导读
本文经过大量案例总结和踩坑复盘,归纳整理了Elastisearch集群在写入性能优化方面一些常用的优化技巧和避坑指南。
在我们服务腾讯云ES的客户过程中,经常会收到一些客户对云上ES集群读写性能未能达到预期的反馈,并希望我们能够配合做一些性能压测及调优的工作。经过我们结合客户的业务场景和深入分析集群性能瓶颈后,基本都可以给出客户一些能够明显提升读写性能的建议和优化措施。
腾讯云大数据ES团队通过众多大客户集群的实践经验,归纳整理了Elastisearch集群在写入性能优化方面一些常用的优化技巧和避坑指南。
ES集群索引原理剖析
在介绍ES集群写入性能优化之前,我们先来简单回顾下Elastisearch集群索引的基本流程。如下图1所示。
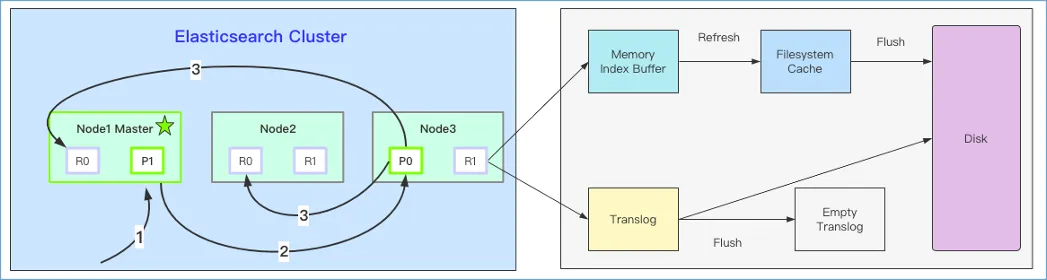
图1. ES集群索引写入流程示意图
通过分析图1的左半部分,可以看出ES写入基本流程如下:
1、客户端向Node1发送索引文档请求;
2、Node1节点根据doc_id确定文档属于分片0,将请求转发到Node3
3、Node3在主分片上执行请求,成功后将请求并行转发到副本分片所在节点。一旦所有副本分片都写入成功,则Node3向协调节点返回写入成功,协调节点向客户端报告doc文档写入成功。
而通过分析图1的右半部分,我们可以看出写入到ES集群的文档在一个分片上的具体执行逻辑,主要分为如下图2所示的四个关键步骤。

图2. ES集群写入核心流程示意图
1、Wirte过程:
分片所在的节点在接收到协调节点的写入请求后,首先会将doc写入到一个叫In-memory Buffer中,也被称为Indexing Buffer。这时候doc还是不可搜索的状态,当In-Menory Buffer空间被写满后,会自动将In-Memory Buffer中的doc生成一个segment文件,这时候doc才会被搜索到。
2、Refresh过程:
上面的write过程中,doc会被首先写入到In-Memory Buffer中,In-Memory Buffer中的数据会在两种情况下被清空:第一种情况就是上面说的当In-_memory Buffer空间被写满了之后,ES会自动清空并生成一个Segment,第二种情况就是ES定时触发的Refresh操作,默认是1s执行一次。Refresh过程其实就是将In-Memory Buffer中的数据写入到Filesystem Cache中的过程,同时该过程也会生成一个Segment文件。
3、Flush过程:
上面的Write过程是将doc写入到In-Memory Buffer中,而Refresh过程是将Doc刷新到文件系统缓存中。这两个过程的数据都还是在内存中,一旦机器故障或宕机重启,都有可能会出现数据丢失风险。ES为了数据丢失,通过translog机制来保障数据的可靠性,实现机制是接收到写入请求后同时将doc以key-value形式写入到translog文件中,当Filesystem Cache中数据被刷到磁盘中才会清空,其中Filesystem Cache中数据刷盘的过程就是Flush操作。从图2中也可以看出,执行了Flush操作后,In-Memory Buffer和translog中的数据都会被清空。
4、Merge过程:
ES的每一次Refresh操作,都会生成一个新的Segment段文件。这样会导致在短时间内段文件数量的暴涨。而段数目太多会带来一系列的问题,比如会大量消耗文件句柄,消耗内存和cpu运行周期。并且每个搜索请求都必须轮流检查每个段文件,导致搜索性能下降明显。为了解决这个问题,Elasticearch通过在后台维护一个线程来定期的合并这些Segment文件,将小的段合并到大的段,然后再将大的段合并到更大的段。这个合并的过程就是Segment Merge的过程。
ES集群写入性能优化
1、时序类场景结合ILM动态滚动索引写入
对于日志、监控、APM等场景建议结合索引生命周期管理(ILM)和快照生命周期管理(SLM)。通过ILM来灵活控制写入索引的大小,尤其是当遇到流量突增时,不至于出现单个索引容量过大而导致影响写入性能的情况。
我们云上的一些客户经常会组织一些运营活动,比如电商类的购物节等,在运营活动期间,业务产生的日志量往往是平常的数倍甚至十几倍。如果按照每天创建一个索引的话,活动期间当天的索引将会变得很大,很容易超过官方推荐的“单分片大小控制在30-50GB”的设计原则。由此会触发一系列的问题,甚至会影响影响性能。例如当单个分片过大,将会影响分片搬迁的速度和节点异常重启后分片恢复的效率,甚至会提前触发单分片21亿条doc数的上限,从而导致数据丢失。
而结合索引生命周期管理,我们可以灵活设计索引滚动的策略,例如一天后开始滚动、索引达到1T后开始滚动,doc数量达到10条开始滚动,任何一个条件先触发都会滚动到下一个新索引写入。这样就能够很好的控制每个索引和分片的大小在一个稳定的范围内。关于索引生命周期管理的更多细节可参考“腾讯云Elasticsearch索引生命周期管理原理及实践”。
2、写入数据时不指定doc_id,让ES自动生成
指定doc_id写入会在写入前先检查该doc是否存在,存在则会做update操作,不存在则会做insert操作,因此指定doc_id写入会对集群的CPU、负载和磁盘IO的消耗都比较大。我们之前有对比分析过一家社区团购大客户在指定doc_id和不指定doc_id写入的写入性能数据。在指定doc_id写入的情况下,CPU使用率上升了30%,IOutils上涨了42%。
3、使用bulk接口批量写入数据,每次bulk数据量大小在10M左右
ES为了提升写入性能,提供了一个叫bulk批量写的API,该API的写入允许客户端一次发送多条doc文档给协调节点进行写入。而批量写入的doc大小或者doc数量直接决定了写入性能高低的关键因素。经过我们大量测试以及官方的建议,每次bulk写入数据量控制在10M是比较理想的,以一条 doc1k来测算的话,一批bulk的doc数量建议控制在8000-20000之间。我们可以通过_tasks API来查看设置的doc条数是否在一个合理的范围内。
GET_tasks?detailed=true&human&group_by=parents&actions=indices:data/write/bulk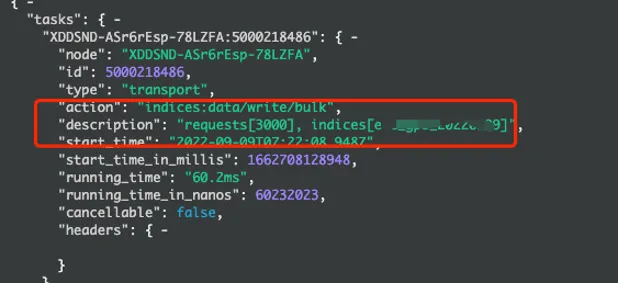
图3. _tasks API查看bulk写入详情
4、开启bulk_routing,将请求转发到较少的分片
默认情况下,客户端的一批bulk写入发送到协调节点后,协调节点在本地先根据一定的策略按照分片的个数将这批doc分成若干份,并行发送到各个主分片所在的节点,然后等待所有分片所在节点返回写入成功ack后,协调节点才会返回给客户端。因此,这一批bulk的写入耗时将直接取决于响应耗时最慢的节点,这就是典型的长尾效应。
而为了解决这一问题,腾讯云ES团队自研了bulk_routing高级特性。通过在协调节点随机生成一个routing,将每一批bulk写入都只转发到特定的一个分片节点上,通过这种方式来降低写入过程中的网络开销和CPU使用率,避免长尾分片影响整体的写入性能。我们可以通过如下API来开启bulk_routing,经过我们观察开启了bulk_routing的某大客户日志集群发现,相对于不开启bulk_routing,写入峰值提升了25%,CPU使用率下降了20%。并且在节点个数越多时,性能提升越明显。
PUT my-index/_settings
{
"index.bulk_routing.enabled": true
}5、规模较大集群,提前创建好索引,使用固定Index mapping
集群规模较大,通常索引容量、分片总数都会比较大,由于在创建索引和更新mapping时涉及到meta元数据的更新,因此会在master更新元数据的过程中短暂阻塞写入,如果此时写入量很大,则有可能会导致写入掉零。下图4是我们云上一客户在每天早上8点切换索引时,更新mapping超时导致写入掉零的日志截图。而如果能提前创建好索引,以及使用固定的索引模版,则可以避免在索引切换时大量的元数据更新操作,从而保障集群的稳定性和写入性能。
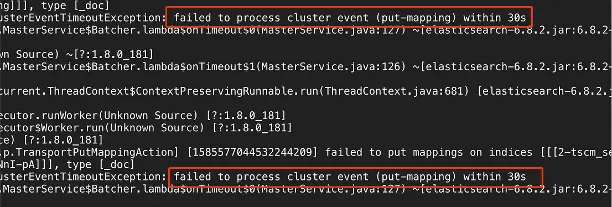
图4. 集群更新mapping超时截图
6、提前设置好mapping,并减少索引字段数量
对于明确不会参与检索的字段,尤其是binary字段和超长的text字段,可以将索引字段的index属性设置为not analyzed或者no,也就是说我们让es不要对这些字段进行分词和构建索引,通过这种方式可以减少不必要的运算,降低CPU性能开销,从而提升集群的写入性能。下图5是我们做的一次性能测试,当我们把所有字段属性都设置了index后, 再次进行写入压测时,可以看到CPU使用率一路攀升到90%。
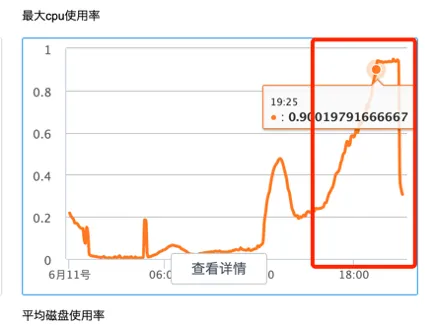
图5. 所有字段开启分词和索引后集群的cpu使用率情况
7、追求写入性能的场景,可以将正在写入的索引设置为单副本,写入完成后打开副本
我们经常会遇到一些客户在两个集群或者两个索引之间做一些数据同步的工作,例如通过logstash来做集群之间的数据迁移,通过reindex API来做索引之间的索引重建工作。在这种快速导数据场景下,可以先将目标端的索引副本关闭,因为在数据迁移这种场景,由于源索引中已经存在一份原始数据了,因此不必担心关闭副本后数据丢失的问题。等迁移完成后再将副本打开即可。同时我们也可以将refresh_interval时间设置得大一些,如30s。目的是可以减少segment文件的生成。以及segment文件的合并次数,从而降低CPU和IO的性能开销,保障集群的写入性能。
以上我们深入剖析了ES集群文档索引的基本原理和流程,同时也结合了腾讯云ES众多大客户的运维经验和踩坑教训,总结了7点写入性能优化相关的建议。希望能对腾讯云ES的每一个客户的都有所帮助。