文章目录
一.Checkpoint 机制
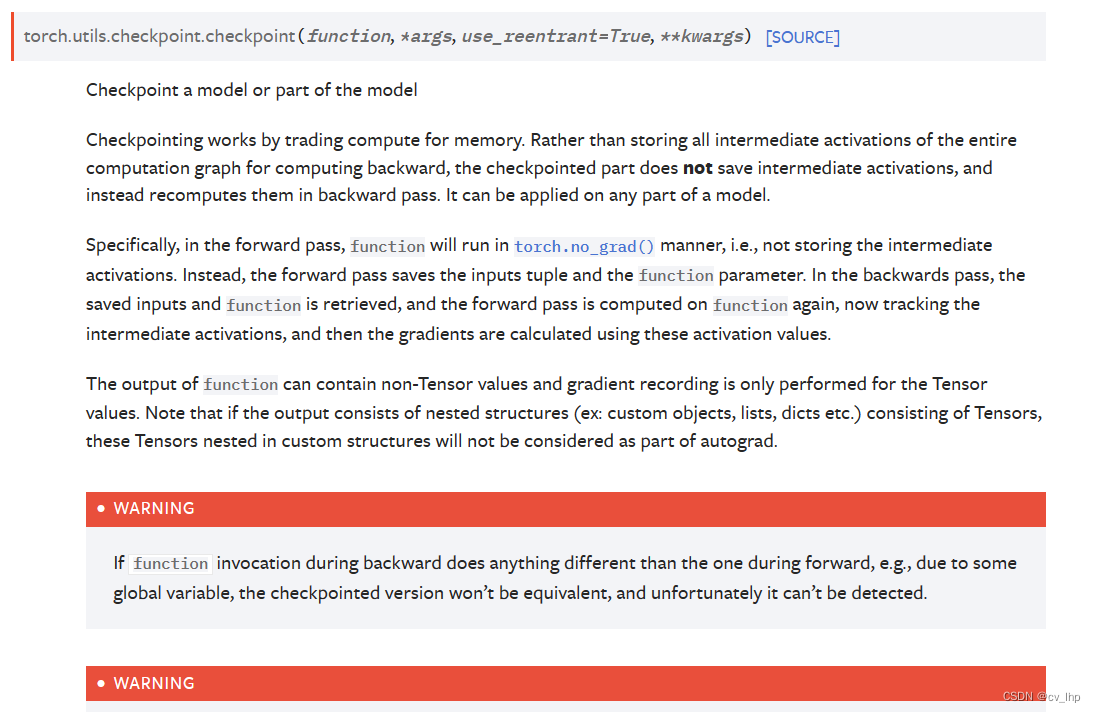
该技术的核心是一种使用时间换空间的策略。在训练的前向传播中不保留中间激活值,从而节省下内存,并在反向传播中重新计算相关值,以此来执行一个高效的内存管理。
主要用于节省训练模型过程中使用的内存,将模型或其部分的激活值的计算方法保存为一个checkpoint,在前向传播中不保留激活值,而在反向传播中根据checkpoint重新计算一次获得激活值用于反向传播。
checkpoint操作是通过将计算交换为内存而起作用的。不同于常规地将整个计算图的所有中间激活值保存下来用于计算反向传播,作为检查点的部分不再保存中间激活值,而是在反向传播中重新计算一次中间激活值,即重新运行一次检查点部分的前向传播。由此可知,checkpoint操作在训练过程中可以节省下作为检查点部分所需占的内存,但是要付出在反向传播中重新计算的时间代价。(checkpoint操作可用于网络的任意部分。)
具体地来说,在前向传递中,传入的function将以torch.no_grad的方式运行,即不保存中间激活值。取而代之的是,前向传递保存了输入元组以及function参数。在反向传递中,保存下来的输入元组与function参数将会被重新取回,并且前向传递将会在function上重新计算,此时会追踪中间激活值,然后梯度将会根据这些中间激活值计算得到。
PyTorch 在进行深度学习训练的时候,有 4 大部分的显存开销,分别是模型参数(parameters),模型参数的梯度(gradients),优化器状态(optimizer states) 以及 中间激活值(intermediate activations) 或者叫中间结果(intermediate results)。
而通过 Checkpoint 技术,我们可以通过一种取巧的方式,使用 PyTorch 提供的 “no-grad” (no_grad())模式来避免将这部分运算被autograd记录到反向图“backward graph”中,从而避免了对于中间激活值的存储需求。
这可以避免存储模型特定层中间运算结果,从而有效降低了前向传播中显存的占用。 这些中间结果会在反向传播的时候被即时重新计算一次。要注意,被 checkpoint 包裹的层反向传播时仍然会在第一次反向传播的时候开辟存储梯度的空间。
这可以避免存储模型特定层中间运算结果,从而有效降低了前向传播中显存的占用。 这些中间结果会在反向传播的时候被即时重新计算一次。要注意,被 checkpoint 包裹的层反向传播时仍然会在第一次反向传播的时候开辟存储梯度的空间。
通过这样的方式,虽然延长了反向传播的时间,但是却也在一定程度上缓解了存储大量中间变量带来的显存占用。
另外前向传播时 autograd 记录各个操作反向传播需要的一些信息和中间变量。反向传播之后,用于计算梯度的中间结果会被释放。也就是说,模型参数、优化器状态和参数梯度是始终在占用着存储空间的,中间激活值在反向传播之后就自动被清空了。
二. torch.utils.checkpoint() 介绍
1、官网文档
https://pytorch.org/docs/stable/checkpoint.html
2、源代码:
class CheckpointFunction(torch.autograd.Function):
@staticmethod
def forward(ctx, run_function, preserve_rng_state, *args):
check_backward_validity(args)
# 暂存前向传播函数
ctx.run_function = run_function
ctx.preserve_rng_state = preserve_rng_state
# 用来保存当前模型的混合精度的状态,以用在反向传播中
ctx.had_autocast_in_fwd = torch.is_autocast_enabled()
if preserve_rng_state: # 保存目标模块前向传播之前,此时CPU和GPU的随机数生成器的状态
ctx.fwd_cpu_state = torch.get_rng_state()
# Don't eagerly initialize the cuda context by accident.
# (If the user intends that the context is initialized later, within their
# run_function, we SHOULD actually stash the cuda state here. Unfortunately,
# we have no way to anticipate this will happen before we run the function.)
ctx.had_cuda_in_fwd = False
if torch.cuda._initialized:
# PyTorch提供的一个内部变量,用于判定CUDA状态是否已经被初始化了
# torch.cuda.is_initialized中就用到了该变量
ctx.had_cuda_in_fwd = True
# 保存输入变量涉及的各个GPU设备的随机状态
ctx.fwd_gpu_devices, ctx.fwd_gpu_states = get_device_states(*args)
# Save non-tensor inputs in ctx, keep a placeholder None for tensors
# to be filled out during the backward.
ctx.inputs = []
ctx.tensor_indices = []
tensor_inputs = []
for i, arg in enumerate(args):
if torch.is_tensor(arg):
tensor_inputs.append(arg)
ctx.tensor_indices.append(i)
ctx.inputs.append(None)
else:
ctx.inputs.append(arg)
# save_for_backward()中保存反向传播中需要用到的输入和输出tensor量。
# 由于在反向传播中需要重新计算记录梯度的output,所以就不要保存output了。
# 并且后面的计算也不需要在梯度模式下计算。
ctx.save_for_backward(*tensor_inputs)
with torch.no_grad():
# 不保存梯度的前向传播操作,也就是说这里的output是不会记录中间变量,无法直接计算梯度的。
outputs = run_function(*args)
return outputs
@staticmethod
def backward(ctx, *args):
if not torch.autograd._is_checkpoint_valid():
raise RuntimeError(
"Checkpointing is not compatible with .grad() or when an `inputs` parameter"
" is passed to .backward(). Please use .backward() and do not pass its `inputs`"
" argument.")
# Copy the list to avoid modifying original list.
inputs = list(ctx.inputs)
tensor_indices = ctx.tensor_indices
tensors = ctx.saved_tensors # 获取前向传播中保存的输入tensor
# Fill in inputs with appropriate saved tensors.
for i, idx in enumerate(tensor_indices):
inputs[idx] = tensors[i]
# Stash the surrounding rng state, and mimic the state that was
# present at this time during forward. Restore the surrounding state
# when we're done.
rng_devices = []
if ctx.preserve_rng_state and ctx.had_cuda_in_fwd:
rng_devices = ctx.fwd_gpu_devices
# 使用之前前向传播开始之前保存的随机数生成器的状态来进行一次一模一样的前向传播过程
with torch.random.fork_rng(devices=rng_devices, enabled=ctx.preserve_rng_state):
# 使用上下文管理器保护原始的随机数生成器的状态,内部处理后在进行复原
if ctx.preserve_rng_state:
torch.set_rng_state(ctx.fwd_cpu_state)
if ctx.had_cuda_in_fwd:
set_device_states(ctx.fwd_gpu_devices, ctx.fwd_gpu_states)
# 这里将inputs从计算图中剥离开,但是其属性requires_grad和原来是一样的,这么做的目的是为了截断反向传播的路径。
# 从整个操作目的来看,由于我们需要重新计算输出,并将梯度回传到输入上,所以输入本身需要可以记录梯度。
# 但是这里的回传不可以影响到checkpoint之外更靠前的那些操作,
# backward之后会将之前保存的中间变量释放掉,而我们仅仅是为了计算当前一小块结构,所以梯度回传需要截断。
detached_inputs = detach_variable(tuple(inputs)) # 会变成叶子结点,grad和grad_fn均重置为None
# 处理完随机状态之后,就该准备着手重新前向传播了。
# 这次前向传播是在梯度模式(torch.enable_grad())下执行的。此时会保存中间变量。
with torch.enable_grad(), torch.cuda.amp.autocast(ctx.had_autocast_in_fwd):
outputs = ctx.run_function(*detached_inputs)
if isinstance(outputs, torch.Tensor):
outputs = (outputs,)
# run backward() with only tensor that requires grad
outputs_with_grad = []
args_with_grad = []
for i in range(len(outputs)):
# 记录需要计算梯度的输出outputs[i]以及对应的回传回来的有效梯度args[i]
if torch.is_tensor(outputs[i]) and outputs[i].requires_grad:
outputs_with_grad.append(outputs[i])
args_with_grad.append(args[i])
# 检查需要计算梯度的输出,如果没有输出需要计算梯度,那么实际上就说明这个模块是不参与梯度计算的,
# 也就是说,该模块不需要使用checkpoint来调整。
if len(outputs_with_grad) == 0:
raise RuntimeError(
"none of output has requires_grad=True,"
" this checkpoint() is not necessary")
# 该操作对被包裹的目标操作计算反向传播,即计算回传到输入detached_inputs上的梯度。
# 由于输入的tensor已被从整体梯度图中剥离,所以可以看做是一个叶子结点,可以在反向传播之后获得其梯度,并且中间变量也会随之释放。
# 另外这里反传计算梯度也不会导致将更靠前的结构中暂时保存来计算梯度的参数给释放掉。
torch.autograd.backward(outputs_with_grad, args_with_grad)
# 如果前面不执行detach(),这里的inp.grad会被直接释放并置为None,这并不符合预期
grads = tuple(inp.grad if isinstance(inp, torch.Tensor) else None
for inp in detached_inputs)
# 这里返回的梯度与当前类的forward输入一一对应,
# 由于这里的forward包含着本不需要梯度的两个参数run_function、preserve_rng_state,故对应回传None即可。
return (None, None) + grads
可以看到,这里的 Checkpoint 本身就是基于 PyTorch 的 Function 实现的一个扩展算子,所以该部分代码也涉及到了 Function 的诸多功能。
这里实际上就是在原始的操作和整体的计算图之间添加了一个中间层,用于信息的交互:
-
原始模型的数据传输到被包裹的目标层的时候,数据进入 checkpoint 的 forward() 中,被 checkpoint 进行检查和记录后,再送入目标层中;
-
目标层在非梯度模式下执行前向传播。该模式下,新创建的 tensor 都是不会记录梯度信息的;
-
目标层的结果通过 checkpoint 的前向传播输出,送入模型后续的其他结构中;
-
执行反向传播,损失求导,链式回传,计算梯度;
-
回传回来的对应于 checkpoint 输出的梯度被送入其对应的反向传播函数,即 checkpoint 的 backward()。
-
梯度送入 checkpoint 中后,需要进一步将梯度回传到目标层的输入上。由于在 checkpoint 的 forward 中目标层本身前向传播是处于非梯度状态下,所以回传路径上缺少目标层中操作的梯度子图。于是为了获取这部分信息,需要先梯度状态下对目标层进行一次前向传播,通过将回传回来的梯度和目标层的输出一起执行 torch.autograd.backward(outputs_with_grad, args_with_grad),从而获得对应输入的梯度信息。
-
将对应目标操作输入的梯度信息按照 checkpoint 本身 Function 的 backward 的需求,使用 None 对其他辅助参数的梯度占位后进行返回。
-
返回的对应于其他模块的输出量的梯度,被沿着反向传播的路径送入对应操作的 backward 中,一层一层回传累加到各个叶子节点上。
3 、补充
定义好操作后,进行一个简单的包装,同时处理一下默认参数,补充了更细致的文档:
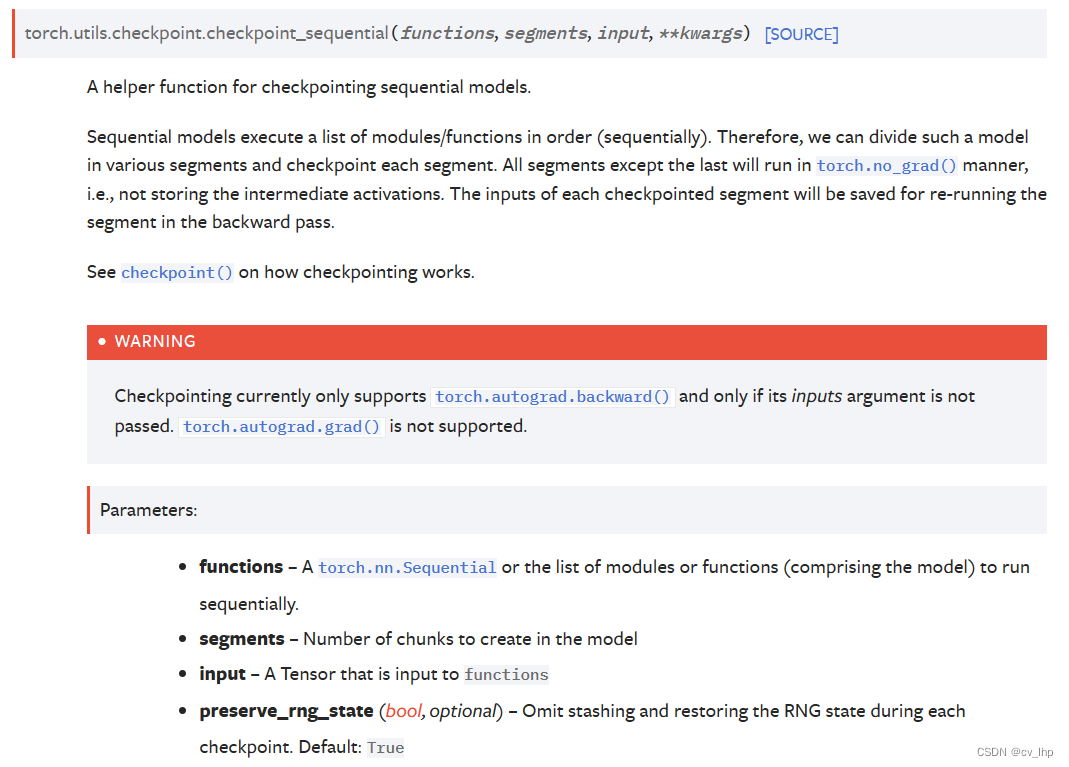
def checkpoint_sequential(functions, segments, input, **kwargs):
r"""A helper function for checkpointing sequential models.
Sequential models execute a list of modules/functions in order
(sequentially). Therefore, we can divide such a model in various segments
and checkpoint each segment. All segments except the last will run in
:func:`torch.no_grad` manner, i.e., not storing the intermediate
activations. The inputs of each checkpointed segment will be saved for
re-running the segment in the backward pass.
See :func:`~torch.utils.checkpoint.checkpoint` on how checkpointing works.
.. warning::
Checkpointing currently only supports :func:`torch.autograd.backward`
and only if its `inputs` argument is not passed. :func:`torch.autograd.grad`
is not supported.
.. warning:
At least one of the inputs needs to have :code:`requires_grad=True` if
grads are needed for model inputs, otherwise the checkpointed part of the
model won't have gradients.
.. warning:
Since PyTorch 1.4, it allows only one Tensor as the input and
intermediate outputs, just like :class:`torch.nn.Sequential`.
Args:
functions: A :class:`torch.nn.Sequential` or the list of modules or
functions (comprising the model) to run sequentially.
segments: Number of chunks to create in the model
input: A Tensor that is input to :attr:`functions`
preserve_rng_state(bool, optional, default=True): Omit stashing and restoring
the RNG state during each checkpoint.
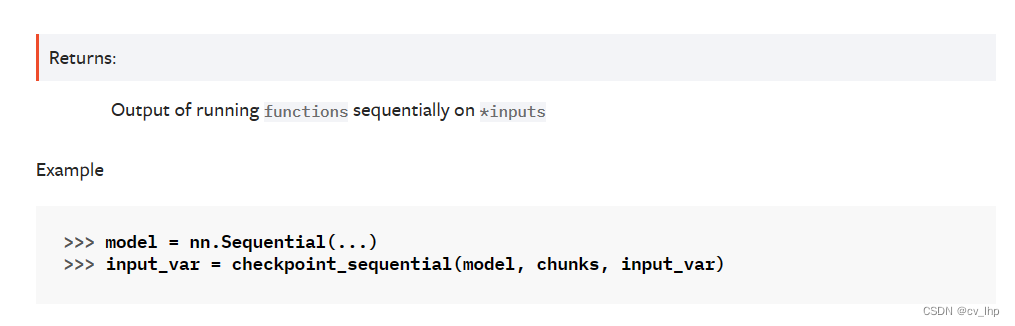
Returns:
Output of running :attr:`functions` sequentially on :attr:`*inputs`
Example:
>>> model = nn.Sequential(...)
>>> input_var = checkpoint_sequential(model, chunks, input_var)
"""
# Hack for keyword-only parameter in a python 2.7-compliant way
preserve = kwargs.pop('preserve_rng_state', True)
if kwargs:
raise ValueError("Unexpected keyword arguments: " + ",".join(arg for arg in kwargs))
def run_function(start, end, functions):
def forward(input):
for j in range(start, end + 1):
input = functions[j](input)
return input
return forward
if isinstance(functions, torch.nn.Sequential):
functions = list(functions.children())
# 获取Sequential的子模块,这里使用children方法,仅获取最外层
segment_size = len(functions) // segments
# the last chunk has to be non-volatile (为什么?似乎加上也是可以的)
end = -1
for start in range(0, segment_size * (segments - 1), segment_size):
end = start + segment_size - 1
# 迭代式的将各个子模块集合使用checkpoint包装并前向传播。
input = checkpoint(run_function(start, end, functions), input,
preserve_rng_state=preserve)
# 剩余的结构不再使用checkpoint
return run_function(end + 1, len(functions) - 1, functions)(input)
4、说明
PyTorch中的检查点(checkpoint)是通过在向后传播过程中重新运行每个检查段的前向传播计算来实现的。这可能导致像RNG状态这样的连续态比没有检查点的状态更高级。默认情况下,检查点包括处理RNG状态的逻辑,这样通过使用RNG(例如通过dropout)进行的检查点传递与非检查点传递相比具有确定的输出。存储和还原RNG状态的逻辑可能会导致性能下降,具体取决于检查点操作的运行时间。如果不需要与非检查点传递相比确定的输出,可以设置preserve_rng_state=False,来忽略在每个检查点期间隐藏和恢复RNG状态。
(简单理解应该是,像dropout这样,每次运行可能结果是不同的,前一次结果可能是要丢弃的,后一次的结果可能又是保留的,而设置preserve_rng_state=True,可以保证在checkpoint里保存dropout这样的RNG状态的逻辑,即前一次丢弃后一次就用丢弃的逻辑,前一次保留后一次就保留。)
隐藏逻辑将当前设备以及所有cuda张量参数的器件备的RNG状态保存并恢复到run_fn。但是,该逻辑无法预料用户是否会在run_fn本身内将张量移动到新器件里,因此,如果在run_fn内将张量移动到新的设备里(新器件指不属于集合[当前器件+张量参数的器件]的器件备),则与非检查点传递相比确定的输出将不再确保是确定的。
(简单理解就是,在run_fn内不要随意修改张量的device,否则preserve_rng_state参数将可能失效,结果是无法事先确定的。)
三. 几个使用示例
注意:第一层建议不要使用checkpoint,dropout和batch normalization层不能用checkpoint(二者起冲突)。
3. 1 示例1
import torch
import torch.nn as nn
import numpy as np
import torch.utils.checkpoint as cp
x = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
x = torch.Tensor(x).float()
y = np.array([1, 0, 0, 1])
y = torch.Tensor(y).long()
class MyNet(nn.Module):
def __init__(self, save_memory=False):
super(MyNet, self).__init__()
self.linear1 = nn.Linear(2, 50)
self.linear2 = nn.Linear(50, 30)
self.linear3 = nn.Linear(30, 2)
self.relu = nn.ReLU()
self.sigmoid = nn.Sigmoid()
self.dropout = nn.Dropout(p=0.5)
self.save_memory = save_memory
def forward(self, x):
if self.save_memory:
x = self.linear1(x)
x = self.relu(x)
x = cp.checkpoint(self.linear2, x)
x = self.dropout(x)
x = cp.checkpoint(self.linear3, x)
else:
x = self.linear1(x)
x = self.relu(x)
x = self.linear2(x)
x = self.dropout(x)
x = self.linear3(x)
return x
net = MyNet(save_memory=True)
# train() enables some modules like dropout, and eval() does the opposit
net.train()
# set the optimizer where lr is the learning-rate
optimizer = torch.optim.SGD(net.parameters(), lr=0.05)
loss_func = nn.CrossEntropyLoss()
for epoch in range(50000):
if epoch % 5000 == 0:
# call eval() and evaluate the model on the validation set
# when calculate the loss value or evaluate the model on the validation set,
# it's suggested to use "with torch.no_grad()" to pretrained the memory. Here I didn't use it.
net.eval()
out = net(x)
loss = loss_func(out, y)
print(loss.detach().numpy())
# call train() and train the model on the training set
net.train()
out = net(x)
loss = loss_func(out, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 5000 == 0:
net.eval()
out = net(x)
loss = loss_func(out, y)
print(loss.detach().numpy())
print('----')
net.train()
if epoch % 1000 == 0:
# adjust the learning-rate
# weight decay every 1000 epochs
lr = optimizer.param_groups[0]['lr']
lr *= 0.9
for param_group in optimizer.param_groups:
param_group['lr'] = lr
net.eval()
print(net(x).data)
3.2 示例2
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.checkpoint import checkpoint
from torchvision.datasets.cifar import CIFAR10
import numpy as np
from progressbar import progressbar
def conv_bn_relu(in_ch, out_ch, ker_sz, stride, pad):
return nn.Sequential(nn.Conv2d(in_ch, out_ch, ker_sz, stride, pad, bias=False),
nn.BatchNorm2d(out_ch),
nn.ReLU())
class NetA(nn.Module):
def __init__(self, use_checkpoint=False):
super().__init__()
self.use_checkpoint = use_checkpoint
k = 2
# 32x32
self.layer1 = conv_bn_relu(3, 32*k, 3, 1, 1)
self.layer2 = conv_bn_relu(32*k, 32*k, 3, 2, 1)
# 16x16
self.layer3 = conv_bn_relu(32*k, 64*k, 3, 1, 1)
self.layer4 = conv_bn_relu(64*k, 64*k, 3, 2, 1)
# 8x8
self.layer5 = conv_bn_relu(64*k, 128*k, 3, 1, 1)
self.layer6 = conv_bn_relu(128*k, 128*k, 3, 2, 1)
# 4x4
self.layer7 = conv_bn_relu(128*k, 256*k, 3, 1, 1)
self.layer8 = conv_bn_relu(256*k, 256*k, 3, 2, 1)
# 1x1
self.layer9 = nn.Linear(256*k, 10)
def seg0(self, y):
y = self.layer1(y)
return y
def seg1(self, y):
y = self.layer2(y)
y = self.layer3(y)
return y
def seg2(self, y):
y = self.layer4(y)
y = self.layer5(y)
return y
def seg3(self, y):
y = self.layer6(y)
y = self.layer7(y)
return y
def seg4(self, y):
y = self.layer8(y)
y = F.adaptive_avg_pool2d(y, 1)
y = torch.flatten(y, 1)
y = self.layer9(y)
return y
def forward(self, x):
y = x
# y = self.layer1(y)
y = y + torch.zeros(1, dtype=y.dtype, device=y.device, requires_grad=True)
if self.use_checkpoint:
# 使用 checkpoint
y = checkpoint(self.seg0, y)
y = checkpoint(self.seg1, y)
y = checkpoint(self.seg2, y)
y = checkpoint(self.seg3, y)
y = checkpoint(self.seg4, y)
else:
# 不使用 checkpoint
y = self.seg0(y)
y = self.seg1(y)
y = self.seg2(y)
y = self.seg3(y)
y = self.seg4(y)
return y
if __name__ == '__main__':
net = NetA(use_checkpoint=True).cuda()
train_dataset = CIFAR10('../datasets/cifar10', True, download=True)
train_x = np.asarray(train_dataset.data, np.uint8)
train_y = np.asarray(train_dataset.targets, np.int)
losser = nn.CrossEntropyLoss()
optim = torch.optim.Adam(net.parameters(), 1e-3)
epoch = 10
batch_size = 31
batch_count = int(np.ceil(len(train_x) / batch_size))
for e_id in range(epoch):
print('epoch', e_id)
print('training')
net.train()
loss_sum = 0
for b_id in progressbar(range(batch_count)):
optim.zero_grad()
batch_x = train_x[batch_size*b_id: batch_size*(b_id+1)]
batch_y = train_y[batch_size*b_id: batch_size*(b_id+1)]
batch_x = torch.from_numpy(batch_x).permute(0, 3, 1, 2).float() / 255.
batch_y = torch.from_numpy(batch_y).long()
batch_x = batch_x.cuda()
batch_y = batch_y.cuda()
batch_x = F.interpolate(batch_x, (224, 224), mode='bilinear')
y = net(batch_x)
loss = losser(y, batch_y)
loss.backward()
optim.step()
loss_sum += loss.item()
print('loss', loss_sum / batch_count)
with torch.no_grad():
print('testing')
net.eval()
acc_sum = 0
for b_id in progressbar(range(batch_count)):
optim.zero_grad()
batch_x = train_x[batch_size * b_id: batch_size * (b_id + 1)]
batch_y = train_y[batch_size * b_id: batch_size * (b_id + 1)]
batch_x = torch.from_numpy(batch_x).permute(0, 3, 1, 2).float() / 255.
batch_y = torch.from_numpy(batch_y).long()
batch_x = batch_x.cuda()
batch_y = batch_y.cuda()
batch_x = F.interpolate(batch_x, (224, 224), mode='bilinear')
y = net(batch_x)
y = torch.topk(y, 1, dim=1).indices
y = y[:, 0]
acc = (y == batch_y).float().sum() / len(batch_x)
acc_sum += acc.item()
print('acc', acc_sum / batch_count)
ids = np.arange(len(train_x))
np.random.shuffle(ids)
train_x = train_x[ids]
train_y = train_y[ids]
3.3 示例3:checkpoint_sequential()的使用
import torch
import torch.nn as nn
from torch.utils.checkpoint import checkpoint_sequential
# a trivial model
model = nn.Sequential(
nn.Linear(100, 50),
nn.ReLU(),
nn.Linear(50, 20),
nn.ReLU(),
nn.Linear(20, 5),
nn.ReLU()
)
# model input
input_var = torch.randn(1, 100, requires_grad=True)
# the number of segments to divide the model into
segments = 2
# finally, apply checkpointing to the model
# note the code that this replaces:
# out = model(input_var)
out = checkpoint_sequential(model , segments, input_var)
# backpropagate
out.sum().backwards()
checkpoint_sequential 替换了 module 对象上的 forward 或 call 方法。out 几乎和我们调用 model(input_var) 时得到的张量一样; 关键的区别在于它缺少了累积值,并且附加了一些额外的元数据,指示 PyTorch 在 out.backward() 期间需要这些值时重新计算。
值得注意的是,checkpoint_sequential 接受整数值的片段数作为输入。checkpoint_sequential 将模型分割成 n 个纵向片段,并对除了最后一个的每个片段应用检查点。
这工作很容易,但有一些主要的限制。你无法控制片段的边界在哪里,也无法对整个模块应用检查点(而是其中的一部分)。
3.4 checkpoint() : 卷积模型的示例
class CIFAR10Model(nn.Module):
def __init__(self):
super().__init__()
self.cnn_block_1 = nn.Sequential(*[
nn.Conv2d(3, 32, 3, padding=1),
nn.ReLU(),
nn.Conv2d(32, 64, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2),
nn.Dropout(0.25)
])
self.cnn_block_2 = nn.Sequential(*[
nn.Conv2d(64, 64, 3, padding=1),
nn.ReLU(),
nn.Conv2d(64, 64, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2),
nn.Dropout(0.25)
])
self.flatten = lambda inp: torch.flatten(inp, 1)
self.head = nn.Sequential(*[
nn.Linear(64 * 8 * 8, 512),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(512, 10)
])
def forward(self, X):
X = self.cnn_block_1(X)
X = self.cnn_block_2(X)
X = self.flatten(X)
X = self.head(X)
return X
这种模型有两个卷积块,一些 dropout,和一个线性层(10个输出对应 CIFAR10 的10类)。
下面是这个模型使用梯度检查点的更新版本:
class CIFAR10Model(nn.Module):
def __init__(self):
super().__init__()
self.cnn_block_1 = nn.Sequential(*[
nn.Conv2d(3, 32, 3, padding=1),
nn.ReLU(),
nn.Conv2d(32, 64, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
])
self.dropout_1 = nn.Dropout(0.25)
self.cnn_block_2 = nn.Sequential(*[
nn.Conv2d(64, 64, 3, padding=1),
nn.ReLU(),
nn.Conv2d(64, 64, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2)
])
self.dropout_2 = nn.Dropout(0.25)
self.flatten = lambda inp: torch.flatten(inp, 1)
self.linearize = nn.Sequential(*[
nn.Linear(64 * 8 * 8, 512),
nn.ReLU()
])
self.dropout_3 = nn.Dropout(0.5)
self.out = nn.Linear(512, 10)
def forward(self, X):
X = self.cnn_block_1(X)
X = self.dropout_1(X)
X = checkpoint(self.cnn_block_2, X)
X = self.dropout_2(X)
X = self.flatten(X)
X = self.linearize(X)
X = self.dropout_3(X)
X = self.out(X)
return X
在 forward 中显示的 checkpoint 接受一个模块(或任何可调用的模块,如函数)及其参数作为输入。参数将在前向时被保存,然后用于在反向时重新计算其输出值。
为了使其能够工作,我们必须对模型定义进行一些额外的更改。
首先,你会注意到我们从卷积块里删除了 nn.Dropout 层; 这是因为检查点与 dropout 不兼容(回想一下,样本有效地通过模型两次 — dropout 会在每次通过时任意丢失不同的值,从而产生不同的输出)。基本上,任何在重新运行时表现出非幂等(non-idempotent )行为的层都不应该应用检查点(nn.BatchNorm 是另一个例子)。解决方案是重构模块,这样问题层就会被排除在检查点片段之外,这正是我们在这里所做的。
其次,你会注意到我们在模型中的第二卷积块上使用了检查点,但是第一个卷积块上没有使用检查点。这是因为检查点简单地通过检查输入张量的 requires_grad 行为来决定它的输入函数是否需要计算梯度(例如,它是否处于 requires_grad=True 或 requires_grad=False模式)。模型的初始输入张量几乎总是处于 requires_grad=False 模式,因为我们感兴趣的是计算相对于网络权重而不是输入样本本身的梯度。因此,模型中的第一个子模块应用检查点没多少意义: 它反而会冻结现有的权重,阻止它们进行任何训练。
更多细节请参考这个 PyTorch 论坛帖子:https://discuss.pytorch.org/t/use-of-torch-utils-checkpoint-checkpoint-causes-simple-model-to-diverge/116271
在 PyTorch 文档(https://pytorch.org/docs/stable/checkpoint.html#)中还讨论了 RNG 状态以及与分离张量不兼容的一些其他细节。
3.5 示例5:对transformer 进行checkpoint() 使用
checkpoint 设置的最佳位置是每一个transformer block,其中计算了多头注意力和 gelu 激活,以及FFN层(线性层):
class ResidualAttentionBlock(nn.Module):
def __init__(self, d_model: int, n_head: int, attn_mask: torch.Tensor = None, dropout = 0., use_checkpoint=False):
super().__init__()
self.attn = nn.MultiheadAttention(d_model, n_head, dropout=dropout) #此处的dropout 是对query和key计算出来的多头注意力分数进行dropout
self.ln_1 = LayerNorm(d_model)
self.drop_path = DropPath(dropout) if dropout > 0. else nn.Identity() #此处的dropout指query经过多头注意力计算出来后得到的值进行dropout,以及经过FFN后进行dropout
self.mlp = nn.Sequential(OrderedDict([
("c_fc", nn.Linear(d_model, d_model * 4)),
("gelu", QuickGELU()),
("c_proj", nn.Linear(d_model * 4, d_model))
]))
self.ln_2 = LayerNorm(d_model)
self.attn_mask = attn_mask
self.control_point = AfterReconstruction(d_model)
self.use_checkpoint = use_checkpoint
def attention(self, x: torch.Tensor):
# x: 50 bT c
self.attn_mask = self.attn_mask.to(dtype=x.dtype, device=x.device) if self.attn_mask is not None else None
return self.attn(x, x, x, need_weights=False, attn_mask=self.attn_mask)[0]
def forward(self, x: torch.Tensor):
x = self.control_point(x)
h = x
if use_checkpoint == True:
attan_out = checkpoint(self.attention,self.ln_1.float()(x))
x = h + self.drop_path(attan_out)
else:
x = h + self.drop_path(self.attention(self.ln_1(x))) #残差连接
x = self.control_point(x)
h = x
if use_checpoint == True:
mlp_out = checkpoint(self.mlp, self.ln_2.float()(x))
x = h + self.drop_path(mlp_out)
else:
x = h + self.drop_path(self.mlp(self.ln_2(x))) #残差连接
return x
对huggingface中的 [pytorch-pretrained-bert] 中的代码进行设置checkpoint,由于 PyTorch 的简单性,它只需要三行即可完成(比 tensorflow 中的方法容易得多!):
import torch.utils
import torch.utils.checkpoint
# change line around 410
hidden_states = layer_module(hidden_states, attention_mask)
# into
hidden_states = torch.utils.checkpoint.checkpoint(layer_module, hidden_states, attention_mask)
四. 基准测试
源代码:https://github.com/spellml/tweet-sentiment-extraction
作为一个快速的基准测试,我在 tweet-sentiment-extraction 上启用了模型检查点,这是一个基于 Twitter 数据的带有 BERT 主干的情感分类器模型。
transformers 库已经将模型检查点checkpoint 作为 API 的一个可选部分来实现;为我们的模型启用它就像翻转一个布尔值标记一样简单,如下所示:
# code from model_5.py
cfg = transformers.PretrainedConfig.get_config_dict("bert-base-uncased")[0]
cfg["output_hidden_states"] = True
cfg["gradient_checkpointing"] = True # NEW!
cfg = transformers.BertConfig.from_dict(cfg)
self.bert = transformers.BertModel.from_pretrained(
"bert-base-uncased", config=cfg
)
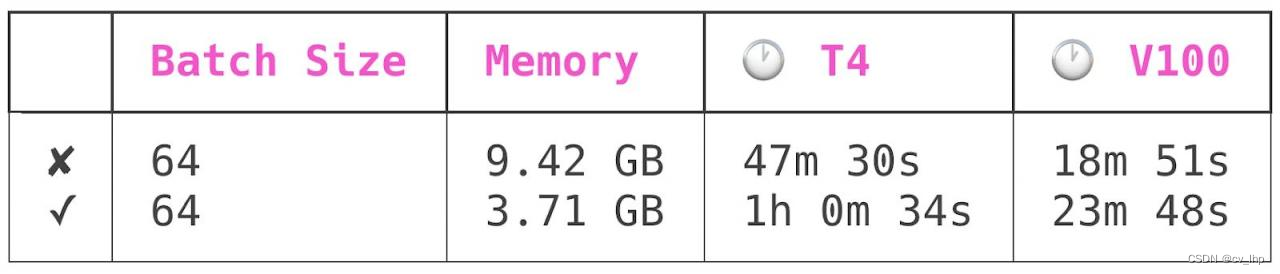
对这个模型进行了四次训练: 分别在 NVIDIA T4和 NVIDIA V100 GPU 上,包括检查点和无检查点模式。所有运行的批次大小为 64。以下是结果:
-
第一行是在模型检查点关闭的情况下进行的训练,第二行是在模型检查点开启的情况下进行的训练。
-
模型检查点降低了峰值模型内存使用量 60% ,同时增加了模型训练时间 25% 。
-
当然,你想要使用检查点的主要原因可能是,这样你就可以在 GPU 上使用更大的批次大小。在另一篇博文:https://qywu.github.io/2019/05/22/explore-gradient-checkpointing.html 中演示了这个很好的例子: 在他们的例子中,每批次样本从 24 个提高到惊人的 132 个!
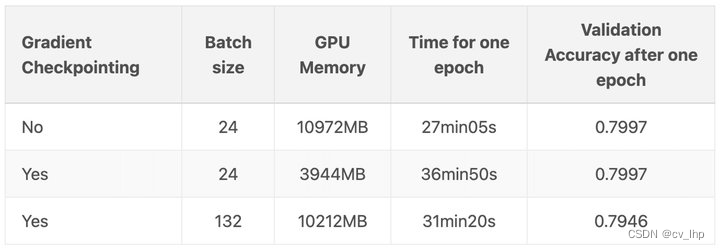
要处理大型神经网络,模型检查点checkpoint 显然是一个非常强大和有用的工具。
使用模型checkpoint后,降低了显存,从而达到增大batch_size的目的,但不会降低模型的准确度,只是会增加模型训练时间。
五. DDP和checkpoint结合使用注意事项
出现报错如下:
RuntimeError: Expected to mark a variable ready only once. This error is caused by one of the following reasons: 1) Use of a module parameter outside the forward function. Please make sure model parameters are not shared across multiple concurrent forward-backward passes. or try to use _set_static_graph() as a workaround if this module graph does not change during training loop.2) Reused parameters in multiple reentrant backward passes. For example, if you use multiple checkpoint functions to wrap the same part of your model, it would result in the same set of parameters been used by different reentrant backward passes multiple times, and hence marking a variable ready multiple times. DDP does not support such use cases in default. You can try to use _set_static_graph() as a workaround if your module graph does not change over iterations.
解决:
查看DDP设置是否设置了find_unused_parameters=True:(model = torch.nn.parallel.DistributedDataParallel(model, find_unused_parameters=True)),
如果设置True,改成False。因为设置True会跟checkpoint的工作原理起冲突,从而报错(在某种程度上 DDP 不知道)。

将find_unused_parameters改成False之后,如果出现模型有些参数为参与计算loss等错误,需要将这部分未参与loss计算的参数给排除掉(未参与loss计算的参数不会进行反向传播计算梯度)。
具体排除方式如下:
# check parameters with no grad
for n, p in model.named_parameters():
if p.grad is None and p.requires_grad is True:
print('No forward parameters:', n, p.shape)
然后把这些没有用到的参数从模型中删除掉(将这段代码放在计算loss.backward()之前打印出来)。
或者将这些未用到的参数,乘以0与模型的loss进行相加,这样从而使为用到的参数也参入了loss计算:
for p in self.parameters():
loss += 0.0 * p.sum()
注意:checkpoint在torch.autograd.grad()中不起作用,但仅适用于torch.autograd.backward()。
参考链接:
- https://github.com/huggingface/transformers/pull/4659
- https://github.com/allenai/longformer/issues/63
- https://stackoverflow.com/questions/68000761/pytorch-ddp-finding-the-cause-of-expected-to-mark-a-variable-ready-only-once
六. 参考链接
- 使用梯度检查点(gradient checkpointing)训练比内存还大的pytorch模型
- PyTorch之Checkpoint机制解析
- GPU显存不够用时,如何用PyTorch训练大模型(torch.utils.checkpoint的使用)
- torch.utils.checkpoint 简介 和 简易使用
- Explore Gradient-Checkpointing in PyTorch
- 网络训练高效内存管理——torch.utils.checkpoint的使用
- PyTorch 之 Checkpoint 机制解析
- pytorch通过torch.utils.checkpoint实现checkpoint功能
- Pytorch节省显存 - checkpoint