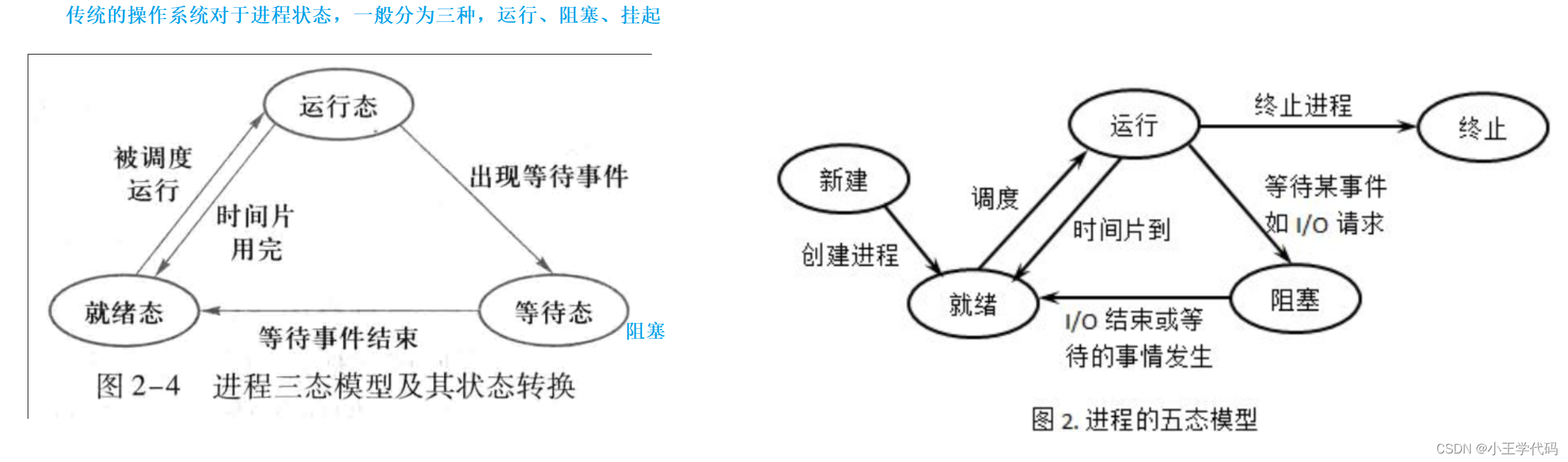
运行态
运行态,顾名思义,该进程现在是可以被执行的,已经准备好被调用了。
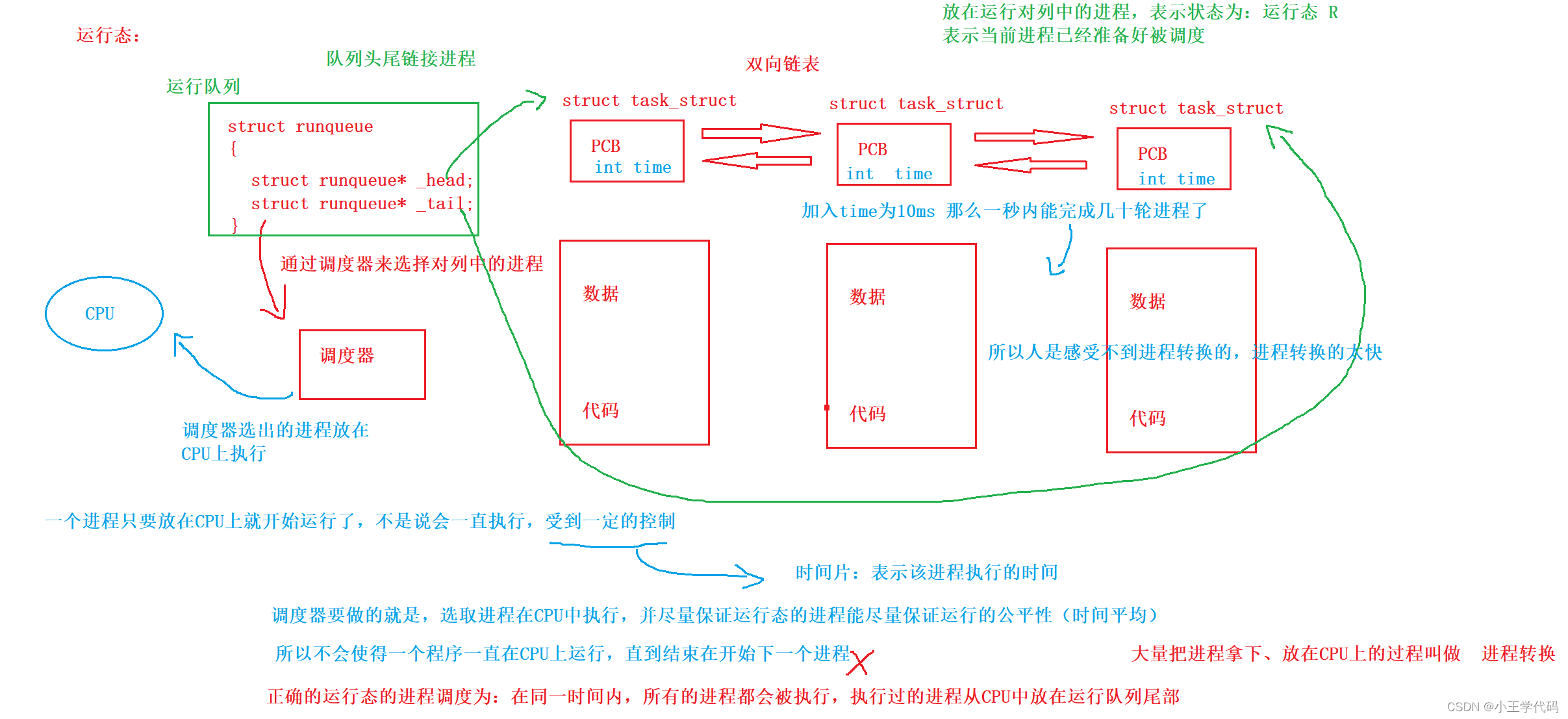
注意:一个进程是否是运行态,看这个进程是否被放在运行队列(runqueue中),一个CPU只有一个运行队列(runqueue)
阻塞态和挂起
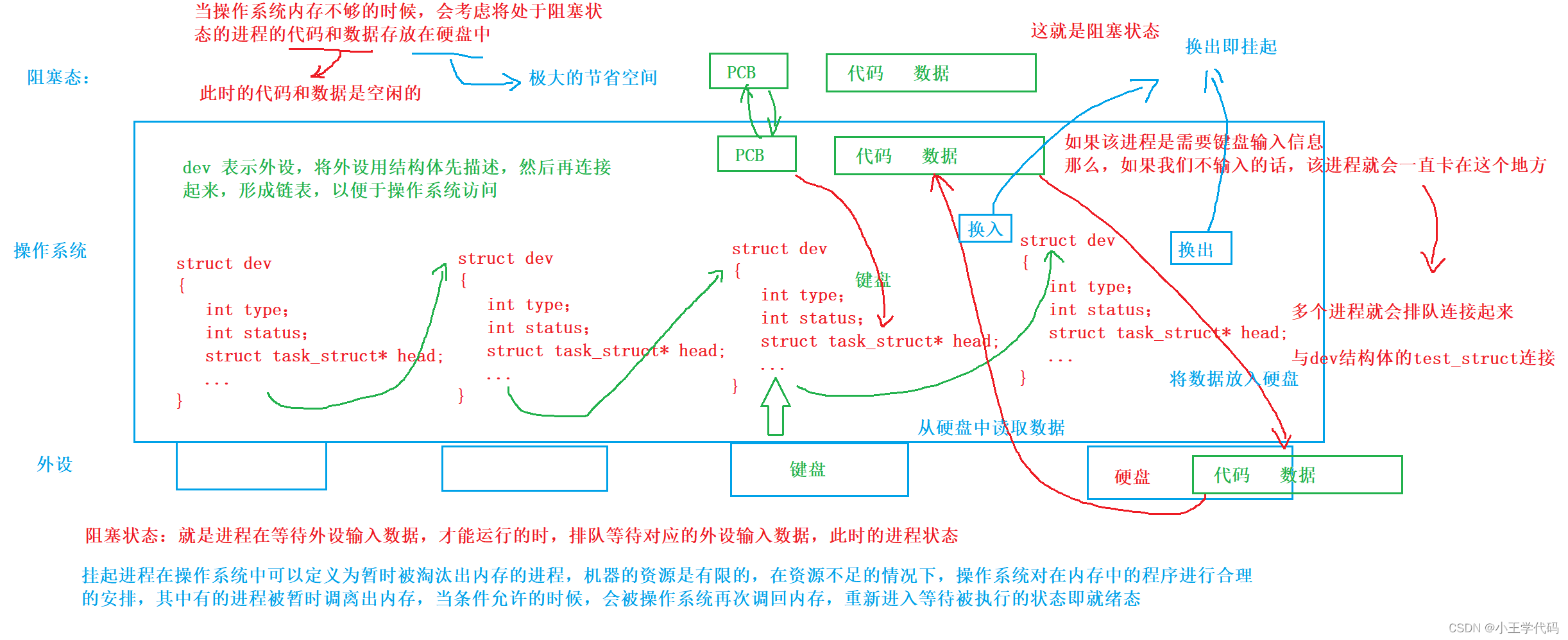
阻塞态,就是等待I/O完成的进程,需要I/O的进程去找对应的外设,连接外设的struct task_struct* head,形成链表,然后在等待输入数据的过程,这就是阻塞
挂起,就是由于操作系统空间不足时,我们将阻塞态的进程的空闲的代码和数据,换出(从内存放在硬盘中),这就叫做挂起。一般的挂起指的是阻塞挂起,运行挂起一般不出现。
换出是暂时调离内存,放在硬盘中,换入是被操作系统调入内存中,重新等待被执行。