上一篇:
Java多线程编程-(11)-从volatile和synchronized的底层实现原理看Java虚拟机对锁优化所做的努力
Java多线程编程-(12)-Java中的队列同步器AQS和ReentrantLock锁原理简要分析
一、背景
在《 Java多线程编程-(11)-从volatile和synchronized的底层实现原理看Java虚拟机对锁优化所做的努力》 这一篇文章中,我们大致介绍了Java虚拟机对锁优化所做的努力,提到了:偏向锁、轻量级锁、重量级锁以及自旋锁。
通过上面的学习,我们应该很清楚的知道了在多线程并发情况下如何保证数据的安全性和一致性的两种主要方法:一种是加锁,另一种是使用ThreadLocal。锁是一种以时间换空间的方式,而ThreadLocal是一种以空间换时间的方式。而关于ThreadLocal的正确使用,以及不正确的使用会造成的OOM已经在前边的文章中有所学习,下边就锁的问题在进一步探讨一下。
二、为什么还要进一步探讨锁
我们知道加锁同步的时候,同一时刻只允许一个线程访问临界资源的。因此,在高并发的情况下激烈的锁竞争以及上下文切换会导致程序的性能下降,就像并不是所有东西都是最优的一样,同样对于锁来说也是有很多可以进行优化的地方。
三、有关锁优化的几点建议
1、减少锁持有的时间
首先看一段代码:
public synchronized void syncMethod(){
method1();
mutextMethod(); //实际需要进行同步的方法
method2();
}- 1
- 2
- 3
- 4
- 5
可以看出只有mutextMethod() 方法是有同步需求的,而method1() 和method2() 方法是不需要进行同步的,但是如果method1()、method2() 是两个耗时的方法的话,那么整个锁持有的时间就会增加,很显然是一种不合理的设计,正确的方式应该使用如下的方式:
public void syncMethod() {
method1();
synchronized (this) {
mutextMethod(); //实际需要进行同步的方法
}
method2();
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
这样的话,只在有必要的时候进行同步,这样就明显减少了线程持有锁的时间,从而提高系统的性能。
2、减小锁粒度
减小锁粒度是一种削弱多线程锁竞争的有效方法。我们知道HashMap不是线程安全的而HashTable是线程安全的,但是我们在使用HashTable的时候,无论是进行读还是进行写操作都需要现获取锁,当有一个线程获取锁之后进行操作,其他的线程就必须进行阻塞等待,可见在高并发的情况下HashTable的性能会显著下降。
为了解决HashTable效率低下的问题ConcurrentHashMap出现了!
HashTable容器在竞争激烈的并发环境下表现出效率低下的原因是所有访问HashTable的线程都必须竞争同一把锁,假如容器里有多把锁,每一把锁用于锁容器其中一部分数据,那么当多线程访问容器里不同数据段的数据时,线程间就不会存在锁竞争,从而可以有效提高并发访问效率,这就是ConcurrentHashMap所使用的锁分段技术。首先将数据分成一段一段地存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
HashMap和ConcurrentHashMap锁的区别:
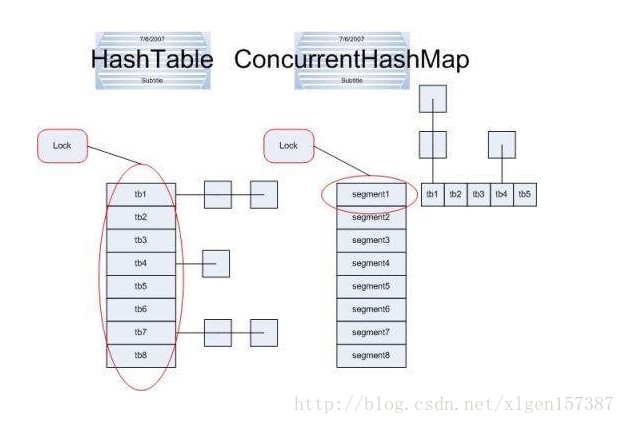
在默认的情况下,ConcurrentHashMap有16个Segment,也就是有16把锁,这样的话只要不同的线程获取不同锁锁住某一个Segment,这样的话就可以实现高并发的操作,这也是减小锁粒度 的一个典型使用。
3、使用读写锁替换独占锁
前几篇文章中,我们大致了解了可以使用ReentrantLock 实现线程的同步,ReentrantLock具有完全互斥排他的效果,即同一时间只能有一个线程在执行ReentrantLock.lock()之后的任务。
类似于我们集合中有同步类容器 和并发类容器,HashTable是完全排他的,即使是读也只能同步执行,而ConcurrentHashMap就可以实现同一时刻多个线程之间并发。为了提高效率,ReentrantLock的升级版ReentrantReadWriteLock就可以实现效率的提升。
ReentrantReadWriteLock有两个锁:一个是与读相关的锁,称为“共享锁”;另一个是与写相关的锁,称为“排它锁”。也就是多个读锁之间不互斥,读锁与写锁互斥,写锁与写锁互斥。
在没有线程进行写操作时,进行读操作的多个线程都可以获取到读锁,而写操作的线程只有获取写锁后才能进行写入操作。即:多个线程可以同时进行读操作,但是同一时刻只允许一个线程进行写操作。
4、锁分离
如果将读写锁的思想进一步延伸,就是锁分离。也就是说:只要操作互不影响,锁就可以分离。最典型的一个例子就是LinkedBlockingQueue ,示意图如下:
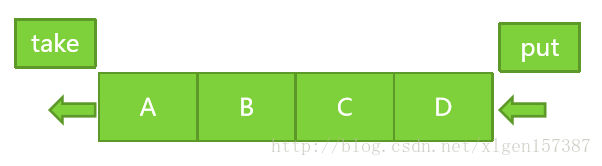
LinkedBlockingQueue是基于链表的,take和put方法分别是向链表中取数据和写数据,他们的操作一个是从队列的头部一个是队列的尾部,从理论上说他们是不冲突的,也就是说可以锁分离的。
如果使用独占锁的话,则要求两个操作在进行时首先要获取当前队列的锁,那么take和put就不是先真正的并发了,因此,在JDK中正是实现了两种不同的锁,一个是takeLock一个是putLock。
5、锁粗化
首先举个简单的例子:
public void syncMethod() {
synchronized (lock) { //第一次加锁
method1();
}
method3();
synchronized (lock) { //第二次加锁
mutextMethod();
}
method4();
synchronized (lock) { //第三次加锁
method2();
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
根据上述的代码,如果第一次和第二次加锁和线程上下文切换的时间超过了method1()、method2()method3()、method4()的时间,那么我们倒不如使用下边的方式:
public void syncMethod() {
synchronized (lock) {
method1();
method3();
mutextMethod();
method4();
method2();
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
改进后的代码的执行时间可能小于上述分别加锁的时间,这就是锁粗化,也是一种锁优化的方式,但是要根据具体的场景。
6、锁消除
锁消除是在编译器级别的事情。
在即时编译器时,如果发现不可能被共享的对象,则可以消除这些对象的锁操作。
也许你会觉得奇怪,既然有些对象不可能被多线程访问,那为什么要加锁呢?写代码时直接不加锁不就好了。
但是有时,这些锁并不是程序员所写的,有的是JDK实现中就有锁的,比如Vector和StringBuffer这样的类,它们中的很多方法都是有锁的。当我们在一些不会有线程安全的情况下使用这些类的方法时,达到某些条件时,编译器会将锁消除来提高性能。
7、Java虚拟机对锁的优化
可参考:Java多线程编程-(11)-从volatile和synchronized的底层实现原理看Java虚拟机对锁优化所做的努力
感谢原创博主-徐刘根