np.random.seed(42)
tf.random.set_seed(42)
这两行代码真是让我着迷了一个晚上。
最近在上手机器学习的东西,然后就需要书写一写tensorflow的代码。
毕竟第一次用tensorflow,也不太明白,也是一直在看文档,但是是照着样例来做的。
然后就照常搭建网络(根据Keras的文档)
import pandas as pd
from sklearn.datasets import fetch_california_housing
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from tensorflow import keras
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# To plot pretty figures
%matplotlib inline
import matplotlib.pyplot as plt
np.random.seed(42)
tf.random.set_seed(42)
#mnist = keras.datasets.mnist
mnist = keras.datasets.fashion_mnist
#文件存放路径,文件默认位置为:~/.keras/datasets
(X_train_full, y_train_full), (X_test, y_test) = mnist.load_data()
#归一化
X_valid, X_train = X_train_full[:5000] / 255., X_train_full[5000:] / 255.
y_valid, y_train = y_train_full[:5000], y_train_full[5000:]
X_test = X_test / 255.
#定义神经网络
model = keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape=[28, 28]))
model.add(keras.layers.Dense(300, activation="relu"))
model.add(keras.layers.Dense(100, activation="relu"))
model.add(keras.layers.Dense(10, activation="softmax"))
#编译模型
model.compile(loss=keras.losses.sparse_categorical_crossentropy,
optimizer=keras.optimizers.SGD(learning_rate = 0.001),
metrics=[keras.metrics.SparseCategoricalAccuracy()])
#训练模型
history = model.fit(X_train, y_train, epochs=5,
validation_data=(X_valid, y_valid))

结果还算正常(这里为了能够快速获得结果,我就训练5次),至此我没有意识到问题的严重性,因为我忽略了文章开头的写的两行代码,我本以为就是产生随机数的,不过也确实,也就是 产 生 随 机 数 的。
但是当我偶然多执行了几次model.fit,却发现结果不是我想的那样——就是每次的loss应该都是1.4968,。
下面这是第二次fit的结果:

下面这是第三次fit的结果:
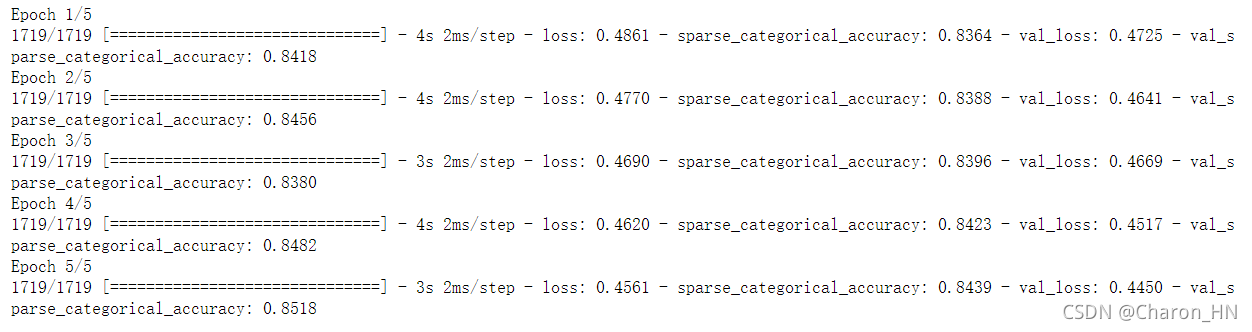
这就导致了什么结果呢???
直到我将这个模型用测试集验证了一下,结果。。。。。。
损失loss直接破1了。。。。(其实在最后fit的过程中loss已经0.1了,过拟合了已经,结果在testset上loss直接到了80)
为什么呢,为什么在fit的过程中loss一直变小呢?我对此不断地调试,结果连续肝了一个晚上,终于,我还是吃了没有仔细读文档和英语不行的亏。
我就在网上找啊,找到了下面这个问题:

然后我又到了Keras的官网文档,里面提到了这个问题:

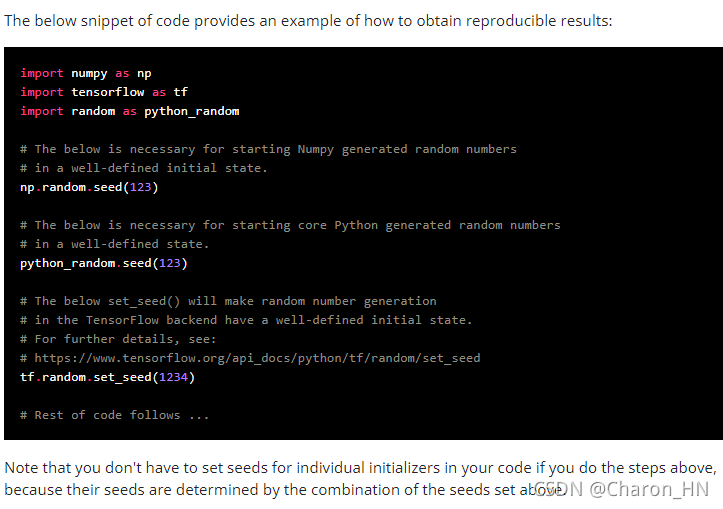

这不正是我的问题吗,这个随机数真的有用的啊!!!!!!!!
然后我又一次次地去尝试,到底是哪个地方需要参数,终于发现原来是建立模型的时候出现的问题
fit方法中有两个参数引起了我的注意:

还是没有提到什么随机数的问题,直到我发现了这个:

或许这个genetator就是问题的关键了。
这也就是为什么要确定随机化的原因了吧。
总结:
要想是每一次都要获得一样结果,就需要每次建立模型,编译,在训练,必须是这个步骤,要不然不是从新开始学习的,是接着上次的学习结果来继续训练的。
也就是说下面的代码要全部执行才能保证是从新开始训练的:
#定义神经网络
model = keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape=[28, 28]))
model.add(keras.layers.Dense(300, activation="relu"))
model.add(keras.layers.Dense(100, activation="relu"))
model.add(keras.layers.Dense(10, activation="softmax"))
#编译模型
model.compile(loss=keras.losses.sparse_categorical_crossentropy,
optimizer=keras.optimizers.SGD(learning_rate = 0.001),
metrics=[keras.metrics.SparseCategoricalAccuracy()])
#训练模型
np.random.seed(42)
tf.random.set_seed(42)
history = model.fit(X_train, y_train, epochs=5,
validation_data=(X_valid, y_valid))
(ps:但是至于是否真的是因为这个地方,我觉得还有待考证,希望大家有问题可以留言指出,一起学习呀)