1.概念
指令在执行时常常因为一些限制而等待。例如,MEM单元访问的数据不在cache中,需要从外部存储器中取,这个过程通常需要几十、几百个Cycle,如果是顺序执行的内核,后面的指令都要等待,而如果处理器足够智能,就可以先执行后面不依赖该数据的指令,这就是处理器的乱序执行。
是在执行阶段乱序,而取指令和提交指令都是顺序的。
2.指令相关性
相关是影响乱序调度的罪魁祸首,如果指令2的执行需要依赖指令1的结果,我们就说这两条指令是相关的,指令2必须在指令1后面执行,无法乱序。
下图描述了指令间的相关性:
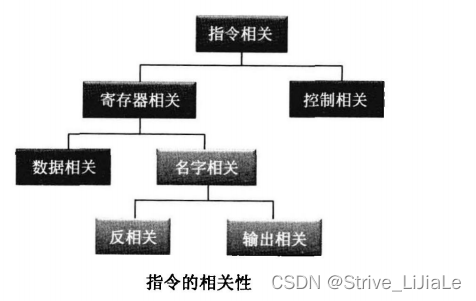
2.1 寄存器相关
当两条语句没有共用寄存器时,它们之间是不相关的,而当两条语句共用寄存器时,它们就有可能相关。
(1)先读后读
ADD BX, AX;将AX和BX相加,存放到BX中(前面的寄存器为目的寄存器)
ADD Cx, Ax;将AX和CX相加,存放到CX中
没有相关性
(2)先写后读(RAW)
ADD Bx, AX;将Ax和 BX相加,存放到BX中
ADD cx, Bx;将BX和 CX相加,存放到CX中这两条指令都用到 BX,指令1输出 BX给指令2用,它们之间有数据流动,存在依赖性,因此也称为数据相关。
(3)先写后读(WAR)
ADD BX, Ax:将AX和BX相加,存放到BX中
MOV Ax, Cx;将Cx的值赋给AX
这两条指令都用到AX,指令1读AX,指令2写AX,如果直接将两条语句调转,执行结果自然是不一样的,因此它们具有相关性。不过如果仔细分析一下,这两条语句之间并没有数据流向,在逻辑上并没有相关性,引起它们相关性的原因在于: x86处理器对程序员可见的通用寄存器太少了,指令不得不共用寄存器,这样才导致指令间存在相关。WAR和RAW相反,因此这种相关也称为反相关(Anti Dependencies)。
(4)先写后写
MOV Ax, BX;将BX的值赋给AX
MOV Ax, cx;将CcX的值赋给AX
这两条指令都向AX中写,和 WAR一样,WAW的两条指令间也没有数据流动,它们的相关是因为有相同的输出寄存器,因此被称为输出相关(Output Dependencies)。
WAR和 WAW没有逻辑上的相关性,只是由于共用了同一个寄存器而存在相关性,它们被称为伪相关(False Dependencies)或者名字相关(Name Dependencies)。
可通过重命名方式解决(见下文3.去除相关性)
2.2 控制相关
JNZ label
……
label:XORJNZ是个条件跳转语句,XOR指令的执行需要依赖于JNZ的结果,这种相关性是由指令的控制流决定的,因此被称为控制相关。
3.去除指令相关性
这些指令的相关性限制了指令的乱序调度与并行调度,需要去除这些相关以达到较好的指令调度。
处理器的ISA寄存器数目通常较少,编译器在将程序中的变量映射到寄存器时,会导致多个变量对应同一个寄存器,这样即使是不相关的指令,也会使用同样的寄存器,导0了名字相关。知道了这个病根,我们就能对症下药,将ISA寄存器重新映射到处理器内部的物理寄存器,由于物理寄存器较多,相同的ISA寄存器可以映射到不同的物理寄存器,经过映射后,新的指令就能使用不同的物理寄存器,指令间的相关性也就消除了。
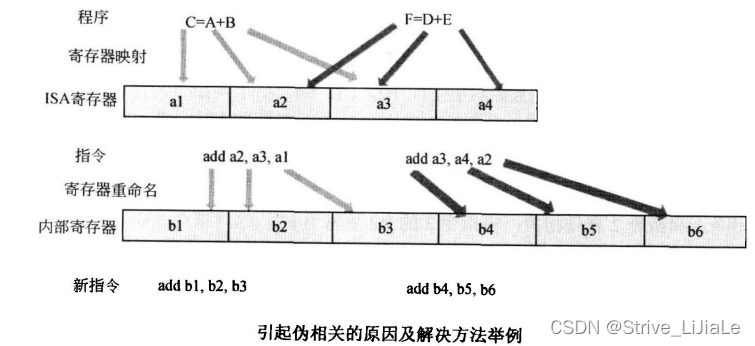 在上图中,两条语句C=A+B和F=D+E本来是不相关的,但是由于ISA寄存器太少,变量映射到同一个寄存器上,采用寄存器重命名,将ISA寄存器映射到新的物理寄存器上,这样新的指令就不再相关了。
在上图中,两条语句C=A+B和F=D+E本来是不相关的,但是由于ISA寄存器太少,变量映射到同一个寄存器上,采用寄存器重命名,将ISA寄存器映射到新的物理寄存器上,这样新的指令就不再相关了。
这里介绍一种在处理器中经常实现的策略:
(1)将每条指令的目的寄存器映射到新的物理寄存器。
(2)指令的源寄存器映射为ISA寄存器最近映射到的那个物理寄存器。
(3)当本条指令完成后,该目的寄存器映射的更早的物理寄存器就可以释放了文字还是太抽象,看图有真相:

在这个例子中,指令的第一个寄存器是目的寄存器,后两个是源寄存器,R1、R2、R3、R4是ISA寄存器,F1…F16是物理寄存器。
R1,R2,R3,R4一开始被映射到F1,F2,F3,F4,第1条指令的目的寄存器是R3,因此将R3重新映射到F5,图中的粗体表示对目的寄存器重新映射。第2条指令的源操作数需要访问R3,就使用R3的最新映射值——-F5,这样就保证了指令2和指令1的数据相关性。
指令3和指令2有反相关,将指令3的R2映射为F7,这样指令3和指令⒉就没有相关性了,即使指令3在指令2前面执行,也不会影响指令2的结果。
指令4和指令3有输出相关,经过寄存器重命名后,指令4和指令3的R2分别对应不同的物理寄存器,它们之间的相关性就去除了。
同样的原理,指令4和指令5的相关性被保留。
如果按照这种方式映射下去,物理寄存器自然会被使用完。因此,需要实时的释放,以备重新分配。R4一开始映射到F4,当第2条指令执行完成后,R4的值就在F6中了,以后访问R4时,都会使用最新的F6,而不会使用F4,这样F4就可以被释放了。
在这种策略中,指令完全不需要访问ISA寄存器,只需要访问物理寄存器。
4. 乱序执行
4.1 Buffer的作用——去耦合
在顺序执行内核中,指令依次流经各个流水线单元,不需要进行缓存,而为了要能乱序执行,首先需要一个Buffer来缓存还没有执行的指令,然后在这个 Buffer中去调度指令的执行顺序。乱序执行内核的基本模型如下:

Buffer的两大功能:
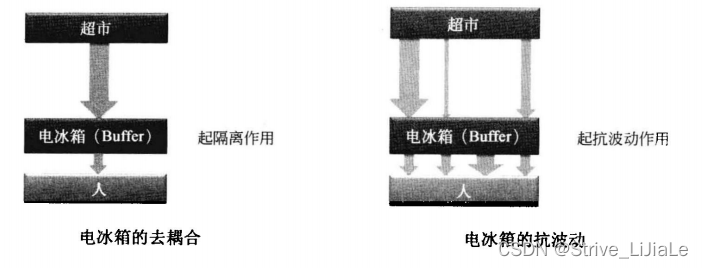
(1)去耦合
(2)抗波动
如果没有电冰箱,每次我们想吃东西时,都要去超市,用专业术语来讲,这就是耦合性太强了,如果超市关门了怎么办?如果超市太远了怎么办?有了电冰箱后,从超市买的食物就放在电冰箱中,我们就直接从电冰箱中取食物,而不需要关注超市的状况了。电冰箱去除了人和超市的耦合。
正常情况下,我们是每天买每天的食物,不过有时候,我们知道明天会有事情,没有时间买食物,因此今天就把今、明两天的食物都买了,这样明天就不会饿肚子了,这就是电冰箱的抗波动功能。
4.2 指令调度
处理器的乱序执行内核也需要一-个调度器,分析指令间的相关性,分析指令什么时候能开始执行。
指令什么时候能开始执行呢?
对于一条指令来说,它有操作码和操作数,操作码描述指令要做什么,处理器会安排一个功能单元(function unit)去执行它。操作数描述指令要处理什么数据,经过寄存器重命名后,目的寄存器总是新的,因此只需要关注源操作数是否准备好即可。所以,指令能否开始执行,依赖于两个条件:
(1)是否有空闲的功能单元去执行这条指令。
(2)该指令的源操作数是否已经准备好。
只要满足这两条要求,指令就可以去执行,而不需要等待前面的指令完成。这样处理器就完成了乱序调度及并行调度。
以前面经过寄存器重命名的指令为例,

处理器会记录指令源操作数的准备状态,当指令1完成后,处理器会通知所有依赖F5的指令,F5已经准备好了,指令2需要的两个源操作数F5和F2都已准备好,它就可以被发送到指令的执行队列中去执行。同样,指令3也可以准备执行,如果处理器中有多个加法单元,指令2和指令3就可以同时执行。指令2完成后,F6也准备好了,指令4就可以去执行,指令4执行完后,F8就准备好了,F5早就准备好了,指令5就可以去执行。在这个调度的例子中,5条指令4个Cycle就可以完成,而使用顺序内核,则需要5个Cycle。
处理器内部需要一个 Buffer来缓存指令,以供乱序调度,这个Buffer就是保留站(Reservation Station),完成寄存器重命名后的指令被放置在保留站中,等到操作数和功能单元都准备好时,保留站中的指令就能被分派出去执行。
4.3 指令的顺序提交
在指令的执行过程中,通常会有中断和异常产生,如在下面的这个例子中,
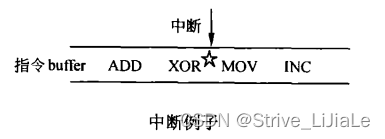
XOR指令执行完后,来了一个中断,中断处理一般都是将处理器的ISA寄存器压栈,执行中断服务程序,然后再退回来执行中断后面的指令。精确中断(Precise Interrupt)要求中断前的指令都执行,中断后的指令都没有执行,而在乱序执行内核中,MOV、INC指令有可能提前到XOR前面执行,那么怎么来实现精确中断呢?
解决方法就是:在指令乱序执行之后,再加一个步骤:指令顺序提交(In-order commit)。乱序执行后,指令的结果虽然出来了,但是这个结果并没有立即提交到ISA寄存器中,而是先缓存起来,只有当前指令前面的指令提交后,这条指令才能提交。
指令的顺序提交也能解决投机执行出错的问题,如下图所示:

分支预测单元预测到JNZ跳转到XOR处执行,乱序执行让XOR指令在ADD前面执行,不过天有不测风云,处理器执行到JNZ时,发现分支预测单元预测错了,实际上应该执行的是MOV这个分支,使用顺序提交策略,JNZ后面指令的结果都没有提交,可以直接抛弃,重新开始执行MOV这条路径即可。
为了实现指令的顺序提交,处理器内部使用了一一个Buffer,叫做重排序缓冲区(ROB,Re-order Buffer),多数的学术文章都叫这个名字,龙芯把这个buffer叫做Reorder Queue,简称ROQ(总要有所区别嘛)。
4.4 总体框架
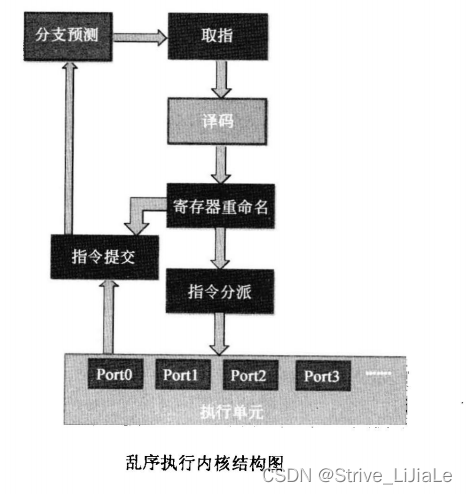
取指、译码、分支预测和顺序执行内核一样。
译码后,指令经过寄存器重命名,去除伪相关,然后进入指令分派模块,指令分派模块决定什么时候将指令分派到什么执行单元去执行。指令同时会进入指令提交单元,它记录了指令的原始顺序,用于指令的顺序提交,同时它会将分支指令的实际执行信息更新到分支预测单元。
下一步,用C语言代码的进行算法实现。