本人能力有限,难免有叙述错误或者不详细之处!希望读者在阅读时可以反馈一下错误以及不够好的地方!感激不尽!
目录
长度不受限制的字符串函数: strcpy,strcat,strcmp
长度受限制的字符串函数介绍:strncpy ,strncat, strncmp
内存操作函数memcpy, memmove,memset, memcmp
在C语言中,难免与字符串打交道,但本身C语言是没有字符串类型的,所以为了更好的去应用字符串,了解C语言中的字符串函数可以跟好的帮助解决一些问题。
求字符串长度:
strlen
size_t strlen ( const char * str ); 字符串已经 '\0' 作为结束标志,strlen函数返回的是在字符串中 '\0' 前面出现的字符个数(不包
含 '\0' )。
参数指向的字符串必须要以 '\0' 结束。
注意函数的返回值为size_t,是无符号的( 易错 )
那么这个size-t又是何方神圣?
我们转到其内部的定义,可以发现如下:
![]()
所以,size_t其实就是重新定义以后的无符号整型
使用代码如下,包含了一个错误示范,即当字符串内部没有“\0”时stlen会返回随机值的问题。
int main()
{
char arr[] = "abcdef"; //实际内存中的存储:abcdef\0
char arr1[] = { 'W', 'T', 'F' };
//[][][][][][W][T][F][][][][][][][]
int len = strlen(arr1);//随机值
printf("%d\n", len);
return 0;
}
请注意!由于strlen返回的时一个无符号整型,那么当我们想用srtlen来帮我们计算两个字符串长度之差的时候,如果返回值是一个负数,那么就会产生错误的数值,还请使用的时候牢记且注意。
长度不受限制的字符串函数:
strcpy
char* strcpy(char * destination, const char * source );strcpy函数的作用是将一个字符串的内容直接拷贝到目标字符串的空间里

使用代码如下
int main ()
{
char name[20]={0};
strcpy (name,"Helen");
return 0;
}请注意,拷贝过去的内容是在“\0”之前的,也就是如果在“Helen”中添加一个“\0”,变成“Hel\0en”那么只有前面的Hel会被拷贝过去。
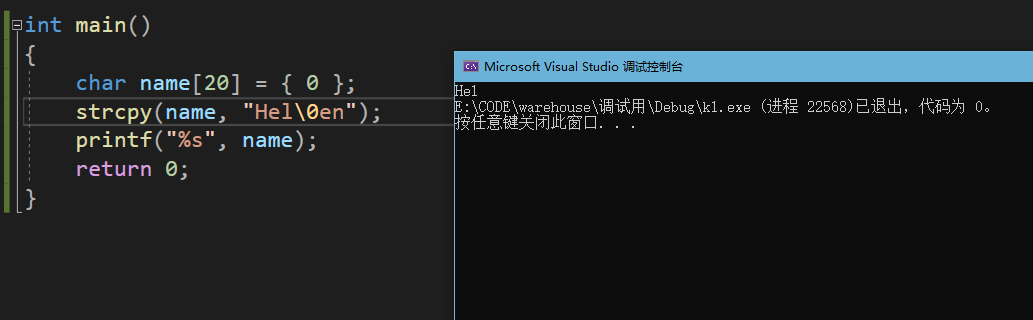
相应的,如果拷贝过去的内容没有“\0”,那么拷过去的字符就会发生问题,strcpy无法得知在哪停下,会发生错误。所以使用strcpy的时候需要满足以下条件。
源字符串必须以 '\0' 结束。
会将源字符串中的 '\0' 拷贝到目标空间。
目标空间必须足够大,以确保能存放源字符串。
目标空间必须可变
strcat
char * strcat ( char * destination, const char * source );将一个字符串的内容追加到目标字符串后面。
使用代码如下:
int main()
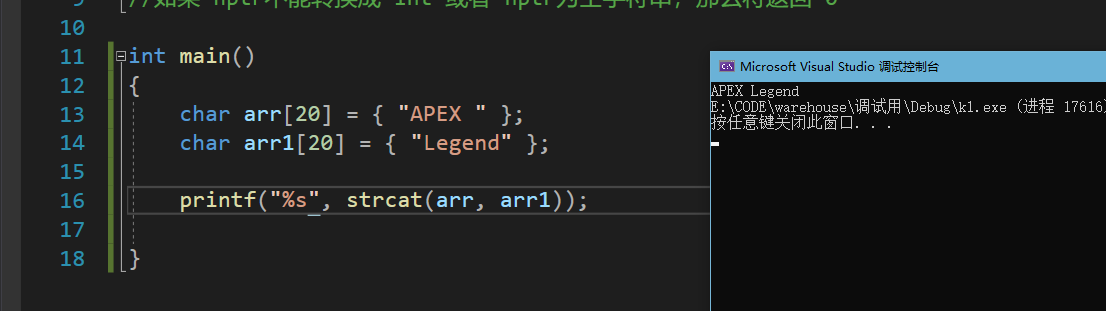
{
char arr[20] = { "APEX " };
char arr1[20] = { "Legend" };
printf("%d", strcmp(arr, arr1));
return 0;
}
strcpy函数返回的是目标空间的起始地址
strcpy函数的返回类型的设置是为了实现链式访问。
源字符串必须以 '\0' 结束。 从\0位置开始追加
目标空间必须有足够的大,能容纳下源字符串的内容。
目标空间必须可修改。
strcmp
int strcmp ( const char * str1, const char * str2 );将两个字符串进行比较,返回一个整型值
第一个字符串大于第二个字符串,则返回大于0的数字
第一个字符串等于第二个字符串,则返回0
第一个字符串小于第二个字符串,则返回小于0的数字
长度受限制的字符串函数介绍:
前文中提到过的strcpy将字符串进行拷贝,但是其实它有一些危险性,当被拷贝的字符串长度大于了目标空间的大小的时候,strcpy不管三七二十一直接回给它塞进去,塞不进去也嗯塞,这就会导致一些问题,所以C语言自带了一种更安全可控的字符串函数,和前文介绍的都大同小异,但是借由这些库函数可以指定每次拷贝或者移动的字符串的大小。
strncpy
char * strncpy ( char * destination, const char * source, size_t num );拷贝num个字符从源字符串到目标空间。
如果源字符串的长度小于num,则拷贝完源字符串之后,在目标的后边追加0,直到num个。
使用方法及使用效果如下:
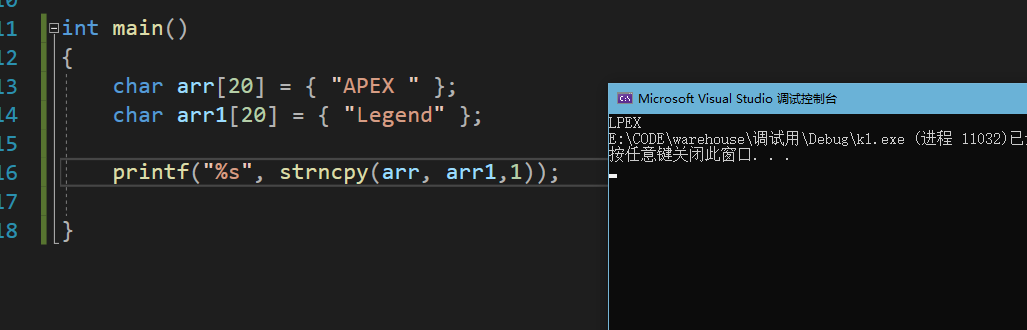
int main()
{
char arr[20] = { "APEX " };
char arr1[20] = { "Legend" };
printf("%s", strncpy(arr, arr1,1));//拷贝一个字节
}
当拷贝的字符串大小没法满足设定的长度时,函数会在拷贝完之后在后面补0,效果如下: 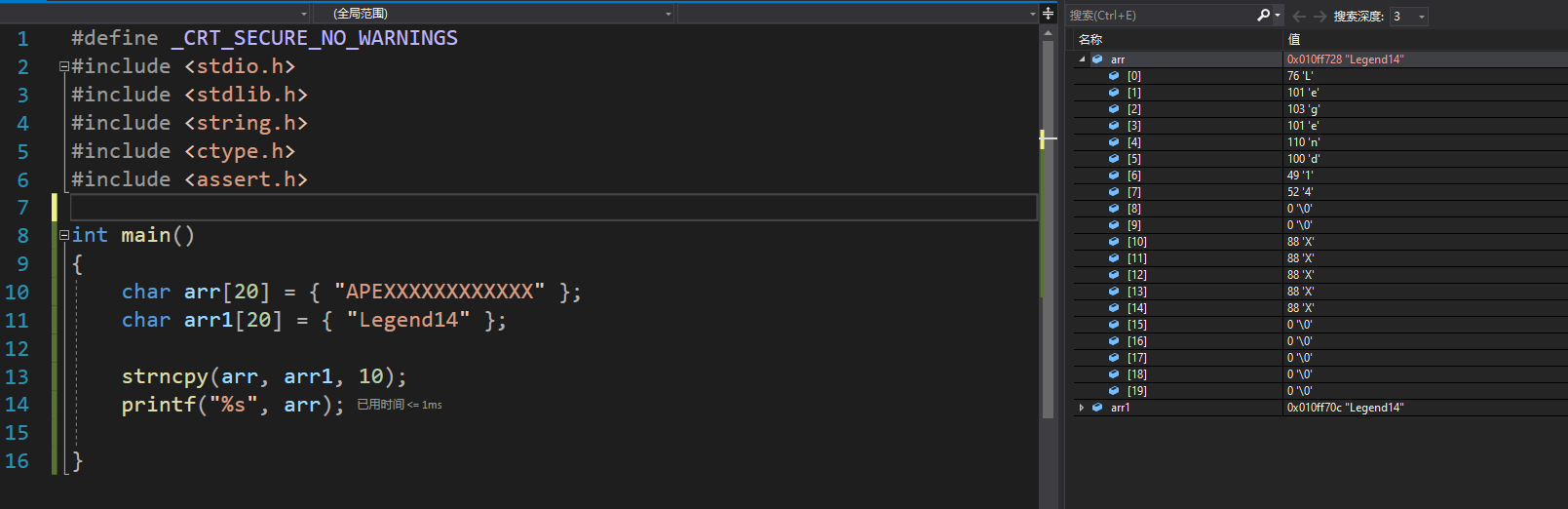
strncat
char * strncat ( char * destination, const char * source, size_t num );追加num个字符从源字符串到目标空间。
使用方法及效果如下:
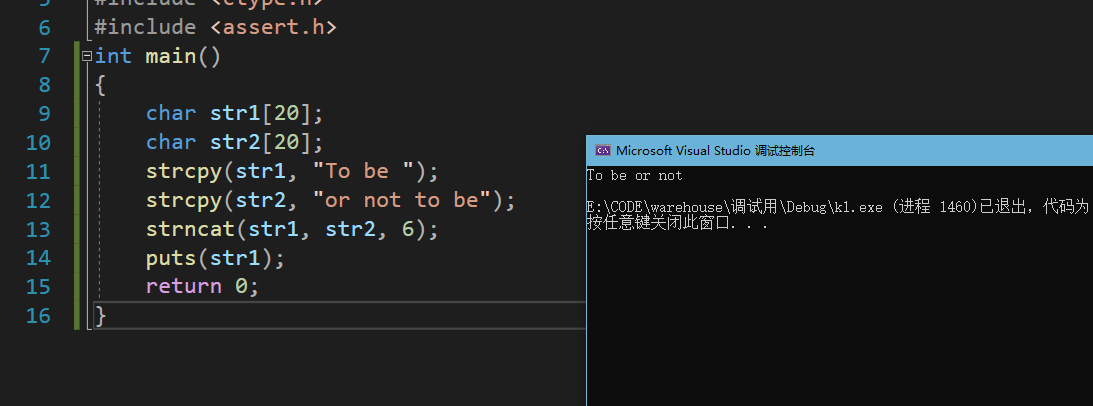
int main ()
{
char str1[20];
char str2[20];
strcpy (str1,"To be ");
strcpy (str2,"or not to be");
strncat (str1, str2, 6);
puts (str1);
return 0;
}
strncmp
int strncmp ( const char * str1, const char * str2, size_t num );比较到出现另个字符不一样或者一个字符串结束或者num个字符全部比较完。
我们借由这个函数可以尝试寻找那些只有开头两个字符一样的字符串,使我们寻找的条件变得可控
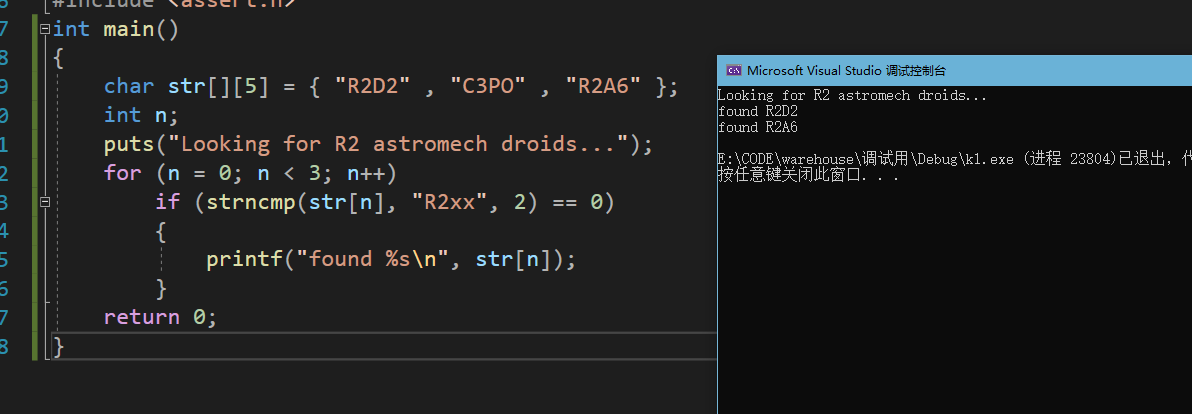
int main ()
{
char str[][5] = { "R2D2" , "C3PO" , "R2A6" };
int n;
puts ("Looking for R2 astromech droids...");
for (n=0 ; n<3 ; n++)
if (strncmp (str[n],"R2xx",2) == 0)
{
printf ("found %s\n",str[n]);
}
return 0;
}
字符串查找:
strstr
char * strstr ( const char *str1, const char * str2);判断str2是不是str1的子串,如果str2在str1中出现,返回在str1中第一次出现的地址
如果没有找到,返回空指针
使用例子如下:
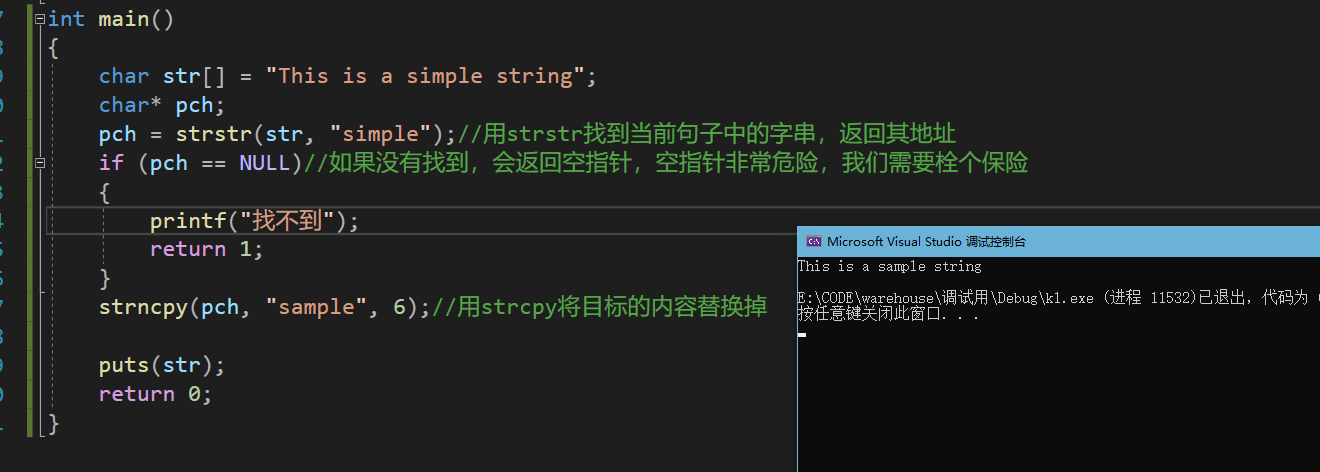
int main()
{
char str[] = "This is a simple string";
char* pch;
pch = strstr(str, "simple");//用strstr找到当前句子中的字串,返回其地址
if (pch == NULL)//如果没有找到,会返回空指针,空指针非常危险,我们需要栓个保险
{
printf("找不到");
return 1;
}
strncpy(pch, "sample", 6);//用strcpy将目标的内容替换掉
puts(str);
return 0;
}
strtok
char * strtok ( char * str, const char * sep );寻找目标字符串中指定的标记字符,并将其返回
sep参数是个字符串,定义了用作分隔符的字符集合
第一个参数指定一个字符串,它包含了0个或者多个由sep字符串中一个或者多个分隔符分割的标
记。
strtok函数找到str中的下一个标记,并将其用 \0 结尾,返回一个指向这个标记的指针。(注:
strtok函数会改变被操作的字符串,所以在使用strtok函数切分的字符串一般都是临时拷贝的内容
并且可修改。)
strtok函数的第一个参数不为 NULL ,函数将找到str中第一个标记,strtok函数将保存它在字符串
中的位置。
strtok函数的第一个参数为 NULL ,函数将在同一个字符串中被保存的位置开始,查找下一个标
记。
如果字符串中不存在更多的标记,则返回 NULL 指针。
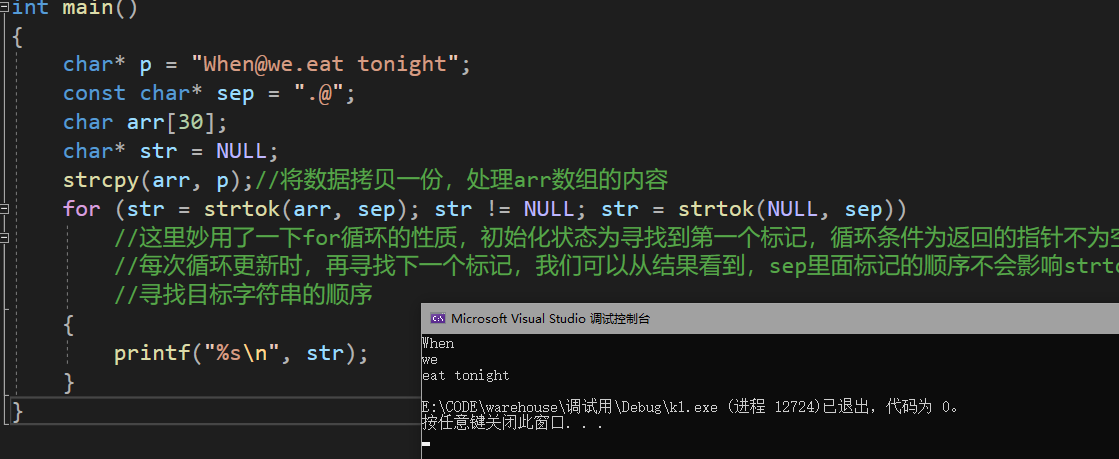
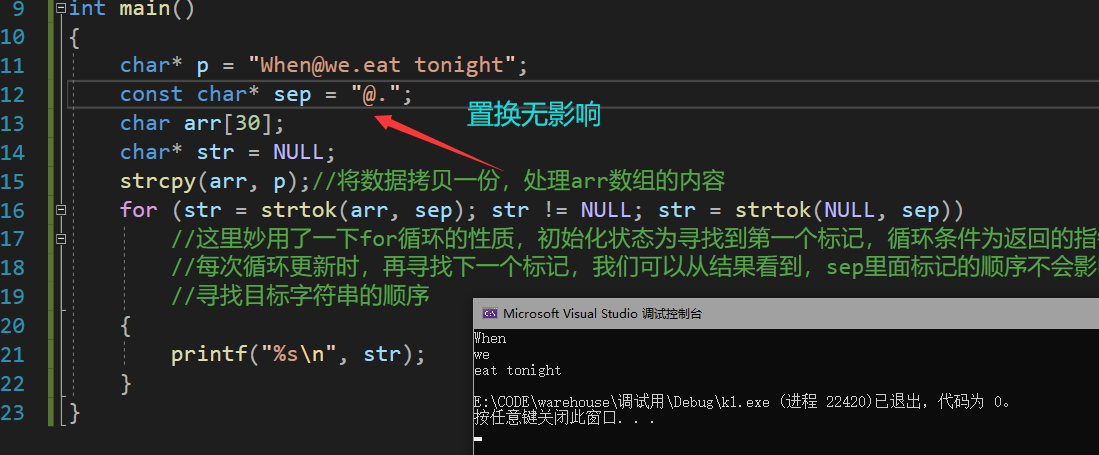
int main()
{
char* p = "[email protected] tonight";
const char* sep = ".@";
char arr[30];
char* str = NULL;
strcpy(arr, p);//将数据拷贝一份,处理arr数组的内容
for (str = strtok(arr, sep); str != NULL; str = strtok(NULL, sep))
//这里妙用了一下for循环的性质,初始化状态为寻找到第一个标记,循环条件为返回的指针不为空
//每次循环更新时,再寻找下一个标记,我们可以从结果看到,sep里面标记的顺序不会影响strtok
//寻找目标字符串的顺序
{
printf("%s\n", str);
}
} 
错误信息报告
strerror
#include <errno.h>//必须包含的头文件
char * strerror ( int errnum );返回错误码,所对应的错误信息。
C语言的库函数,在执行失败的时候,都会设置错误码
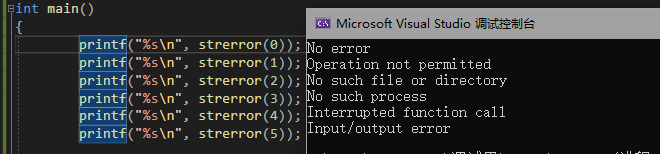
各类错误码的样式
我们不需要去记忆这些错误码,因为C语言在发生错误的时候都会返回一个错误码,可是我们可能会疑问,那这个错误码我怎么去调用它呢?
所以C语言自带了一个全局的专门存放错误代码的变量errno
只要C语言发生了错误,那么错误码就会被置放在这个变量里头
所以我们只需要在发生错误的时候执行以下代码就知道发生了什么错误:
printf("%s",strerror(errno));
字符分类函数:
| 函数 | 如果他的参数符合下列条件就返回真 |
| iscntrl | 任何控制字符 |
| isspace | 空白字符:空格‘ ’,换页‘\f’,换行'\n',回车‘\r’,制表符'\t'或者垂直制表符'\v' |
| isdigit | 十进制数字 0~9 |
| isxdigit | 十六进制数字,包括所有十进制数字,小写字母a~f,大写字母A~F |
| islower | 小写字母a~z |
| isupper | 大写字母A~Z |
| isalpha | 字母a~z或A~Z |
| isalnum | 字母或者数字,a~z,A~Z,0~9 |
| ispunct | 标点符号,任何不属于数字或者字母的图形字符(可打印) |
| isgraph | 任何图形字符 |
| isprint | 任何可打印字符,包括图形字符和空白字符 |
字符转换:
int tolower ( int c );//大写——>小写
int toupper ( int c );//小写——>大写int main ()
{
int i=0;
char str[]="Test String.\n";
char c;
while (str[i])
{
c=str[i];
if (isupper(c))
{
c=tolower(c);
}
putchar (c);
i++;
}
return 0;
}内存操作函数
C语言其实还有一些实用的函数,可以像字符串函数一样快捷的对内存中的数据进行操作。
memcpy
void * memcpy ( void * destination, const void * source, size_t num ); 函数memcpy从source的位置开始向后复制num个字节的数据到destination的内存位置。
这个函数在遇到 '\0' 的时候并不会停下来。
如果source和destination有任何的重叠,复制的结果都是未定义的,翻译成人话来讲就是如果想用memcpy自己拷贝自己的话是行不通的
由于memcpy可以对内存进行操作,所以结构体也是完全可以的
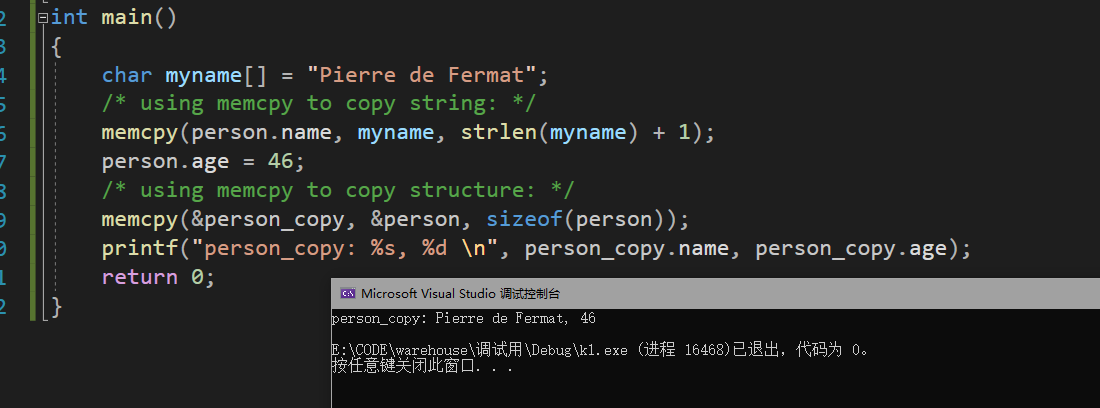
#include <stdio.h>
#include <string.h>
struct
{
char name[40];
int age;
} person, person_copy;
int main ()
{
char myname[] = "Pierre de Fermat";
/* using memcpy to copy string: */
memcpy ( person.name, myname, strlen(myname)+1 );
person.age = 46;
/* using memcpy to copy structure: */
memcpy ( &person_copy, &person, sizeof(person) );
printf ("person_copy: %s, %d \n", person_copy.name, person_copy.age );
return 0;
}
memmove
void * memmove ( void * destination, const void * source, size_t num );和memcpy的差别就是memmove函数处理的源内存块和目标内存块是可以重叠的。
如果源空间和目标空间出现重叠,就得使用memmove函数处理。
也就是memmove就可以实现自己转移自己的效果了。

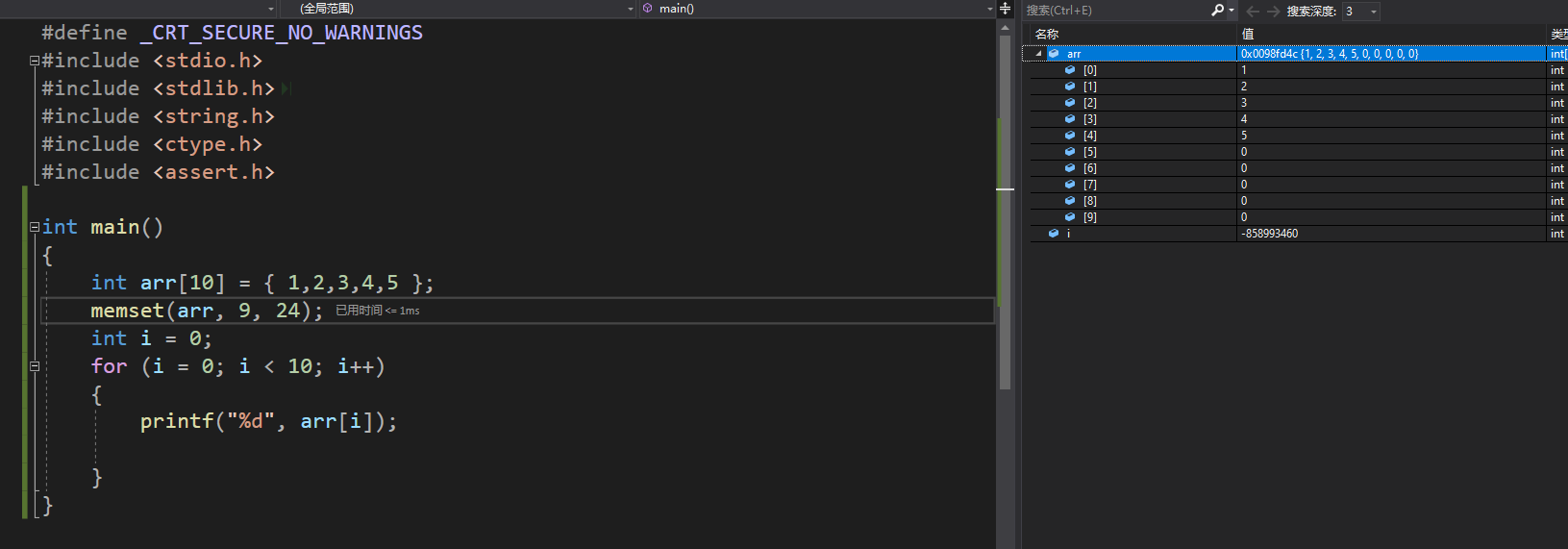
memset
以字节为单位进行内存设置
void *memset( void *dest, int c, size_t count );//目标空间,需要设置的字符,所需要设置的字节数注意,设置的是字节数,如果有使用需求还请注意修改的内容大小数量以及产生的影响。
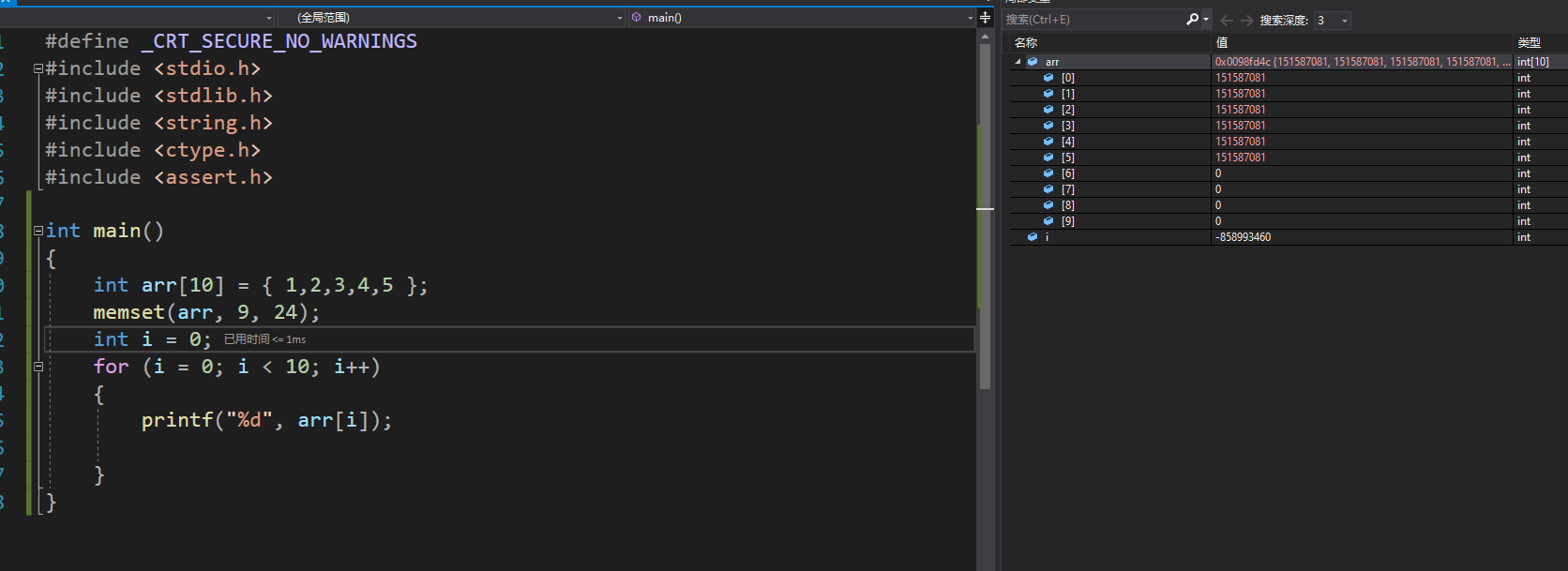
memcmp
比较从ptr1和ptr2指针开始的num个字节
int memcmp ( const void * ptr1,const void * ptr2,size_t num );返回值如下:
当返回值小于0时:两个内存空间中出现了一个比特位的值与另一个不相等,且空间1里的那个比特位的值小于空间2
当返回值等于0时:两个内存空间中的所有比特位的值另一个空间处处相等
当返回值大于0时:两个内存空间中出现了一个比特位的值与另一个不相等,且空间1里的那个比特位的值大于空间2
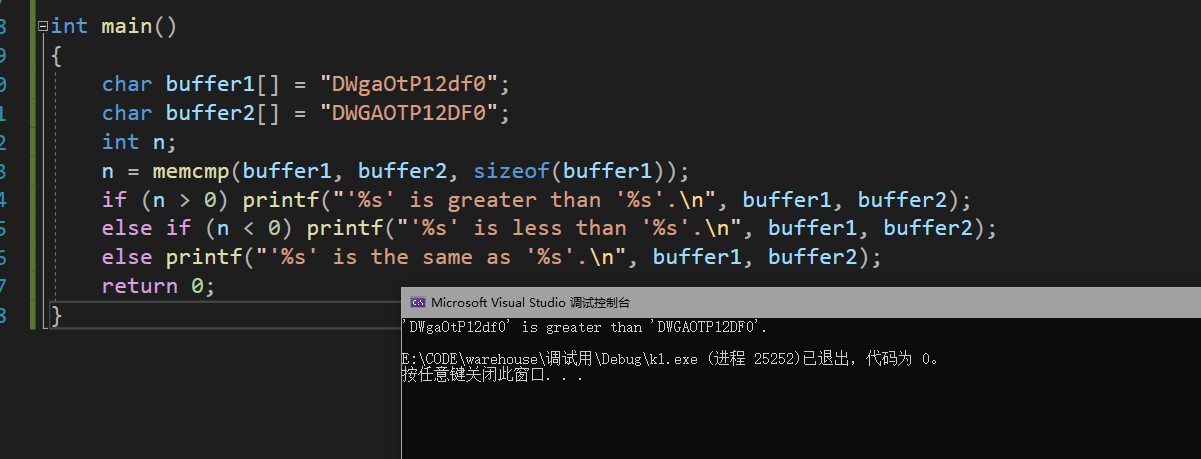
此处返回了大于0的值,小写字符的ASCll码值大于大写的,所以返回大于0的值。
模拟实现字符串函数及内存函数
了解完这些函数之后,还是有必要了解其工作原理的,不然很容易知其然不知其所以然,深入了解这些函数的逻辑原理也有助于理解,所以我们可以尝试一下模拟实现其中几个比较常用的函数。
模拟实现strlen
strlen还是比较常用的函数,所以我们先那它试试手,其主要逻辑若是暴力求解那就是计数器,计数至“\0”停手返回计数值,这是第一种方法:
//非递归实现strlen
int main()
{
int n = 0;
int count = 0;
char arr[] = "OMG";
while (arr[n] != '\0')
{
count++;
n +=1;
}
printf("%d ", count);
return 0;
}
第二种方法就是递归:
//递归和非递归分别实现strlen
int Fun(char* n)
{
int count = 0;
if (*n !='\0')
{
count++;
return Fun(n+1)+1;
}
else
return count;
}
int main()
{
int a = 0;
char arr[] = "OMG";
int ret = Fun(arr);
printf("%d ", ret);
return 0;
}
第三种方法简单易懂,使用指针来计数:
int mystrlen(const char* arr)
{
int count = 0;
while (*arr++)
{
count++;
}
return count;
}
int main()
{
char arr[50] = "XXXXX";
scanf("%s", arr);
printf("%d ", mystrlen(arr));
return 0;
}
指针方法还有优化版本,如下:
//指针-指针的方式
int my_strlen(char *s)
{
char *p = s;
while(*p != ‘\0’ )
p++;
return p-s;
}
因为指针-指针可以得到两个指针之间的元素个数,我们让指针走到“\0”之前,然后减去指向首地址的指针,就可以得到字符串的长度了。
模拟实现strcpy
解析已写入代码段:
char* my_strcpy(char* des,const char* res)//利用const保证res和不会因为位置对调而报错
//原理是const修饰的变量不能被改变,当赋值顺序改变的时候,触发const机制
//即*res ++ = des ++ 的之后报错,扼杀可能报错的来源
{
assert(res != NULL);//断言,放置啥都不输入就执行函数
assert(des != NULL);
char* ret = des;
while (*des++ = *res++ )
{
;
}
return ret;//为什么返回一个指针变量呢?方便链式访问,数组名相当于一个指针变量,返回char*就相当于返回了整个数组
}
int main()
{
char des[] = "XXXXXXXXXXX";
char res[] = "copy down";
//my_strcpy(des, res);
printf("%s\n", my_strcpy(des, res));
return 0;
}
模拟实现strcat
strcat实现起来也不复杂,我们只需要先获得目标字符串末尾的地址然后接过去就好了。
char* mystrcat(char* dest, const char* sour)//在另一个字符串后面加字符串
{
char* ret = dest;
char* end = 0;
assert((dest && sour )!= NULL);
while (*dest)
{
dest++;
}
while (*dest++ = *sour++)
{
;
}
return ret;
}
模拟实现strstr
strstr有一个比较棘手的问题,当目标字符串里头只有前面一部分是我要找的字串该怎么办?两个指针一起移动时遇到这个问题时就需要回到最初的情况,然后向下遍历。
这个时候我们就需要多几个指针来解决这个问题,当没有找全的时候不返回值,将arr2的指针重新赋值回arr1,arr1向后遍历,每+1一个字符arr2的指针就与arr1一起向后比对,直到arr2的指针成功的碰到了“\0”才算结束。
如果arr2的指针没有碰到“\0”之前arr1与arr2的字符就已经不相等了,那么arr1的指针回到开始的位置并+1.,arr2指针也回到起点。
char* mystrstr(char* arr1, const char* arr2)
{
assert(arr1 && arr2);
char* mark1;
char* mark2 = arr2;
while (*arr1)
{
mark1 = arr1;
arr2 = mark2;
while (*arr1 != '\0' && *arr2 != '\0' && *arr1 == *arr2)
{
arr1++;
arr2++;
}
if (*arr2 == '\0')
{
return mark1;
}
arr1++;
}
return NULL;
}
模拟实现strcmp
int mystrcmp(const char* arr1, const char* arr2)
{
assert(arr1 && arr2);
while (*arr1 == *arr2)
{
if (*arr1 == '0')
return 0;
*arr1++;
*arr2++;
}
return (*arr1 - *arr2);
}
模拟实现memcpy
接下来则是内存函数的实现了,内存函数的模拟实现则有些不同,这个时候我们需要处理内存里面的数据,而内存里面存放的数据类型我们根本不可能知道,所以我们需要使用void*来接收来自内存里的变量,然后又一个问题来了,那么我都不知道内存里的数据类型是什么,我该如何控制内存里面数据的改动呢?
我们知道,一个int*类型的指针变量,每一次+1就是一次访问4个字节,而char*类型的指针变量每一次+1只访问1个字节,那么,我们只需要将每个传过来的数据像一刀刀切成小块来逐个处理不就可以实现改动内存里面的数据了吗?一个一个字节的逐个更改移动,直接解决了我们的问题,那么实现起来就不在话下了。
void * memcpy ( void * dst, const void * src, size_t count)
{
void * ret = dst;
assert(dst);
assert(src);
while (count--)
{
*(char *)dst = *(char *)src;//将指针类型强制转化成char*,每次只访问一个字节
dst = (char *)dst + 1;
src = (char *)src + 1;
}
return(ret);
}模拟实现memmove
memmove有一个需要注意的点,memmove可以自己对自己进行修改,但是有一些情况下会出现问题比如下图:
图片来自于博主:@北方留意尘

所以,直接正向拷贝是不行的,而反向拷贝可以解决我们的问题,但是问题则是什么时候我们使用正向拷贝,什么时候使用反向拷贝?
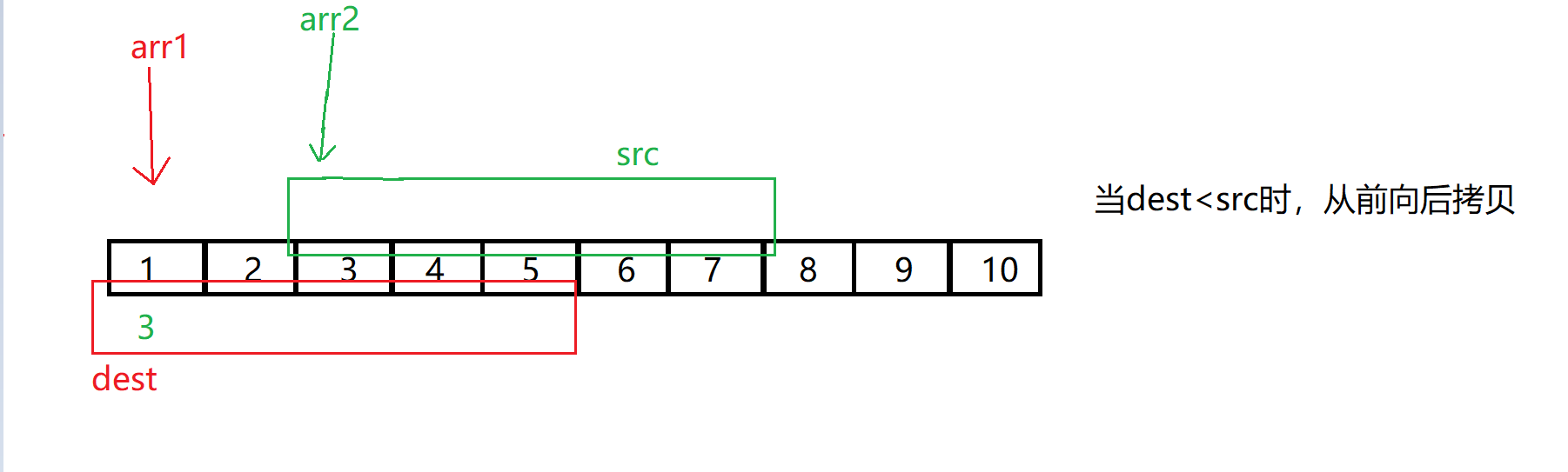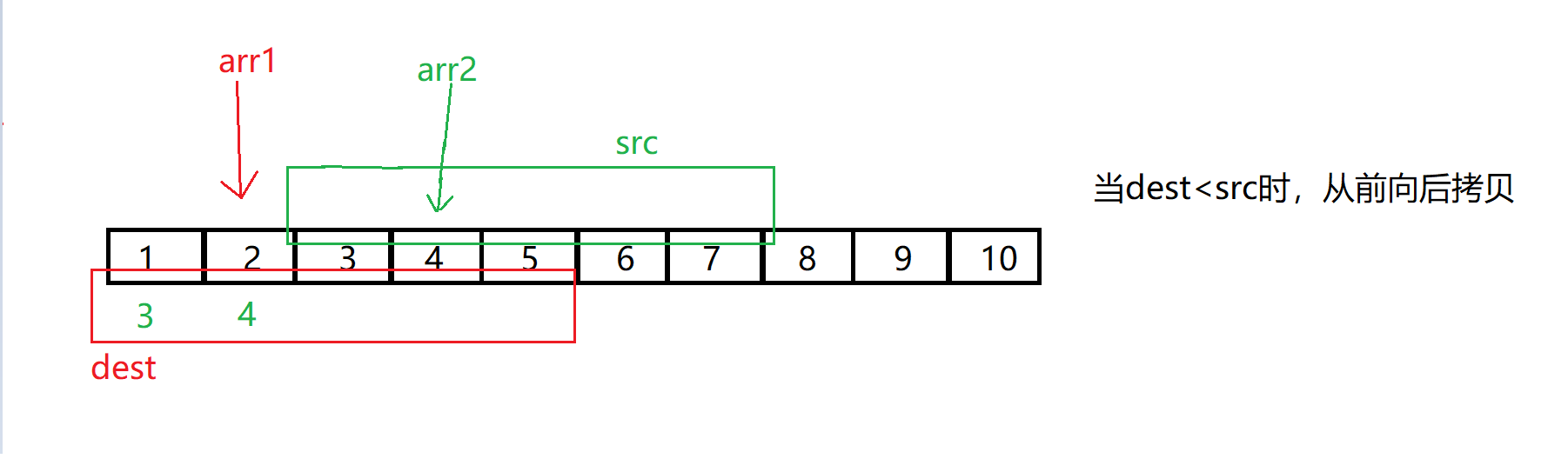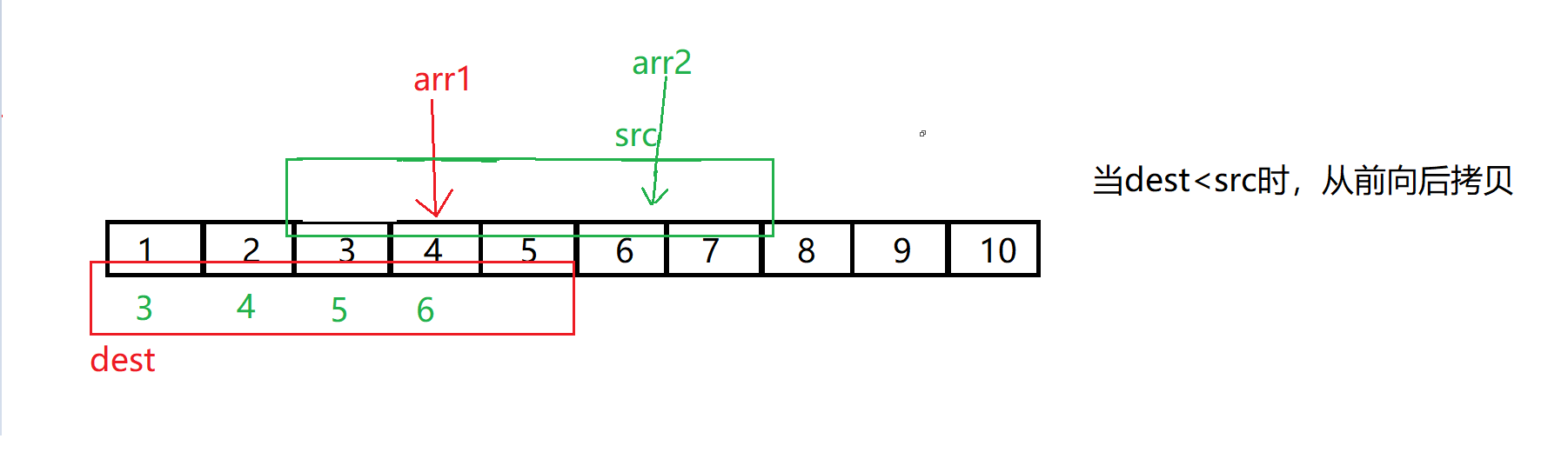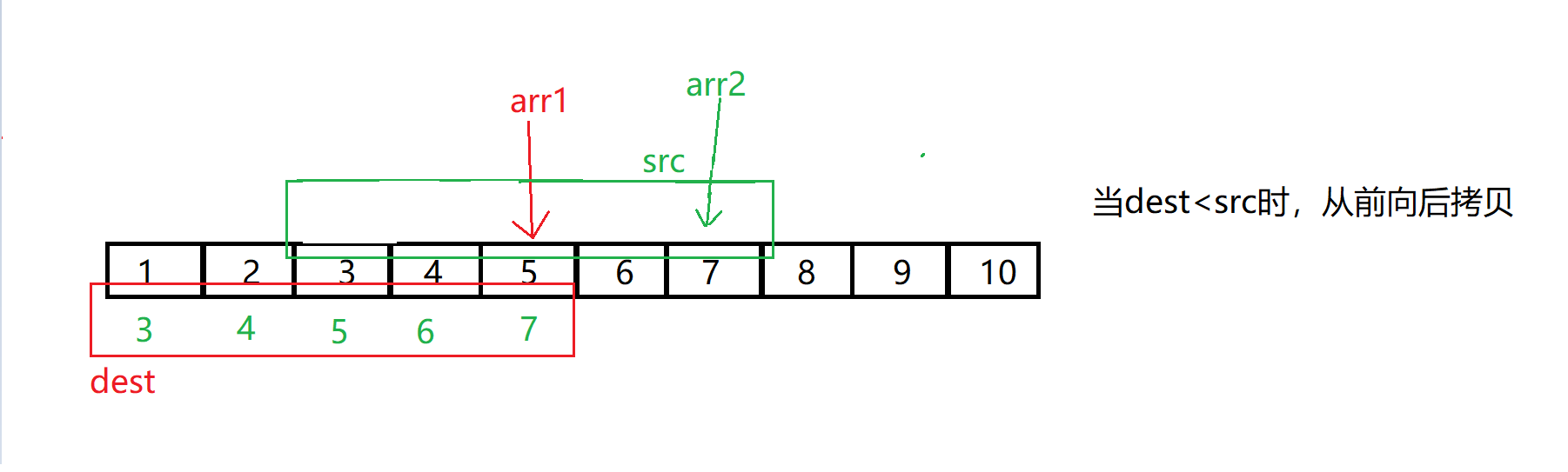
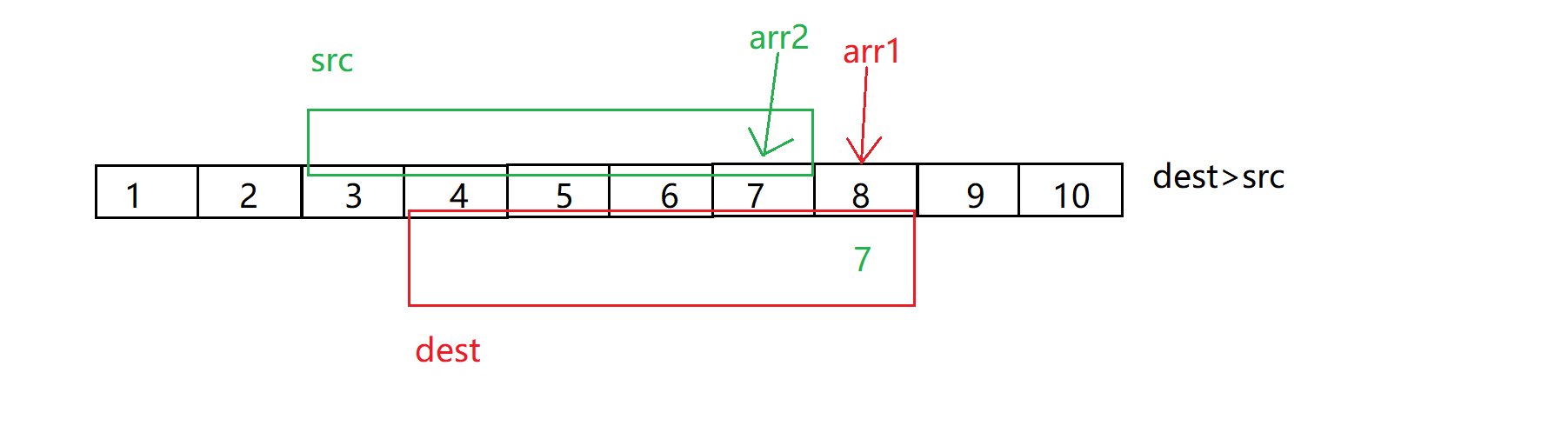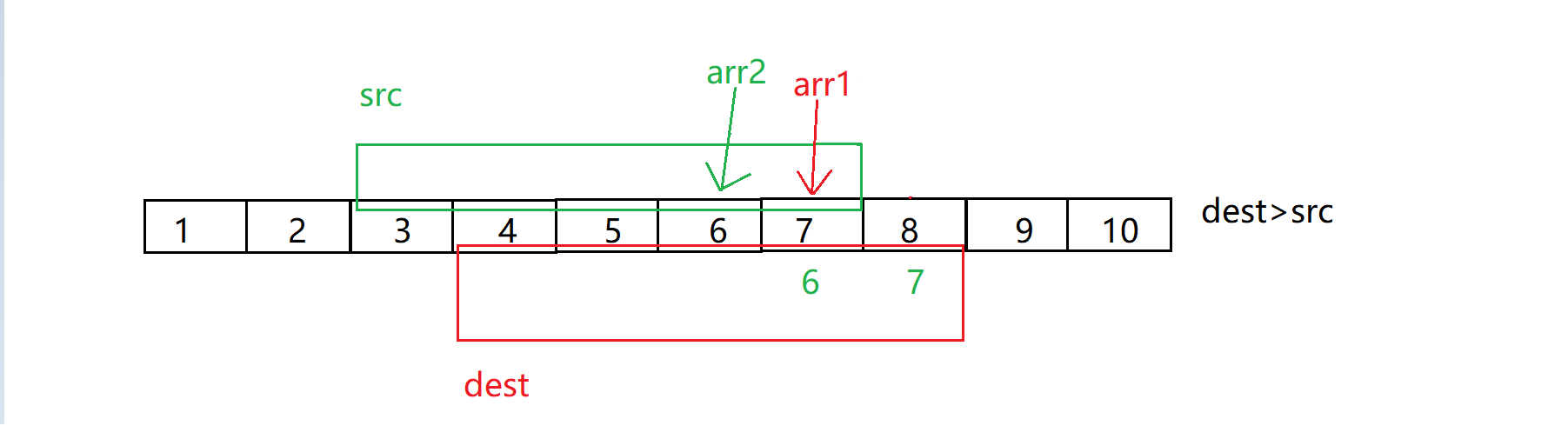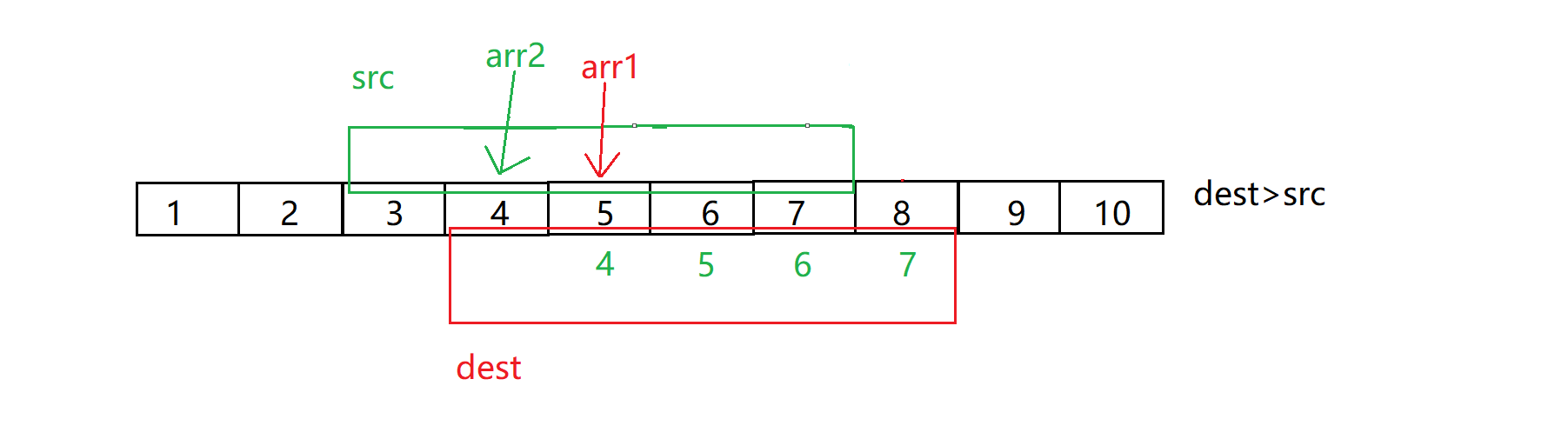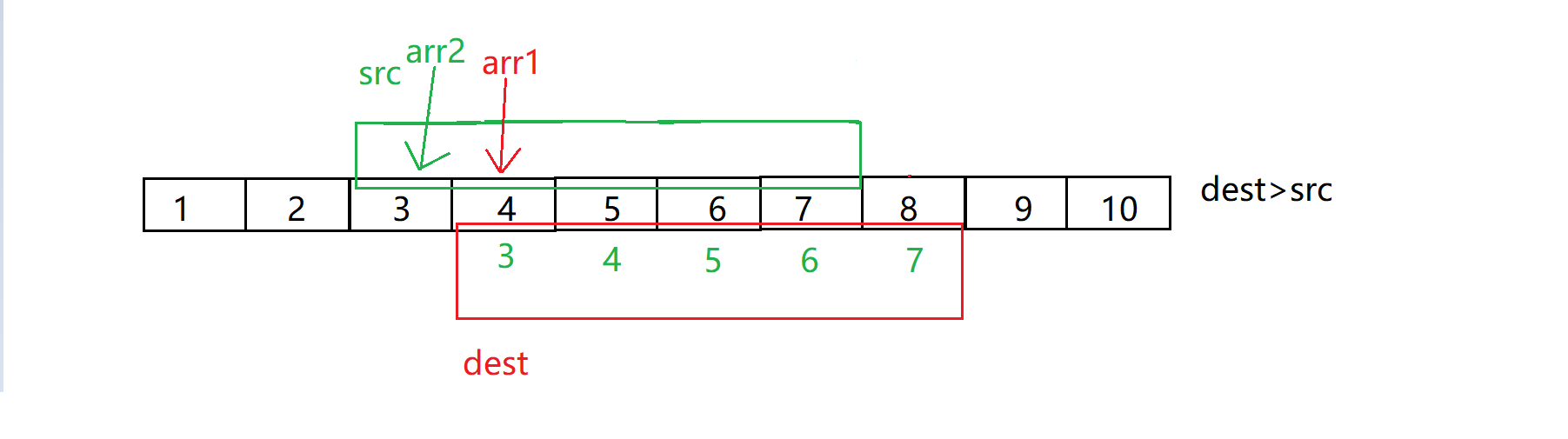
总结:当需要拷贝的地址dest > src地址,从后向前拷贝 ;dest < src时,从前向后拷贝
void* mymemmove(void * dst,const void *src, size_t length)
{
void* ret = dst;
assert(dst && src );
if (dst > src)
{
while (length--)
{
*((char*)dst + length) = *((char*)src + length);
//加上lenth以达到尾部
}
}
else//从前向后拷贝
{
while (length--)
{
*(char*)dst = *(char*)src;
dst = (char*)dst + 1;
src = (char*)src + 1;
}
}
return ret;
}
至此,概述完毕,希望对你有点帮助!
