Kaggle比赛官网:https://www.kaggle.com/c/the-nature-conservancy-fisheries-monitoring
代码:https://github.com/pengpaiSH/Kaggle_NCFM
阅读参考:http://wh1te.me/index.php/2017/02/24/kaggle-ncfm-contest/
相关的课程:http://course.fast.ai/index.html
1. NCFM图像分类任务简介
为了保护和监控海洋环境及生态平衡,大自然保护协会(The Nature Conservancy)邀请Kaggle[1]社区的参赛者们开发能够出机器学习算法,自动分类和识别远洋捕捞船上的摄像头拍摄到的图片中鱼类的品种,例如不同种类的吞拿鱼和鲨鱼。大自然保护协会一共提供了3777张标注的图片作为训练集,这些图片被分为了8类,其中7类是不同种类的海鱼,剩余1类则是不含有鱼的图片,每张图片只属于8类中的某一类别。
图1给出了数据集中的几张图片样例,可以看到,有些图片中待识别的海鱼所占整张图片的一小部分,这就给识别带来了很大的挑战性。此外,为了衡量算法的有效性,还提供了额外的1000张图片作为测试集,参赛者们需要设计出一种图像识别的算法,尽可能地识别出这1000张测试图片属于8类中的哪一类别。Kaggle平台为每一个竞赛都提供了一个榜单(Leaderboard),识别的准确率越高的竞赛者在榜单上的排名越靠前。

图1. NCFM图像分类比赛
2. 问题分析与求解思路
2.1卷积神经网络(ConvNets)
从问题的描述我们可以发现,NCFM竞赛是一个典型的“单标签图像分类”问题,即给定一张图片,系统需要预测出图像属于预先定义类别中的哪一类。在计算机视觉领域,目前解决这类问题的核心技术框架是深度学习(Deep Learning),特别地,针对图像类型的数据,是深度学习中的卷积神经网络(Convolutional Neural Networks, ConvNets)架构(关于卷积神经网络的介绍和算法,这里有个视频教程可以看下:CNN之卷积计算层,本博客也写过:CNN笔记)。
总的来说,卷积神经网络是一种特殊的神经网络结构,即通过卷积操作可以实现对图像特征的自动学习,选取那些有用的视觉特征以最大化图像分类的准确率。
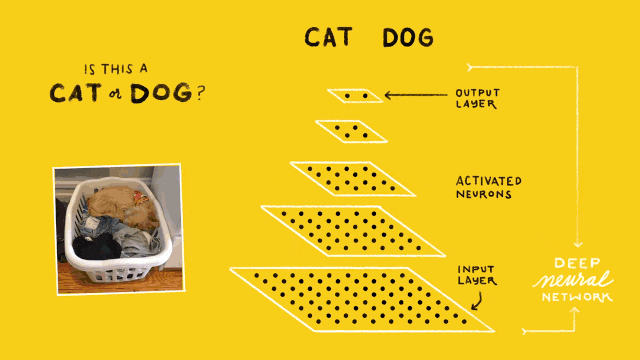
图2. 卷积神经网络架构
图2给出了一个简单的猫狗识别的卷积神经网络结构,在最底下(同时也是最大的)的点块表示的是网络的输入层(Input Layer),通常这一层作用是读入图像作为网络的数据输入。在最上面的点块是网络的输出层(Output Layer),其作用是预测并输出读入图像的类别,在这里由于只需要区分猫和狗,因此输出层只有2个神经计算单元。而位于输入和输出层的,都称之为隐含层(Hidden Layer),图中有3个隐含层,正如前文提到的,图像分类的隐含层都是由卷积操作完成的,因此这样的隐含层也成为卷积层(Convolutional Layer)。
因此,输入层、卷积层、输出层的结构及其对应的参数就构成了一个典型的卷积神经网络。当然,我们在实际中使用的卷积神经网络要比这个示例的结构更加复杂,自2012年的ImageNet比赛起,几乎每一年都会有新的网络结构诞生,已经被大家认可的常见网络有AlexNet[5], VGG-Net[6], GoogLeNet[7], Inception V2-V4[8, 9], ResNet[10]等等。
2.2 一种有效的网络训练技巧—微调(Fine-tune)
我们没有必要从头开始一个一个的参数去试验来构造一个深度网络,因为已经有很多公开发表的论文已经帮我们做了这些验证,我们只需要站在前人的肩膀上,去选择一个合适的网络结构就好了。且选择已经公认的网络结构另一个重要的原因是,这些网络几乎都提供了在大规模数据集ImageNet[11]上预先训练好的参数权重(Pre-trained Weights)。这一点非常重要!因为我们只有数千张训练样本,而深度网络的参数非常多,这就意味着训练图片的数量要远远小于参数搜索的空间,因此,如果只是随机初始化深度网络然后用这数千张图片进行训练,非常容易产生“过拟合”(Overfitting)的现象。
所谓过拟合,就是深度网络只看过了少量的样本,因而“坐井观天”,导致只能识别这小部分的图片,丧失了“泛化”(Generalization)能力,不能够识别其它没见过、但是也是相似的图片。为了解决这样的问题,我们一般都会使用那些已经在数百万甚至上千万上训练好的网络参数作为初始化参数,可以想象这样一组参数的网络已经“看过”了大量的图片,因此泛化能力大大提高了,提取出来的视觉特征也更加的鲁棒和有效。
接下来我们就可以使用已经标注的三千多张海鱼图片接着进行训练,注意为了防止错过了最优解,此时的训练节奏(其实应该称为“学习速率”)应该比较缓慢,因此这样的训练策略我们称为“微调技术”(Fine-tune)。
当我们使用自己的标注数据微调某个预先训练的网络时候,有一些经验值得借鉴。以总图3为例,假设我们的网络结构是类似AlexNet这样的7层结构,其中前5层是卷积层,后2层是全连接层。
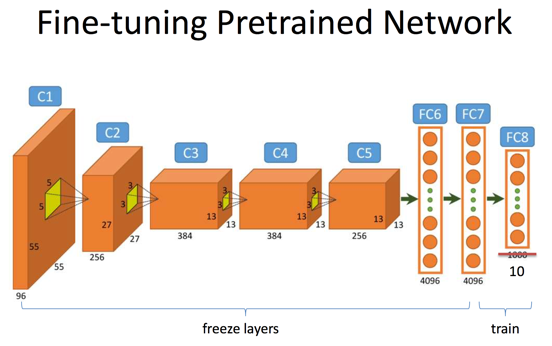
(1)
- (1)我们首先微调最后一层Softmax分类器,假设原来的网络是用来分类1000类物体的(例如ImageNet的目标),而现在我们的数据只有10个类别标签,因此我们最后一层输出层(FC8)的神经元个数变为10。我们使用很小的学习率来学习层FC7与FC8之间的权重矩阵而固定这之前所有层的权重;
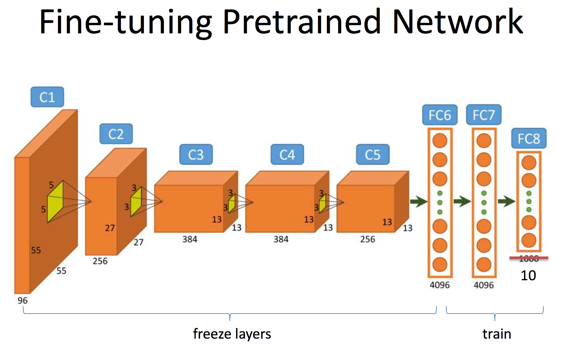
(2)
- (2)一旦网络趋于收敛,我们进一步扩大微调的范围,这时微调两个全连接层,即FC6与FC7,以及FC7与FC8之间的权重,与此同时固定FC6之前的所有卷积层权重不变;
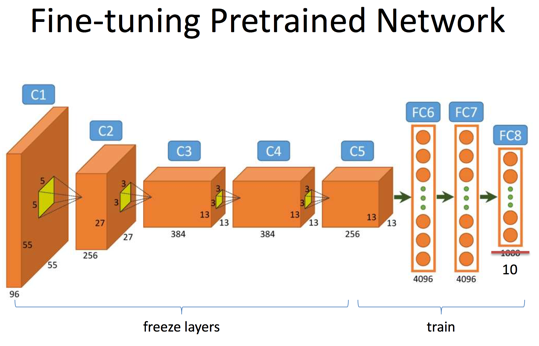
(3)
- (3)我们将微调的范围扩大至倒数第一个卷积层C5;
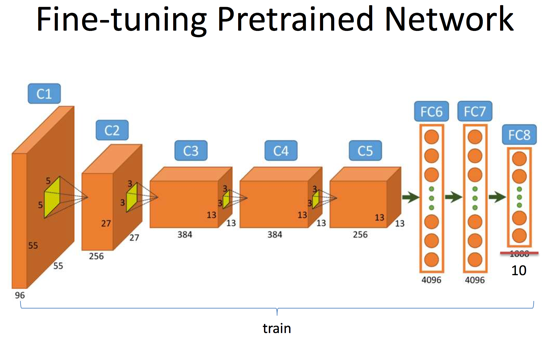
- (4)我们将微调的范围扩大至更多的卷积层。不过事实上,我们会认为位置相对靠前的卷积层提取出来的特征更加的底层和具有通用性,而位置相对靠后的卷积层以及全连接层更加与数据集的相关性大一些,因此有时候我们并不会微调前几个卷积层。
总图3. 网络Finetune的基本步骤
3. 算法实现和分析
在NCFM这个比赛的论坛里已经有开源的实现供大家参考(https://www.kaggle.com/c/the-nature-conservancy-fisheries-monitoring/discussion/26202),
在这里分析一下模型训练文件train.py的逻辑结构。
- Import相关的模块以及参数的设置——图4;
- 构建Inception_V3深度卷积网络,使用在ImageNet大规模图片数据集上已经训练好的参数作为初始化,定义回调函数保存训练中在验证集合上最好的模型——图5;
- 使用数据扩增(Data Augmentation)技术加载训练图片,数据扩增技术是控制过拟合现象的一种常见的技巧,其思想很简单,同样是一张图片,如果把它水平翻转一下,或者边角裁剪一下,或者色调再调暗淡或者明亮一些,都不会改变这张图片的类别——图6;
- Inception_V3网络模型训练;
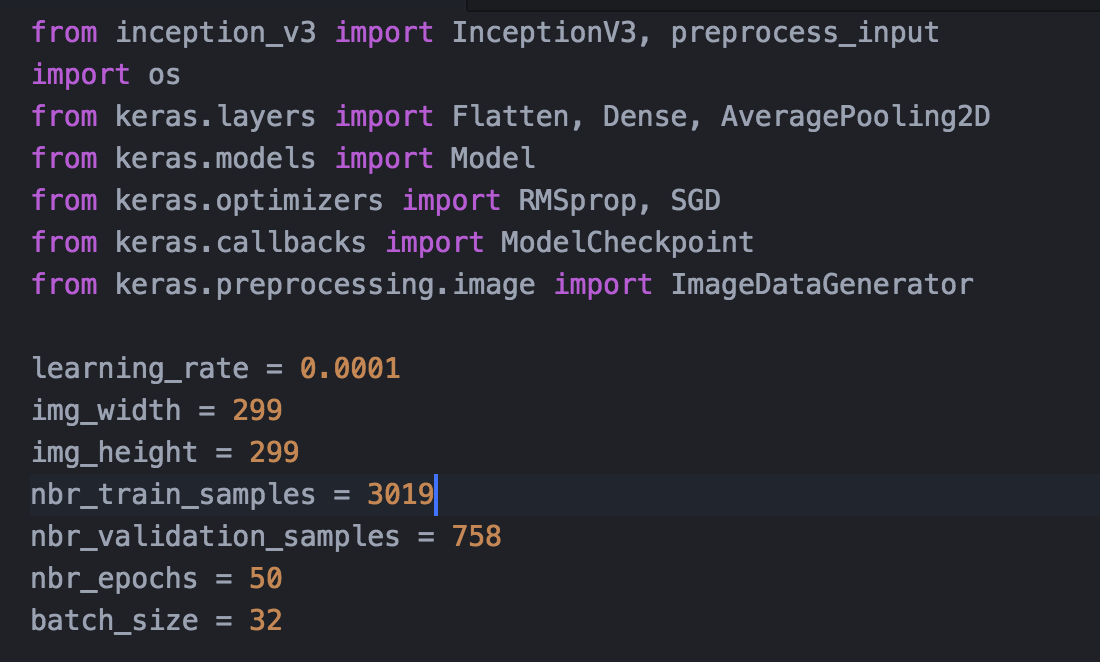
图4. Import和参数设置
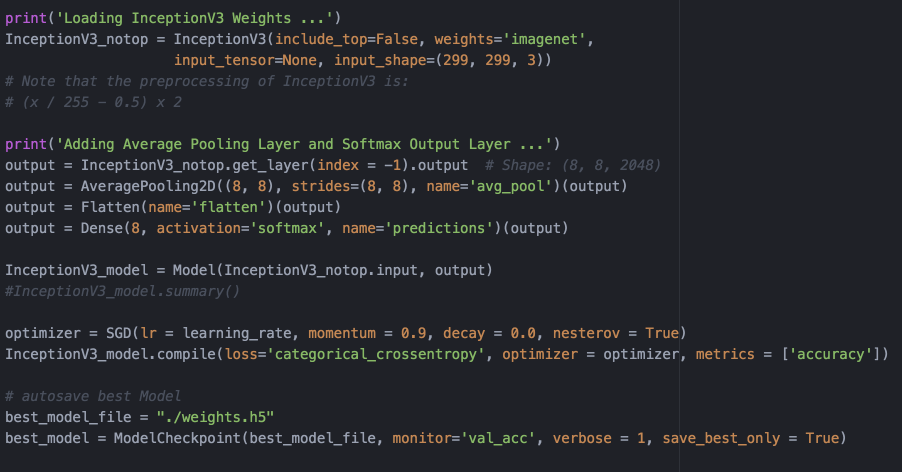
图5. 构建Inception_V3网络并加载预训练参数
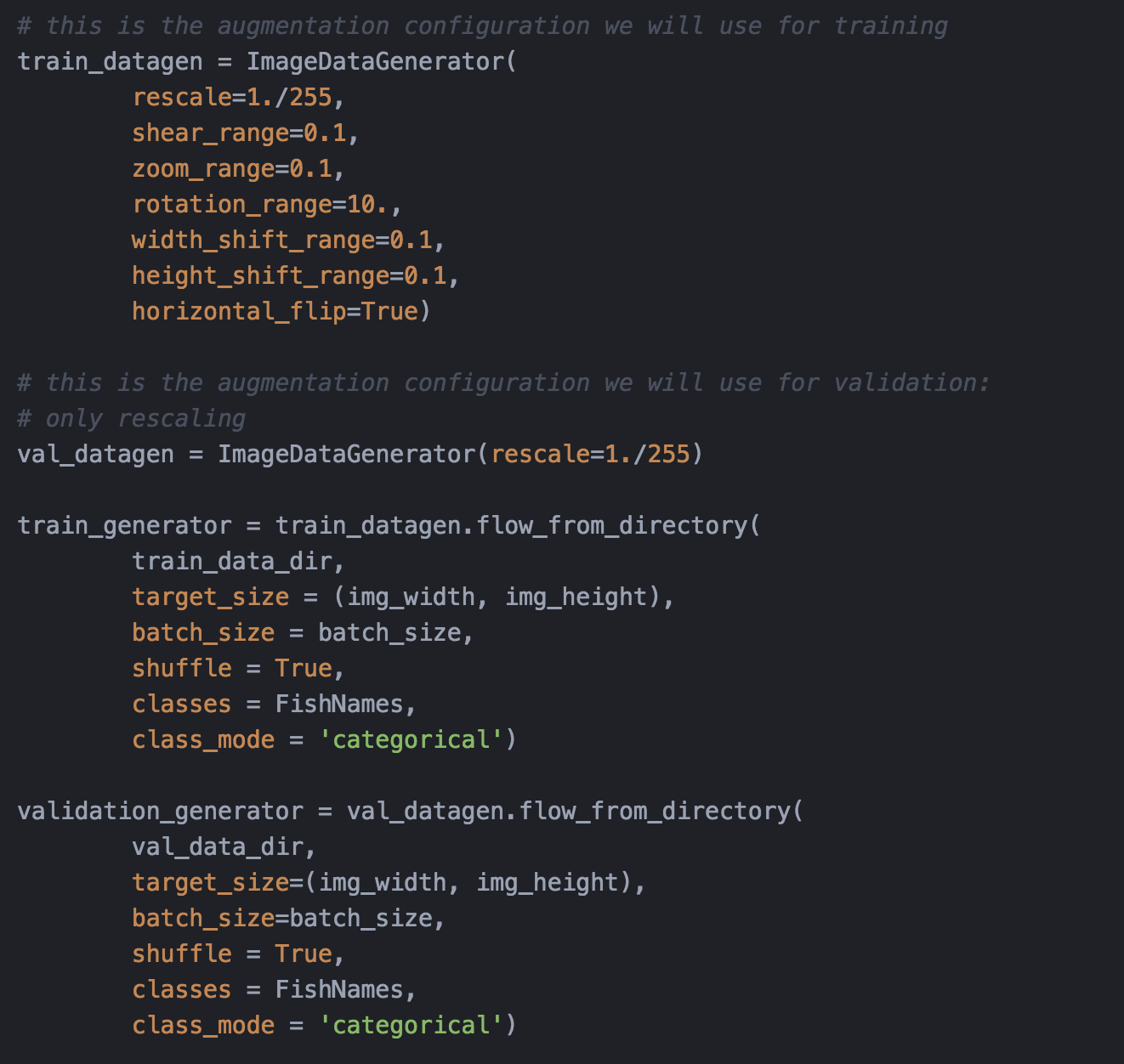
图6. 使用数据扩增技术加载训练和验证图片集

图7. 模型训练
4. 提升排名的若干技巧
一旦我们训练好了模型,我们就用这个模型预测那些测试图片的类别了,论坛中predict.py中的代码就是预测鱼类的并且生成提交文件。这里我们给大家分享一下在机器学习和图像识别类竞赛中常见的两个技巧,简单而有效。它们的思想都是基于平均和投票思想。其背后的原理用一句话总结就是:群众的眼睛是雪亮的!
技巧1:同一个模型,平均多个测试样例
这个技巧指的是,当我们训练好某个模型后,对于某张测试图片,我们可以使用类似数据扩增的技巧生成若干张图片相类似的多张图片,并把这些图片送进我们训练好的网络中去预测,我们取那些投票数最高的类别为最终的结果。Github仓库中的predict_average_augmentation.py实现的就是这个想法,其效果也非常明显。
技巧2:交叉验证训练多个模型
还记得我们之前说到要把三千多张图片分为训练集和验证集吗?这种划分其实有很多种。一种常见的划分是打乱图片的顺序,把所有的图片平均分为K份,那么我们就可以有K种<训练集,验证集>的组合,即每次取1份作为验证集,剩余的K-1份作为训练集。因此,我们总共可以训练K个模型,那么对于每张测试图片,我们就可以把它送入K个模型中去预测,最后选投票数最高的类别作为预测的最终结果。我们把这种方式成为“K折交叉验证”(K-Fold Cross-Validation)。图9表示的就是一种5折交叉验证的数据划分方式。
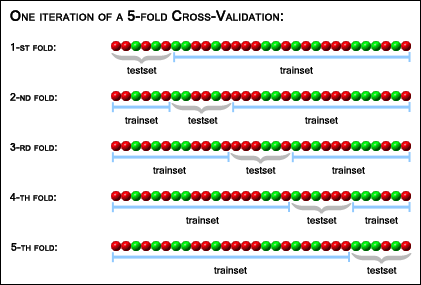
图9. 五折交叉验证
当然,技巧1和2也可以联合在一起使用。假设我们做了5折交叉验证,并且对于每一张测试图片都用5次数据扩增,那么不难计算,每一张测试图片的投票数目就是25个。采用这种方式,我们的排名可以更进一步。
5. 后记
我们回顾了深度学习中的深度卷积网络的典型结构和特点,并且知道了如何使用梯度下降算法来训练一个深度网络。我们展示了如何用微调技术,使用Inception_V3网络来解决Kaggle的NCFM海鱼分类比,并且通过两个简单而有效的小技巧,使得我们的排名能够进入Top 5%。
如果读者对该比赛有兴趣,想进一步提升名次,那么一种值得尝试的方法是:物体检测(Object Detection)技术。试想一下,其实我们只要区分海鱼的品种,由于摄像头远近等关系,图片中海鱼的区域其实只占据一小部分像素点,更多的区域都是船体、桅杆或是海洋等噪音。如果有一种算法能够帮我们把海鱼从照片中“扣”(检测)出来,那么可以想象,深度网络的准确率就能够进一步提升了。
6、补充:Kaggle冠军分享
从以前的研究或比赛中借鉴了什么方法?
借鉴了 Faster R-CNN。
使用了什么监督学习方法?
主要使用带 VGG-16 的 Faster R-CNN作为特征提取器,其中一个模型是用的带 ResNet-101 的 R-FCN。

数据预处理和数据增强是怎么做的?
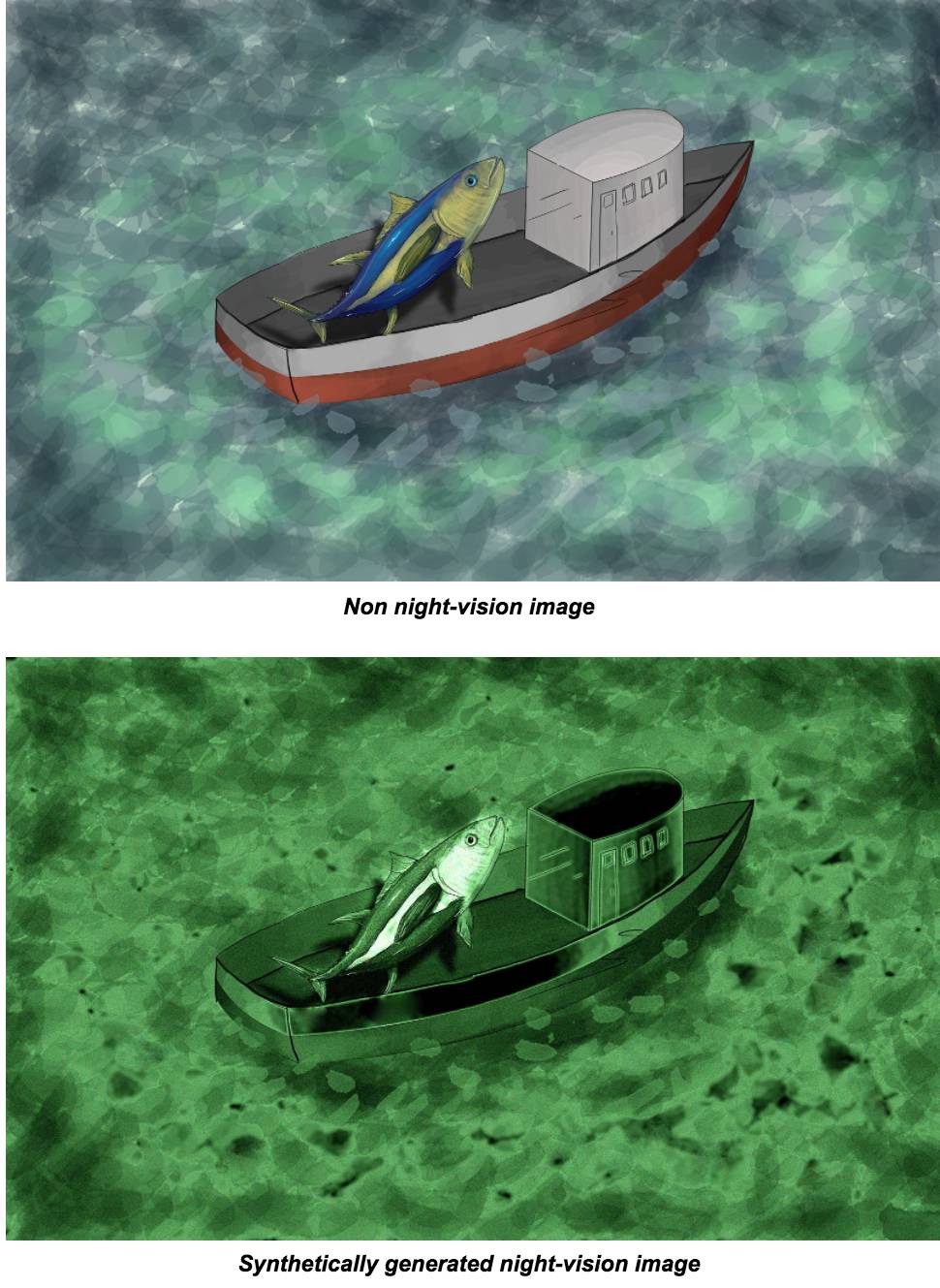
大多数用于训练模型的增强管道都是相当标准的。随机旋转,水平翻转,模糊和尺度变化等方法都可以提高了验证分数。然而,最重要的两件事情是使用夜视图像和图像颜色。
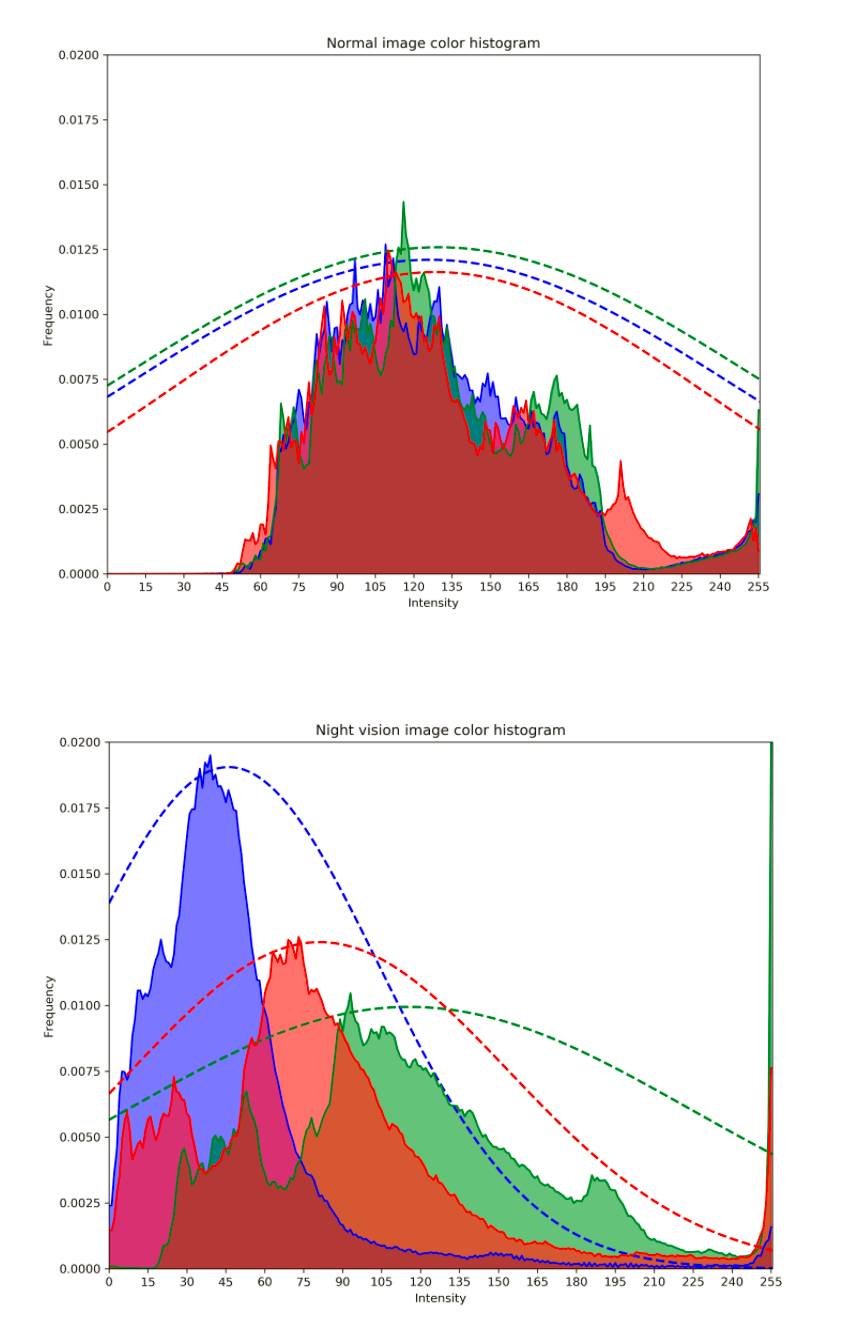
夜视图像真的很容易识别——只需检查绿色通道的平均值是否比红色和蓝色通道两者相加的均值更亮就行了,加权系数为 0.75,在所有情况下都适用。观察典型正常图像和夜视图像的颜色强度直方图,可以清楚地发现差异,因为常规图像的颜色分布通常彼此相近,这可以从下图中看出。虚线表示近似这些分布的最佳拟合高斯。
想要增加更多的夜视图像,就随机分配了一些训练图像,并且扩展直方图,使其更接近于夜视图像。这是针对每个颜色通道分别完成的,并假设是高斯的(实际情况并不是高斯的),并且相应地修改了平均值和标准偏差——基本上就是缩小红色和蓝色通道,从图中可以看出。之后也分别对每个颜色通道进行了随机的对比度拉伸。因为夜视图像本身可能是非常多样的,而固定变换无法体现这种变化。
因为这个模型性能非常好,如果添加一个不单独使用夜视图像的模型,但却会加长所有图像的对比度。因为这是分别在每个通道上完成的,可能会改变鱼类或周围环境的颜色。由于数据中海洋里光照条件变化多端,真实图像中的颜色不太稳定,所以这种方法结果看上去还是很好的。
关于数据方面,最重要的看法是什么?
首先,必须具有包含来自不同船舶的图像的验证集,而不是训练集中的图像,否则模型可以根据船舶特征学习分类鱼类,这虽然不会在验证分数上有所体现,但可能会导致 stage2 测试集的精确度下降。
其次,整个数据集中鱼的大小都非常不同,因此对这一点进行处理显然是有用的。
第三,有大量的夜视图像具有不同的颜色分布,因此用不同的方式处理夜视图像也可以提高分数。
更重要的是,其他团队在论坛上发布的附加数据似乎包含了很多这样的图像,其中的鱼看起来与放在船上的鱼看起来不一样,因此过滤掉这部分数据很重要。
最后,对原始训练图像进行了多边形注释,这有助于在旋转图像上实现更准确的边界框,否则图像将包含很多背景(如果旋转框的边框被视为基本真实的)。
使用的工具?
使用从定制的存储库 py-R-FCN(包括 Faster R-CNN)代码:https://github.com/Orpine/py-R-FCN 。
在这次比赛中都做了哪些事情?
注释数据,从论坛上发布的图像中找到有用的附加数据,找到正确的扩充来训练模型,查看生成的验证图像预测,然后查看模型可能学到的任何虚假模式。
硬件设置是什么样的?
两台 NVIDIA GTX 1080,一台 NVIDIA TITAN X
获胜解决方案的训练和预测运行时间分别是多少?
非常粗略的估计,GTX 1080 训练大约 50 小时,预测每个图像 7-10 秒。最好的单一模型其实比整个系统更加精确,可以在 4 小时内训练,需要 0.5 秒进行预测。
对刚入门数据科学的人的建议吗?
先阅读介绍类的材料,然后逐渐开始阅读论文,尝试自动动手解决机器学习问题,培养直觉,检查训练好的模型,努力去了解出了什么问题。计算机视觉问题对于练手来说相当不错。学习享受机器学习过程要付出长期的努力,保持兴趣才能保持动力。Kaggle 是学习机器学习的完美平台。
参考文献
- [1] https://www.kaggle.com/
- [2] http://cs231n.github.io/neural-networks-3/
- [3] https://github.com/tensorflow/tensorflow
- [4] https://github.com/fchollet/keras
- [5] Image Classification with Deep Convolutional Neural Networks. NIPS 2012.
- [6] Very Deep Convolutional Networks for Large-Scale Image Recognition. ICLR 2015.
- [7] Going Deep with Convolutions. CVPR 2015.
- [8] Rethinking the Inception Architecture for Computer Vision. CVPR 2016.
- [9] Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. ICLR 2016.
- [10] Deep Residual Learning for Image Recognition. CVPR 2016.
- [11] http://www.image-net.org/
- 七月在线《kaggle案例实战班》
- kaggle实战公开课《模型分析与模型融合》
各种动物识别:
猫狗:
http://blog.csdn.net/shizhengxin123/article/details/72473245
http://blog.csdn.net/qq_25964837/article/details/79038613