目录标题
1. 引言
1.1 FFmpeg简介
FFmpeg是一个自由软件,可以运行音频和视频多种格式的录影、转换、流功能,包含了libavcodec——这是一个用于多个项目中音频和视频的解码器库,以及libavformat——一个音频/视讯封装格式的解码器库。FFmpeg在编程中被广泛应用,它的强大功能使得开发者可以更加方便地处理音视频数据。
在C++领域,我们可以通过调用FFmpeg提供的API,对音视频数据进行各种操作,如解码、编码、转码、滤镜处理等。这使得FFmpeg成为音视频处理领域的重要工具。
1.2 YUV和PCM的基础知识
1.2.1 YUV
YUV是一种颜色编码方法,常用于视频系统。在YUV中,Y代表亮度(Luminance),U和V代表色度(Chrominance)。YUV的设计考虑到了人眼对亮度信息比色度信息更敏感的特性,因此在视频压缩时,可以通过降低色度信息的精度,而保持亮度信息的精度,以实现高效的压缩。
在FFmpeg中,解码后的视频帧数据通常以YUV格式存储。每个像素的颜色信息由一个Y值和一个UV值对表示,其中Y值表示像素的亮度,UV值对表示像素的色度。
1.2.2 PCM
PCM(Pulse Code Modulation,脉冲编码调制)是一种数字表示模拟信号的方法,在音频领域被广泛使用。在PCM中,模拟信号在时间上进行等间隔采样,并将每个采样值量化为数字。PCM数据可以有不同的参数,例如采样率(每秒的样本数)、采样大小(每个样本的位数)、声道数等。
在FFmpeg中,解码后的音频数据通常被存储为PCM数据。每个音频样本的数据由一个或多个PCM值表示,每个PCM值表示在一个特定时间点的音频信号的振幅。
在接下来的章节中,我们将深入探讨YUV和PCM在FFmpeg中的应用,以及如何在C++中使用FFmpeg进行音视频数据的处理。我们将通过实例和源码分析,揭示这些技术背后的原理,并提供一些实用的编程技巧。
2. FFmpeg中的YUV和AVFrame
在FFmpeg中,解码视频后的默认格式是YUV,这个YUV格式的数据是被存储在AVFrame结构体中的。下面我们将详细介绍YUV在FFmpeg中的角色,以及AVFrame的作用和结构。
2.1 YUV在FFmpeg中的角色
YUV是一种颜色编码系统,用于视频系统如电视和计算机图形。在这种格式中,Y是亮度分量(也称为灰度),而U和V是色度分量(代表颜色信息)。在FFmpeg中,解码后的视频数据通常是以YUV格式存储的。
在FFmpeg的解码流程中,解码器将编码的数据(例如,H.264编码的视频流)解码为原始的音频/视频帧,并将这些帧存储在AVFrame结构体中。对于视频,这些帧通常是YUV格式的。
下图是FFmpeg的解码流程:
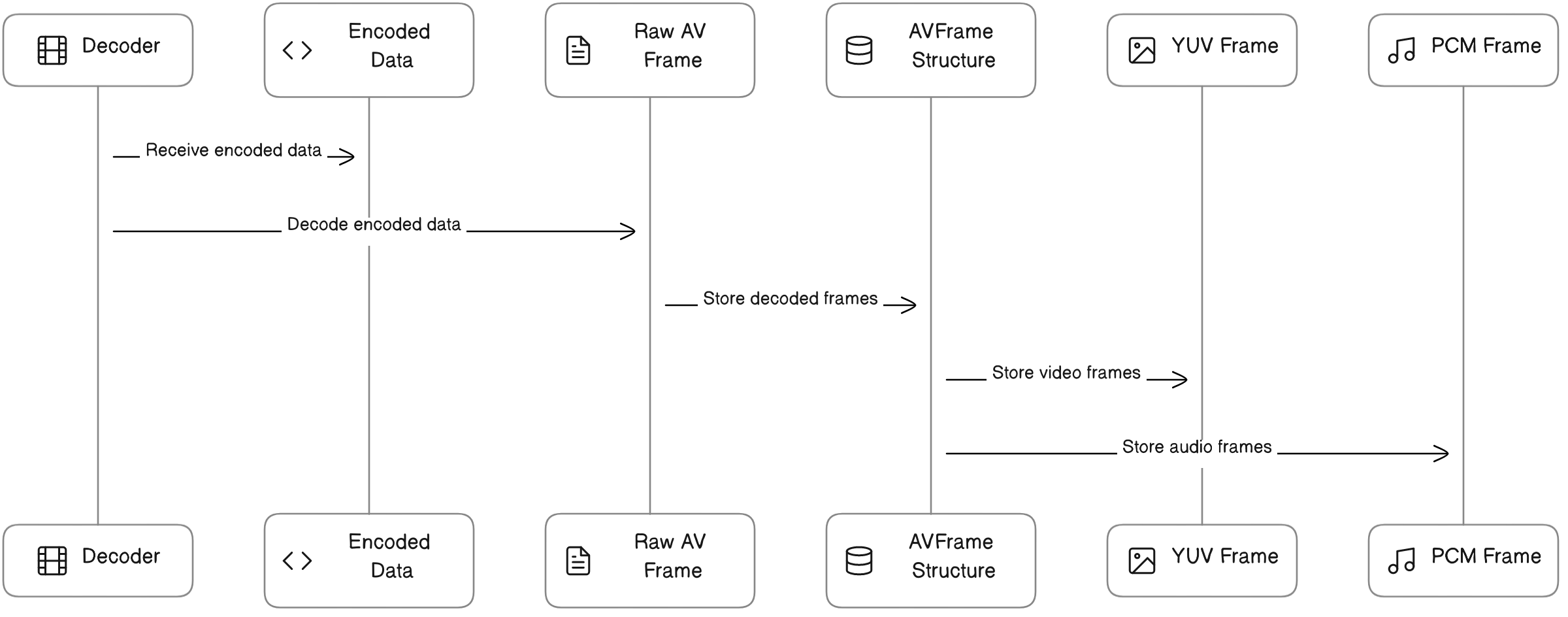
2.2 AVFrame的作用和结构
AVFrame是FFmpeg中用来存储解码后的音频/视频帧的数据结构。AVFrame结构体包含了帧的数据以及一些元数据,例如,帧的宽度和高度(对于视频)、采样率(对于音频)、时间戳(PTS和DTS)等。你可以通过AVFrame的成员变量来访问这些数据和元数据。
在C++中,AVFrame的定义如下:
typedef struct AVFrame {
uint8_t *data[AV_NUM_DATA_POINTERS]; // 指向帧数据的指针数组
int linesize[AV_NUM_DATA_POINTERS]; // 每行数据的大小
...
int width, height; // 帧的宽度和高度
int format; // 帧的格式(例如,YUV420P)
...
int64_t pts, dts; // 时间戳
...
} AVFrame;
在这个结构体中,data数组是指向帧数据的指针,linesize数组是每行数据的大小。width和height是帧的宽度和高度,format是帧的格式,pts和dts是时间戳。
2.3 YUV和AVFrame的关系
当你说“解码后都是AVFrame包”,实际上是指解码后的音频/视频帧被存储在AVFrame结构体中。这并不矛盾,因为AVFrame是用来存储解码后的帧,而这些帧的格式通常是YUV(对于视频)。
在FFmpeg中,解码器将编码的数据解码为原始的音频/视频帧,并将这些帧存储在AVFrame结构体中。对于视频,这些帧通常是YUV格式的。因此,你可以将YUV数据看作是存储在AVFrame中的原始视频数据。
例如,如果你想从AVFrame中获取YUV数据,你可以这样做:
AVFrame *frame = ...; // 已经解码的帧
uint8_t *y_data = frame->data[0]; // Y数据
uint8_t *u_data = frame->data[1]; // U数据
uint8_t *v_data = frame->data[2]; // V数据
在这个例子中,frame->data[0]、frame->data[1]和frame->data[2]分别指向Y、U和V数据。你可以直接使用这些数据,或者将它们转换为其他格式(例如,RGB)。
总的来说,YUV和AVFrame在FFmpeg中的关系是:YUV是解码后的视频数据的格式,而AVFrame是存储这些数据的结构体。
3. YUV数据的处理
在本章中,我们将深入探讨如何在FFmpeg中处理YUV数据。我们将首先讨论如何直接使用YUV数据,然后讨论如何将YUV数据转换为RGB数据,最后讨论如何优化YUV数据的处理。
3.1 YUV数据的直接使用
如果你的显示设备或渲染库可以直接处理YUV格式的数据,那么你可以直接从AVFrame中取出YUV数据进行显示,无需进行任何转换。这种情况下,你的代码可能会类似于以下的样子:
// 假设frame是一个已经解码的AVFrame
AVFrame *frame = ...;
// 获取YUV数据
uint8_t *y_data = frame->data[0];
uint8_t *u_data = frame->data[1];
uint8_t *v_data = frame->data[2];
// 使用YUV数据
display_yuv_data(y_data, u_data, v_data, frame->width, frame->height);
在这个示例中,我们首先从AVFrame中获取YUV数据,然后将这些数据传递给一个名为display_yuv_data的函数,该函数负责将YUV数据显示出来。
3.2 YUV到RGB的转换
然而,许多常见的显示设备和渲染库(例如,SDL、OpenGL)通常只能处理RGB格式的数据。在这种情况下,你需要将YUV数据转换为RGB数据才能进行显示。FFmpeg提供了一个名为swscale的库,可以用来进行这种转换。
以下是一个使用swscale库将YUV数据转换为RGB数据的示例:
// 假设frame是一个已经解码的AVFrame
AVFrame *frame = ...;
// 创建一个新的AVFrame来存储RGB数据
AVFrame *rgb_frame = av_frame_alloc();
rgb_frame->format = AV_PIX_FMT_RGB24;
rgb_frame->width = frame->width;
rgb_frame->height = frame->height;
av_frame_get_buffer(rgb_frame, 0);
// 创建swscale上下文
struct SwsContext *sws_ctx = sws_getContext(
frame->width, frame->height, (AVPixelFormat)frame->format,
rgb_frame->width, rgb_frame->height, (AVPixelFormat)rgb_frame->format,
SWS_BILINEAR, NULL, NULL, NULL);
// 将YUV数据转换为RGB数据
sws_scale(sws_ctx, frame->data, frame->linesize, 0, frame->height, rgb_frame->data, rgb_frame->linesize);
// 使用RGB数据
display_rgb_data(rgb_frame->data[0], rgb_frame->width, rgb_frame->height);
// 释放资源
sws_freeContext(sws_ctx);
av_frame_free(&rgb_frame);
在这个示例中,我们首先创建了一个新的AVFrame来存储RGB数据,然后创建了一个swscale上下文,用于进行YUV到RGB的转换。然后,我们使用sws_scale函数将YUV数据转换为RGB数据,最后将RGB数据显示出来。
3.3 YUV数据的优化策略
YUV到RGB的转换是一个计算密集型的操作,可能会消耗一定的计算资源。因此,如果可能,最好直接使用YUV数据进行显示,以避免这种转换。如果必须进行转换,你可以考虑使用一些优化策略,例如,使用硬件加速、预先转换和缓存转换结果等,以减少转换的开销。
以下是一些可能的优化策略:
-
硬件加速:一些硬件设备(例如,GPU)可以进行高效的YUV到RGB的转换。如果你的环境支持硬件加速,你可以考虑使用硬件加速来进行转换。
-
预先转换:如果你知道你将需要将YUV数据转换为RGB数据,你可以在解码时就进行转换,而不是在显示时才进行转换。这样,你可以在解码和显示之间的空闲时间进行转换,从而减少显示时的延迟。
-
缓存转换结果:如果你需要多次显示同一帧,你可以将转换结果缓存起来,而不是每次显示时都进行转换。这样,你可以避免重复的转换,从而减少计算开销。
以上就是本章的内容,我们详细讨论了如何在FFmpeg中处理YUV数据,包括如何直接使用YUV数据,如何将YUV数据转换为RGB数据,以及如何优化YUV数据的处理。在下一章中,我们将讨论如何在FFmpeg中处理PCM数据。
4. FFmpeg中的PCM和AVFrame
在音频处理中,PCM(Pulse Code Modulation,脉冲编码调制)和AVFrame是两个非常重要的概念。PCM是一种原始的、未压缩的音频数据格式,而AVFrame则是FFmpeg中用来存储解码后的音频/视频帧的数据结构。在本章节中,我们将深入探讨PCM在FFmpeg中的角色,以及如何在AVFrame中处理PCM数据。
4.1 PCM在FFmpeg中的角色
PCM是一种常用的音频数据格式,它是一种未经过压缩的原始音频数据格式。在PCM中,音频信号被分为一系列的样本,每个样本代表了在一个特定时间点的音频信号的振幅。每个样本都被量化为一个特定的数值,然后被编码为二进制数据。PCM数据可以有不同的参数,例如样本率(每秒的样本数)、样本大小(每个样本的位数)、声道数(例如,单声道、立体声)等。
在FFmpeg中,解码后的音频数据通常被存储为PCM数据。这是因为PCM数据是一种原始的、未压缩的音频数据,它可以直接被音频播放设备使用,也可以方便地进行进一步的处理和转换。
4.2 PCM数据在AVFrame中的表现
在FFmpeg中,AVFrame是用来存储解码后的音频/视频帧的数据结构。对于音频数据,AVFrame中的数据指针指向的就是PCM数据。
AVFrame结构体包含了帧的数据以及一些元数据,例如,帧的采样率(对于音频)、时间戳(PTS和DTS)等。你可以通过AVFrame的成员变量来访问这些数据和元数据。
下面是一个简单的示例,展示了如何从AVFrame中取出PCM数据:
// 假设frame是一个已经解码的音频帧
AVFrame *frame = ...;
// 数据指针指向的就是PCM数据
uint8_t *pcm_data = frame->data[0];
// 样本数可以通过nb_samples来获取
int sample_count = frame->nb_samples;
// 样本格式可以通过format来获取
enum AVSampleFormat sample_format = (enum AVSampleFormat)frame->format;
// 根据样本格式,可以知道每个样本的大小
int sample_size = av_get_bytes_per_sample(sample_format);
// 现在,你可以遍历所有的样本
for (int i = 0; i < sample_count; ++i) {
// 根据样本大小,从pcm_data中取出一个样本
uint8_t *sample = pcm_data + i * sample_size;
// 现在,你可以处理这个样本了
// ...
}
在这个示例中,我们首先从AVFrame中取出了PCM数据的指针,然后根据样本数和样本大小,遍历了所有的样本。这就是如何在AVFrame中处理PCM数据的基本方法。
4.3 PCM和AVFrame的关系
从上述内容中,我们可以看到PCM和AVFrame之间的关系:在FFmpeg中,解码后的音频帧被存储在AVFrame结构体中,而这些帧的数据就是PCM数据。因此,当我们说“解码后的音频帧是PCM数据”,实际上是指解码后的音频帧被存储在AVFrame结构体中,而这些帧的数据就是PCM数据。
这种关系可以用下面的图来表示:

在这个图中,我们可以看到PCM数据被存储在AVFrame中,而AVFrame则被用来存储解码后的音频帧。这就是PCM和AVFrame的关系。
在下一章节中,我们将探讨如何处理PCM数据,包括如何从PCM数据中提取样本,以及如何将PCM数据转换为适合音频播放设备的格式。
5. PCM数据的处理
在FFmpeg中,解码后的音频数据通常被存储为PCM数据。PCM(Pulse Code Modulation,脉冲编码调制)是一种常用的音频数据格式,它是一种未经过压缩的原始音频数据格式。在PCM中,音频信号被分为一系列的样本,每个样本代表了在一个特定时间点的音频信号的振幅。每个样本都被量化为一个特定的数值,然后被编码为二进制数据。PCM数据可以有不同的参数,例如样本率(每秒的样本数)、样本大小(每个样本的位数)、声道数(例如,单声道、立体声)等。
5.1 PCM数据的直接使用
在FFmpeg中,你可以直接从AVFrame中取出PCM数据,并将其转换为适合你的音频播放设备的格式。例如,如果你的音频播放设备需要float格式的数据,你可能需要将样本从原始的PCM格式转换为float格式。
下面是一个简单的示例,展示了如何从AVFrame中取出PCM数据,并将其转换为float数组:
// 假设frame是一个已经解码的AVFrame
AVFrame *frame = ...;
// 获取样本大小(以字节为单位)
int sample_size = av_get_bytes_per_sample(frame->sample_format);
// 获取声道数
int channels = frame->channels;
// 创建一个float数组来存储转换后的数据
float *data = new float[frame->nb_samples * channels];
// 遍历每个样本
for (int i = 0; i < frame->nb_samples; i++) {
// 遍历每个声道
for (int ch = 0; ch < channels; ch++) {
// 获取样本数据
uint8_t *sample_data = frame->data[ch] + sample_size * i;
// 根据样本大小和样本格式,将样本数据转换为float
float sample_value;
if (sample_size == 1) {
// 8位样本
sample_value = *sample_data / 255.0f;
} else if (sample_size == 2) {
// 16位样本
sample_value = *((int16_t *)sample_data) / 32767.0f;
} else {
// 其他情况
sample_value = 0.0f;
}
// 存储转换后的样本值
data[i * channels + ch] = sample_value;
}
}
// 现在,data数组中存储的就是转换后的音频数据,可以传输给音频播放设备
这个示例中,我们首先获取了样本大小和声道数,然后创建了一个float数组来存储转换后的数据。然后,我们遍历了每个样本和每个声道,将样本数据从原始的PCM格式转换为float格式,并存储在float数组中。最后,我们可以将这个float数组传输给音频播放设备。
5.2 PCM数据的转换
在处理PCM数据时,你需要根据PCM的参数(例如,样本大小、样本格式、声道布局、声道数)来解释数据,并将样本转换为适合你的音频播放设备的格式。这个过程可能涉及到一些复杂的计算和转换,但是FFmpeg提供了一些工具和函数来帮助你进行这些操作。
例如,FFmpeg提供了一个名为swresample的库,可以用来进行音频重采样和格式转换。你可以使用这个库来将PCM数据转换为其他格式,例如,将16位整数PCM转换为float PCM,或者将立体声PCM转换为单声道PCM。
下面是一个简单的示例,展示了如何使用swresample库来进行PCM数据的转换:
// 假设frame是一个已经解码的AVFrame
AVFrame *frame = ...;
// 创建一个重采样上下文
SwrContext *swr_ctx = swr_alloc_set_opts(NULL,
AV_CH_LAYOUT_MONO, // 输出声道布局:单声道
AV_SAMPLE_FMT_FLT, // 输出样本格式:float
44100, // 输出样本率:44100Hz
frame->channel_layout, // 输入声道布局
frame->format, // 输入样本格式
frame->sample_rate, // 输入样本率
0, NULL);
if (!swr_ctx) {
// 错误处理
}
// 初始化重采样上下文
if (swr_init(swr_ctx) < 0) {
// 错误处理
}
// 创建一个新的AVFrame来存储转换后的数据
AVFrame *out_frame = av_frame_alloc();
out_frame->channel_layout = AV_CH_LAYOUT_MONO;
out_frame->format = AV_SAMPLE_FMT_FLT;
out_frame->sample_rate = 44100;
out_frame->nb_samples = frame->nb_samples;
// 假设输出样本数和输入样本数相同
// 分配数据缓冲区
av_frame_get_buffer(out_frame, 0);
// 进行重采样
if (swr_convert(swr_ctx, out_frame->data, out_frame->nb_samples, (const uint8_t **)frame->data, frame->nb_samples) < 0) {
// 错误处理
}
// 现在,out_frame中存储的就是转换后的音频数据,可以传输给音频播放设备
// 释放资源
swr_free(&swr_ctx);
av_frame_free(&out_frame);
这个示例中,我们首先创建了一个重采样上下文,并设置了输入和输出的参数。然后,我们创建了一个新的AVFrame来存储转换后的数据,并分配了数据缓冲区。然后,我们调用swr_convert函数进行重采样。最后,我们释放了重采样上下文和AVFrame。
5.3 PCM数据处理流程图
下面的流程图展示了PCM数据的处理流程:
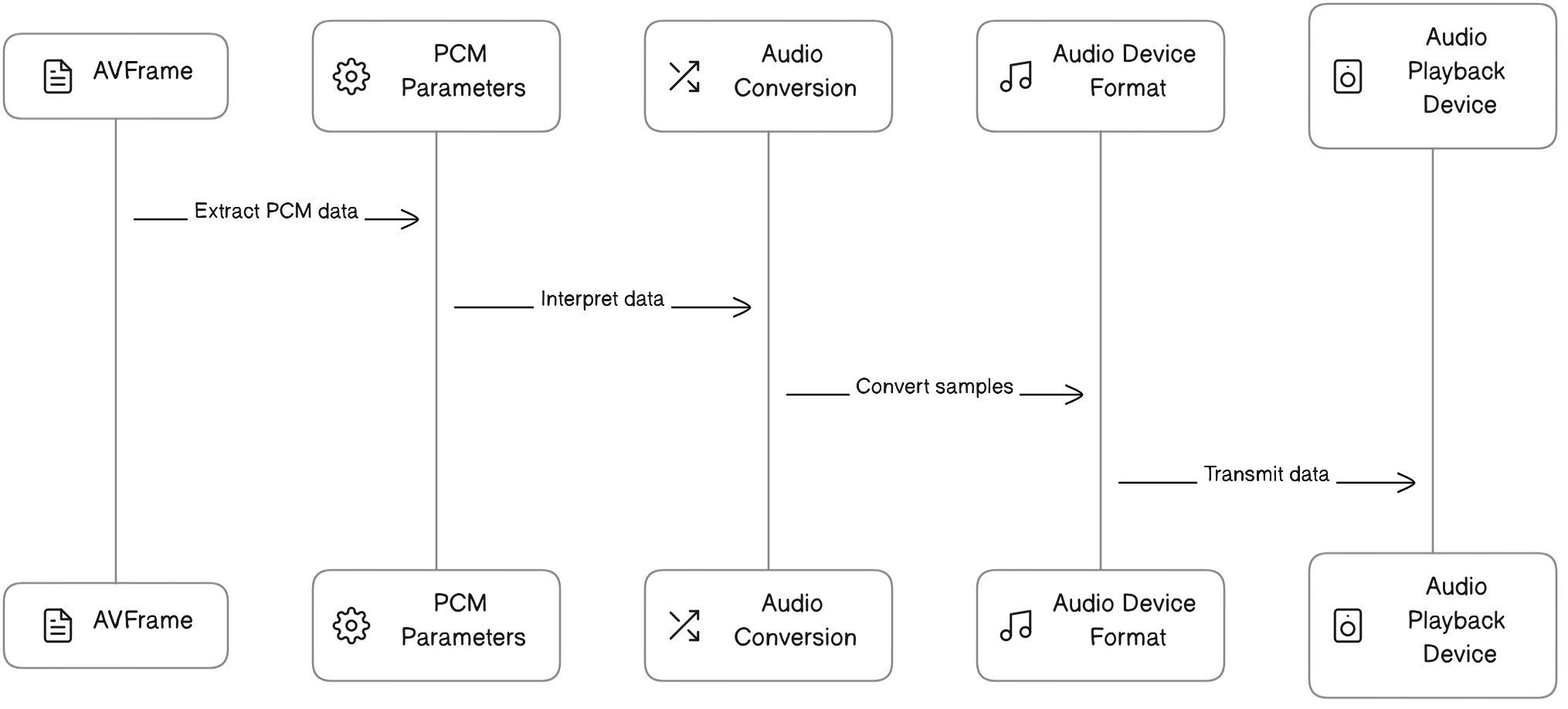
在这个流程中,我们首先从AVFrame中取出PCM数据,然后根据PCM参数(样本大小、样本格式、声道布局、声道数)解释数据,然后将样本转换为适合音频播放设备的格式,最后将数据传输给音频播放设备。
5.4 PCM数据处理方法对比
下面的表格总结了处理PCM数据的一些常用方法的对比:
| 方法 | 优点 | 缺点 |
|---|---|---|
| 直接使用PCM数据 | 简单,不需要额外的转换 | 可能需要手动处理样本大小和样本格式的转换 |
使用swresample库进行转换 |
可以处理复杂的转换,例如声道布局的转换和样本格式的转换 | 需要创建和管理重采样上下文,可能需要处理错误 |
在选择处理PCM数据的方法时,你需要根据你的需求和音频播放设备的能力来选择最适合的方法。
6. 视频编码中的I帧、P帧和B帧
在本章中,我们将深入探讨视频编码中的I帧、P帧和B帧。这些帧类型是视频编码中的基础概念,理解它们对于理解视频编码和解码的过程至关重要。
6.1 I帧、P帧和B帧的定义和特性
在视频编码中,我们通常会遇到I帧(Intra-coded picture)、P帧(Predicted picture)和B帧(Bidirectionally predicted picture)这三种类型的帧。它们的定义和特性如下:
-
I帧:也被称为关键帧,是自我完整的帧,不依赖于任何其他帧进行解码。I帧通常包含了图像的全部信息,因此在视频中的数据量最大。
-
P帧:依赖于前面的I帧或P帧进行解码,它只存储与参考帧的差异信息。P帧的数据量通常小于I帧,因为它只包含差异信息。
-
B帧:依赖于前面和后面的I帧或P帧进行解码,它只存储与前后参考帧的差异信息。B帧的数据量通常是最小的,因为它只包含差异信息。
下表总结了这三种帧类型的主要特性:
| 帧类型 | 完整性 | 依赖性 | 数据量 |
|---|---|---|---|
| I帧 | 完整的 | 无依赖 | 最大 |
| P帧 | 差异的 | 有依赖 | 中等 |
| B帧 | 差异的 | 有依赖 | 最小 |
6.2 I帧、P帧和B帧在编码和解码中的作用
在视频编码中,I帧、P帧和B帧的主要作用是通过存储差异信息来减少数据量,从而实现视频的压缩。
例如,假设我们有一个视频序列,其中包含10帧图像。如果我们将每一帧都作为I帧进行编码,那么每一帧都需要存储完整的图像信息,这将产生大量的数据。然而,如果我们将第一帧作为I帧,然后将后续的帧作为P帧或B帧,那么后续的帧只需要存储与前一帧的差异信息,这将大大减少数据量。
在解码时,解码器会首先解码I帧,然后根据P帧和B帧的差异信息来恢复出原始的图像序列。
6.3 I帧、P帧和B帧与YUV、PCM的关系
I帧、P帧和B帧是描述帧之间的依赖关系和压缩方式的概念,而YUV和PCM则是描述帧的颜色和音频信息的方式。
在视频编码中,每一帧的图像信息通常以YUV格式存储,而音频信息则以PCM格式存储。然后,这些帧会根据它们之间的依赖关系和差异信息,被编码为I帧、P帧或B帧。
在解码后,无论原来是I帧、P帧还是B帧,都已经被转换成了完整的图像数据,可以用YUV或RGB等颜色空间来表示。这些解码后的帧都是可以独立显示的,不再依赖于其他帧。
下面是一个简单的示例,展示了如何使用FFmpeg库来解码视频帧,并获取YUV数据:
extern "C" {
#include <libavcodec/avcodec.h>
#include <libavformat/avformat.h>
}
int main() {
AVFormatContext *pFormatCtx = avformat_alloc_context();
// 打开视频文件
if(avformat_open_input(&pFormatCtx, "input.mp4", NULL, NULL)!=0)
return -1;
// 查找视频流
if(avformat_find_stream_info(pFormatCtx, NULL)<0)
return -1;
// 找到视频流的编码器
AVCodecContext *pCodecCtx = pFormatCtx->streams[0]->codec;
AVCodec *pCodec = avcodec_find_decoder(pCodecCtx->codec_id);
if(pCodec==NULL)
return -1;
// 打开编码器
if(avcodec_open2(pCodecCtx, pCodec, NULL)<0)
return -1;
// 分配视频帧
AVFrame *pFrame = av_frame_alloc();
// 读取视频帧
AVPacket packet;
while(av_read_frame(pFormatCtx, &packet)>=0) {
if(packet.stream_index == 0) {
// 解码视频帧
int got_picture;
avcodec_decode_video2(pCodecCtx, pFrame, &got_picture, &packet);
if(got_picture) {
// 此时,pFrame中的数据就是YUV数据
// 可以对这些数据进行进一步的处理
}
}
av_packet_unref(&packet);
}
// 释放资源
av_frame_free(&pFrame);
avcodec_close(pCodecCtx);
avformat_close_input(&pFormatCtx);
return 0;
}
在这个示例中,我们首先打开了一个视频文件,然后找到了视频流的编码器。然后,我们读取了视频帧,并使用编码器将它们解码为YUV数据。这些YUV数据可以用于进一步的处理,例如转换为RGB数据,或者进行图像分析等。
希望这个章节能帮助你更深入地理解视频编码中的I帧、P帧和B帧,以及它们与YUV和PCM的关系。在下一章中,我们将探讨视频数据的采集和处理。
7. 视频数据的采集和处理
在本章中,我们将深入探讨视频数据的采集和处理过程,包括视频数据的采集方式,YUV和RGB在视频数据处理中的应用,以及视频数据的最小单位——帧。
7.1 视频数据的采集过程
视频数据的采集通常由摄像头完成。摄像头捕获的原始视频数据通常是以YUV格式存储的。YUV是一种颜色编码系统,用于视频系统如电视和计算机图形。在这种格式中,Y是亮度分量(也称为灰度),而U和V是色度分量(代表颜色信息)。
在摄像头捕获图像时,图像的每个像素首先被转换为RGB格式,然后通常被转换为YUV格式。这是因为YUV格式有一些优点,例如它可以更有效地进行视频压缩,因为人眼对亮度信息(Y分量)比色度信息(U和V分量)更敏感,所以可以在保持视觉质量的同时减少色度信息的精度。
然而,尽管YUV是一种常见的视频数据格式,但并不是所有的摄像头都直接输出YUV数据。有些摄像头可能会输出其他格式的数据,例如RGB或者直接输出压缩后的数据(例如JPEG或H.264)。具体的输出格式取决于摄像头的硬件和驱动程序。
7.2 YUV和RGB在视频数据处理中的应用
YUV和RGB是两种不同的颜色空间。RGB是基于颜色光的三原色(红、绿、蓝)来描述颜色的,每个像素的颜色由这三种颜色的强度组合而成。而YUV则是将颜色信息分为亮度信息(Y)和色度信息(UV),这种方式更接近人眼对颜色的感知方式,因此在视频编码和传输中更常用。
在处理视频数据时,可能需要根据具体的需求和环境,选择合适的颜色模型。例如,如果你的显示设备或者渲染库可以直接处理YUV格式的数据,那么你可以直接从AVFrame中取出YUV数据进行显示,无需进行任何转换。然而,许多常见的显示设备和渲染库(例如,SDL、OpenGL)通常只能处理RGB格式的数据。在这种情况下,你需要将YUV数据转换为RGB数据才能进行显示。
在C++中,我们可以使用FFmpeg提供的swscale库来进行这种转换。以下是一个简单的示例:
// 创建一个swsContext,用于YUV到RGB的转换
struct SwsContext* sws_ctx = sws_getContext(width, height, AV_PIX_FMT_YUV420P,
width, height, AV_PIX_FMT_RGB24,
SWS_BILINEAR, NULL, NULL, NULL);
if (!sws_ctx) {
// 错误处理
}
// 创建一个AVFrame,用于存储RGB数据
AVFrame* rgb_frame = av_frame_alloc();
if (!rgb_frame) {
// 错误处理
}
rgb_frame->format = AV_PIX_FMT_RGB24;
rgb_frame->width = width;
rgb_frame->height = height;
// 分配RGB数据的内存
int ret = av_frame_get_buffer(rgb_frame, 0);
if (ret < 0) {
// 错误处理
}
// 将YUV数据转换为RGB数据
sws_scale(sws_ctx, yuv_frame->data, yuv_frame->linesize, 0, height,
rgb_frame->data, rgb_frame->linesize);
// 此时,rgb_frame中存储的就是RGB数据,可以直接用于显示
在这个示例中,我们首先创建了一个swsContext,用于YUV到RGB的转换。然后,我们创建了一个AVFrame,用于存储RGB数据,并分配了相应的内存。最后,我们使用sws_scale函数将YUV数据转换为RGB数据。此时,rgb_frame中存储的就是RGB数据,可以直接用于显示。
7.3 视频数据的最小单位:帧
在视频中,帧(Frame)是最小的独立单位,每一帧都代表了一个独立的图像。在处理视频数据时,我们通常需要处理一系列的视频帧,每一帧都是一个独立的YUV或RGB图像。
在FFmpeg中,每一帧的数据被存储在一个AVFrame结构体中。AVFrame结构体包含了帧的数据以及一些元数据,例如,帧的宽度和高度、时间戳(PTS和DTS)等。你可以通过AVFrame的成员变量来访问这些数据和元数据。
在处理视频帧时,我们通常需要遍历每一帧,对每一帧进行相应的处理。以下是一个简单的示例:
// 创建一个AVFrame,用于存储解码后的帧
AVFrame* frame = av_frame_alloc();
if (!frame) {
// 错误处理
}
// 循环读取和解码帧
while (1) {
// 读取一帧
int ret = av_read_frame(format_ctx, &pkt);
if (ret < 0) {
// 错误处理
}
// 判断是否是我们需要的视频流
if (pkt.stream_index == video_stream_index) {
// 解码帧
ret = avcodec_send_packet(codec_ctx, &pkt);
if (ret < 0) {
// 错误处理
}
while (ret >= 0) {
ret = avcodec_receive_frame(codec_ctx, frame);
if (ret == AVERROR(EAGAIN) || ret == AVERROR_EOF) {
break;
} else if (ret < 0) {
// 错误处理
}
// 此时,frame中存储的就是解码后的帧,可以进行相应的处理
// 例如,你可以将帧的数据转换为RGB格式,然后显示出来
}
}
// 释放pkt
av_packet_unref(&pkt);
}
// 释放frame
av_frame_free(&frame);
在这个示例中,我们首先创建了一个AVFrame,用于存储解码后的帧。然后,我们进入一个循环,不断地读取和解码帧。对于每一帧,我们首先判断它是否是我们需要的视频流,如果是,我们就进行解码,并对解码后的帧进行相应的处理。最后,我们释放了pkt和frame。
这就是视频数据的采集和处理的基本过程。在下一章中,我们将讨论音频数据的采集和处理。
8. 音频数据的采集和处理
在本章中,我们将深入探讨音频数据的采集和处理过程。我们将从音频数据的采集开始,然后讨论PCM(Pulse Code Modulation,脉冲编码调制)在音频数据处理中的应用,最后我们将探讨音频数据的最小单位:样本。
8.1 音频数据的采集过程
音频数据的采集过程可以分为以下几个步骤:
- 音频采集设备(如麦克风)首先将声音(这是一种模拟信号)转换为电信号。
- 通过模数转换器(ADC,Analog-to-Digital Converter)将电信号转换为数字信号。这个数字信号就是 PCM 数据。
下图展示了音频采集的过程:
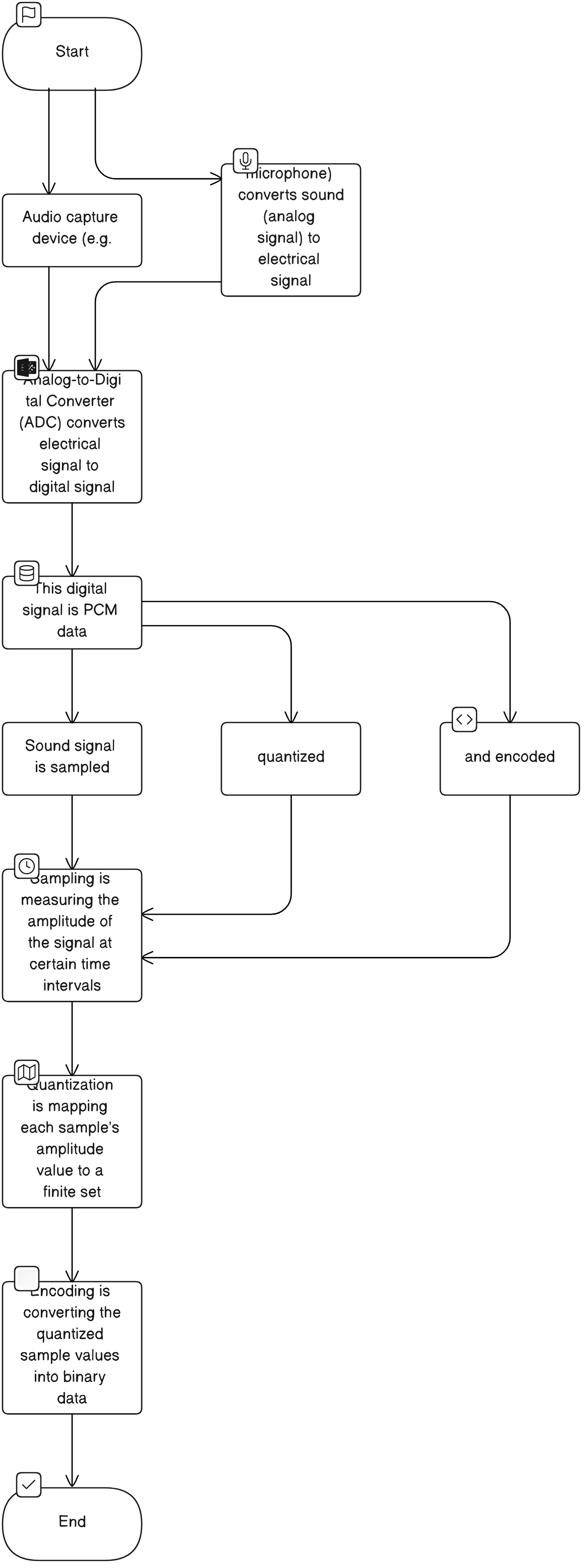
在这个过程中,声音信号会被样本化(sampling),量化(quantization),并编码(encoding):
-
样本化是指在一定的时间间隔内测量信号的振幅。样本化的频率(即每秒的样本数)通常被称为采样率(sample rate)。常见的采样率包括 44.1 kHz(CD 质量)和 48 kHz(DVD 质量)。
-
量化是指将每个样本的振幅值映射到一个有限的集合。量化的精度(即振幅值的可能数)通常被称为位深(bit depth)。常见的位深包括 16 位(CD 质量)和 24 位(高分辨率音频)。
-
编码是指将量化后的样本值转换为二进制数据。
这个过程会生成 PCM 数据,这是一种原始的、未压缩的音频数据格式。
8.2 PCM在音频数据处理中的应用
在音频数据处理中,PCM(Pulse Code Modulation,脉冲编码调制)是一种常用的音频数据格式。PCM 是一种未经过压缩的原始音频数据格式。在 PCM 中,音频信号被分为一系列的样本,每个样本代表了在一个特定时间点的音频信号的振幅。
在 FFmpeg 中,解码后的音频数据通常被存储为 PCM 数据。AVFrame 中的数据指针指向的就是这些 PCM 数据。你可以直接从 AVFrame 中取出这些数据,并将其转换为适合你的音频播放设备的格式(例如,float 数组)。
在处理 PCM 数据时,你需要知道以下的参数:
-
样本大小:这决定了每个样本的位数。例如,如果样本大小为 16 位,那么你需要每 16 位取出一个样本。
-
样本格式:这决定了样本的表示方式。例如,样本可以是有符号的整数、无符号的整数、浮点数等。
-
声道布局:这决定了多声道音频中各个声道的顺序。例如,对于立体声音频,声道布局可以是左声道在前,右声道在后,也可以是右声道在前,左声道在后。
-
声道数:这决定了每个立体声样本中包含的声道数。例如,对于立体声音频,声道数为 2。
你需要根据这些参数,正确地从 AVFrame 的数据指针中取出样本,并将样本转换为适合你的音频播放设备的格式。例如,如果你的音频播放设备需要 float 格式的数据,你可能需要将样本从原始的 PCM 格式转换为 float 格式。
8.3 音频数据的最小单位:样本
在音频数据中,样本(Sample)是最小的独立单位。在 PCM 中,音频信号被分为一系列的样本,每个样本代表了在一个特定时间点的音频信号的振幅。样本的数量、大小和格式都会影响音频的质量和特性。
样本的数量,也就是采样率,决定了音频的频率响应。根据奈奎斯特定理,采样率必须至少是音频信号最高频率的两倍,才能无失真地重建音频信号。因此,对于人耳能听到的最高频率(大约 20 kHz),CD 的采样率为 44.1 kHz,这是足够的。
样本的大小,也就是位深,决定了音频的动态范围。位深越大,动态范围越大,音频信号的细节就越丰富。例如,16 位的位深可以提供大约 96 dB 的动态范围,而 24 位的位深可以提供大约 144 dB 的动态范围。
样本的格式,例如有符号的整数、无符号的整数、浮点数等,决定了样本的表示方式。不同的样本格式可能需要不同的处理方式。
在处理音频数据时,理解样本的概念是非常重要的。只有正确地处理样本,才能正确地处理音频数据。
结语
FFmpeg在音视频处理中的重要性
FFmpeg是一个强大的音视频处理库,它提供了一套完整的工具和API,可以用来进行音视频的编解码、转码、流化等操作。在C/C++和嵌入式领域,FFmpeg是音视频处理的首选工具。
FFmpeg的强大之处在于它的灵活性和功能性。它支持大量的音视频编解码器,可以处理几乎所有的音视频格式。它的API设计得非常灵活,可以满足各种复杂的音视频处理需求。
在实际应用中,我们可以使用FFmpeg进行各种音视频处理任务,例如:
解码视频文件,获取原始的YUV数据
将YUV数据转换为RGB数据,以便在计算机屏幕上显示
解码音频文件,获取原始的PCM数据
将PCM数据转换为其他格式,以便在音频设备上播放
编码YUV或PCM数据,生成视频或音频文件
将一个音视频格式转换为另一个格式(转码)
将音视频数据流化,以便进行网络传输
在使用FFmpeg时,我们需要了解一些关键的概念和技术,例如YUV、PCM、I帧、P帧和B帧等。这些概念和技术是音视频处理的基础,理解它们对于有效地使用FFmpeg非常重要。
在我们的编程学习之旅中,理解是我们迈向更高层次的重要一步。然而,掌握新技能、新理念,始终需要时间和坚持。从心理学的角度看,学习往往伴随着不断的试错和调整,这就像是我们的大脑在逐渐优化其解决问题的“算法”。
这就是为什么当我们遇到错误,我们应该将其视为学习和进步的机会,而不仅仅是困扰。通过理解和解决这些问题,我们不仅可以修复当前的代码,更可以提升我们的编程能力,防止在未来的项目中犯相同的错误。
我鼓励大家积极参与进来,不断提升自己的编程技术。无论你是初学者还是有经验的开发者,我希望我的博客能对你的学习之路有所帮助。如果你觉得这篇文章有用,不妨点击收藏,或者留下你的评论分享你的见解和经验,也欢迎你对我博客的内容提出建议和问题。每一次的点赞、评论、分享和关注都是对我的最大支持,也是对我持续分享和创作的动力。
阅读我的CSDN主页,解锁更多精彩内容:泡沫的CSDN主页
