基本查询语句
SELECT 语句非常的强大,是最常用的查询语句。他具有一个固定的格式,如下:
SELECT 查询的内容 FROM 数据表名 WHERE >>>(满足的条件) GROUP BY >>>(对结果进行分组) ORDER BY >>> (对结果进行排序)HAVING >>>(满足的第二个条件) LIMIT >>>(限定输出的行数)
- 这里的查询内容为多列时,使用逗号进行分隔,如下:
SELECT ID,NAME FROM STUDENT_TEXT; - 从多个数据表中查找多个信息时,需要指定每个表中的列,并且数据表也使用逗号进行分隔,如下:
SELECT STUDENT_TEXT1.ID,STUDENT_TEXT1.NAME,STUDENT_TEXT2_TEXT.ID FROM STUDENT_TEXT1,STUDENT_TEXT2;
提示:当同时含有WHERE、GROUP BY、HAVING和聚集函数时,首先执行WHERE子句查找符合条件的数据,然后对符合条件的数据进行分组,分组之后形成的组使用聚集函数计算每一组的值,最后使用HAVING子句去掉不符合条件的组。
需要注意的是:
- HAVING 子句中的每一个元素也必须出现在
查询的内容中 ;HAVING 和 WHERE 子句都可用来限制条件,但是HAVING的使用必须建立在使用GROUP BY的基础之上 ,因为HAVING子句限制的是组,而不是行;WHERE 子句不能使用聚集函数,但是在HAVING子句中可以使用。
单表查询
单表查询指从一个表中查询需要的数据。
-
查询所有字段
SELECT * FROM 表名; -
查询指定字段
SELECT 字段名 FROM 表名; -
查询指定数据
SELECT * FROM 表名 WHERE 查询条件;>>> WHERE子句使用时,需要一些比较运算符来确定查询条件。>>> 例如:SELECT * FROM STUDENT_TEXT WHERE NAME="LISI"; -
带关键字IN的查询
SELECT * FROM 表名 WHERE 条件 [NOT] IN (元素1,元素2...);>>> 表示判断元素是否在集合内。>>> 例如:SELECT * FROM WHERE ID IN(1,2,3);扫描二维码关注公众号,回复: 15949982 查看本文章
-
带关键字BETWEEN AND的范围查询
SELECT * FROM 表名 WHERE 条件 [NOT] BETWEEN 取值1 AND 取值2;>>> 查询满足在范围内的条件。>>> 例如:SELECT * FROM WHERE ID BETWEEN 1 AND 5; -
带LIKE的字符匹配查询
SELECT * FROM 表名 WHERE NAME LIKE "%明_";>>>"%"可以匹配一个或多个字符,"-"匹配一个字符。>>> 例如:"%明_"可以匹配***...明* -
用IS NULL关键字查询空值
SELECT * FROM 表名 WHERE 字段名 IS NOT NULL;>>> 查询得字段不为空值>>>例如:SELECT * FROM STUDENT_TEXT WHERE NAME IS NOT NULL; -
带AND的多条件查询
SELECT * FROM 数据名 WHERE 条件1 AND 条件2 [...AND条件表达式n];>>>条件全满足才能被查出来。 -
带OR的多条件查询
SELECT * FROM 数据名 WHERE 条件1 OR 条件2 [...AND条件表达式n];>>> 只要条件有一个满足就能查出来。 -
用DISTINCT关键字去除结果中的重复行
SELECT DISTINCT 字段名 FROM 表名;>>>例如:SELECT DISTINCT NAME FROM STUDENT;表示对NAME字段名重复的行进行合并。 -
用ORDER BY关键字对查询结果排序
SELECT * FROM 表名 ORDER BY [ASC | DESC];>>>DESC(descending order) 表示降序排列,ASC(ascending order)表示升序排列。>>>注意:对排序的列中含有NULL值,如果为升序,NULL放在最前面,如果为降序,NULL放在最后面。 -
用GROUP BY关键字分组查询
SELECT * FROM 表名 GROUP BY 字段名1,字段名2...;>>> 按照哪一列来分类,对多个列用逗号进行分隔。 -
用LIMIT限制查询结果的数量
SELECT * FROM 数据表名 LIMIT 数量;>>> 例如:SELECT * FORM STUDENT LIMIT 3;表示查询数据的前三条。
聚合函数查询
COUNT()函数:COUNT()函数用于对除“*”以外的任何参数,返回所选择的集合中非NULL值得行的数目;如果参数为“*”则返回集合的所用行,包含NULL值的行。没有WHERE子句的COUNT(*)是经过内部优化的,能够快速地返回表中所有的记录总数。
代码如下:
SELECT COUNT(*) FROM 表名 >>>查询表中所有数据行数和。
结果如下:
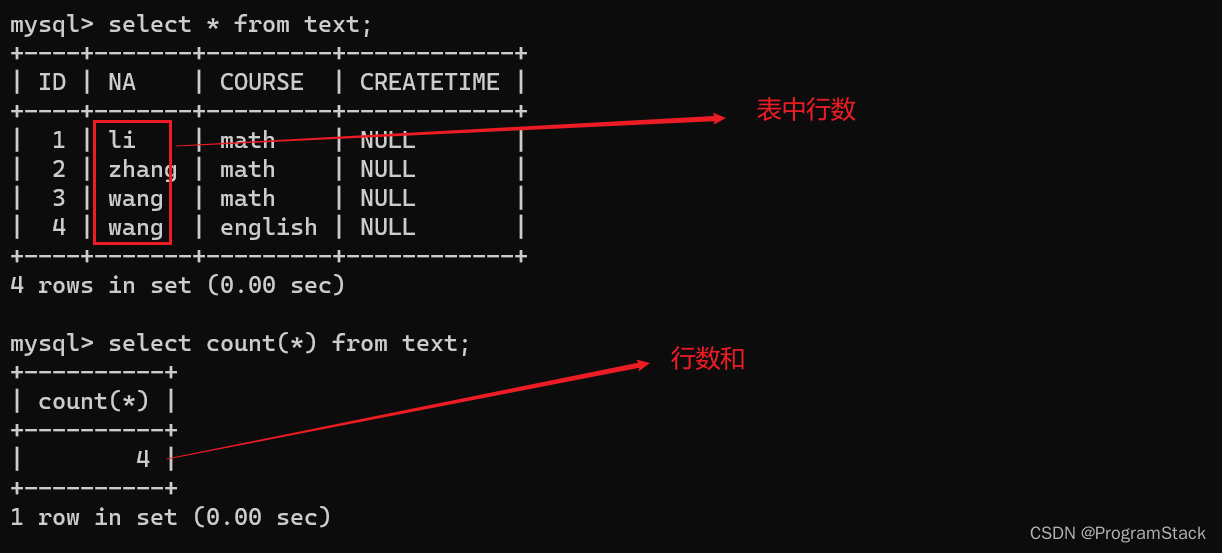
SUM()函数:求表中某个数据类型字段取值的总和。
代码如下:
SELECT SUM(ID) FROM TEXT;
结果如下:
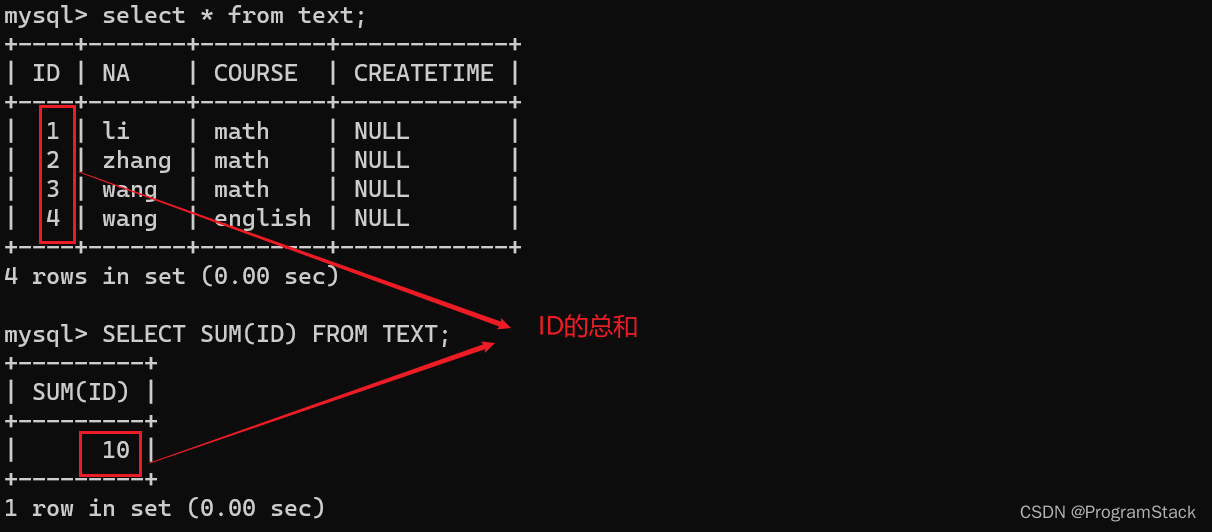
AVG()函数:求出表中某个数值类型字段取值的平均值。
代码如下:
SELECT AVG(ID) FROM TEXT;
结果如下:

MAX()函数:求出表中某个数值类型字段取值的最大值。
代码如下:
SELECT MAX(ID) FROM TEXT;
结果如下:

MIN()函数:求某个数值类型字段取值的最小值。
代码如下:
SELECT MIN(ID) FROM TEXT;
结果如下:
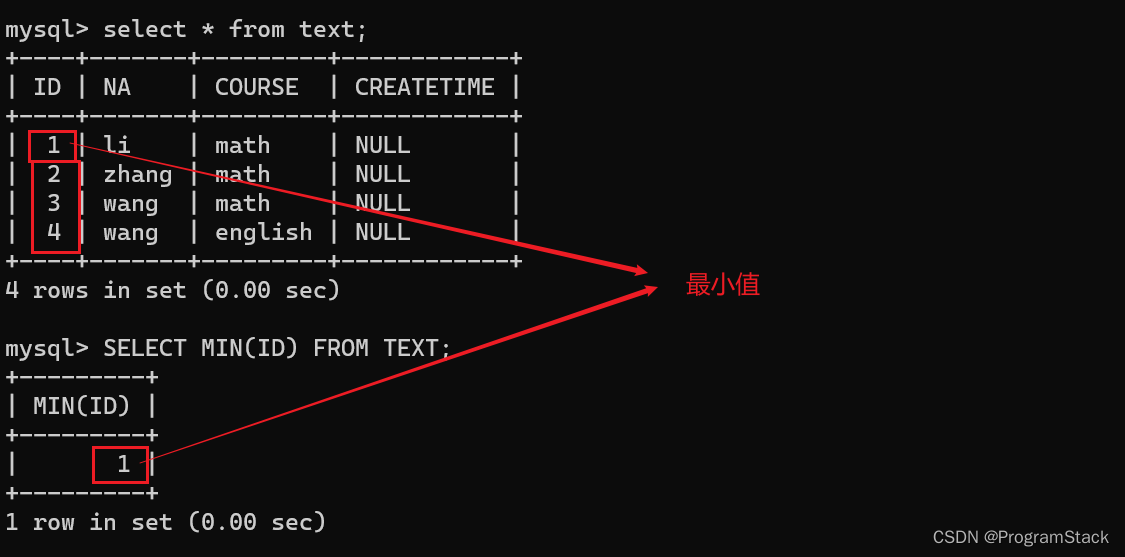
多表连接查询
多表连接查询指把不同表的记录连接到一起。
- 内连接查询
内连接是最普通的连接类型,而且是最匀称的,因为他们要求构成连接的每个表的共有列匹配,不匹配将被排除。内连接包括相等连接和自然连接,最常见的是相等连接,也就是使用等号运算符,根据每个表共有列的值匹配两个表中的行,最后的结果只包含参与连接的表中与指定字段相符的行。
此时数据库中有TEXT 和 TEXT_1 两个数据表:

代码如下:
SELECT NA,SEX,COURSE,CREATETIME FROM TEXT,TEXT_1 WHERE TEXT.NA = TEXT_1.NA1;
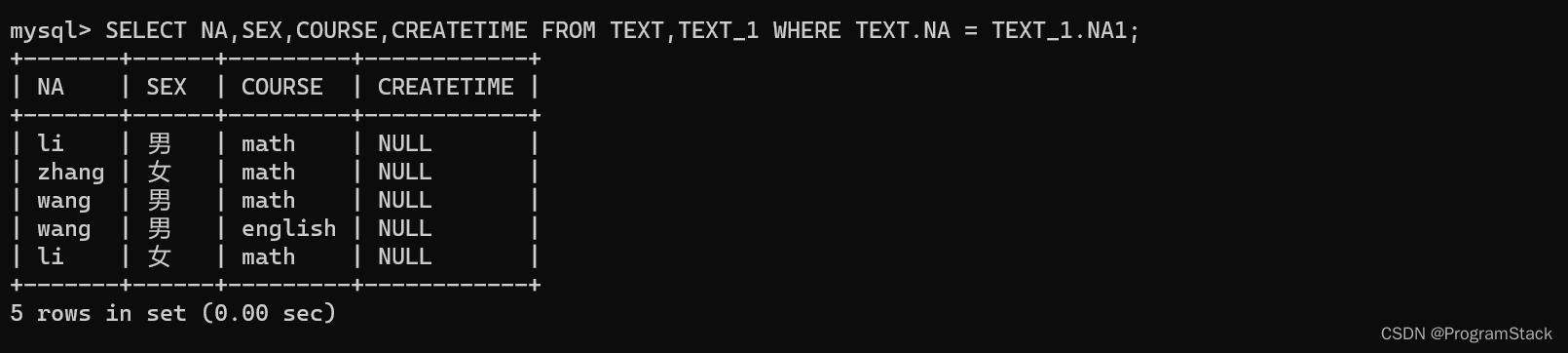
注意:如果要查询表中相同属性的列名下的内容,两个表中的字段名称不能一样,如果一样(都为NA)会报错(
字段列表中的列“NA”不明确)
- 外连接查询
与内连接不同的是,外连接使用OUTER JOIN关键字将两个表连接起来,外连接生成的结果集不仅包括符合连接条件的行数据,而且包括左表(左外连接时的表)、右表(右外连接时的表)或两边连接表(全连接时的表)中所有的数据行。语法格式如下:SELECT 字段名 FROM 表名1 LEFT|RIGHT JOIN 表名2 ON 表名1.字段名 = 表名2.字段名 2;
左外连接(LEFT JOIN): 指的是将左表中的所有数据分别与右表中的每条数据进行连接组合,返回的结果除内连接的数据外,还包括左表中不符合条件的数据,并在右表的相应列中添加NULL值。代码如下:SELECT NA1,SEX,COURSE FROM TEXT_1 LEFT JOIN TEXT ON TEXT_1.NA1 = TEXT.NA;
插入结果:
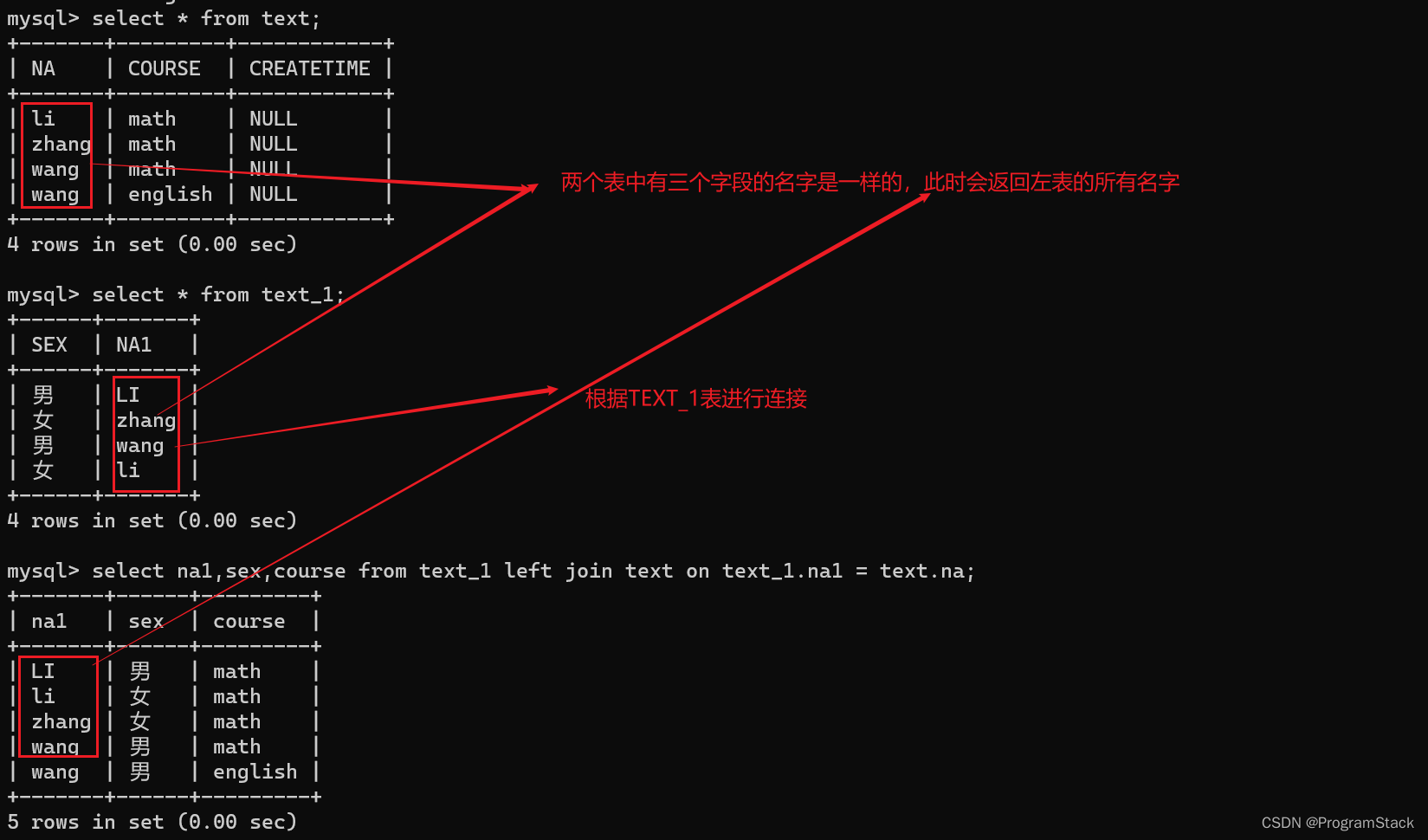
右外连接(RIGHT JOIN):指的是将右表中的所有数据分别与左表中的每条数据进行连接组合,返回的结果除内连接的数据外,还包括右表中不符合条件的数据,并在左表的相应列中添加NULL值。代码如下:SELECT NA,SEX,COURSE FROM TEXT_1 RIGHT JOIN TEXT ON TEXT_1.NA1 = TEXT.NA;
结果如下:
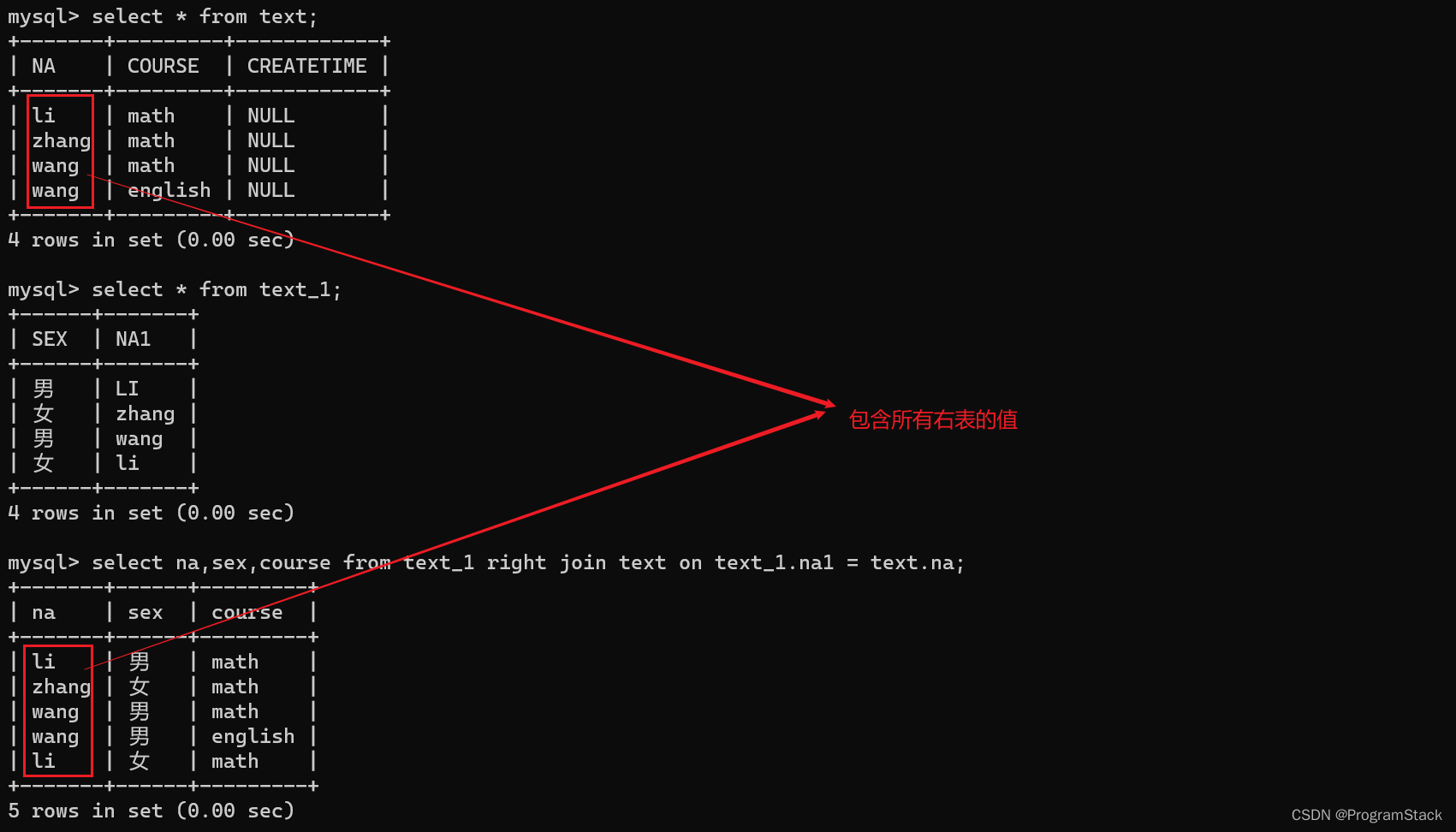
复合条件连接查询:在连接查询时(通常用于内连接),也可以增加其他的限制条件,通过多个条件的复合查询(使用WHERE条件语句等),可以使查询结果更加准确。
子查询
子查询就是多个SELECT查询的嵌套,在外面一层的查询中使用里面一层查询产生的结果集。子查询和常规的SELECT查询的执行方式一样,必须包含一个字段列表、一个或多个表名字的FROM子句以及可选的WHERE、HAVING、GROUP BY子句,而且也可以使用关键字进行查询,但是他必须由父查询包围。他的执行方式为从最内层查询开始,然后逐步向外扩展,每个查询产生的结果集都被赋给包围它的父查询,接着这个父查询被执行,其结果也被指定给它的父查询。
-
带IN关键字的子查询
SELECT * FROM 表名 WHERE 条件 [NOT] IN (SELCET语句);>>> 检测结果集中是否存在某个特定的值,如果检测成功则执行外部的查询。 -
带比较运算符的子查询
SELECT * FROM 表名 WHERE 字段名 比较运算符 (SELECT语句); -
带EXISTS关键字的子查询
SELECT * FROM 表名 WHERE EXISTS(SELECT语句);>>>使用EXISTS关键字时,内层查询语句不返回查询的记录,而是返回一个布尔值。如果内层查询语句查询到满足条件的,就返回一个True,此时外层查询执行操作。反之,则为False,此时外层不执行操作或没有查询结果。 -
带ANY关键字的子查询
SELCECT * FROM 表名 WHERE 字段名 比较运算符 ANY (SELECT语句);>>>ANY表示满足其中任意一个条件,通常与比较运算符一起使用,只要满足内层查询语句返回的结果中的任意一个,就可以执行外层查询。 -
带ALL关键字的子查询
SELCECT * FROM 表名 WHERE 字段名 比较运算符 ALL (SELECT语句);>>>ALL表示满足所有内层查询的返回结果,则执行外层查询。
合并查询结果
合并查询结果时将多个SELECT语句的查询结果合并到一起。使用UNION 和 UNION ALL关键字。
- UNION关键字
SELECT语句 UNION SELECT语句;>>>UNION关键字表示将所有的查询结果合并到一起,然后去除相同的记录。 - UNION ALL关键字
SELECT语句 UNION ALL SELECT语句;>>>UNION ALL 关键字只是简单的将结果合并到一起。
定义表和字段的别名
- 表的别名
查询时,可以为表和字段取一个别名,这个别名可以代替其指定的表和字段。为表进行取别名,可以使查询更加的方便,而且可以时查询结果以更加合理的方式显示。通常在表的连接时使用。
SELECT 字段名 FROM 表名1 AS 别名1 LEFT | RIGHT JOIN 表名2 AS 别名2 ON 别名1.字段名 = 别名2.字段名;>>> AS可以使用空格进行代替。
- 字段的别名
查询时字段名会显示默认情况下定义的列名,同样可以为这个列取别名,方便结果的显示与查询。在使用聚合函数的时候,也可以为其取别名。
SELECT 字段名 AS 别名1,聚合函数 AS 别名2 FROM 表名;>>>AS可以使用空格进行代替。
使用正则表达式查询
正则表达式时用某种匹配模式去匹配一类字符串的一个方式。正则表达式的查询能力比通配字符(LIKE的匹配模式)的查询能力更加强大,而且更加灵活。
SELECT * FROM 表名 WHERE 字段名 REGEXP "匹配方式";>>>匹配方式如下:
| 模式字符 | 含义 |
|---|---|
| ^ | 匹配以特定字符或字符串开头的记录 |
| $ | 匹配以特定字符或字符串结尾的记录 |
| . | 匹配字符串的任意一个字符,包括回车和换行符 |
| [字符集合] | 匹配“字符集合”中的任意一个字符 |
| [^字符集合] | 匹配除“字符集合”以外的任意一个字符 |
| S1|S2|S3 | 匹配S1、S2、S3中的任意一个字符串 |
| * | 匹配多个该符号之前的字符,包括0个或1个 |
| + | 匹配多个该符号前的字符,包括1个 |
| ? | 匹配0个或一个该字符 |
| 字符串{N} | 匹配字符串出现N次 |
| 字符串{M,N} | 匹配字符串出现至少M次,最多N次 |
提示:正则中
*、+匹配默认为贪婪模式,如果使用非贪婪需要在后面加"?"