1.一般实际生活中我们遇到的算法分为四类:
一>判定性问题
二>最优化问题
三>构造性问题
四>计算性问题
而今天所要总结的算法就是着重解决 最优化问题
《算法之道》对三种算法进行了归纳总结,如下表所示:
| 标准分治 |
动态规划 |
贪心算法 |
|
| 适用类型 |
通用问题 |
优化问题 |
优化问题 |
| 子问题结构 |
每个子问题不同 |
很多子问题重复(不独立) |
只有一个子问题 |
| 最优子结构 |
不需要 |
必须满足 |
必须满足 |
| 子问题数 |
全部子问题都要解决 |
全部子问题都要解决 |
只要解决一个子问题 |
| 子问题在最优解里 |
全部 |
部分 |
部分 |
| 选择与求解次序 |
先选择后解决子问题 |
先解决子问题后选择 |
先选择后解决子问题 |
分治算法特征:
1)规模如果很小,则很容易解决。//一般问题都能满足
2)大问题可以分为若干规模小的相同问题。//前提
3)利用子问题的解,可以合并成该问题的解。//关键
4)分解出的各个子问题相互独立,子问题不再包含公共子问题。 //效率高低
【一】动态规划:
依赖:依赖于有待做出的最优选择
实质:就是分治思想和解决冗余。
自底向上(每一步,根据策略得到一个更小规模的问题。最后解决最小规模的问题。得到整个问题最优解)
特征:动态规划任何一个i+1阶段都仅仅依赖 i 阶段做出的选择。而与i之前的选择无关。但是动态规划不仅求出了当前状态最优值,而且同时求出了到中间状态的最优值。
缺点:空间需求大。
【二】贪心算法:
依赖:依赖于当前已经做出的所有选择。
自顶向下(就是每一步,根据策略得到一个当前最优解。传递到下一步,从而保证每一步都是选择当前最优的。最后得到结果)
【三】分治算法:
实质:递归求解
缺点:如果子问题不独立,需要重复求公共子问题
---------------------------------------------------------------------------------------------------------------------------
贪心算法:贪心算法采用的是逐步构造最优解的方法。在每个阶段,都在一定的标准下做出一个看上去最优的决策。决策一旦做出,就不可能再更改。做出这个局部最优决策所依照的标准称为贪心准则。
分治算法:分治法的思想是将一个难以直接解决大的问题分解成容易求解的子问题,以便各个击破、分而治之。
动态规划:将待求解的问题分解为若干个子问题,按顺序求解子阶段,前一子问题的解,为后一子问题的求解提供了有用的信息。在求解任一子问题时,列出各种可能的局部解,通过决策保留那些有可能达到最优的局部解,丢弃其他局部解。依次解决各子问题,最后一个子问题就是初始问题的解。
二、算法间的关联与不同
1、分治算法与动态规划
分治法所能解决的问题一般具有以下几个特征:
① 该问题的规模缩小到一定程度就可以容易地解决。
② 该问题可以分为若干个较小规模的相似的问题,即该问题具有最优子结构性质。
③ 利用该问题分解出的子问题的解可以合并为该问题的解。
④ 该问题所分解出的各个子问题是相互独立的且子问题即之间不包含公共的子问题。
上述的第一条特征是绝大多数问题都可以满足的,因为问题的计算复杂性一般是随着问题规模的增加而增加;
第二条特征是分治法应用的前提,它也是大多数问题可以满足的,此特征反映了递归思想的应用;
第三条特征是关键,能否利用分治法完全取决于问题是否具有第三条特征,如果具备了第一条和第二条特征,而不具备第三条特征,则可以考虑贪心算法或动态规划算法;
第四条特征涉及到分治法的效率,如果各个子问题不是独立的,则分治法要做许多不必要的工作,重复地解公共的子问题。这类问题虽然可以用分治法解决,但用动态规划算法解决效率更高。
当问题满足第一、二、三条,而不满足第四条时,一般可以用动态规划法解决,可以说,动态规划法的实质是: 分治算法思想+解决子问题冗余情况
2、贪心算法与动态规划算法
多阶段逐步解决问题的策略就是按一定顺序或一定的策略逐步解决问题的方法。分解的算法策略也是多阶段逐步解决问题策略的一种表现形式,主要是通过对问题逐步分解,然后又逐步合并解决问题的。
贪心算法每一步都根据策略得到一个结果,并传递到下一步,自顶向下,一步一步地做出贪心决策。
动态规划算法的每一步决策给出的不是唯一结果,而是一组中间结果,而且这些结果在以后各步可能得到多次引用,只是每走一步使问题的规模逐步缩小,最终得到问题的一个结果。
举例:如图1有一三角形数塔,求一自塔顶到塔底的路径,要求该路径上结点的值的和最大。
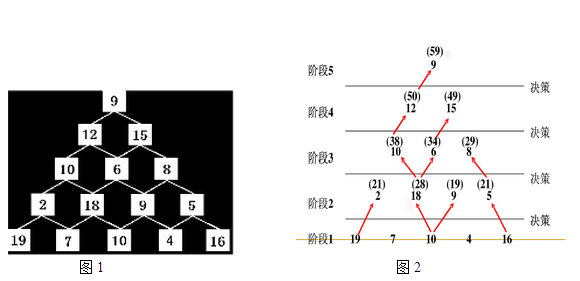
贪心算法解题过程:自顶向下从第一层9开始,到第二层,选数值较大的15,第三层,在可选路径中选数值较大的8,同理,第四层选9,第五层选10,这样就确定了一条路径:9→15→8→9→10。
动态规划算法接题过程:如图2,阶段1:自第五层开始,对经过第四层的2的路径,在第五层的19、7中选择数值较大的19,同理,对经过第四层18的路径,选10,对经过第四层9的路径,选10,对经过5的路径选16。
以上是一次决策过程,也是一次递推过程和降阶过程。因为以上的决策结果将5阶数塔问题变为4阶子问题,递推出第四层与第五层和为:
21(2+19),28(18+10),19(9+10),21(5+16)
用同样的方法还可以将4阶数塔问题变为3阶数塔问题,……,最后得到1阶数塔问题,这样也确定了一条路径:9→12→10→18→10,就是真个问题的最优解。
显然,以上数塔问题用贪心算法得不到最优解,这里只是用作与动态规划算法的比较。
三、适用条件
贪心算法:
①贪心选择性质:在求解一个问题的过程中,如果再每一个阶段的选择都是当前状态下的最优选择,即局部最优选择,并且最终能够求得问题的整体最优解,那么说明这个问题可以通过贪心选择来求解,这时就说明此问题具有贪心选择性质。
②最优子结构性质:当一个问题的最优解包含了这个问题的子问题的最优解时,就说明该问题具有最优子结构。
分治算法:见二、算法间的关联与不同中的①②③④。
动态规划:
①最优化原理:如果问题的最优解所包含的子问题的解也是最优的,就称该问题具有最优子结构,即满足最优化原理。
②无后效性:即某阶段状态一旦确定,就不受这个状态以后决策的影响。也就是说,某状态以后的过程不会影响以前的状态,只与当前状态有关。
③有重迭子问题:即子问题之间是不独立的,一个子问题在下一阶段决策中可能被多次使用到。
四、优势:
采用动态规划方法,可以高效地解决许多用贪婪算法或分而治之算法无法解决的问题。
但贪心算法也有它的优势:构造贪心策略不是很困难,而且贪心策略一旦经过证明成立后,它就是一种高效的算法。
==========================================
2.排序
3.二叉查找树
简介
树是一种非线性结构。树的本质是将一些节点由边连接起来,形成层级的结构。而二叉树是一种特殊的树,使得树每个子节点必须小于等于2.而二叉查找树又是一类特殊的二叉树。使得每一个节点的左节点或左子树的所有节点必须小于这个节点,右节点必须大于这个节点。从而方便高效搜索。
下面来看如何使用C#实现二叉查找树。
实现节点
二叉查找树是节点的集合。因此首先要构建节点,如代码1所示。
//二叉查找树的节点定义
public class Node
{
//节点本身的数据
public int data;
//左孩子
public Node left;
//右孩子
public Node right;
public void DisplayData()
{
Console.Write(data+" ");
}
}
代码1.节点的定义
构建二叉树
构建二叉树是通过向二叉树插入元素得以实现的,所有小于根节点的节点插入根节点的左子树,大于根节点的,插入右子树。依此类推进行递归。直到找到位置进行插入。二叉查找树的构建过程其实就是节点的插入过程。C#实现代码如代码2所示。
public void Insert(int data)
{
Node Parent;
//将所需插入的数据包装进节点
Node newNode=new Node();
newNode.data=data;
//如果为空树,则插入根节点
if(rootNode==null)
{
rootNode=newNode;
}
//否则找到合适叶子节点位置插入
else
{
Node Current = rootNode;
while(true)
{
Parent=Current;
if(newNode.data<Current.data)
{
Current=Current.left;
if(Current==null)
{
Parent.left=newNode;
//插入叶子后跳出循环
break;
}
}
else
{
Current = Current.right;
if (Current == null)
{
Parent.right = newNode;
//插入叶子后跳出循环
break;
}
}
}
}
}
代码2.实现二叉树的插入
二叉树的遍历
二叉树的遍历分为先序(PreOrder),中序(InOrder)和后序(PostOrder)。先序首先遍历根节点,然后是左子树,然后是右子树。中序首先遍历左子树,然后是根节点,最后是右子树。而后续首先遍历左子树,然后是右子树,最后是根节点。因此,我们可以通过C#递归来实现这三种遍历,如代码3所示。
//中序
public void InOrder(Node theRoot)
{
if (theRoot != null)
{
InOrder(theRoot.left);
theRoot.DisplayData();
InOrder(theRoot.right);
}
}
//先序
public void PreOrder(Node theRoot)
{
if (theRoot != null)
{
theRoot.DisplayData();
PreOrder(theRoot.left);
PreOrder(theRoot.right);
}
}
//后序
public void PostOrder(Node theRoot)
{
if (theRoot != null)
{
PostOrder(theRoot.left);
PostOrder(theRoot.right);
theRoot.DisplayData();
}
}
代码3.实现二叉排序树的先序,中序和后续遍历
找到二叉查找树中的最大值和最小值
二叉查找树因为已经有序,所以查找最大值和最小值非常简单,找最小值只需要找最左边的叶子节点即可。而找最大值也仅需要找最右边的叶子节点,如代码4所示。
//找到最大节点
public void FindMax()
{
Node current = rootNode;
//找到最右边的节点即可
while (current.right != null)
{
current = current.right;
}
Console.WriteLine("\n最大节点为:" + current.data);
}
//找到最小节点
public void FindMin()
{
Node current = rootNode;
//找到最左边的节点即可
while (current.left != null)
{
current = current.left;
}
Console.WriteLine("\n最小节点为:" + current.data);
}
代码4.二叉查找树找最小和最大节点
二叉查找树的查找
因为二叉查找树已经有序,所以查找时只需要从根节点开始比较,如果小于根节点,则查左子树,如果大于根节点,则查右子树。如此递归,如代码5所示。
//查找
public Node Search(int i)
{
Node current = rootNode;
while (true)
{
if (i < current.data)
{
if (current.left == null)
break;
current = current.left;
}
else if (i > current.data)
{
if (current == null)
break;
current = current.right;
}
else
{
return current;
}
}
if (current.data != i)
{
return null;
}
return current;
}
代码5.二叉查找树的查找
二叉树的删除
二叉树的删除是最麻烦的,需要考虑四种情况:
- 被删节点是叶子节点
- 被删节点有左孩子没右孩子
- 被删节点有右孩子没左孩子
- 被删节点有两个孩子
我们首先需要找到被删除的节点和其父节点,然后根据上述四种情况分别处理。如果遇到被删除元素是根节点时,还需要特殊处理。如代码6所示。
//删除二叉查找树中的节点,最麻烦的操作
public Node Delete(int key)
{
Node parent = rootNode;
Node current = rootNode;
//首先找到需要被删除的节点&其父节点
while (true)
{
if (key < current.data)
{
if (current.left == null)
break;
parent = current;
current = current.left;
}
else if (key > current.data)
{
if (current == null)
break;
parent = current;
current = current.right;
}
//找到被删除节点,跳出循环
else
{
break;
}
}
//找到被删除节点后,分四种情况进行处理
//情况一,所删节点是叶子节点时,直接删除即可
if (current.left == null && current.right == null)
{
//如果被删节点是根节点,且没有左右孩子
if (current == rootNode&&rootNode.left==null&&rootNode.right==null)
{
rootNode = null;
}
else if (current.data < parent.data)
parent.left = null;
else
parent.right = null;
}
//情况二,所删节点只有左孩子节点时
else if(current.left!=null&¤t.right==null)
{
if (current.data < parent.data)
parent.left = current.left;
else
parent.right = current.left;
}
//情况三,所删节点只有右孩子节点时
else if (current.left == null && current.right != null)
{
if (current.data < parent.data)
parent.left = current.right;
else
parent.right = current.right;
}
//情况四,所删节点有左右两个孩子
else
{
//current是被删的节点,temp是被删左子树最右边的节点
Node temp;
//先判断是父节点的左孩子还是右孩子
if (current.data < parent.data)
{
parent.left = current.left;
temp = current.left;
//寻找被删除节点最深的右孩子
while (temp.right != null)
{
temp = temp.right;
}
temp.right = current.right;
}
//右孩子
else if (current.data > parent.data)
{
parent.right = current.left;
temp = current.left;
//寻找被删除节点最深的左孩子
while (temp.left != null)
{
temp = temp.left;
}
temp.right = current.right;
}
//当被删节点是根节点,并且有两个孩子时
else
{
temp = current.left;
while (temp.right != null)
{
temp = temp.right;
}
temp.right = rootNode.right;
rootNode = current.left;
}
}
return current;
}
代码6.二叉查找树的删除
测试二叉查找树
现在我们已经完成了二叉查找树所需的各个功能,下面我们来对代码进行测试:
BinarySearchTree b = new BinarySearchTree();
/*插入节点*/
b.Insert(5);
b.Insert(7);
b.Insert(1);
b.Insert(12);
b.Insert(32);
b.Insert(15);
b.Insert(22);
b.Insert(2);
b.Insert(6);
b.Insert(24);
b.Insert(17);
b.Insert(14);
/*插入结束 */
/*对二叉查找树分别进行中序,先序,后序遍历*/
Console.Write("\n中序遍历为:");
b.InOrder(b.rootNode);
Console.Write("\n先序遍历为:");
b.PreOrder(b.rootNode);
Console.Write("\n后序遍历为:");
b.PostOrder(b.rootNode);
Console.WriteLine(" ");
/*遍历结束*/
/*查最大值和最小值*/
b.FindMax();
b.FindMin();
/*查找结束*/
/*搜索节点*/
Node x = b.Search(15);
Console.WriteLine("\n所查找的节点为" + x.data);
/*搜索结束*/
/*测试删除*/
b.Delete(24);
Console.Write("\n删除节点后先序遍历的结果是:");
b.InOrder(b.rootNode);
b.Delete(5);
Console.Write("\n删除根节点后先序遍历的结果是:");
b.InOrder(b.rootNode);
Console.ReadKey();
/*删除结束*/
代码7.测试二叉查找树
运行结果如图1所示:

图1.测试运行结果
总结
树是节点的层级集合,而二叉树又是将每个节点的孩子限制为小于等于2的特殊树,二叉查找树又是一种特殊的二叉树。二叉树对于查找来说是非常高效,尤其是查找最大值和最小值。
下面这个二叉查找树更完整哦
/// <summary> /// 二叉树节点的定义 /// </summary> public class Node { //本身的数据 public int data; //左右节点 public Node left; public Node right; public void DisplayData() { Console.Write(data + " "); } } public class BinarySearchTree { Node rootNode = null; public void Insert(int data) { Node parent; //包装数据进节点 Node newNode = new Node(); newNode.data = data; //根节点 if (rootNode == null) { rootNode = newNode; } //找到合适的子节点位置插入 else { Node currentNode = rootNode; while (true) { parent = currentNode; if (newNode.data < currentNode.data) { currentNode = currentNode.left; if (currentNode == null) { parent.left = newNode; break; } } else { currentNode = currentNode.right; if (currentNode == null) { parent.right = newNode; break; } } } } } /// <summary> /// 中序遍历 /// </summary> /// <param name="theRoot"></param> public void InOrder(Node theRoot) { if (theRoot != null) { InOrder(theRoot.left); theRoot.DisplayData(); InOrder(theRoot.right); } } //先序遍历 public void PreOrder(Node theRoot) { if (theRoot != null) { theRoot.DisplayData(); PreOrder(theRoot.left); PreOrder(theRoot.right); } } //后序遍历 public void PostOrder(Node theRoot) { if (theRoot != null) { PostOrder(theRoot.left); PostOrder(theRoot.right); theRoot.DisplayData(); } } public void FindMax() { Node current = rootNode; //找到最右边的即可 while (current.right != null) { current = current.right; } Console.WriteLine("max:" + current.data); } public void FindMin() { Node current = rootNode; //找到最左边的节点即可 while (current.left != null) { current = current.left; } Console.WriteLine("min:" + current.data); } public Node Search(int i) { Node current = rootNode; while (true) { if (i < current.data) { if (current.left == null) break; current = current.left; } else if (i > current.data) { if (current == null) break; current = current.right; } else { return current; } } if (current.data != i) { return null; } return current; } public Node Delete(int key) { Node parent = rootNode; Node current = rootNode; //首先找到需要被删除的节点和其父节点 while (true) { if (key < current.data) { if (current.left == null) break; parent = current; current = current.left; } else if (key > current.data) { if (current == null) break; parent = current; current = current.right; } else { break; } } //找到被删除的节点后,分四种情况 //1.当是子节点的时候,直接删除 if (current.left == null && current.right == null) { if (current == rootNode && rootNode.left == null && rootNode.right == null) { rootNode = null; } else if (current.data < parent.data) { parent.left = null; } else { parent.right = null; } } //所删除的节点只有左节点的时 else if (current.left != null && current.right == null) { if (current.data < parent.data) parent.left = current.left; else parent.right = current.left; } //所删除的节点只有右节点时 else if (current.left == null && current.right != null) { if (current.data < parent.data) parent.left = current.right; else parent.right = current.right; } //当删除的节点有左右节点的时候 else { //current是被删除的节点,temp是被删左子树最右边的节点 Node temp; //先判断是父节点的左节点还是右节点 if (current.data < parent.data) { parent.left = current.left; temp = current.left; //寻找被删除节点最深的右孩子 while (temp.right != null) { temp = temp.right; } temp.right = current.right; } //右节点 else if (current.data > parent.data) { parent.right = current.left; temp = current.left; //寻找被删除节点最深的左孩子 while (temp.left != null) { temp = temp.left; } temp.right = current.right;<a href="http://www.cnblogs.com/CareySon/archive/2012/04/19/implebinarytreewithcsharp.html" target="_blank">点击打开链接</a> } //当被删节点是根节点,并且有两个孩子时 else { temp = current.left; while (temp.right != null) { temp = temp.right; } temp.right = rootNode.right; rootNode = current.left; } } return current; } }
public int[] Srt(int[] k) { int[] temp = k; //冒泡排序法 /* for (int i = 0; i < temp.Length - 1; i++) { for (int j = 1 + i; j < temp.Length; j++) { if (temp[i] > temp[j]) { int t = temp[i]; temp[i]=temp[j]; temp[j]=t; } } } */ //选择排序 /* int temps = 0; for(int i=0;i<temp.Length-1;i++){ int minVal =temp[i]; int minIndex =i; for(int j=i+1;j<temp.Length;j++){ if(minVal>temp[j]){ minVal =temp[j]; minIndex =j; } } temps= temp[i]; temp[i]=temp[minIndex]; temp[minIndex]=temps; } */ /* for (int i = 1; i < temp.Length; i++) { int insertVal = temp[i]; //首先记住这个预备要插入的数 int insertIndex = i - 1; //找出它前一个数的下标(等下 准备插入的数 要跟这个数做比较) //如果这个条件满足,说明,我们还没有找到适当的位置 while (insertIndex >= 0 && insertVal < temp[insertIndex]) //这里小于是升序,大于是降序 { temp[insertIndex + 1] = temp[insertIndex]; //同时把比插入数要大的数往后移 insertIndex--; //指针继续往后移,等下插入的数也要跟这个指针指向的数做比较 } //插入(这时候给insertVal找到适当位置) temp[insertIndex + 1] = insertVal; } */ foreach (var item in temp) { print(item); } return temp; }