目录
-
- *资料集结地
- docker
- 阿里云 ECS
- 云服务器ucloud
-
- 1.报错
-
- 1.1sudo apt-get update不能更新源
- 2.[sudo apt-get update提示E: 仓库 “http://mirrors.aliyun.com/ubuntu eoan Release” 没有 Release 文件。 解决办法](https://blog.csdn.net/jh_luchi/article/details/102812031)
- 3.[E: Sub-process /usr/bin/dpkg returned an error code (1)解决办法](https://blog.csdn.net/stickmangod/article/details/85316142/)
- Ubuntu16.04 配置SSH无密码登录
- Linux目录结构
- 常用命令
- 1.hadoop
- 2.HDFS
*资料集结地
下载专区
教材配套的各种资料的下载,包括讲义PPT(最新版本)、教学大纲、软件、数据集等
学习路线
主目录:林子雨:大数据学习路线
- 在Windows中使用VirtualBox安装Ubuntu虚拟机√
- Hadoop3.1.3安装教程_单机/伪分布式配置_Hadoop3.1.3/Ubuntu18.04(16.04)√
- Hadoop集群安装配置教程_Hadoop3.1.3_Ubuntu√
- HDFS编程实践(Hadoop3.1.3))√
- HBase2.2.2安装和编程实践指南
- MapReduce编程实践(Hadoop3.1.3)
- Hive3.1.2安装指南
- Spark安装和编程实践(Spark2.4.0)√
- Flink安装与编程实践(Flink1.9.1)√
大数据专栏
csdn:快速入门大数据
github:BigData-Notes
大数据经典论文
论文下载地址:链接:https://pan.baidu.com/s/1sbZ6w9jf8ivYFP8CWZgO4w
提取码:682u
| 名称 | 论文来源 | 发表年份 |
|---|---|---|
| GFS | The Google File System | 2003 |
| MapReduce | MapReduce:Simplified Data Processing on Large Clusters | 2004 |
| Bigtable | Bigtable:A Distributed Storage System for Structured Datapdf | 2006 |
| Chubby | The Chubby lock service for loosely-coupled distributed systems | 2006 |
| Thrift | Thrift:Scalable Cross-Language Services Implementation | 2009 |
| Hive | Hive:A Warehousing Solution Over a Map-Reduce | 2009 |
| Dremel | Dremel:Interactive Analysis of Web-Scale Datasets | 2010 |
| Spark | Spark:Cluster Computing with Working Sets | 2010 |
| Megastore | Megastore:Providing Scalable, Highly Available | 2011 |
| Spanner | Spanner: Google’s Globally-Distributed Database | 2012 |
| S4 | S4:Distributed_Stream_Computing_Platform | 2010 |
| Storm | Storm @Twitter | 2014 |
| Kafka | Kafka:a Distributed Messaging System for Log Processing | 2011 |
| GFS | The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out-of-Order Data Processing | 2015 |
| Raft | In Search of an Understandable Consensus Algorithm | 2014 |
| Brog | Large-scale cluster management at Google with Borg | 2015 |
| Kubernetes | Borg, Omega, and Kubernetes | 2016 |

Java学习总结
IDEA 编码设置
github:学习Java过程中的一些代码
docker
菜鸟教程:docker安装与使用
docker原理与k8s的区别
阿里云 ECS
ping不通ECS的外网IP
添加安全组,开放网络字段,实际操作,请见https://developer.aliyun.com/article/767653?spm=a2c6h.13813017.content3.6.143c6be7TYmHl5

Centos7.4免密码登录
- 在每个主机上都下载ssh
sudo yum install openssh-server - 关闭防火墙
systemctl disable firewalld.service - 生成公钥密钥,
ssh-keygen - 建立信任连接列表,
cat ~/.ssh/id_rsa.pub>>~/.ssh/authorized_keys - 无密码登录主机,
ssh localhost,退出exit
centos7下安装python3.8
hadoop 运行python程序
Hadoop与Python的联系
Python3调用Hadoop的API
使用pyhdfs连接HDFS进行操作
1.常用命令
重启docker
systemctl restart docker
查看状态
systemctl status docker
*报错
1.Docker“Got permission denied while trying to connect to the Docker daemon socket“问题
2.Docker 安装完成后测试hello-world出现问题:Unable to find image ‘hello-world:latest’ locally
云服务器ucloud
1.报错
1.1sudo apt-get update不能更新源
2.sudo apt-get update提示E: 仓库 “http://mirrors.aliyun.com/ubuntu eoan Release” 没有 Release 文件。 解决办法
3.E: Sub-process /usr/bin/dpkg returned an error code (1)解决办法
Ubuntu16.04 配置SSH无密码登录
Linux目录结构
bin 存放二进制可执行文件(ls,cat,mkdir等)
boot 存放用于系统引导时使用的各种文件
dev 用于存放设备文件
etc 存放系统配置文件
home 存放所有用户文件的根目录
lib 存放跟文件系统中的程序运行所需要的共享库及内核模块
mnt 系统管理员安装临时文件系统的安装点
opt 额外安装的可选应用程序包所放置的位置
proc 虚拟文件系统,存放当前内存的映射
root 超级用户目录
sbin 存放二进制可执行文件,只有root才能访问
tmp 用于存放各种临时文件
usr 用于存放系统应用程序,比较重要的目录/usr/local 本地管理员软件安装目录
var 用于存放运行时需要改变数据的文件
常用命令
1.vim
保存退出 wq!
不保存退出 q!
定位到任意行 :行数
从开头搜索
在命令模式下,输入/你要查找的字符
按下回车,可以看到vim把光标移动到该字符处
再按n(小写)查看下一个匹配
按N(大写)查看上一个匹配(capslock切换大小写,也可以在小写状态下按shift+n)
从结尾处搜索
?要搜索的字符串或字符
搜索后,打开别的文件发现也被高亮了,怎么关闭
命令行模式下,输入:nohlsearch或者:set nohlsearch
可以简写成noh喝set-noh
2.rm
rm [选项] 文件
-f, --force 强力删除,不要求确认
-i 每删除一个文件或进入一个子目录都要求确认
-I 在删除超过三个文件或者递归删除前要求确认
-r, -R 递归删除子目录
-d, --dir 删除空目录
-v, --verbose 显示删除结果
============================================================================
常用如下几个:
rm -d 目录名 #删除一个空目录
rmdir 目录名 #删除一个空目录
rm -r 目录名 #删除一个非空目录
rm 文件名 #删除文件
在终端进到那个文件夹,然后执行:
sudo rm -rf 文件夹名
如果还是不行,就用
sudo chmod 777 文件夹名
sudo rm -rf 文件夹名
zookeeper安装例子
1.1 解压安装包至路径 /usr/local,命令如下:
evan@evan-virtual-machine:~/下载$ sudo tar -zxf apache-zookeeper-3.5.9.tar.gz -C /usr/local
1.2 将解压的文件名apache-zookeeper-3.5.9改为zookeeper,以方便使用,命令如下:
cd /usr/local
sudo mv ./apache-zookeeper-3.5.9 ./zookeeper
把zookeeper目录权限赋予给evan用户
cd /usr/local
sudo chown -R evan ./zookeeper
1.3 配置环境变量
将hbase下的bin目录添加到path中,这样,启动hbase就无需到/usr/local/zookeeper目录下,大大的方便了zookeeper的使用。教程下面的部分还是切换到了/usr/local/zookeeper目录操作,有助于初学者理解运行过程,熟练之后可以不必切换。
编辑~/.bashrc文件
vim ~/.bashrc
如果没有引入过PATH请在~/.bashrc文件尾行添加如下内容:
export PATH=$PATH:/usr/local/zookeeper/bin
1.hadoop
1.1本地安装
管理界面:http://evan-virtual-machine:8088/cluster/
NameNode界面:
http://evan-virtual-machine:50070(2.x)
http://evan-virtual-machine:9870(3.x)
HaDoop3.0之前web访问端口是50070 hadoop3.0之后web访问端口为9870
WEB访问问题
HDFS NameNode界面:http://evan-virtual-machine:8042
Ubuntu20.04下Hadoop的本地安装与配置
1.2Hadoop单机配置(非分布式)
切换到hadoop安装目录
cd /usr/local/hadoop
NameNode 的格式化
./bin/hdfs namenode -format
生成输入输出目录
mkdir ./input
mkdir ./output
启动hadoop
./sbin/start-dfs.sh
查看主节点和备份节点
jps

cp ./etc/hadoop/*.xml ./input # 将配置文件作为输入文件
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input ./output 'dfs[a-z.]+'
cat ./output/* # 查看运行结果
1.3伪分布式运行mapreduce
1.3.1配置 core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/evan/文档/hadoop-tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://evan-virtual-machine:9000</value>
</property>
</configuration>
1.3.2配置 hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/evan/文档/hadoop-tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/evan/文档/hadoop-tmp/dfs/data</value>
</property>
</configuration>
1.3.3配置 yarn-site.xml
<configuration>
<!-- reducer 获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 YARN 的 ResourceManager 的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>evan-virtual-machine</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>/usr/local/hadoop//etc/hadoop:/usr/local/hadoop//share/hadoop/common/lib/*:/usr/local/hadoop//share/hadoop/common/*:/usr/local/hadoop//share/hadoop/hdfs:/usr/local/hadoop//share/hadoop/hdfs/lib/*:/usr/local/hadoop//share/hadoop/hdfs/*:/usr/local/hadoop//share/hadoop/mapreduce/lib/*:/usr/local/hadoop//share/hadoop/mapreduce/*:/usr/local/hadoop//share/hadoop/yarn:/usr/local/hadoop//share/hadoop/yarn/lib/*:/usr/local/hadoop//share/hadoop/yarn/*</value>
</property>
</configuration>
1.3.4配置 mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
sudo vim /etc/hosts
1.3.5本地主机名和Hadoop主机名要一样,注释::1行
127.0.1.1 evan-virtual-machine(本地主机名)
127.0.0.1 evan-virtual-machine(Hadoop主机名)

最后再把hadoop-env.sh和yarn-env.sh文件,添加JAVA_HOME=export JAVA_HOME=/usr/lib/java/jdk1.8.0_212
1.3.6HDFS创建实例
在使用HDFS之前,需要保证hadoop处于运行状态
在HDFS中创建用户目录
./bin/hdfs dfs -mkdir -p /user/hadoop
在user/hadoop 中建立input文件夹,将etc/hadoop中的xml文件复制到input文件夹中作为输入文件
./bin/hdfs dfs -mkdir /user/hadoop/input
./bin/hdfs dfs -put ./etc/hadoop/*.xml /user/hadoop/input
复制完成后,可以通过命令查看文件列表
./bin/hdfs dfs -ls /user/hadoop/input

伪分布式运行mapreduce读取的是HDFS的文件
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep /user/hadoop/input /user/hadoop/output 'dfs[a-z.]+'

利用命令查看运行结果,输出结果位于HDFS中
./bin/hdfs dfs -cat /user/hadoop/output/*

删除非空目录
./bin/hdfs dfs -rm -r /user/hadoop/output/
参考资料:伪分布式运行mapreduce
伪分布式运行相关报错
1.hadoop3.1.3:找不到或无法加载主类 org.apache.hadoop.mapreduce.v2.app.MRAppMaster
yarn执行MapReduce任务时,找不到主类导致的
解决:
1、在命令行输入:hadoop classpath
evan@evan-virtual-machine:/usr/local/hadoop$ hadoop classpath
/usr/local/hadoop//etc/hadoop:/usr/local/hadoop//share/hadoop/common/lib/*:/usr/local/hadoop//share/hadoop/common/*:/usr/local/hadoop//share/hadoop/hdfs:/usr/local/hadoop//share/hadoop/hdfs/lib/*:/usr/local/hadoop//share/hadoop/hdfs/*:/usr/local/hadoop//share/hadoop/mapreduce/lib/*:/usr/local/hadoop//share/hadoop/mapreduce/*:/usr/local/hadoop//share/hadoop/yarn:/usr/local/hadoop//share/hadoop/yarn/lib/*:/usr/local/hadoop//share/hadoop/yarn/*
2、把上述输出的值添加到yarn-site.xml文件对应的属性 yarn.application.classpath下面,eg:
<property>
<name>yarn.application.classpath</name>
<value>/usr/local/hadoop//etc/hadoop:/usr/local/hadoop//share/hadoop/common/lib/*:/usr/local/hadoop//share/hadoop/common/*:/usr/local/hadoop//share/hadoop/hdfs:/usr/local/hadoop//share/hadoop/hdfs/lib/*:/usr/local/hadoop//share/hadoop/hdfs/*:/usr/local/hadoop//share/hadoop/mapreduce/lib/*:/usr/local/hadoop//share/hadoop/mapreduce/*:/usr/local/hadoop//share/hadoop/yarn:/usr/local/hadoop//share/hadoop/yarn/lib/*:/usr/local/hadoop//share/hadoop/yarn/*</value>
</property>
1.4Hadoop集群安装配置
1.4.1网络配置
开始学习Hadoop集群都是按照1主(Master)2从(Slave1、Slave2)配置。由于集群中有两台机器需要设置,所以,在接下来的操作中,一定要注意区分Master节点和Slave节点。为了便于区分Master节点和Slave节点,可以修改各个节点的主机名,这样,在Linux系统中打开一个终端以后,在终端窗口的标题和命令行中都可以看到主机名,就比较容易区分当前是对哪台机器进行操作。在Centos中,我们在 Master 节点上执行如下命令修改主机名:
sudo vim /etc/hostname
执行上面命令后,就打开了“/etc/hostname”这个文件,这个文件里面记录了主机名,比如,假设Centos系统,设置的主机名是“localhost”,因此,打开这个文件以后,里面就只有“localhost”这一行内容,可以直接删除,并修改为“Master”(注意是区分大小写的),然后,保存退出vim编辑器,这样就完成了主机名的修改,需要重启Linux系统才能看到主机名的变化。在阿里云ECS控制台,点击Master实例重启。注意观察主机名修改前后的变化。
然后,在Master节点中执行如下命令打开并修改Master节点中的“/etc/hosts”文件:
sudo vim /etc/hosts
可以在hosts文件中增加如下两条IP和主机名映射关系:
172.19.138.111 Master Master
172.19.138.112 Slave1 Slave1
172.19.138.113 Slave2 Slave2
修改后的效果如下图所示。

需要注意的是,一般hosts文件中只能有一个127.0.0.1,其对应主机名为localhost,如果有多余127.0.0.1映射,应删除,特别是不能存在“127.0.0.1 Master”这样的映射记录。修改后需要重启Master服务器。

上面完成了Master节点的配置,接下来要继续完成对其他Slave节点的配置修改。请参照上面的方法,把Slave1和Slave2节点上的“/etc/hostname”文件中的主机名修改为“Slave1”和“Slave2”,同时,修改“/etc/hosts”的内容,在hosts文件中增加如下两条IP和主机名映射关系:
172.19.138.111 Master Master
172.19.138.112 Slave1 Slave1
172.19.138.113 Slave2 Slave2
修改完成以后,请重新启动Slave节点服务器。
这样就完成了Master节点和Slave节点的配置,然后,需要在各个节点上都执行如下命令,测试是否相互ping得通,如果ping不通,后面就无法顺利配置成功:
ping Master -c 3 # 只ping 3次就会停止,否则要按Ctrl+c中断ping命令
ping Slave1 -c 3
ping Slave2 -c 3
例如,在Master节点上ping Master、Slave1、Slave2,如果ping通的话,会显示如下图所示的结果。

注:购买相同配置的机型,互相ping通没问题
1.4.2SSH无密码登录节点
必须要让Master节点可以SSH无密码登录到各个Slave节点上。首先,生成Master节点的公匙,如果之前已经生成过公钥,必须要删除原来生成的公钥,重新生成一次,因为前面我们对主机名进行了修改。具体命令如下:
cd ~/.ssh # 如果没有该目录,先执行一次ssh localhost
rm ./id_rsa* # 删除之前生成的公匙(如果已经存在)
ssh-keygen -t rsa # 执行该命令后,遇到提示信息,一直按回车就可以
为了让Master节点能够无密码SSH登录本机,需要在Master节点上执行如下命令:
cat ./id_rsa.pub >> ./authorized_keys
完成后可以执行命令“ssh Master”来验证一下,可能会遇到提示信息,只要输入yes即可,测试成功后,请执行“exit”命令返回原来的终端。
Slave1和Slave2节点在各自服务器上创建mkdir /home/hadoop/,接下来,在Master节点将上公匙传输到Slave1和Slave2节点:
scp ~/.ssh/id_rsa.pub root@Slave1:/home/hadoop/
scp ~/.ssh/id_rsa.pub root@slave2:/home/hadoop/
接着在Slave1节点上,将SSH公匙加入授权:
ssh Slave1 # 需要输入登录密码
mkdir ~/.ssh # 如果不存在该文件夹需先创建,若已存在,则忽略本命令
cat /home/hadoop/id_rsa.pub >> ~/.ssh/authorized_keys
rm /home/hadoop/id_rsa.pub # 用完以后就可以删掉
然后在Slave2节点上,将SSH公匙加入授权:
ssh Slave2 # 需要输入登录密码
mkdir ~/.ssh # 如果不存在该文件夹需先创建,若已存在,则忽略本命令
cat /home/hadoop/id_rsa.pub >> ~/.ssh/authorized_keys
rm /home/hadoop/id_rsa.pub # 用完以后就可以删掉
如果有其他Slave节点,也要执行将Master公匙传输到Slave节点以及在Slave节点上加入授权这两步操作。
这样,在Master节点上就可以无密码SSH登录到各个Slave节点了,可在Master节点上执行如下命令进行检验:
ssh Slave1

1.4.3配置PATH变量
在前面的伪分布式安装内容中,已经介绍过PATH变量的配置方法。可以按照同样的方法进行配置,这样就可以在任意目录中直接使用hadoop、hdfs等命令了。如果还没有配置PATH变量,那么需要在Master节点上进行配置。 首先执行命令“vim ~/.bashrc”,也就是使用vim编辑器打开“~/.bashrc”文件,然后,在该文件最上面的位置加入下面内容:
export JAVA_HOME=/home/hadoop/jdk1.8.0/ # 如果有就不要添加
export JRE_HOME=$JAVA_HOME/jre # 如果有就不要添加
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib # 如果有就不要添加
export PATH=$PATH:$JAVA_HOME/bin # 如果有就不要添加
export PATH=$PATH:/usr/local/hadoop/bin:/usr/local/hadoop/sbin
保存后执行命令“source ~/.bashrc”,使配置生效。
1.4.4配置集群/分布式环境
在配置集群/分布式模式时,需要修改“/usr/local/hadoop/etc/hadoop”目录下的配置文件,这里仅设置正常启动所必须的设置项,包括workers 、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml共5个文件,更多设置项可查看官方说明。
1.4.4.1修改文件 workers
需要把所有数据节点的主机名写入该文件,每行一个,默认为 localhost(即把本机作为数据节点),所以,在伪分布式配置时,就采用了这种默认的配置,使得节点既作为名称节点也作为数据节点。在进行分布式配置时,可以保留localhost,让Master节点同时充当名称节点和数据节点,或者也可以删掉localhost这行,让Master节点仅作为名称节点使用。
本教程让Master节点仅作为名称节点使用,因此将workers文件中原来的localhost删除,添加如下两行内容:
Slave1
Slave2
1.4.4.2修改文件 core-site.xml
切到core-site.xml所在的根目录下,修改core-site.xml:
cd /usr/local/hadoop/etc/hadoop/
vim core-site.xml
core-site.xml文件修改为如下内容:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>
1.4.4.3修改文件 hdfs-site.xml
对于Hadoop的分布式文件系统HDFS而言,一般都是采用冗余存储,冗余因子通常为3,也就是说,一份数据保存三份副本。本教程有两个Slave节点作为数据节点,即集群中有两个数据节点,数据能保存两份,所以 ,dfs.replication的值还是设置为 2。hdfs-site.xml具体内容如下:
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
1.4.4.4修改文件 mapred-site.xml
“/usr/local/hadoop/etc/hadoop”目录下有一个mapred-site.xml.template,需要修改文件名称,把它重命名为mapred-site.xml,然后,把mapred-site.xml文件配置成如下内容:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
</configuration>
1.4.4.5修改文件 yarn-site.xml
请把yarn-site.xml文件配置成如下内容:
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
上述5个文件全部配置完成以后,需要把Master节点上的“/usr/local/hadoop”文件夹复制到各个节点上。如果之前已经运行过伪分布式模式,建议在切换到集群模式之前首先删除之前在伪分布式模式下生成的临时文件。具体来说,需要首先在Master节点上执行如下命令:
cd /usr/local
sudo rm -r ./hadoop/tmp # 删除 Hadoop 临时文件
sudo rm -r ./hadoop/logs/* # 删除日志文件
tar -zcf ~/hadoop.master.tar.gz ./hadoop # 先压缩再复制
cd ~
scp ./hadoop.master.tar.gz Slave1:/home/hadoop
然后在Slave1节点上执行如下命令:
sudo rm -r /usr/local/hadoop # 删掉旧的(如果存在)
sudo tar -zxf /home/hadoop/hadoop.master.tar.gz -C /usr/local
sudo chown -R root /usr/local/hadoop
同样,Slave2节点,也要执行将hadoop.master.tar.gz传输到Slave节点以及在Slave节点解压文件的操作。
scp ./hadoop.master.tar.gz Slave2:/home/hadoop
sudo rm -r /usr/local/hadoop # 删掉旧的(如果存在)
sudo tar -zxf /home/hadoop/hadoop.master.tar.gz -C /usr/local
sudo chown -R root /usr/local/hadoop
首次启动Hadoop集群时,需要先在Master节点执行名称节点的格式化(只需要执行这一次,后面再启动Hadoop时,不要再次格式化名称节点),命令如下:
hdfs namenode -format
现在就可以启动Hadoop了,启动需要在Master节点上进行,执行如下命令:
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver
通过命令jps可以查看各个节点所启动的进程。如果已经正确启动,则在Master节点上可以看到NameNode、ResourceManager、SecondrryNameNode和JobHistoryServer进程,如下图所示。

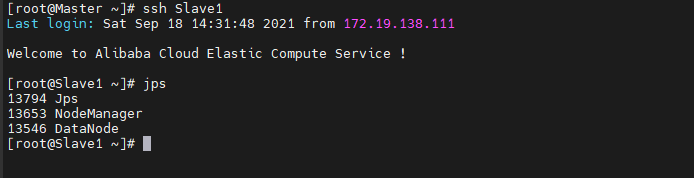
在Slave节点可以看到DataNode和NodeManager进程,如下图所示。
缺少任一进程都表示出错。另外还需要在Master节点上通过命令“hdfs dfsadmin -report”查看数据节点是否正常启动,如果屏幕信息中的“Live datanodes”不为 0 ,则说明集群启动成功。本教程只有2个Slave节点充当数据节点,因此,数据节点启动成功以后,会显示如下图所示信息。

这里再次强调,伪分布式模式和分布式模式切换时需要注意以下事项:
(a)从分布式切换到伪分布式时,不要忘记修改slaves配置文件;
(b)在两者之间切换时,若遇到无法正常启动的情况,可以删除所涉及节点的临时文件夹,这样虽然之前的数据会被删掉,但能保证集群正确启动。所以,如果集群以前能启动,但后来启动不了,特别是数据节点无法启动,不妨试着删除所有节点(包括Slave节点)上的“/usr/local/hadoop/tmp”文件夹,再重新执行一次“hdfs namenode -format”,再次启动即可。
1.4.5执行分布式实例
执行分布式实例过程与伪分布式模式一样,首先创建HDFS上的用户目录,命令如下:
hdfs dfs -mkdir -p /user/hadoop
然后,在HDFS中创建一个input目录,并把“/usr/local/hadoop/etc/hadoop”目录中的配置文件作为输入文件复制到input目录中,命令如下:
hdfs dfs -mkdir /user/hadoop/input
hdfs dfs -put /usr/local/hadoop/etc/hadoop/*.xml /user/hadoop/input
接着就可以运行 MapReduce 作业了,命令如下:
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar grep /user/hadoop/input /user/hadoop/output 'dfs[a-z.]+'
运行时的输出信息与伪分布式类似,会显示MapReduce作业的进度,如下图所示。

执行过程可能会有点慢,但是,如果迟迟没有进度,比如5分钟都没看到进度变化,那么不妨重启Hadoop再次测试。若重启还不行,则很有可能是内存不足引起,建议增大虚拟机的内存,或者通过更改YARN的内存配置来解决。
再用cat命令查看刚刚生成在/user/hadoop/output中的文件内容
hdfs dfs -cat /user/hadoop/output/*

最后,关闭Hadoop集群,需要在Master节点执行如下命令:
stop-yarn.sh
stop-dfs.sh
mr-jobhistory-daemon.sh stop historyserver
1.5基于OSS存储搭建Hadoop集群
1.5.0前面要做的工作

开通OSS功能,创建"hadoop-demo1"bucket,https://oss.console.aliyun.com/bucket/oss-cn-shenzhen/hadoop-demo1/object

下载AccessKey.csv,接下来的步骤会用到。
1.5.1修改配置文件
1.5.1.1修改文件 core-site.xml
切到core-site.xml所在的根目录下,修改core-site.xml:
cd /usr/local/hadoop/etc/hadoop/
vim core-site.xml
core-site.xml文件修改为如下内容:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>hadoop.native.lib</name>
<value>false</value>
<description>Should native hadoop libraries, if present, be used.</description>
</property>
<property>
<name>fs.oss.endpoint</name>
<value>oss-cn-shenzhen-internal.aliyuncs.com</value>
</property>
<property>
<name>fs.oss.accessKeyId</name>
<value>LTAI5tFVBTAG5KtrHCoKaTn2</value>
<description>Aliyun access key ID</description>
</property>
<property>
<name>fs.oss.accessKeySecret</name>
<value>TGEy9IXM62GgdhMcamVCO1mv2WKIQX</value>
<description>Aliyun access key secret</description>
</property>
<property>
<name>fs.oss.impl</name>
<value>org.apache.hadoop.fs.aliyun.oss.AliyunOSSFileSystem</value>
</property>
<property>
<name>fs.oss.buffer.dir</name>
<value>/tmp/oss</value>
</property>
</configuration>
1.5.1.2修改文件 mapred-site.xml
“/usr/local/hadoop/etc/hadoop”目录下有一个mapred-site.xml.template,需要修改文件名称,把它重命名为mapred-site.xml,然后,把mapred-site.xml文件配置成如下内容:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
/usr/local/hadoop/etc/hadoop,
/usr/local/hadoop/share/hadoop/common/*,
/usr/local/hadoop/share/hadoop/common/lib/*,
/usr/local/hadoop/share/hadoop/hdfs/*,
/usr/local/hadoop/share/hadoop/hdfs/lib/*,
/usr/local/hadoop/share/hadoop/mapreduce/*,
/usr/local/hadoop/share/hadoop/mapreduce/lib/*,
/usr/local/hadoop/share/hadoop/yarn/*,
/usr/local/hadoop/share/hadoop/yarn/lib/*,
/usr/local/hadoop/share/hadoop/tools/lib/*
</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>2048</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>2048</value>
</property>
</configuration>
1.5.1.3修改文件 yarn-site.xml
请把yarn-site.xml文件配置成如下内容:
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>Master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>Master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>Master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>Master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>Master:8088</value>
</property>
</configuration>
上述5个文件全部配置完成以后,需要把Master节点上的“/usr/local/hadoop”文件夹复制到各个节点上。如果之前已经运行过伪分布式模式,建议在切换到集群模式之前首先删除之前在伪分布式模式下生成的临时文件。具体来说,需要首先在Master节点上执行如下命令:
cd /usr/local
sudo rm -r ./hadoop/tmp # 删除 Hadoop 临时文件
sudo rm -r ./hadoop/logs/* # 删除日志文件
tar -zcf ~/hadoop.master.tar.gz ./hadoop # 先压缩再复制
cd ~
scp ./hadoop.master.tar.gz Slave1:/home/hadoop
然后在Slave1节点上执行如下命令:
sudo rm -r /usr/local/hadoop # 删掉旧的(如果存在)
sudo tar -zxf /home/hadoop/hadoop.master.tar.gz -C /usr/local
sudo chown -R root /usr/local/hadoop
同样,Slave2节点,也要执行将hadoop.master.tar.gz传输到Slave节点以及在Slave节点解压文件的操作。
scp ./hadoop.master.tar.gz Slave2:/home/hadoop
sudo rm -r /usr/local/hadoop # 删掉旧的(如果存在)
sudo tar -zxf /home/hadoop/hadoop.master.tar.gz -C /usr/local
sudo chown -R root /usr/local/hadoop
启动Hadoop集群时,需要先在Master节点执行名称节点的格式化(只需要执行这一次,后面再启动Hadoop时,不要再次格式化名称节点),命令如下:
hdfs namenode -format
1.5.1.4在master节点上启动集群
在master节点,进入hadoop主目录,启动dfs :
cd $HADOOP_HOME
sbin/start-all.sh
1.5.1.5在master节点上检查dfs能够正常工作
执行如下命令,在hdfs上创建文件夹my-test-dir然后显示和删除该文件夹,均能够返回预期结果:
$HADOOP_HOME/bin/hadoop fs -mkdir /my-test-dir
$HADOOP_HOME/bin/hadoop fs -ls /
$HADOOP_HOME/bin/hadoop fs -rm -r /my-test-dir
1.5.1.6在master节点上检查dfs的基本信息
$HADOOP_HOME/bin/hdfs dfsadmin -report
$HADOOP_HOME/bin/hdfs dfsadmin -report | grep Hostname
能够正确报告文件系统的基本信息和统计信息。
1.5.2验证基于AliyunOSS数据源的Hadoop环境
1.5.2.1在master节点上重启Hadoop
cd /usr/local/hadoop
sbin/stop-all.sh
sbin/start-all.sh
如果能够显示bucket的内容,则表示配置AliyunOSS数据源成功。
$HADOOP_HOME/bin/hadoop fs -ls oss://hadoop-demo1/
$HADOOP_HOME/bin/hadoop fs -mkdir oss://hadoop-demo1/input
$HADOOP_HOME/bin/hadoop fs -ls oss://hadoop-demo1/
$HADOOP_HOME/bin/hadoop fs -put /usr/local/hadoop/README.txt oss://bucket-hadoop/input/README.txt
$HADOOP_HOME/bin/hadoop fs -ls oss://hadoop-demo1/input
运行wordcount进行验证
$HADOOP_HOME/bin/hadoop fs -rm -r oss://hadoop-demo1/output
$HADOOP_HOME/bin/hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.0-beta1.jar wordcount oss://bucket-hadoop/input/README.txt oss://hadoop-demo1/output
$HADOOP_HOME/bin/hadoop fs -cat oss://hadoop-demo1/output/part-r-00000

然后分别执行如下两条命令,如果能够返回相同的统计结果, 则说明基于OSS的Hadoop多机环境下已经成功运行wordcount:
$HADOOP_HOME/bin/hadoop fs -cat oss://hadoop-demo1/output/part-r-00000 | grep hadoop | wc -l
$HADOOP_HOME/bin/hadoop fs -cat oss://hadoop-demo1/input/README.txt | grep hadoop | wc -l

*参考资料
阿里云:低成本基于抢占式ECS实例进行离线大数据分析
阿里云:基于OSS存储搭建Hadoop集群
2.HDFS
2.1常用命令总结
2.1.1目录操作
1.查看hdfs下根目录下的文件
hdfs dfs -ls /
2.查看hdfs某个目录下的所有文件结构
如:查看根目录所有文件结构
hdfs dfs -ls -R /
hdfs dfs -lsr /
如:查看根文件tmp下的所有文件列表
hdfs dfs -ls -R /tmp/
hdfs dfs -lsr /tmp/
3.创建文件夹
如:在根文件的test目录下,创建test2
hdfs dfs -mkdir /test/test2
或者:
hdfs dfs -mkdir hdfs://49.2.1.1/test/test123/
4.创建文件夹 - 递归创建文件夹
hdfs dfs -mkdir -p /test/test3/test4/
5.本地文件移动上传hdfs某个目录
hdfs dfs -moveFromLocal /opt/hadoop/servers/test/hellow.txt /test/test123
6.hfds递归删除
hdfs dfs -rm -r /test
7.hdfs赋予文件夹权限
hdfs dfs -chmod -R -777 /
2.1.2文件操作
1.hdfs文件下载到本地
hdfs dfs -get /test/test123/hellow.txt /opt/hadoop/servers/
2.hdfs内部进行文件移动
hdfs dfs -mv /test/test123/ /test/test2/
3.将本地文件放到hdfs某个目录
hdfs dfs -put /opt/hadoop/servers/test/ /tmp/
4.查看hdfs上某个文件的内容:
hdfs dfs -cat /test/test2/test123/hellow.txt
5.追加一个或者多个文件到hdfs指定文件中.也可以从命令行读取输入
如:追加本地aa.txt 到hdfs 上的 hellow.txt中
hdfs dfs -appendToFile /opt/hadoop/servers/test/aa.txt /test/test2/test123/hellow.txt
如:追加本地bb.txt cc.txt 到hdfs 上的 hellow.txt中:
hdfs dfs -appendToFile /opt/hadoop/servers/test/bb.txt /opt/hadoop/servers/test/cc.txt /test/test2/test123/hellow.txt
6.hdfs间文件拷贝:复制文件(夹),可以覆盖,可以保留原有权限信息
hdfs dfs -cp /test/test2/test123/hellow.txt /test/
7.hdfs删除某个文件
hdfs dfs -rm /test/test2/test123/hellow.txt
2.1.3参数解析
1.get
格式 hdfs dfs -get [-ignorecrc ] [-crc] <src> <localdst>
作用:将文件拷贝到本地文件系统。 CRC 校验失败的文件通过-ignorecrc选项拷贝。 文件和CRC校验和可以通过-CRC选项拷贝
hdfs dfs -get /install.log /export/servers
2.chown
格式: hdfs dfs -chmod [-R] URI[URI ...]
作用: 改变文件的所属用户和用户组。如果使用 -R 选项,则对整个目录有效递归执行。使用这一命令的用户必须是文件的所属用户,或者超级用户。
hdfs dfs -chown -R hadoop:hadoop /install.log
3.Hbase篇
Hbase Web界面:http://evan-virtual-machine:16010/master-status#generaltasks
3.1Zookeeper安装
常用命令
1.1 解压安装包至路径 /usr/local,命令如下:
evan@evan-virtual-machine:~/下载$ sudo tar -zxf apache-zookeeper-3.5.9.tar.gz -C /usr/local
1.2 将解压的文件名apache-zookeeper-3.5.9改为zookeeper,以方便使用,命令如下:
cd /usr/local
sudo mv ./apache-zookeeper-3.5.9 ./zookeeper
把zookeeper目录权限赋予给evan用户
cd /usr/local
sudo chown -R evan ./zookeeper
1.3 配置环境变量
将hbase下的bin目录添加到path中,这样,启动hbase就无需到/usr/local/zookeeper目录下,大大的方便了zookeeper的使用。教程下面的部分还是切换到了/usr/local/zookeeper目录操作,有助于初学者理解运行过程,熟练之后可以不必切换。
编辑~/.bashrc文件
vim ~/.bashrc
如果没有引入过PATH请在~/.bashrc文件尾行添加如下内容:
export ZOOKEEPER_HOME=/usr/local/zookeeper
export PATH=$PATH:/usr/local/zookeeper/bin
1.4 创建配置文件
下载链接:zookeeper-3.5.9
在路径/usr/local/zookeeper/zookeeper-3.5.9/conf下,打开zoo.cfg文件,做以下修改,如果没有先创建空文件zoo.cfg,拷贝zoo_sample.cfg内容到zoo.cfg;
$ sudo cp -v zoo_sample.cfg zoo.cfg
$ sudo vi zoo.cfg # 修改zoo.cfg文件

tickTime = 2000
dataDir=/usr/local/zookeeper
clientPort = 2080
initLimit = 5
syncLimit = 2
修改完zoo.cfg文件后,再切回到zookeeper根目录下创建tmp目录
$ cd /usr/local/zookeeper
$ sudo mkdir tmp
$ sudo chown -R evan tmp
1.5 启动zookeeper
$ ./bin/zkServer.sh start
开启成功后将显示以下内容:

Zookeeper安装参考资料
Zookeeper下载地址:http://mirror.bit.edu.cn/apache/zookeeper/
Zookeeper相关报错
zoo.cfg配置文件时,指定了log的输出目录,但是却未创建,需要mkdir创建。
修改zoo.cfg中的dataDir,替换成dataDir=/usr/local/zookeeper,端口替换成clientPort=2080
HbBase相关报错
HADOOP_ORG.APACHE.HADOOP.HBASE.UTIL.
4.hive篇
Ubuntu安装下载mysql
林子雨:Ubuntu安装MySQL及常用操作
Ubuntu中MySQL的卸载,安装,及安装之后的默认配置修改
报错
mysql出现ERROR1698(28000):Access denied for user root@localhost错误解决方法