1.多发射muti-issue
在前面的乱序执行内核中,每个cycle最多只发射一条指令,即使有时很多指令并行,平均的指令执行效率也最多只有每个cycle一条指令。如果发射单元一次可以发射多条指令,那么就有更多指令能并行处理了。
(1)超标量(superscalar)
(2)VLIW
如果将指令的并行化显示的声明在指令格式中,处理器只是傻乎乎的执行,即,程序员手动写并行汇编代码,然后定义为并行指令。
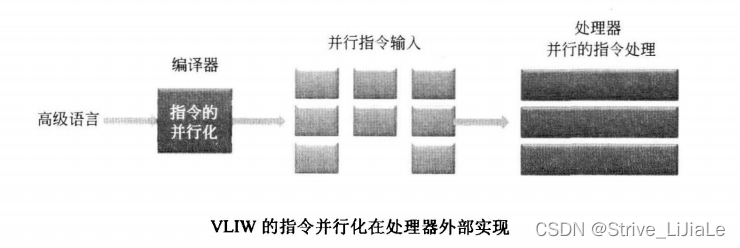
LDH .D1*A5++,A0
|| LDH .D2*B6++,B1指令前面的“||”表示这条指令核上条指令在同一个Cycle执行,如果没有“||”,则表示这条指令在下一个Cycle执行。每条指令32位,“||”在第0位表示,处理器只需按照指令规则执行即可。
2.superscalar处理器
(1)以P4COU为例:
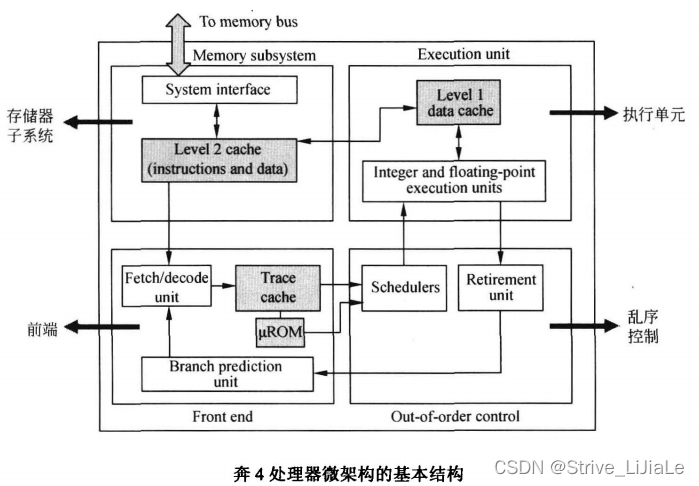
主要分为存储子系统、前端、后端;
前端用来准备指令,包括取值、译码、分支预测;后端包括执行单元和乱序控制。
(2)译码
超标量处理器需要一次对多条指令进行译码,对于定长编码的指令,每条指令的bit数是固定的,只需要多增加几套译码电路就能实现多条指令并性的译码。
而对于变长编码,不知道哪几个是第一条指令的,无从解起。
所以需要对指令的起始位进行标识,指令从内存读入到Cache中时,就开始预解码。预译码标识连同指令一起存储在指令Cache中。
Intel 的处理器则采用多级译码流水线的方式来实现译码。第一级先检测出指令的起始和结束位置,第二级将指令解码为uop。
一条x86 CISC指令通常对应多条uop。当一条CISC指令生成的uop数目多于4条时,就将这些CISC指令对应的uop存储在micro-ROM (uROM)中,解码时使用查表的方式从micro-ROM中得到,这样就简化了复杂指令的译码过程。
(3)Trace Cache
解码后的uop被存储在Trace Cache,和Cache不同的是,该存储的指令顺序不是指令的地址顺序,而是指令的执行顺序。而且存储的不是原来的指令,而是译码后的微操作。
(4)前端流水线
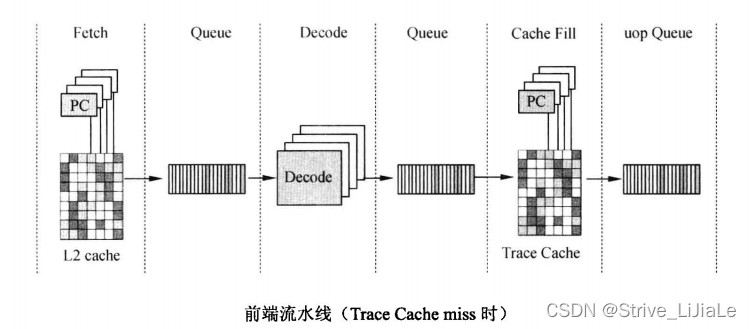
1)从L2Cache中读指令,然后放入队列Buffer中(起到对速度平滑)。
2)Decode从队列中取出指令进行译码
3)将译码后的指令也放入队列中
4)按照uop的执行顺序存入Trace Cache中
5)然后再从Trace Cache中取出放入uop Queue中
(5)后端流水线
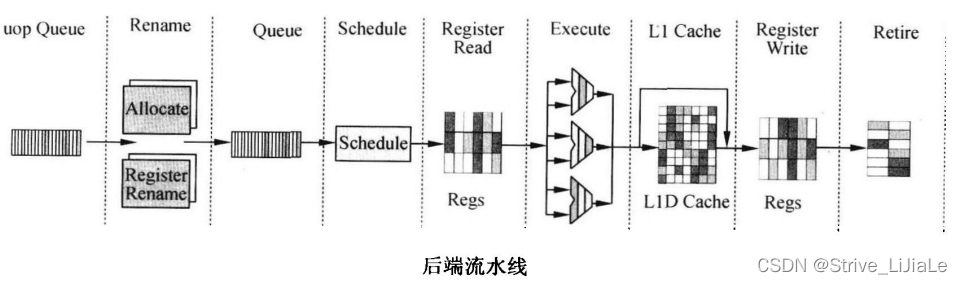
1)当uop进入后端时,先进行资源的分配,利用Buffer来调度分配,如果需要在ROB
中有一个位置,逻辑寄存器需要使用到物理寄存器,,内存操作需要Load/Store Buffer,
2)uop被寄存器重命名,映射关系被保存到RAT(Register Alias Table)中。
3)指令的调度是乱序执行的核心,调度器根据iop操作数的准备情况和执行单元的准
备情况来决定uop什么时候执行。 如内存访问和ALU指令放在不同的队列中
4)调度器连接了4个Dispatch Ports(分派口),不同类型的指令由不同的Dispatch Port分派,如下图所示:
Exec Port0和Exec Port 1用于分派ALU uop,Load Port用于分派Load uop,Store Port用于分派Store uop。ALU(double speed)表示Exec Port每半个Cycle就能分派1个简单的ALUuop,于是在最理想的情况下,Exec Port 0和Exec Port 1每个Cycle分别发射两条uop,Load Port和Store Port每个Cycle分别发射1条uop,所以1个Cycle最多能发射6条uop。不过这只是理论上的情况,实际情况由于指令的依赖性,远远达不到6条uop并行。实时上,处理器流水线每个阶段能并行处理的最大指令数都不一样,如 Trace Cache -一个 Cycle输出3条uop,因此Intel处理器几乎在每个阶段都有Buffer 来隔离它们之间的速率偏差。
5)后面的 Register Read、Execute、L1 Cache (MEM)、Register Write和经典的MIPS 5级流水线类似。
6)乱序执行内核的最后一步,就是Retire(退出),它负责更新ISA寄存器状态,指令按照顺序退出乱序执行内核。Allocate、Register Rename、Schedule、Retire组成了乱序控制。
P4处理器实际的流水线达到了20级,比上面的介绍要更为复杂。
3.VLIW处理器实例
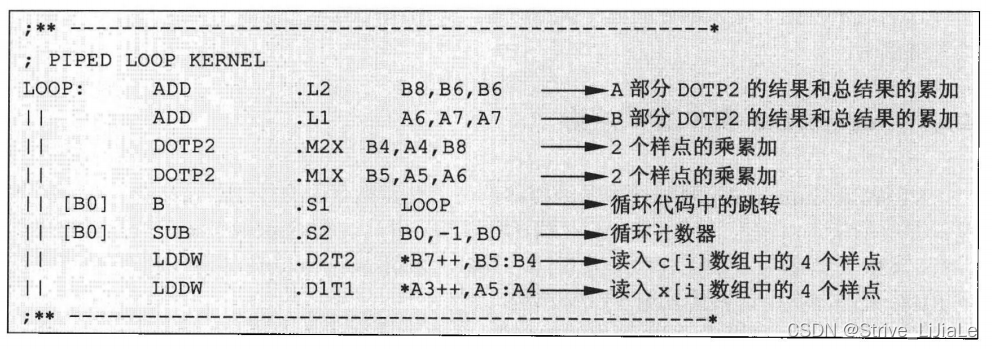
DSP最重要的任务是执行数字信号处理算法,数字信号处理中的典型算法是FIR滤波:
从中我们可以看到: 8个功能单元全速并行执行,效率达到最优。怎样才能达到这么高的并行度呢?
编译器采用了优化循环的两种做法:循环展开和软件流水。
编译器在处理这个循环时,将这个循环展开了4次:

DSP中有很多的功能单元,循环展开后,就可以充分利用这些功能单元一次处理更多的数据。count如果不是4的整数倍,可以拆成两部分,一部分是4的整数倍;另一部分是余下的内容。
软件流水是编译器优化循环代码的一种指令调度策略,用于在循环的多次迭代中提高指令的并行性。硬件流水前面已经介绍过,软件流水顾名思义,就是对软件(这里特指循环)进行类似的流水线调度。软件流水也称为循环级并行。
每次循环称为一次迭代(Iteration),每次迭代执行3条指令:K1,K2,K3(如取数、计算、存数)。
下面我们分析FIR滤波器的8条指令并行是怎么实现的。下面的代码中,箭头后面为每条指令的描述: