本节内容:
- 为什么会有字符编码
- 编码介绍
- Python默认编码
- Python中编码和解码概念
- 文件从磁盘到内存的编码
刚学编程的时候,被编码问题搞的一头雾水,感觉一会这样一会那样,稍微不注意就乱了。现在就捋一捋这个问题的来龙去脉。
为什么会有字符编码
众所周知计算机只能识别二进制0和1,而人只能识别字符,所以源码要从字符“翻译”成二进制。但是人类又有多门语言英文、中文、拉丁文、日文、德文等等。所以就会出现多个人类语言字符都要转换为二进制这种情况。
编码介绍
1、ASCII
由于计算机是由美国人先使用的,所以设计之初ASCII只包含英文字符、数字及其特殊符号,是美国的一套标准。是一个字符使用一个字节8位二进制来表示
例如:大写字母A 8位二进制表示为01000001
由于设计之初就没有考虑到其他国家的字符,所以ascii码只能表示英文,不能用来表示中文
2、GBK2312
既然美国人的那一套不能适用于中文,那就出一套中文的标准吧,所以GBK2312应运而生,GBK2312是中文的标准,一个字符使用2个字节 16位二进制表示
3、Unicode
英文、中文的编码有了,那其他国家也有自己的一套编码标准,这样就会出现不统一,怎么办?这个时候就出现了Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536。
4、Utf-8
UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...
Python编码情况
Python2
Python2默认使用ASCII码
如果在Python2中
#!/usr/bin/env python
print "你好,中国"将会报错,需要告诉Python解释器编码为utf-8
#!/usr/bin/env python
# -*- coding: utf-8 -*-
print "你好,世界"Python3
Python3中默认编码方式为utf-8,但字符串编码为Unicode
python3.x
int 编码方式为utf-8
str 编码方式为Unicode
bytes 编码方式为非Unicode,可以指定utf-8 gbk gbk2312这些编码方式
boole 编码方式为utf-8
list 编码方式为utf-8
tuple 编码方式为utf-8
dict 编码方式为utf-8
python中进行编码和解码
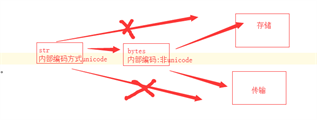
Unicode数据使用的是Unicode编码,而bytes数据使用的是(utf-8,ascii,gbk)其中一种编码
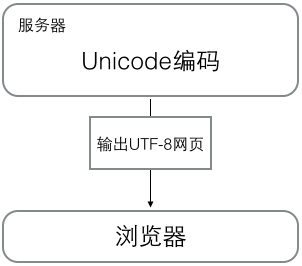
Unicode数据是用于显示到界面,bytes数据是用于传输和保存
当计算机在工作时,内存中的数据一直是以Unicode数据,即以Unicode编码方式的数据,当数据要保存到磁盘或者网络传输时,才会使用bytes数据即使用(utf-8,ascii,gbk)编码进行操作。

python3.x
python3有两种字符串类型:str和bytes类型
str类型存储Unicode数据,使用的是unicode编码,用于显示。
bytes类型存储bytes数据,使用的是utf-8 gbk ascii用于传输和保存
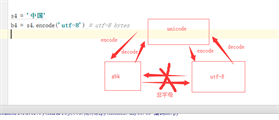
s1 = '马云'
print(s1, type(s1)) # 马云 <class 'str'>
b1 = s1.encode('utf-8')
print(b1, type(b1)) # b'\xe9\xa9\xac\xe4\xba\x91' <class 'bytes'>
s2 = b1.decode()
print(s2, type(s2)) # 马云 <class 'str'>从结果看:
s1是str类型 存储是Unicode数据 使用Unicode编码
b1是bytes类型 存储的是bytes数据 使用utf-8编码
s2是str类型 存储是Unicode数据 使用Unicode编码
Python2.x
python2有两种字符串类型:str和unicode类型,str存储bytes数据用于传输和保存,unicode存储unicode数据,用于进行显示
#!/usr/bin/env python
s1 = '马云' # SyntaxError: Non-ASCII character '\xe9' in file
print(s1, type(s1))在python2中直接会报错,因为python2默认编码是ascii,无法识别中文,要声明中文必须这样
#!/usr/bin/env python
# -*-coding:utf-8-*-
s1 = '马云'
print(s1, type(s1)) # '\xe9\xa9\xac\xe4\xba\x91', <type 'str'>
b1 = s1.decode('utf-8')
print(b1, type(b1)) # u'\u9a6c\u4e91', <type 'unicode'>
s2 = b1.encode('utf-8')
print(s2, type(s2)) # '\xe9\xa9\xac\xe4\xba\x91', <type 'str'>
从结果上看:
s1是str类型 存储是bytes数据,使用utf-8编码
b1是Unicode类型,存储是unicode数据,使用Unicode编码
s2是str类型 存储是bytes数据,使用utf-8编码
通过python2和python3分析后我们
得出结论:
| 分类 | 编码角度 | 数据角度 |
|---|---|---|
| 编码encode | unicode编码--->(utf-8、ascii、gbk)编码 | unicode数据--->bytes数据 |
| 解码decode | (utf-8、ascii、gbk)编码--->unicode编码 | bytes数据--->unicode数据 |
文件从磁盘到内存的编码
当我们在编辑文本的时候,字符在内存对应的是unicode编码的,这是因为unicode覆盖范围最广,几乎所有字符都可以显示。但是,当我们将文本等保存在磁盘时,数据是怎么变化的?
答案是通过某种编码方式编码的bytes字节串。比如utf-8,一种可变长编码,很好的节省了空间;当然还有历史产物的gbk编码等等。于是,在我们的文本编辑器软件都有默认的保存文件的编码方式,比如utf-8,比如gbk。当我们点击保存的时候,这些编辑软件已经"默默地"帮我们做了编码工作。
那当我们再打开这个文件时,软件又默默地给我们做了解码的工作,将数据再解码成unicode,然后就可以呈现明文给用户了!所以,unicode是离用户更近的数据,bytes是离计算机更近的数据。
其实,python解释器也类似于一个文本编辑器,它也有自己默认的编码方式。python2.x默认ASCII码,python3.x默认的utf-8,可以通过如下方式查询:
import sys
print(sys.getdefaultencoding())如果我们不想使用默认的解释器编码,就得需要用户在文件开头声明了。还记得我们经常在python2.x中的声明吗?
#coding:utf-8
如果python2解释器去执行一个utf-8编码的文件,就会以默认的ASCII去解码utf-8,一旦程序中有中文,自然就解码错误了,所以我们在文件开头位置声明 #coding:utf-8,其实就是告诉解释器,你不要以默认的编码方式去解码这个文件,而是以utf-8来解码。而python3的解释器因为默认utf-8编码,所以就方便很多了。