深度学习论文分享(四)Retentive Network: A Successor to Transformer for Large Language Models
前言
论文原文:https://arxiv.org/abs/2307.08621
论文代码:https://aka.ms/retnet
Title:Retentive Network: A Successor to Transformer for Large Language Models
Authors:Yutao Sun∗ †‡ Li Dong∗ † Shaohan Huang† Shuming Ma† Yuqing Xia† Jilong Xue† Jianyong Wang‡ Furu Wei†⋄
g Xia† Jilong Xue† Jianyong Wang‡ Furu Wei†⋄
† Microsoft Research ‡ Tsinghua University
在此仅做翻译
Abstract
在这项工作中,我们提出保留网络(RETNET)作为大型语言模型的基础架构,同时实现训练并行性,低成本推理和良好的性能。我们从理论上推导了递归和注意力之间的联系。然后提出了序列建模的保留机制,该机制支持并行、递归和块递归三种计算范式。具体来说,并行表示允许训练并行性。循环表示支持低成本的O(1)推理,从而在不牺牲性能的情况下提高解码吞吐量、延迟和GPU内存。块递归表示促进了具有线性复杂性的高效长序列建模,其中每个块在循环汇总块的同时并行编码。语言建模实验结果表明,RETNET实现了良好的扩展效果、并行训练、低成本部署和高效推理。这些有趣的特性使RETNET成为大型语言模型中Transformer的强大继承者。代码将在https://aka.ms/retnet上提供。

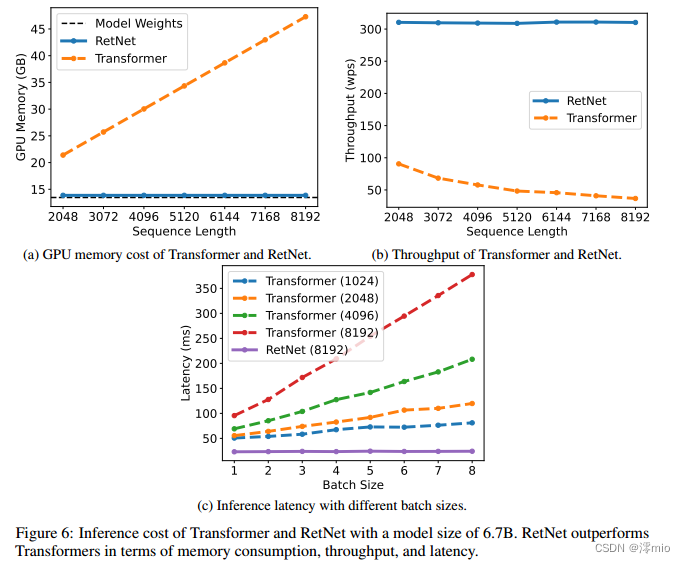
图1:与Transformer相比,RetNet实现了低成本推理(即GPU内存、吞吐量和延迟)、训练并行性和有利的缩放曲线。以8k作为输入长度报告推理成本的结果。图6显示了不同序列长度的更多结果。
1 Introduction
Transformer [VSP+17]已经成为大型语言模型的事实上的架构[BMR+20],它最初被提出是为了克服循环模型的顺序训练问题[HS97]。然而,transformer的训练并行性是以低效的推理为代价的,因为每一步的复杂度为O(N),并且内存绑定键值缓存[Sha19],这使得transformer对部署不友好。不断增长的序列长度增加了GPU内存消耗以及延迟,降低了推理速度。
开发下一代架构的许多努力仍在继续,旨在保持训练并行性和具有竞争力的性能,同时具有高效的O(1)推理。同时实现上述目标是具有挑战性的,即所谓的“不可能三角”,如图2所示

图2:RetNet使“不可能三角”成为可能,同时实现训练并行性、良好的性能和较低的推理成本。
有三个主要的研究方向。首先,线性化注意力[KVPF20]用核φ (q)·φ (k)近似标准注意力分数exp(q·k),因此自回归推理可以用循环形式重写。但是,该方法的建模能力和性能都不如transformer,阻碍了该方法的推广。第二条链返回到循环模型,在牺牲训练并行性的同时进行有效的推理。作为补救措施,元素智能运算符[PAA+23]用于加速,然而,表示能力和性能受到损害。第三条研究探索用其他机制替代注意力,如S4 [GGR21]及其变体[DFS+22, PMN+23]。之前的作品都没有突破不可能三角,导致与《transformer》相比没有明显的赢家。
在这项工作中,我们提出保留网络(RetNet),同时实现低成本推理,高效的长序列建模,可媲美transformer的性能和并行模型训练。具体来说,我们引入了一种多尺度保留机制来替代多头注意,该机制有三种计算范式,即并行、循环和块循环表征。首先,并行表示使训练并行性能够充分利用GPU设备。其次,循环表示在内存和计算方面实现了高效的O(1)推理。可以显著降低部署成本和延迟。此外,没有键值缓存技巧,实现也大大简化了。第三,分块递归表示可以实现高效的长序列建模。我们并行编码每个局部块以提高计算速度,同时循环编码全局块以节省GPU内存。
我们进行了大量的实验来比较RetNet与Transformer及其变体。语言建模的实验结果表明,RetNet在缩放曲线和上下文学习方面都具有持续的竞争力。此外,RetNet的推理代价是长度不变的。对于7B型号和8k序列长度,RetNet解码速度比具有键值缓存的transformer快8.4倍,节省70%的内存。在训练期间,RetNet还实现了25-50%的内存节省和7倍的加速,比标准Transformer和高度优化的FlashAttention的优势[DFE+22]。此外,RetNet的推理延迟对批处理大小不敏感,允许巨大的吞吐量。这些有趣的特性使RetNet成为大型语言模型中Transformer的强大继承者。
2 Retentive Networks
保留网络(RetNet)由L个相同的块堆叠,遵循与Transformer [VSP+17]相似的布局(即残余连接和预层规范 pre-LayerNorm)。每个RetNet块包含两个模块:一个多尺度保持(MSR)模块和一个前馈网络(FFN)模块。我们将在以下部分中介绍MSR模块。给定输入序列 x = x 1 ⋅ ⋅ ⋅ x ∣ x ∣ x = x_1···x_{|x|} x=x1⋅⋅⋅x∣x∣, RetNet以自回归的方式对序列进行编码。首先将输入向量{ x i {x_i} xi} i = 1 ∣ x ∣ ^{|x|}_{i=1} i=1∣x∣打包成 X 0 = [ x 1 , ⋅ ⋅ ⋅ , x ∣ x ∣ ] ∈ R ∣ x ∣ × d m o d e l X_0 = [x_1,···,x_{|x|}]∈\mathbb{R}^{|x|×d_{model}} X0=[x1,⋅⋅⋅,x∣x∣]∈R∣x∣×dmodel,其中 d m o d e l d_{model} dmodel为隐维。然后我们计算上下文化向量表示 X l = R e t N e t l ( X l − 1 ) , l ∈ [ 1 , L ] X^l = RetNet_l(X^{l−1}),l∈[1,L] Xl=RetNetl(Xl−1),l∈[1,L]。
2.1 Retention
在本节中,我们将介绍具有递归性和并行性双重形式的保留机制。因此,我们可以在循环进行推理的同时以并行的方式训练模型。
给定输入 X ∈ R ∣ x ∣ × d m o d e l X∈\mathbb{R}^{|x|×d_{model}} X∈R∣x∣×dmodel,我们将其投影为一维函数 v ( n ) = X n ⋅ w V v(n) = X_n·w_V v(n)=Xn⋅wV。考虑一个序列建模问题,它通过状态 s n s_n sn映射 v ( n ) → o ( n ) v(n)→o(n) v(n)→o(n)。简而言之,让 v n v_n vn表示 v ( n ) v(n) v(n) o n o_n on表示 o ( n ) o(n) o(n).我们以一种循环的方式来表述这种映射:
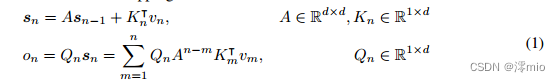
其中我们将 v n v_n vn映射到状态向量 s n s_n sn,然后实现线性变换来循环编码序列信息。
接下来,我们使投影 Q n , K n Q_n, K_n Qn,Kn是内容感知的:

其中, W Q , W K ∈ R d × d W_Q, W_K∈\mathbb{R}^{d×d} WQ,WK∈Rd×d为可学习矩阵。
我们对角化矩阵 A = Λ ( γ e i θ ) Λ − 1 A = Λ(γe^{iθ})Λ^{−1} A=Λ(γeiθ)Λ−1,其中 γ , θ ∈ R d γ,θ∈\mathbb{R}^d γ,θ∈Rd。得到 A n − m = Λ ( γ e i θ ) n − m Λ − 1 A^{n−m} = Λ(γe^{iθ}) ^{n−m}Λ^{−1} An−m=Λ(γeiθ)n−mΛ−1。将 Λ Λ Λ代入 W Q W_Q WQ和 W K W_K WK,可以将式(1)改写为:
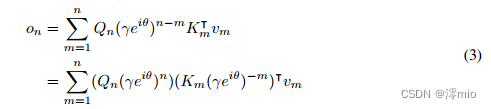
其中 Q n ( γ e i θ ) n , K m ( γ e i θ ) − m Q_n(γe^{iθ})^n, K_m(γe^{iθ})^{−m} Qn(γeiθ)n,Km(γeiθ)−m称为xPos [SDP+22],即为Transformer提出的相对位置嵌入。我们进一步将 γ γ γ简化为标量,式(3)变成:
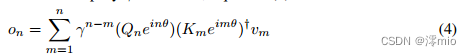
其中†是共轭转置。该公式很容易在训练实例中并行化。
综上所述,我们从式(1)所示的循环建模开始,然后推导出式(4)所示的并行表达式。我们将原始映射v(n)→o(n)作为向量,得到保留机制如下。
保留的并行表示:如图3a所示,保留层定义为:
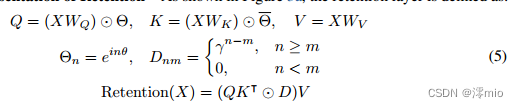
其中 Θ ‾ \overline{Θ} Θ是 Θ Θ Θ的复共轭, D ∈ R ∣ x ∣ × ∣ x ∣ D∈\mathbb{R}^{|x|×| x|} D∈R∣x∣×∣x∣将因果掩蔽和指数衰减沿相对距离组合为一个矩阵。与自关注类似,并行表示使我们能够有效地利用gpu训练模型。
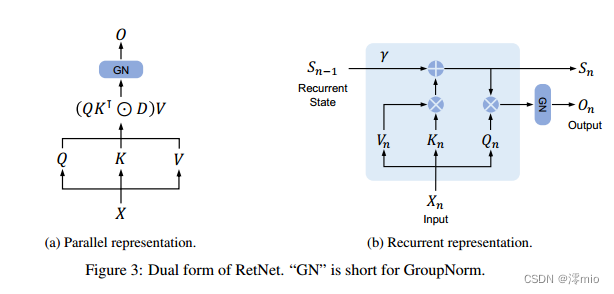
保留的循环表征:如图3b所示,所提出的机制也可以写成递归神经网络(rnn),这有利于推理。对于第n个时间步长,我们循环得到如下输出:
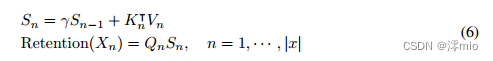
其中 Q , K , V , γ Q, K, V,γ Q,K,V,γ与式(5)相同。
保留的块递归表示:并行表示和循环表示的混合形式可用于加速训练,特别是对于长序列。我们将输入序列分成块。在每个块内,我们按照并行表示(式(5))进行计算。相反,跨块信息是按照循环表示(式(6))传递的。具体来说,设B表示块长度。我们通过以下方式计算第i块的保留输出:
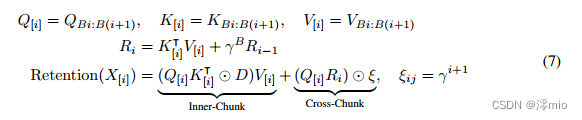
式中 [ i ] [i] [i]表示第 i i i块,即 x [ i ] = [ x ( i − 1 ) B + 1 , ⋅ ⋅ ⋅ , x i B ] x_{[i]} = [x_{(i−1)B+1},···,x_{iB}] x[i]=[x(i−1)B+1,⋅⋅⋅,xiB]。
2.2 Gated Multi-Scale Retention
我们在每个层中使用 h = d m o d e l / d h = d_{model}/d h=dmodel/d保留头,其中 d d d是头的维度。头部使用不同的参数矩阵 W Q , W K , W V ∈ R d × d W_Q, W_K, W_V∈\mathbb{R}^{d×d} WQ,WK,WV∈Rd×d。此外,多尺度保留(MSR)为每个头分配不同的 γ γ γ。为简单起见,我们将不同层之间的 γ γ γ设置为相同并保持固定。此外,我们增加了一个闪门[HG16, RZL17]来增加保持层的非线性。形式上,给定输入 X X X,我们将层定义为:
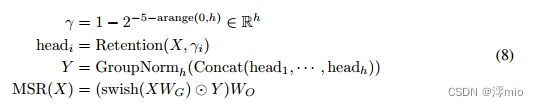
其中 W G , W O ∈ R d m o d e l × d m o d e l W_G, W_O∈\mathbb{R}^{d_{model}×d_{model}} WG,WO∈Rdmodel×dmodel为可学习参数,GroupNorm [WH18]对每个头部的输出进行归一化,遵循[SPP+19]中提出的subn。注意,正面使用多个 γ γ γ尺度,这导致不同的方差统计。所以我们分别对正面输出进行归一化。
保留的伪代码总结在图4中

保留分数归一化:我们利用GroupNorm的尺度不变性来提高保留层的数值精度。具体来说,在GroupNorm内乘以标量值不会影响输出和向后梯度,即 G r o u p N o r m ( α ∗ h e a d i ) = G r o u p N o r m ( h e a d i ) GroupNorm(α∗head_i) = GroupNorm(head_i) GroupNorm(α∗headi)=GroupNorm(headi)。我们在式(5)中实现了三个归一化因子。首先,我们将 Q K ⊺ QK^⊺ QK⊺归一化为 Q K ⊺ / √ d QK^⊺/√d QK⊺/√d。其次,我们将 D D D替换为 D ~ n m = D n m / Σ i = 1 n D n i \widetilde{D}_{nm} = D_{nm}/\sqrt{\Sigma_{i=1}^nD_{ni}} D
nm=Dnm/Σi=1nDni。第三,设 R R R表示保留分数 R = Q K ⊺ ⊙ D R = QK^⊺⊙D R=QK⊺⊙D,我们将其归一化为 R ~ n m = R n m / m a x ( ∣ Σ i = 1 n R n i ∣ , 1 ) \widetilde{R}_{nm} = R_{nm}/max(|\Sigma_{i=1}^nR_{ni}|,1) R
nm=Rnm/max(∣Σi=1nRni∣,1)。此时,保留率输出变为 R e t e n t i o n ( X ) = R ~ V Retention(X) = \widetilde{R}V Retention(X)=R
V。由于尺度不变的特性,上述技巧不会影响最终结果,同时稳定了向前和向后通过的数值流。
2.3 Overall Architecture of Retention Networks
对于 l l l层保留网络,我们将多尺度保留(MSR)和前馈网络(FFN)叠加在一起构建模型。形式上,输入序列 x i i = 1 ∣ x ∣ {x_i}^{|x|}_{i=1} xii=1∣x∣通过词嵌入层转换为向量。我们使用填充嵌入 X 0 = [ x 1 , ⋅ ⋅ ⋅ , x ∣ x ∣ ] ∈ R ∣ x ∣ × d m o d e l X^0 = [x_1,···,x_{|x|}]∈\mathbb{R}^{|x|×d_{model}} X0=[x1,⋅⋅⋅,x∣x∣]∈R∣x∣×dmodel作为输入,计算模型输出 X L X^L XL:

式中 L N ( ⋅ ) LN(·) LN(⋅)为 L a y e r N o r m LayerNorm LayerNorm [BKH16]。FFN部分计算为 F F N ( X ) = g e l u ( X W 1 ) W 2 FFN(X) = gelu(XW_1)W_2 FFN(X)=gelu(XW1)W2,其中 W 1 、 W 2 W_1、W_2 W1、W2为参数矩阵。
Training:我们在训练过程中使用并行(式(5))和块递归(式(7))表示。序列或块内的并行化有效地利用了gpu来加速计算。更有利的是,块递归对于长序列训练特别有用,这在FLOPs和内存消耗方面都是有效的。
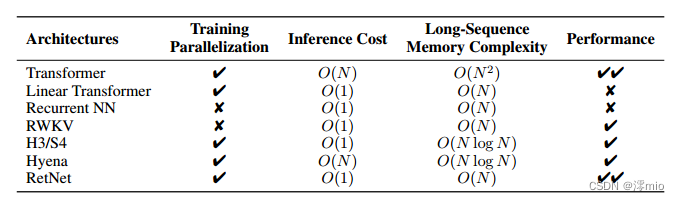
表1:不同角度的模型比较。RetNet实现了训练并行化、恒定的推理成本、线性长序列内存复杂度和良好的性能。
Inference:在推理过程中使用循环表示(式(6)),它很好地适应自回归解码。O(1)复杂度降低了内存和推理延迟,同时获得了相同的结果。
2.4 Relation to and Differences from Previous Methods
表1从不同角度对RetNet与以往的方法进行了比较。对比结果与图2所示的“不可能三角形”相呼应。此外,RetNet对于长序列具有线性记忆复杂性,因为它采用了分块递归表示。我们还将与具体方法的比较总结如下。
Transformer:保留的并行表现与《Transformer》(VSP+17)有着相似的精神。最相关的Transformer变体是Lex Transformer [SDP+22],它实现了xPos作为位置嵌入。如式(3)所示,留存率的推导与xPos一致。与注意力相比,保留消除了softmax并使循环公式成为可能,这大大有利于推理。
S4:与式(2)不同,如果Qn和Kn不含内容,则公式可简并为S4 [GGR21],其中O = (QK⊺,QAK⊺,…, QA|x|−1K⊺)* V。
Linear Attention:变体通常使用各种内核ϕ(qi)ϕ(kj)/ |x| n=1 ϕ(qi)ϕ(kn)来取代softmax函数。然而,线性注意力难以有效地编码位置信息,导致模型性能下降。此外,我们从头开始重新检查序列建模,而不是以近似softmax为目标。
AFT/RWKV:注意力自由Transformer(AFT)简化了点积对元素操作的关注,并将softmax移动到关键向量。RWKV用指数衰减取代AFT的位置嵌入,并循环运行模型进行训练和推理。相比之下,保留算法保留了高维状态来编码序列信息,有助于提高表达能力和性能
xPos/RoPE:与提出的变压器相对位置嵌入方法相比,式(3)与xPos [SDP+22]和RoPE [SLP+21]的表达式相似。
Sub-LayerNorm:如式(8)所示,保留层使用sublayernorm [WMH+22]对输出进行归一化。由于多尺度建模导致头部的方差不同,我们用GroupNorm代替原来的LayerNorm。
3 Experiments
我们进行了语言建模实验来评估RetNet。我们用各种基准来评估提议的体系结构,例如,语言建模性能,以及下游任务的零/少次学习。此外,对于训练和推理,我们比较了速度、内存消耗和延迟。

表2:语言建模实验中模型的大小和学习超参数。
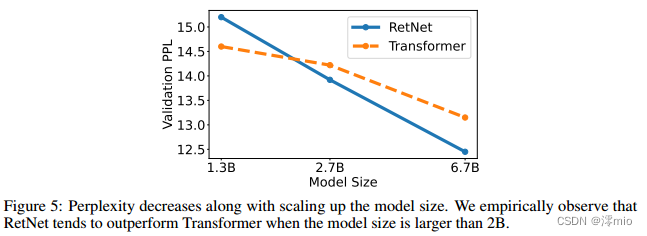
图5:复杂度随着模型尺寸的增大而降低。我们根据经验观察到,当模型大小大于2B时,RetNet倾向于优于Transformer。
3.1 Setup
参数配置:为了公平比较,我们重新分配了MSR和FFN中的参数。为简单起见,这里用d表示dmodel。在《变形金刚》中,自关注中约有4d个参数,其中WQ, WK, WV, WO∈R d×d; FFN中约有82d个参数,其中中间维数为4d。相比之下,RetNet的保留参数为8d 2,其中WQ, WK∈R d×d, WG, WV∈R d×2d, WO∈R 2d×d。注意V的头部维数是Q, k的两倍,扩大后的维数被WO投影回d。为了保持参数数与Transformer相同,RetNet中FFN的中间维数为2d。同时,我们在实验中将头部维度设置为256,即查询和键为256,值为512。为了公平比较,我们在不同的模型尺寸中保持γ相同,其中γ = 1−e linspace(log 1/32,log 1/512,h)∈R h,而不是式(8)中的默认值
语言模型训练:如表2所示,我们从零开始训练不同大小的语言模型(1.3B、2.7B、6.7B)。训练语料库是The Pile [GBB+20]、C4 [DMI+21]和The Stack [KLBA+22]的精选汇编。我们附加令牌以指示序列的开始2。训练批大小为4M令牌,最大长度为2048。我们用100B个标记训练模型,即25k步。我们使用AdamW [LH19]优化器,β1 = 0.9, β2 = 0.98,权重衰减设置为0.05。热身步骤的数量为375,学习率呈线性衰减。参数按照DeepNet [WMD+22]初始化,保证训练的稳定性。实现是基于TorchScale [MWH+22]。我们用512 AMD MI200 gpu训练模型。
3.2 Comparisons with Transformer
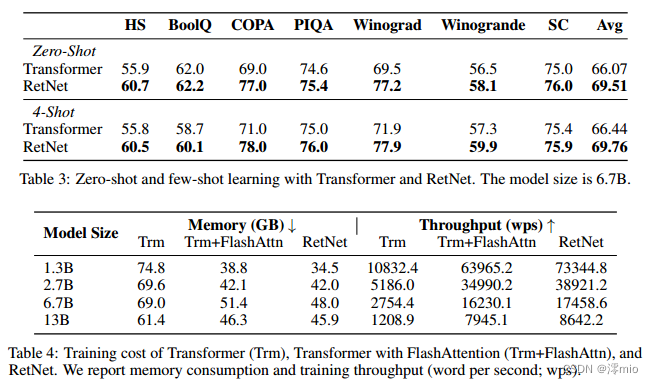
3.3 Training Cost
3.4 Inference Cost
3.5 Comparison with Transformer Variants
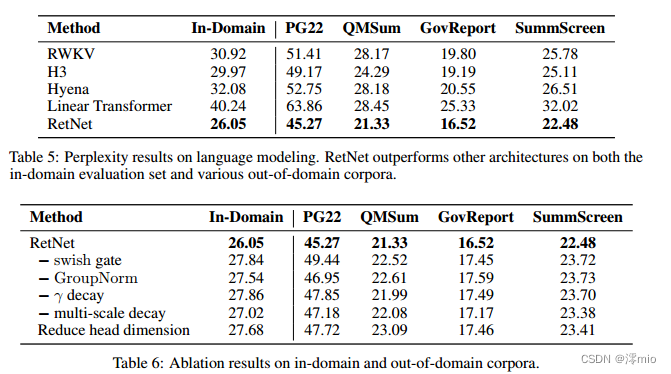
3.6 Ablation Studies
4 Conclusion
在这项工作中,我们提出了用于序列建模的保留网络(RetNet),它支持各种表示,即并行,循环和块循环。与transformer相比,RetNet实现了明显更好的推理效率(在内存、速度和延迟方面)、有利的训练并行化和具有竞争力的性能。以上优点使RetNet成为大型语言模型transformer的理想继承者,特别是考虑到O(1)推理复杂性带来的部署优势。在未来,我们希望在模型大小[CDH+22]和训练步骤方面扩大RetNet。此外,通过压缩长期记忆,保留可以有效地处理结构化提示[HSD+22b]。我们还将使用RetNet作为主干架构来训练多模态大型语言模型[HSD+22a, HDW+23, PWD+23]。
此外,我们有兴趣在各种边缘设备(如手机)上部署RetNet模型
致谢
我们要感谢来自MSRA系统组的丁嘉宇、杨松林和同事们的有益讨论。
References
[BKH16] Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization. arXiv preprint arXiv:1607.06450, 2016.
[BMR+20] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners. In Advances in Neural Information Processing Systems, volume 33, pages 1877–1901. Curran Associates, Inc., 2020.
[BZB+20] Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. Piqa: Reasoning about physical commonsense in natural language. In Thirty-Fourth AAAI Conference on Artificial Intelligence, 2020.
[CCWG21] Mingda Chen, Zewei Chu, Sam Wiseman, and Kevin Gimpel. Summscreen: A dataset for abstractive screenplay summarization. arXiv preprint arXiv:2104.07091, 2021.
[CDH+22] Zewen Chi, Li Dong, Shaohan Huang, Damai Dai, Shuming Ma, Barun Patra, Saksham Singhal, Payal Bajaj, Xia Song, Xian-Ling Mao, Heyan Huang, and Furu Wei. On the representation collapse of sparse mixture of experts. In Advances in Neural Information Processing Systems, 2022.
[CLC+19] Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. BoolQ: Exploring the surprising difficulty of natural yes/no questions. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics, pages 2924–2936, 2019.
[DFE+22] Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness. Advances in Neural Information Processing Systems, 35:16344–16359, 2022.
[DFS+22] Tri Dao, Daniel Y Fu, Khaled K Saab, Armin W Thomas, Atri Rudra, and Christopher Ré. Hungry hungry hippos: Towards language modeling with state space models. arXiv preprint arXiv:2212.14052, 2022.
[DMI+21] Jesse Dodge, Ana Marasovic, Gabriel Ilharco, Dirk Groeneveld, Margaret Mitchell, and ´ Matt Gardner. Documenting large webtext corpora: A case study on the colossal clean crawled corpus. In Conference on Empirical Methods in Natural Language Processing, 2021.
[GBB+20] Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, et al The Pile: An 800GB dataset of diverse text for language modeling. arXiv preprint arXiv:2101.00027, 2020.
[GGR21] Albert Gu, Karan Goel, and Christopher Ré. Efficiently modeling long sequences with structured state spaces. arXiv preprint arXiv:2111.00396, 2021.
[HCP+21] Luyang Huang, Shuyang Cao, Nikolaus Parulian, Heng Ji, and Lu Wang. Efficient attentions for long document summarization. arXiv preprint arXiv:2104.02112, 2021.
[HDW+23] Shaohan Huang, Li Dong, Wenhui Wang, Yaru Hao, Saksham Singhal, Shuming Ma, Tengchao Lv, Lei Cui, Owais Khan Mohammed, Qiang Liu, Kriti Aggarwal, Zewen Chi, Johan Bjorck, Vishrav Chaudhary, Subhojit Som, Xia Song, and Furu Wei. Language is not all you need: Aligning perception with language models. ArXiv, abs/2302.14045, 2023.
[HG16] Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (GELUs). arXiv: Learning, 2016.
[HS97] Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural Computation, 9:1735–1780, November 1997.
[HSD+22a] Yaru Hao, Haoyu Song, Li Dong, Shaohan Huang, Zewen Chi, Wenhui Wang, Shuming Ma, and Furu Wei. Language models are general-purpose interfaces. ArXiv, abs/2206.06336, 2022.
[HSD+22b] Yaru Hao, Yutao Sun, Li Dong, Zhixiong Han, Yuxian Gu, and Furu Wei. Structured prompting: Scaling in-context learning to 1,000 examples. ArXiv, abs/2212.06713, 2022.
[KLBA+22] Denis Kocetkov, Raymond Li, Loubna Ben Allal, Jia Li, Chenghao Mou, Carlos Muñoz Ferrandis, Yacine Jernite, Margaret Mitchell, Sean Hughes, Thomas Wolf, Dzmitry Bahdanau, Leandro von Werra, and Harm de Vries. The Stack: 3TB of permissively licensed source code. Preprint, 2022.
[KVPF20] Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and François Fleuret. Transformers are rnns: Fast autoregressive transformers with linear attention. In International Conference on Machine Learning, pages 5156–5165. PMLR, 2020.
[LDM12] Hector Levesque, Ernest Davis, and Leora Morgenstern. The winograd schema challenge. In Thirteenth International Conference on the Principles of Knowledge Representation and Reasoning, 2012.
[LH19] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In International Conference on Learning Representations, 2019.
[MRL+17] Nasrin Mostafazadeh, Michael Roth, Annie Louis, Nathanael Chambers, and James Allen. Lsdsem 2017 shared task: The story cloze test. In Proceedings of the 2nd Workshop on Linking Models of Lexical, Sentential and Discourse-level Semantics, pages 46–51, 2017.
[MWH+22] Shuming Ma, Hongyu Wang, Shaohan Huang, Wenhui Wang, Zewen Chi, Li Dong, Alon Benhaim, Barun Patra, Vishrav Chaudhary, Xia Song, and Furu Wei. TorchScale: Transformers at scale. CoRR, abs/2211.13184, 2022.
[OSG+23] Antonio Orvieto, Samuel L. Smith, Albert Gu, Anushan Fernando, Caglar Gulcehre, Razvan Pascanu, and Soham De. Resurrecting recurrent neural networks for long sequences. ArXiv, abs/2303.06349, 2023.
[PAA+23] Bo Peng, Eric Alcaide, Quentin Anthony, Alon Albalak, Samuel Arcadinho, Huanqi Cao, Xin Cheng, Michael Chung, Matteo Grella, Kranthi Kiran GV, Xuzheng He, Haowen Hou, Przemyslaw Kazienko, Jan Kocon, Jiaming Kong, Bartlomiej Koptyra, Hayden Lau, Krishna Sri Ipsit Mantri, Ferdinand Mom, Atsushi Saito, Xiangru Tang, Bolun Wang, Johan S. Wind, Stansilaw Wozniak, Ruichong Zhang, Zhenyuan Zhang, Qihang Zhao, Peng Zhou, Jian Zhu, and Rui-Jie Zhu. Rwkv: Reinventing rnns for the transformer era, 2023.
[PMN+23] Michael Poli, Stefano Massaroli, Eric Nguyen, Daniel Y Fu, Tri Dao, Stephen Baccus, Yoshua Bengio, Stefano Ermon, and Christopher Ré. Hyena hierarchy: Towards larger convolutional language models. arXiv preprint arXiv:2302.10866, 2023.
[PWD+23] Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, and Furu Wei. Kosmos-2: Grounding multimodal large language models to the world.
ArXiv, abs/2306.14824, 2023.
[RZL17] Prajit Ramachandran, Barret Zoph, and Quoc V. Le. Swish: a self-gated activation function. arXiv: Neural and Evolutionary Computing, 2017.
[SDP+22] Yutao Sun, Li Dong, Barun Patra, Shuming Ma, Shaohan Huang, Alon Benhaim, Vishrav Chaudhary, Xia Song, and Furu Wei. A length-extrapolatable transformer.
arXiv preprint arXiv:2212.10554, 2022.
[Sha19] Noam M. Shazeer. Fast transformer decoding: One write-head is all you need. ArXiv, abs/1911.02150, 2019.
[SLP+21] Jianlin Su, Yu Lu, Shengfeng Pan, Bo Wen, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:2104.09864, 2021.
[SPP+19] Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-LM: Training multi-billion parameter language models using model parallelism. arXiv preprint arXiv:1909.08053, 2019.
[SSI+22] Uri Shaham, Elad Segal, Maor Ivgi, Avia Efrat, Ori Yoran, Adi Haviv, Ankit Gupta, Wenhan Xiong, Mor Geva, Jonathan Berant, et al Scrolls: Standardized comparison over long language sequences. arXiv preprint arXiv:2201.03533, 2022.
[VSP+17] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N.
Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, 4-9 December 2017, Long Beach, CA, USA, pages 6000– 6010, 2017.
[WH18] Yuxin Wu and Kaiming He. Group normalization. In Proceedings of the European conference on computer vision (ECCV), pages 3–19, 2018.
[WMD+22] Hongyu Wang, Shuming Ma, Li Dong, Shaohan Huang, Dongdong Zhang, and Furu Wei. DeepNet: Scaling Transformers to 1,000 layers. ArXiv, abs/2203.00555, 2022.
[WMH+22] Hongyu Wang, Shuming Ma, Shaohan Huang, Li Dong, Wenhui Wang, Zhiliang Peng, Yu Wu, Payal Bajaj, Saksham Singhal, Alon Benhaim, et al Foundation transformers.
arXiv preprint arXiv:2210.06423, 2022.
[WPN+19] Alex Wang, Yada Pruksachatkun, Nikita Nangia, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R Bowman. SuperGLUE: A stickier benchmark for general-purpose language understanding systems. arXiv preprint arXiv:1905.00537, 2019.
[ZHB+19] Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019.
[ZYY+21] Ming Zhong, Da Yin, Tao Yu, Ahmad Zaidi, Mutethia Mutuma, Rahul Jha, Ahmed Hassan Awadallah, Asli Celikyilmaz, Yang Liu, Xipeng Qiu, et al Qmsum: A new benchmark for query-based multi-domain meeting summarization. arXiv preprint arXiv:2104.05938, 2021.
Appendix
A Hyperparameters

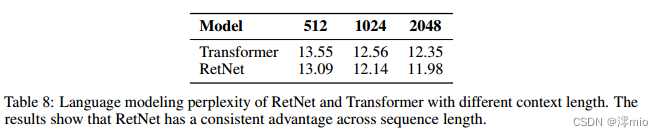
B Grouped Results of Different Context Lengths
如表8所示,我们报告了具有不同上下文长度的语言建模结果。为了使数字具有可比性,我们使用2048个文本块作为评估数据,并且只计算最后128个令牌的困惑度。实验结果表明,RetNet在不同的上下文长度上优于Transformer。此外,RetNet可以利用更长的上下文来获得更好的结果。