文本生成的解码/采样策略总结
文章目录
在 自然语言生成(Natural Language Generation, NLG)任务中,训练完成之后,通常需要根据已有的输入tokens 序列来预测下一个 token 在词表(vocabulary)上的条件概率分布,再从条件概率分布中搜索或采样出下一个 token。生成的 token 作为输入序列的一部分,进入到模型中,最终生成所需要的完整句子,即自回归生成。文本生成任务中,采样方法的选择决定了生成文本的质量。
文本生成中的采样策略主要可以分为两大类:
-
贪婪采样(Argmax Decoding):主要包括beam search, class-factored softmax等。
-
随机采样(Stochastic Decoding):主要包括temperature sampling, top-k sampling等。
-
两类decoding strategy的主要区别就在于,如何从vocabulary probability distribution中选取一个词 :
- 贪婪采样的做法是选择词表中probability最大的词 ;这种方式能得到机器认为的所谓的最优解,但是容易生成重复的、可预测的词。句子/语言的连贯性差。
- 随机采样则是基于概率分布随机sample一个词。采样的依据就是解码器输出的词典中每个词的概率分布。相比于按概率“掐尖”,这样会增大所选词的范围,引入更多的随机性。但是这种方法生成的句子容易不连贯,上下文比较矛盾。容易出现奇怪的句子,出现罕见词。
1. Greedy Search
核心思想
即局部最优的贪心搜索方法,每一步都选择概率最大的token进行输出,最后组成整个句子。
优缺点
- 优点:计算速度快,方法简单。
- 缺点:局部最优并不等于全局最优,某一步选错,后续生成的可能也都是错的。总是选择概率最大的词,很可能会生成重复无意义的句子( get stuck in loops),例如“I don’t know. I don’t know. I don’t know. I don’t know“.
代码实现
def greedy_search(prob):
return np.argmax(prob)
2. Beam Search
核心思想
束搜索,返回一系列最有可能的输出序列。在第 t t t步时,生成第 t + 1 t+1 t+1步所有可能组合,并从中选取K个概率最大的组合,其中K为指定的搜索参数,即beam_size,束宽。当K=1时,该算法即退化为greedy search。每个时间步保留 beam_size个最大的可能取值路径。假设词典大小为V,beam_size 为K,则每个时间步生成的候选路径有K∗V个,保留其中概率最大的K个路径,再进入下一个时间步的搜索中。
图解
如图所示,beam_size=2。

- 在第一个时间步,A和C是最优的两个,因此得到了两个结果[A],[C],其他三个就被抛弃了;
- 第二步会基于这两个结果继续进行生成,在A这个分支可以得到5个候选词,[AA],[AB],[AC],[AD],[AE],C也同理得到5个,此时会对这10个进行统一排序,再保留最优的两个,即图中的[AB]和[CE];
- 第三步同理,也会从新的10个候选词里再保留最好的两个,最后得到了[ABD],[CED]两个结果。 可以发现,beam search在每一步需要考察的候选词数量是贪心搜索的beam_size倍,因此是一种牺牲时间换性能的方法
优缺点
- 优点:平衡了Greedy Search和暴力穷举搜索,在时间复杂度和模型最优解之间取平衡。
- 缺点:由于每一步比较的概率是路径上每个时间步概率的乘积,因此Beam Search倾向于生成较短的句子。另外,在生成模型中,利用Greedy Searc 或Beam Search都是根据概率最大化的原则生成文本,相比人正常对话的句子,这些生成的文本缺乏多样性和意外性。通过后文中阐述的采样方法可以在一定程度上解决这一问题。
- 算法复杂度:O(B * V * L),B为束宽,V为词表大小,L为生成序列长度。
Beam size设置
-
B越大
优点:可考虑的选择越多,能找到的句子越好。
缺点:计算代价更大,速度越慢,内存消耗越大。
-
B越小
优点:计算代价小,速度快,内存占用越小。
缺点:可考虑的选择变少,结果没那么好。
问题及解决
数据下溢(numerical underflow)
-
解释:求序列概率的时候,序列概率是多个条件概率的乘积,每个概率都小于1甚至远远小于1,很多概率相乘起来,会得到很小很小的数字,会造成数据下溢,即数值太小,计算机的浮点表示不能精确储存。
-
解决:因此我们不会最大化这个乘积,而是取log值,对数函数是严格单调递增函数,取log不会影响排序结果,但是在数值上会更稳定,不容易出现数据下溢。
倾向于生成短的序列
-
解释:原目标函数是很多个单词条件概率的乘积,因为每个都远小于1,则相乘之后结果会更小。如果句子很长的话,会得到一个非常小的概率值,所以这种目标函数会更偏向于短的输出。因为短句子的概率是由更少数量的小于1的数字乘积得到的。取log后结果一样,因为概率小于1,则取log后是负值,加起来的数字的越多,得到的结果就越小。
-
解决:归一化对数似然函数(length normalization),最简单的方法,对于概率值相乘(或者对数概率相加)的结果,除以序列长度 L L L,这样就很明显的缓解了长句子输出概率低的问题 。实践中,通常采用更柔和的方法,在 L L L 上加上指数 a ∈ ( 0 , 1 ) a∈(0,1) a∈(0,1),即 L a L^a La ,例如 a = 0.7 a=0.7 a=0.7。如果 a = 1 , L a = L a=1,L^a=L a=1,La=L就相当于完全用长度来归一化;如果 a = 0 a=0 a=0, L a = 1 L^a=1 La=1 就相当于完全没有归一化, a ∈ ( 0 , 1 ) a∈(0,1) a∈(0,1)就是在完全归一化和没有归一化之间。
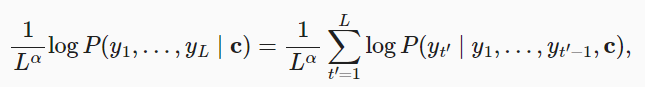
单一性问题
-
解释:输出的beam_size个句子的差异性很小,无法体现语言的多样性(比如文本摘要、机器翻译的生成文本,往往有不止一种表述方式)
-
解决:分组,加入相似性惩罚,参考论文diverse beam search,accepted at AAAI 2018。
应用场景
Beam Search(集束搜索)多用在一些大型系统中,比如机器翻译系统,语音识别系统等,因为这些系统中的数据集可能非常大,而且结果也没有唯一正确的解,系统用最快的方式找到最接近正确的解才是系统的目标。
代码实现
def beam_search(probs, k):
sequences = [[list(), 0.0]]
# 迭代序列中的每一步
for prob in probs:
all_candidates = list()
# 遍历候选序列
for i in range(len(sequences)):
# 序列,概率得分
seq, score = sequences[i]
# 遍历当前候选序列、当前时间步的词典概率分布
for j in range(len(prob)):
# 这里取log,是为了防止数据下溢。因为概率小于1,取log小于0,相减后得正。
candidate = [seq + [j], score - log(prob[j])]
all_candidates.append(candidate)
# 对所有的候选序列,通过score排序;
# 这里sorted函数默认是升序排序
ordered = sorted(all_candidates, key=lambda tup: tup[1])
# 选择K个score最低的,因为上面取log然后取负之后概率大的值变小,所以score低的概率反而大。
sequences = ordered[:k]
return sequences
3. Temperature Sampling
核心思想
对于随机采样,如果按照全体词的概率分布来进行采样,还是有可能生成低概率的单词,导致生成的句子出现语法或语义错误。通过在 softmax函数中加入Temperature参数(对logist操作),强化顶部词的生成概率,在一定程度上可以解决这一问题。
p ( i ) = ∑ k = 1 K e z k T e z i T p(i)=\frac{\sum_{k=1}^K e^\frac{z_k}{T}}{e^{\frac{z_i}{T}}} p(i)=eTzi∑k=1KeTzk
Temperature参数分析
-
当T<1时,将会增加顶部词的生成概率,且T越小,越倾向于使用Greedy Search的方法生成下一个词;小的temperature 会引发极大的repetitive 和predictable文本,但是文本内容往往更贴合语料(highly realistic),基本所有的词都来自与语料库。
-
当T>1时,将会增加底部词的生成概率,且T越大,越倾向于从均匀分布中生成下一个词,分布变得更加平缓,生成的文本更具有随机性(random)、趣味性( interesting),甚至创造性( creative);甚至有些时候能发现一些新词(misspelled words) 。当设置高temperature时,文本局部结构往往会被破坏,大多数词可能会是semi-random strings的形式。
实际应用中,可以使用多个T进行实验,当保持了一定的随机性又能不破坏结构时,往往会得到有意思的生成文本。
优缺点
优点:生成的文本具有多样性和随机性。
缺点:T值的选择需要依赖于经验或调参。
代码实现
def temperature_sampling(prob, T=0.2):
def softmax(z):
return np.exp(z) / sum(np.exp(z))
# logstic
log_prob = np.log(prob)
# 联合温度系数softmax归一化
reweighted_prob = softmax(log_prob / T)
# 样本空间
sample_space = list(range(len(prob)))
# 根据p的概率分布在样本空间中随机采样,第一种方式是使用多项式分布采样
# temperature_sample = np.random.multinomial(1, reweighted_prob, 1)
temperature_sample = np.random.choice(sample_space, p=reweighted_prob)
return temperature_sample
4. Top-K Sampling
核心思想
在Temperature Sampling的过程中,即便选取了合适的 T T T 值,还是会有较低的可能性生成低概率的单词。应用Top-K或Top-P的方法,可以根据概率分布情况,预先挑选出一部分概率高的单词,然后再对这部分单词进行采样,从而避免低概率词的出现。
Top-K是直接挑选概率最高的K个单词,然后重新根据softmax计算这K个单词的概率(redistributed),再根据概率分布情况进行采样,生成下一个单词。Top-k采样也可以结合Temperature Sampling方法。
优缺点和K值的选取
-
优点:可以避免低概率词的生成,基本top-k的采样方法,能够提升生成质量,因为它会把概率较低的结果丢弃(removing the tail),因此能使得生成过程不那么偏离主题。
-
缺点:K值的选择需要依赖于经验或调参。比如,在较为狭窄的分布中,选取较小的K值;在较为宽广的分布中,选取较大的K值。但是一些情况下,丢弃掉的部分(Tail)可能会包含很多的词语,这导致我们能选择的词汇较少。而在另一些情况下,丢弃掉大部分可能包含的词汇较少,我们能生成较为丰富的文本。
代码实现
def top_k(prob, k=5):
def softmax(z):
return np.exp(z) / sum(np.exp(z))
# 以p为key对分布进行降序排序
topk = sorted([(p, i) for i, p in enumerate(prob)], reverse=True)[:k]
k_prob = [p for p, i in topk]
k_prob = softmax(np.log(k_prob))
k_idx = [i for p, i in topk]
return k_idx, k_prob, np.random.choice(k_idx, p=k_prob)
5. Top-P Sampling(Nucleus Sampling )
核心思想
与Top-K采样对低概率词汇直接丢弃的处理方法不同,top-p采用的是累计概率的方式。
Top-P Sampling (Nucleus sampling) 是预先设置一个概率界限值p,然后将所有可能取到的单词,根据概率大小从高到低排列,依次选取单词。当单词的累积概率大于或等于p值时停止,然后从已经选取的单词中进行采样,生成下一个单词。采样同样可以结合Temperature采样方法。根据参数p的大小调节(0<=p<=1), Top-P采样增大了出现概率较小的词汇的生成的概率。
分析
这种方法来自于论文:The Curious Case of Neural Text Degeneration
这是这篇论文提出的方式,也是相比前面那些都更好的采样方式,这个方法不再取一个固定的k,而是固定候选集合的概率密度和在整个概率分布中的比例。也就是构造一个最小候选集V ,使得
∑ x ∈ V p ( x ) > p \sum_{x∈V} p(x) > p x∈V∑p(x)>p
优点
- 在不同的时间步,随着解码词的概率分布不同,候选词集合的大小会动态变化,相较于top-k采样更加灵活;
- 由于解码词还是从头部候选集中筛选,这样根据概率动态调整的方式可以使生成的句子在满足多样性的同时又保持通顺。
代码实现
def top_p(prob, p=0.9):
def softmax(z):
return np.exp(z) / sum(np.exp(z))
# 根据p值进行降序排序
sorted_prob = sorted([(p, i) for i, p in enumerate(prob)], reverse=True)
sorted_p = [p for p, i in sorted_prob]
sorted_idx = [i for p, i in sorted_prob]
# 计算概率累计和
acc_p = list(accumulate(sorted_p))
# bisect二分查找,在acc_p中查找p,p存在时返回p右侧的位置,p不存在返回应该插入的位置
k = bisect(acc_p, p)
# 这里切片逻辑不对有bug,但是思路对,懒得读正确代码了。。。正确代码可以参考huggingface的实现
# 重新分布归一化
reweighted_p = softmax(np.log(sorted_p[:k]))
# 返回随机采样结果
return sorted_idx[:k], reweighted_p, np.random.choice(sorted_idx[:k], p=reweighted_p)
6. repetitions penalized sampling
为了解决重复问题,还可以通过惩罚因子将出现过词的概率变小或者强制不使用重复词来解决。惩罚因子来自于用于可控文本生成的大规模预训练语言模型的CTRL: A Conditional Transformer Language Model for Controllable Generation。
这种方法一般结合其他采样方法来使用。
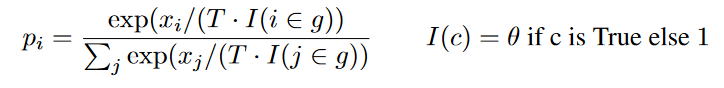
其中,i是当前token,g是已生成token,当 i ∈ g i∈g i∈g时, I = θ I=θ I=θ,否则为1。这里的 θ θ θ应该是大于1的,如果重复了,可以降低其概率。CTRL这篇文章实验结果发现 θ ≈ 1.2 θ≈1.2 θ≈1.2时效果很好。
代码实现
# 输入的同样是logits(lprobs)
# 同时输入了之前出现过的词以及惩罚系数(大于1的)
# 考虑到了logit是正和负时处理方式应该不一样
def enforce_repetition_penalty_(self, lprobs, batch_size, num_beams, prev_output_tokens, repetition_penalty):
"""repetition penalty (from CTRL paper https://arxiv.org/abs/1909.05858). """
for i in range(batch_size * num_beams):
for previous_token in set(prev_output_tokens[i].tolist()):
# if score < 0 then repetition penalty has to multiplied to reduce the previous token probability
if lprobs[i, previous_token] < 0:
lprobs[i, previous_token] *= repetition_penalty
else:
lprobs[i, previous_token] /= repetition_penalty
总结
-
实际应用中可以将多种采样方法进行结合,如Tok-p+Temperature。
-
没有最好的方法,只有最适合任务的方法。结合具体任务反复实验找到最佳生成方法,推荐使用不同的参数,在生成文本的结构性和随机性之间进行权衡。
-
文本生成的两大要素是质量和多样性。采样本质上就是在生成文本的质量(Quality)和多样性(Diversity)间寻求平衡。
在解码的时候,不按照模型本身得到的每个词的概率采样,而是进行一定的变换,然后再采样,如果采样范围缩小,那么多样性就减少,但质量也会提高,如果采样范围扩大,多样性就会增大,但质量也会降低。
参考文章
https://www.modb.pro/db/381462
https://www.cnblogs.com/miners/p/14950681.html
https://zhuanlan.zhihu.com/p/453286395
https://zhuanlan.zhihu.com/p/460733009
https://blog.csdn.net/qq_41466892/article/details/121119550
https://zhuanlan.zhihu.com/p/43703136/