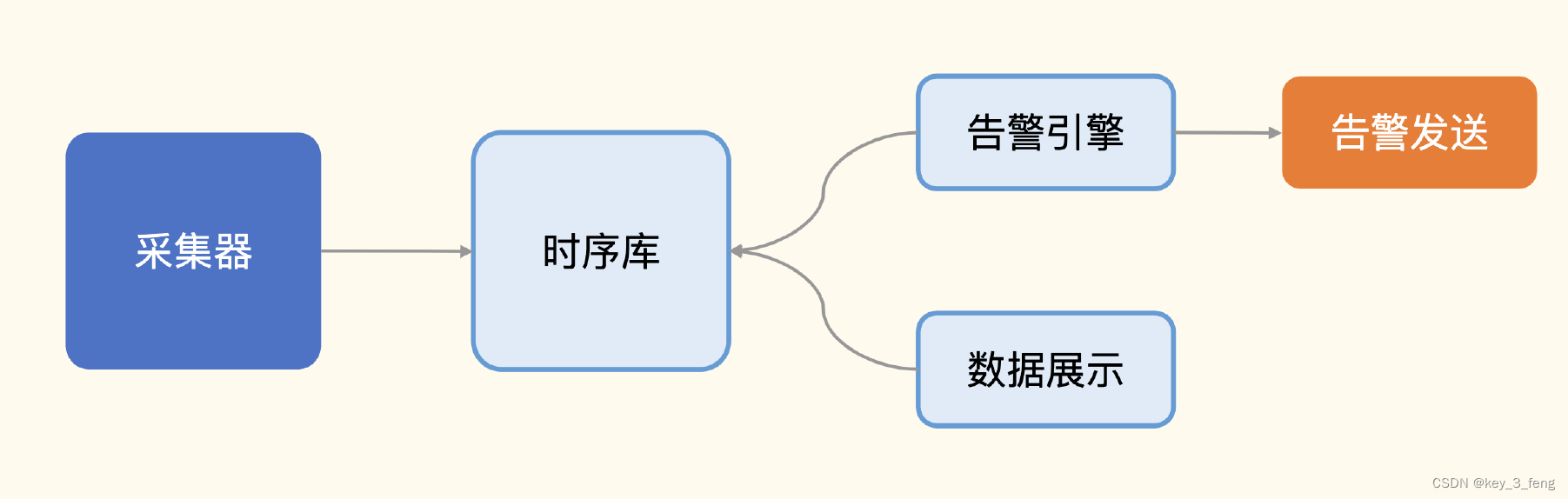
监控系统的典型架构图,从左往右看,采集器是负责采集监控数据的,采集到数据之后传输给服务端,通常是直接写入时序库。然后就是对时序库的数据进行分析和可视化,分析部分最典型的就是告警规则判断,即图上的告警引擎,告警引擎产生告警事件之后交给告警发送模块做不同媒介的通知。可视化比较简单,就是图上的数据展示,通过各种图表来合理地渲染各类监控数据,便于用户查看比较、日常巡检。
1、采集器
采集器负责采集监控数据,有两种典型的部署方式,一种是跟随监控对象部署,比如所有的机器上都部署一个采集器,采集机器的 CPU、内存、硬盘、IO、网络相关的指标;另一种是远程探针式,比如选取一个中心机器做探针,同时探测很多个机器的 PING 连通性,或者连到很多 MySQL 实例上去,执行命令采集数据。
- Telegraf 是 InfluxData 公司的产品,开源协议是 MIT,非常开放,有很多外部贡献者,主要配合 InfluxDB 使用。当然,Telegraf 也可以把监控数据推给 Prometheus、Graphite、Datadog、OpenTSDB 等很多其他存储,但和 InfluxDB 的对接是最丝滑的。
- Exporter 是专门用于 Prometheus 生态的组件,Prometheus 生态的采集器比较零散,每个采集目标都有对应的 Exporter 组件,比如 MySQL 有 mysqld_exporter,Redis 有 redis_exporter,交换机有 snmp_exporter,JVM 有 jmx_exporter。
- Grafana-Agent 是 Grafana 公司推出的一款 All-In-One 采集器,不但可以采集指标数据,也可以采集日志数据和链路数据。开源协议是 Apache 2.0,比较开放。Grafana-Agent 集成了 Loki 生态的日志采集器 Promtail。对于链路数据,Grafana-Agent 集成了 OpenTelemetry Collector。
- Categraf 的定位类似 Grafana-Agent,支持 metrics、logs、traces 的采集。Categraf 偏重 Prometheus 生态,标签是稳态结构,只采集数值型时序数据,通过 Remote Write 方式推送数据给后端存储,所有支持 Remote Write 协议的时序库都可以对接,比如 Prometheus、VictoriaMetrics、M3DB、Thanos 等等。

采集器采集到数据之后,要推给服务端。通常有两种做法,一个是直接推给时序库,一个是先推给 Kafka,再经由 Kafka 写到时序库。
2、时序库
监控系统的架构中,最核心的就是时序库。老一些的监控系统直接复用关系型数据库,比如 Zabbix 直接使用 MySQL 存储时序数据,MySQL 擅长处理事务场景,没有针对时序场景做优化,容量上有明显的瓶颈。
OpenTSDB 是基于 HBase 封装的,后来持续发展,也有了基于 Cassandra 封装的版本。由于底层存储是基于 HBase 的,一般小公司都玩不转,在国内的受众相对较少,当下再选型时序数据库时,就已经很少有人会选择 OpenTSDB 了。
InfluxDB 针对时序存储场景专门设计了存储引擎、数据结构、存取接口,国内使用范围比较广泛,而且 InfluxDB 可以和 Grafana、Telegraf 等良好整合,生态是非常完备的。不过 InfluxDB 开源版本是单机的,没有开源集群版本。毕竟是商业公司,需要赚钱实现良性发展,这个点是需要我们斟酌的。
TDEngine 可以看做是国产版 InfluxDB。针对物联网设备的场景做了优化,性能很好,也可以和 Grafana、Telegraf 整合,对于偏设备监控的场景,TDEngine 是个不错的选择。TDEngine 的集群版是开源的,相比 InfluxDB,TDEngine 这点很有吸引力。TDEngine 不止是做时序数据存储,还内置支持了流式计算,可以让用户少部署一些组件。
M3DB 是来自 Uber 的时序数据库,M3 声称在 Uber 抗住了 66 亿监控指标,这个量非常庞大。而且 M3DB 是全开源的,包括集群版,不过架构原理比较复杂,CPU 和内存占用较高,在国内没有大规模推广起来。M3DB 的架构代码中包含很多分布式系统设计的知识,是个可以拿来学习的好项目。
VictoriaMetrics,简称 VM,架构非常简单清晰,采用 merge read 方式,避免了数据迁移问题,搞一批云上虚拟机,挂上云硬盘,部署 VM 集群,使用单副本,是非常轻量可靠的集群方式。
TimescaleDB 是 timescale.inc 开发的一款时序数据库,作为一个 PostgreSQL 的扩展提供服务。
3、告警引擎
告警引擎的核心职责就是处理告警规则,生成告警事件。通常来讲,用户会配置数百甚至数千条告警规则,一些超大型的公司可能要配置数万条告警规则。每个规则里含有数据过滤条件、阈值、执行频率等,有一些配置丰富的监控系统,还支持配置规则生效时段、持续时长、留观时长等。
告警引擎通常有两种架构,一种是数据触发式,一种是周期轮询式。
数据触发式,是指服务端接收到监控数据之后,除了存储到时序库,还会转发一份数据给告警引擎,告警引擎每收到一条监控数据,就要判断是否关联了告警规则,做告警判断。因为监控数据量比较大,告警规则的量也可能比较大,所以告警引擎是会做分片部署的,即部署多个实例。
周期轮询式,架构简单,通常是一个规则一个协程,按照用户配置的执行频率,周期性查询判断即可,因为是主动查询的,做指标关联计算就会很容易。像 Prometheus、Nightingale、Grafana 等,都是这样的架构。生成事件之后,通常是交给一个单独的模块来做告警发送,这个模块负责事件聚合、收敛,根据不同的条件发送给不同的接收者和不同的通知媒介。
4、数据展示
监控数据的可视化也是一个非常通用且重要的需求,业界做得最成功的当数 Grafana。Grafana 采用插件式架构,可以支持不同类型的数据源,图表非常丰富,基本可以看做是开源领域的事实标准。很多公司的商业化产品中,甚至直接内嵌了 Grafana,可见它是多么流行。
监控数据可视化,通常有两类需求,一个是即时查询,一个是监控大盘(Dashboard)。即时查询是临时起意,比如线上有个问题,需要追查监控数据,还原现场排查问题,这就需要有个方便我们查看的指标浏览功能,快速找到想要的指标。监控大盘通常用于日常巡检和问题排查,由资深工程师创建,放置了一些特别值得重点关注的指标,一定程度上可以引发我们思考,具有很强的知识沉淀效果。如果想要了解某个组件的原理,这个组件的监控大盘通常可以带给你一些启发。
此文章为7月Day29学习笔记,内容来源于极客时间《运维监控系统实战笔记》,推荐该课程。