
事情总是这样:
压力初露端倪,暗自考虑改变。
压力高能爆表,立马做出改变。
我们从一家叫做Databricks的美国知名公司聊起。
这家Databricks公司很有创新基因。
其创始人阿里·戈西(Ali Ghodsi)作为“2022年福布斯全球亿万富豪榜”排名第1645位的瑞典富豪,不缺钱,也舍得为公司花钱。
他多次公开表示,不会考虑降低研发投入。
此前(距大模型问世还有几年时间),Databricks就具备一种很重要的能力,我们姑且称之为“二合一”的能力吧:
大数据能力,以及传统人工智能能力。
总称为:“Data+AI”的能力。
更准确地称为:“Data+AI”平台的能力。
传统AI平台的功能,Databricks也早有了。
毕竟,号称一站式商店。
以前,传统AI还可以被归类为“高级”数据分析服务,比如用于预测等场景。
大模型出现后,这样归类就不合时宜了。
大模型不仅仅是分析,人家高低是有智能的。
于是,如今对AI平台的基本要求“水涨船高”:能训练大模型。
而Databricks 公司这样一个Data+AI 平台横跨两界的三好学生优秀班干部,虽然早早具备“二合一”的能力,但也没有在其所辖“四海之内率土之滨”,长出一个生成式AI大模型的功能。
该有的都有呀,居然,眼睁睁看着自己落后了。
大模型需要多大的数据,讲一个训练时候的事实好了。
千亿参数的大模型一次微调,用时大约两个月,消费数据大约20个T。
这意味着,大模型问世之后,大数据“身价”变了,“富贵骄人”。
因为大模型能把大数据里面的价值用得更彻底了。
以前存了多久不要紧,
落了多少灰不要紧。
要紧的是,赶紧喂给大模型。
让大模型把这些尘封已久的知识都“学会”。
一朝变化生,百端头绪出。
轮到大模型给“二合一”平台出难题了。
第一,数据类型多了。
数据不同,模态不同,多种数据,多个模态,大模型向多模态演进。
虽说一般的多模型大模型,训练图文音三种数据;但是,美国大模型这把领先之后,诸君都很激进。手里有好牌,就连续出王炸。
2023年5月9号,
美国厂商Meta大模型ImageBind以视觉为核心,结合文本、声音、深度、热量(红外辐射)、运动(惯性传感器),覆盖6个模态。
无独有偶。
2023年5月26日下午,
国产“紫东太初”2.0全模态大模型发布,特色为可实现文本、图片、语音、视频、3D点云、传感信号等不同模态。
行文至此,不得不感慨,同一个5月份,仅仅从9号到26号,多模态急管繁弦的节奏感了。
第二,计算引擎多了。
按照贾扬清的说法,从技术的角度来看,数据和AI计算是分开的。
数据用数据平台,AI用AI的平台。
今天,无论数据平台,还是 AI 平台,都没法用自己的经验解决对方的问题。因为数据平台和AI平台,背后的技术是截然不同的。
以前的大数据计算引擎主要是支持结构化数据的计算。
不同计算引擎的优化方向(数据新鲜度、查询性能、成本)不同,开发语言、计算语义、存储系统亦不同,组装难度极大。
而AI需要自己的引擎。
一个计算引擎不够,在大数据系统产品时代,就出现这个问题了;
一类计算引擎不够,在传统人工智能时代,也出现这个问题了。
这下好了,多个计算引擎。
看你的Data+AI架构怎么支撑?
大模型时代,Data+AI架构问题恶化,肉眼可见。
第三,大模型迭代太快。
时而以周为单位,时而以天为单位,大模型主打一个“表演型人格”,玩的就是“高速演进”。
这么多新东西,看得人瑟瑟发抖,学得人点灯熬油。
第四,大模型的计算负载只会增多,不会减少。
人们可能倾向于认同:
在可预见的将来,大模型带来的AI负载会占据主导地位。
所以,会为“增多的计算”做准备。
以前的情况是,传统AI负载占比少。
比如,5%,能把AI当做单独的组件来处理。
现在地位今非昔比,
大模型AI计算负载占比由10%增长到80%。
性质变了。
这是一个新家伙对旧事物施加压力,逼迫其做出改变的故事。
DataBricks内心OS是:
家人们,谁懂啊?
大数据平台架构复杂,Data+AI平台架构很复杂。
大模型来了,Data+AI平台架构更复杂。

而重中之重在于,这类平台的架构水平决定了技艺的高度。
怎么解决?
现在没有一步到位的成熟解决方案,
我们试图回顾一下平台架构的历史,寻找启发。
大数据,依然站在大模型的背后。其技术也有年头了。
2023年是大数据技术发展的第 23 个年头(从2001年谷歌开始构建大数据平台做搜索业务算起)。
纯做大数据系统的那套架构,弄起来也非常复杂。
要么,互联网大厂,以开源为基础自建;
台词:“干就完了。”
要么,用公共云平台架构,买 PaaS 服务;
台词:“有钱还得会花,选型很费事。”
要么,外包了事。
台词是:“有钱买服务。虽然对技术栈,技术选型不敏感,但这不妨碍他们对稳定性要求很高。”
从平台技术架构的角度来观察,更能揭示本质。
因为“二合一”平台架构大致分成两部分,计算,存储。
AI还在高速迭代,Data+AI架构的迭代速度没有那么快。
那么我们真的需要一个强大且可扩展的架构。
计算部分就不重要了吗?
并不是,而是计算可以搬迁,加GPU、加CPU没有那么难。
但是数据存储之后不好搬移,参考数据中心间的长传带宽的昂贵。
所以存储理应更受重视。
于是乎,Data+AI平台绕不过“老三样”:
数据湖,数据仓库,湖仓。

观察它们,本质上是从存储的视角观察Data+AI平台。
其实,它们都不能算纯粹的单一产品,而且都包含了“存储架构”。
因为通常来说,这种“二合一”平台包括多个组件。
不同的组件组合会带来多种系统架构形态,让事情非常难办。
而计算机系统软件架构本质上是耐用品,
能谓之“好”的架构核心在于:
它能持续很久。如果每隔半年,或者一年就冒出一个新架构来,
那这个架构可能有大病。
所以,其迭代的时间轴刻度可能很长。
可以观察到,一开始,江湖里就有两派势力并行发展。
一派,数据仓库,已经发展了 40 多年,主流的计算范式就是二维关系表达。
于是,十几年以来,数据仓库都是以关系型计算的架构为主。
所以,它的架构迭代时间轴刻度可能是十年。
另一派,数据湖。
大数据缘起于数据湖上(2006年),
而数据湖的解决方案诞生于领先的技术公司,谷歌和雅虎。
数据湖派先行者是谷歌文件系统(Google File System,GFS),生来就是数据湖架构。
谷歌文件系统的一个开源版Hadoop Distributed File System也是如此。
数据湖派的共同之处是都有一个标准数据湖架构,上面是计算引擎,底下有一套标准存储(是一个文件系统,放什么都行),里面有统一的元数据。
数据湖派的追随者颇多,Spark,Presto(Facebook开发的数据查询引擎),这些都是数据湖上的计算能力。
它们主打一个:存储与计算分离。
可用于灵活组合的内容很多,
比如存储系统、资源调度系统,
多种不同的计算引擎都可以灵活组合。
两个流派,两个车道,同时并举,发展都不错。
从花销来讲,无花销的开源偏向数据湖,有花销的企业级的付费服务偏向数据仓库。
大概再过一段时间,磨合出来一个新架构。
主要是大家突然发现,哎,这个在数据库上做数据分析不够高效,
涉及存储计算一体化联动这样的一些问题。
于是,大数据整体架构往数据仓库那个车道的方向里发展。
所以,像ClickHouse这些东西用了新架构,带着存储,不用分离式的架构,而用更一体化的架构来做里面的事情。
近几年,湖仓(一体)的发展刚刚起步,放在十年的时间刻度轴上观察,
也就往前发展了一小段路,湖仓还是相对较新的架构。
本质上,湖仓是把数据湖的开放性和灵活性,与数据仓库这种高效和管理的能力,结合在一起。
2022年第一季度,硅谷著名投资机构A16Z“Data50榜单”表明,Databricks公司所处细分赛道(查询和处理,Query & Processing)所获投资惊人,几乎占数据企业类赛道资金总量的50%。
尽管Databricks自己的高额融资占掉了很大一部分,但是细究原因,数据分析(查询处理)太慢会影响业务,这是一种关乎客户生死存亡的刚需。
也就是说,在大模型流行之前,AI负载占比不算多,很多企业把它当成一个相对独立的大组件。
大模型问世后,
客户企业会考虑数据库里这些成堆的数据,怎么能被AI消费掉。
而“二合一”平台公司的技术核心点转而成为:
能不能很好地支持AI负载。
此时AI,非彼时AI。
AI今非昔比,已是一等公民。
至少,AI跟数据分析,平起平坐。
所以,在湖仓一体的存储架构的发展大趋势里,AI相当于是往数据湖方向投了一票。
因为数据仓库处理的是结构化和半结构化的数据,但AI强调了这个非结构、半结构数据的处理能力。
因此,你可以理解成大模型在给湖仓一体架构压力,推动它向前走。
故事还在那家叫做Databricks的公司身上结束。
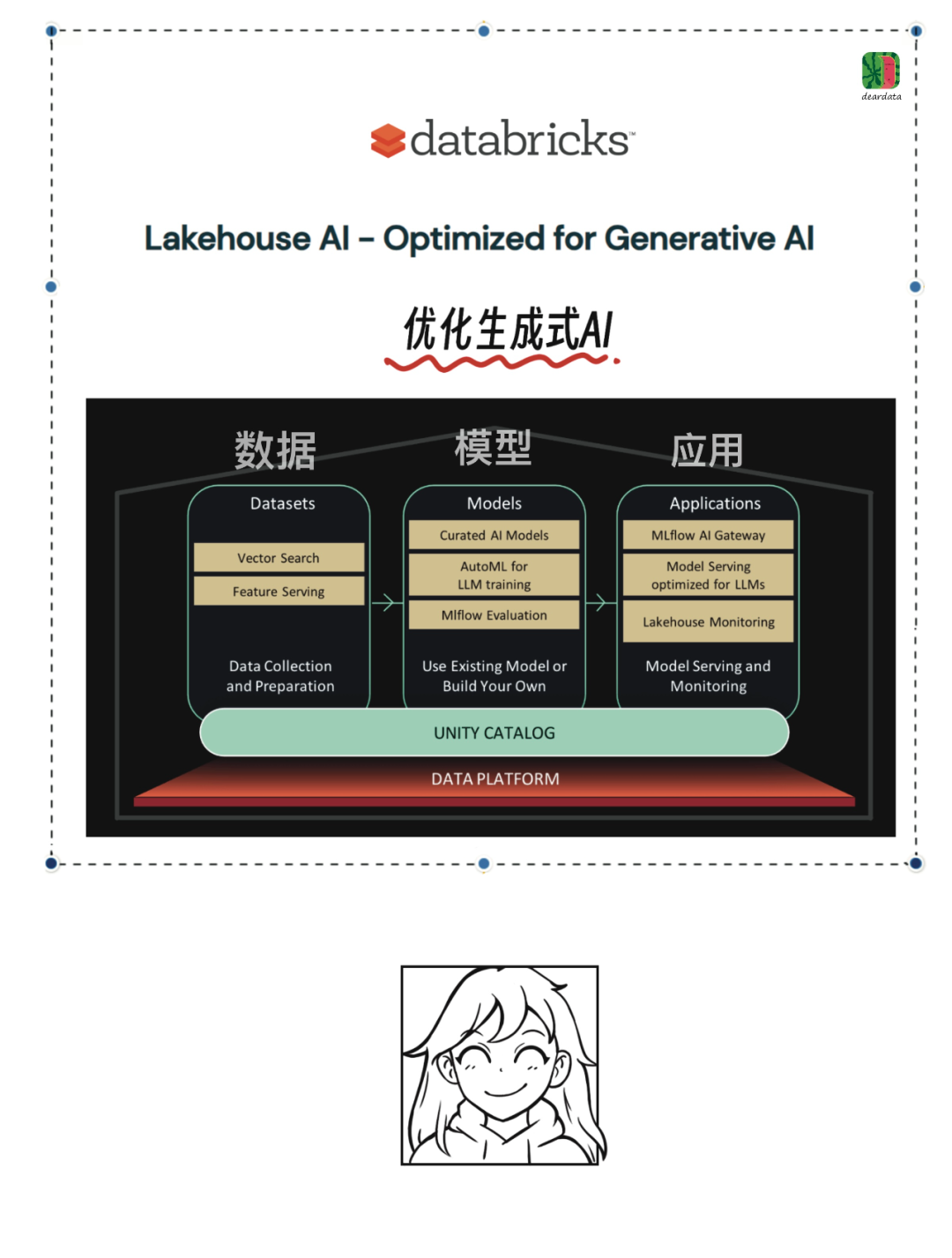
Databricks公司自掏腰包13 亿美元,收购人工智能初创公司 MosaicML。
MosaicML产品成为 Databricks Lakehouse AI组件里的一部分。
最近的“Data + AI Summit 2023(峰会)”上,能看到Databricks也在其大模型工具链上加码。
与此同时,“百模大战”中的大模型公司也飙发电举。
两边都想尽早争取客户。
错失,或者踏空,毕竟都不是好事情。
有的人总能迅速做出改变。
(完)
One More thing
不做标题党,再直接一点回答文章标题问题:
大模型问世后,在面向未来的数据平台选型中,会先淘汰仅面向结构化关系表达设计的传统数仓产品。

带货ing
《我看见了风暴》谭老师新书,京东有售

更多阅读
AI大模型与ChatGPT系列:
1. ChatGPT大火,如何成立一家AIGC公司,然后搞钱?
4. 独家丨从大神Alex Smola与李沐离职AWS创业融资顺利,回看ChatGPT大模型时代“底层武器”演进
5. 独家丨前美团联合创始人王慧文“正在收购”国产AI框架OneFlow,光年之外欲添新大将
8. 云从科技从容大模型:大模型和AI平台什么关系?为什么造行业大模型?
9. 深聊第四范式陈雨强丨如何用AI大模型打开万亿规模传统软件市场?
10. 深聊京东科技何晓冬丨一场九年前的“出发”:奠基多模态,逐鹿大模型
11. 老店迎新客:向量数据库选型与押注中,没人告诉你的那些事
AI大模型与学术论文系列:
1.开源“模仿”ChatGPT,居然效果行?UC伯克利论文,劝退,还是前进?
2. 深聊王金桥丨紫东太初:造一个国产大模型,需用多少篇高质量论文?(二)
3. 深聊张家俊丨 “紫东太初”大模型背后有哪些值得细读的论文(一)
漫画系列
4. AI for Science这事,到底“科学不科学”?
5. 想帮数学家,AI算老几?
11. 强化学习:人工智能下象棋,走一步,能看几步?
14. 云计算Serverless:一支穿云箭,千军万马来相见
15. 数据中心网络:数据还有5纳秒抵达战场
AI框架系列:
3.搞 AI 框架那帮人(三):狂热的 AlphaFold 和沉默的中国科学家
4.搞 AI 框架那帮人(四):AI 框架前传,大数据系统往事
注:(三)和(四)仅收录于《我看见了风暴》。
