花在注释上的时间可能很快就会成为过去。
Meta 的 FAIR 实验室最近推出了 Segment Anything Model,这是一种先进的图像分割模型,旨在彻底改变计算机视觉。它可以根据输入提示(例如点或框)生成高质量的对象蒙版。该模型还可以为图像中的所有对象生成蒙版。
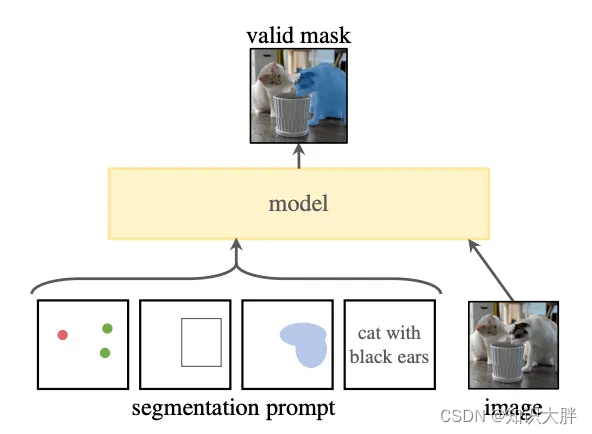
有什么大不了的?
如果您花了数小时在 LabelImg、LabelMe 或像我一样的任何其他注释工具上注释图像,您也会明白为什么 SAM 是我们的新朋友。分割注释是一项非常耗时且乏味的任务。例如,要注释图像中的人物,您必须在其身体周围放置多个点以捕获不同的边缘和曲线并为人物创建蒙版。而使用 SAM 时,模型会分割图像,您只需确认掩模并添加标签“Person”即可。
一个有趣的特性: SAM 拥有零样本泛化能力。这是指模型在未经过明确训练的图像分割任务上表现良好的能力,而不需要额外的训练或微调。
自己尝试一下
演示页面可让您感受模型的功能。在这里查看:
https: //segment-anything.com/demo
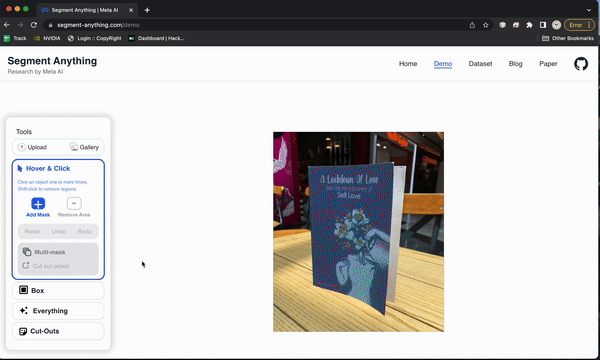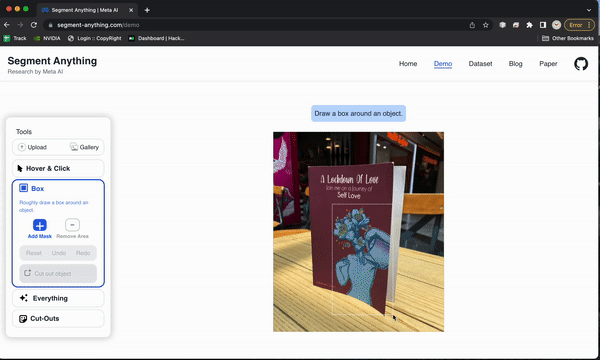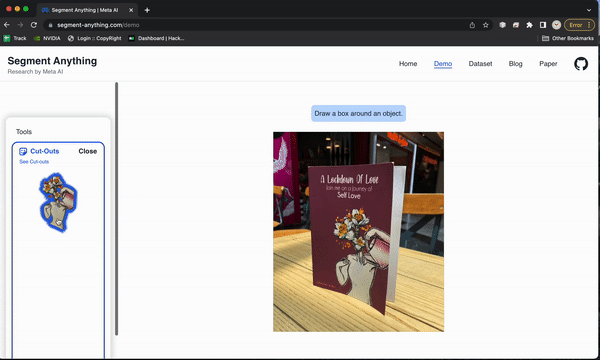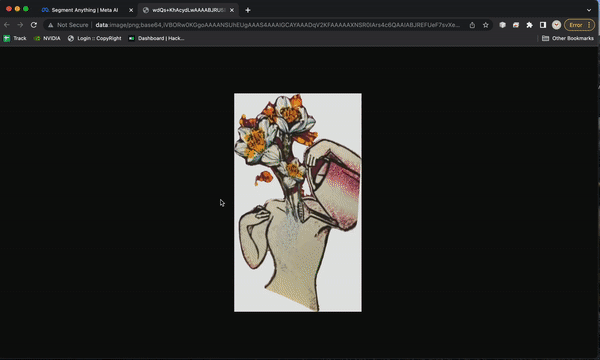
设置代码库并尝试模型也非常简单。我花了大约20分钟。以下是我所遵循的步骤的概述
- 安装 PyTorch 和 TorchVision
- 安装的段任何东西
- 我安装了一些提到的用于掩模后处理的其他库。