模型显示及排序
vi models/library_book.py
# 在class内部加入如下代码
# 为模型添加更为友好的描述,更新后在Settings下可发现相应的变化(需开启调试模式Database Structure>Models)
_description = 'Library Book'
# 默认情况下Odoo使用内置的id进行排序,可以通过逗号分隔指定多个字段进行排序,desc表示降序,仅能使用数据库中存储的字段排序,外部计算后的字段不适用,_order有些类似SQL语句中的ORDER BY,但无法使用NULL FIRST之类的语句
_order = 'date_release desc, name'
# _rec_name用于配置记录表示,模型记录在被其它模型引用时会有表示信息,如user_id为1时表示Administrator用户,当它在表单视图中显示时,会显示为用户名而非id,因为_rec_name的默认值是name,这也是建议在模型内添加name字段的原因,如没有name字段,则采用模型记录的标识符,类似(library.book, 1)
_rec_name = 'short_name'
short_name = fields.Char('Short Title', required=True)
记录表示(record representation)还有一个Odoo 8.0的新增的魔术字段display_name,其值通过name_get()方法生成。默认情况下name_get()使用_rec_name属性来查找该数据,如需更复杂逻辑仅需重写该方法,返回一个包含记录id和记录表示的元组即可。要显示为如平凡的世界 (2017-06-01),在类中定义如下方法
def name_get(self):
result = []
for record in self:
result.append(
(record.id,
"%s (%s)" % (record.name, record.date_release)
))
return result
模型中的数据类型讲解
# vi models/library_book.py
...
# Char用于字符串
short_name = fields.Char('Short Title', required=True)
# Text用于多行字符串
notes = fields.Text('Internal Notes')
# Selection用于选择列表,由值和描述对组成,选择的值将存储在数据库中,可以为字符串或整型,描述默认可翻译
# 虽然整型的值看似简洁,但注意Odoo会把0解析为未设置(unset),因而当存储值为0时不会显示描述
state = fields.Selection(
[('draft', 'Not Available'),
('available', 'Available'),
('lost', 'Lost')],
'State')
# Html类似text字段,但一般用于存储富文本格式的HTML
description = fields.Html('Description')
# Binary字段用于存储二进制文件,如图片或文档
cover = fields.Binary('Book Cover')
# Boolean字段用于存储True/False布尔值
out_of_print = fields.Boolean('Out of Print?')
# Date字段用于存储日期,ORM中以字符串格式对其进行处理,但以日期形式存放在数据库中,该格式在odoo.fileds.DATE_FORMAT中定义
date_release = fields.Date('Release Date')
# Datetime用于存储日期时间,在数据库中以UTC无时区时间(naive)存放,ORM中以字符串和UTC时间表示,该格式在odoo.fields.DATETIME_FORMAT中定义
date_updated = fields.Datetime('Last Updated')
# Integer即为整型
pages = fields.Integer('Number of Pages')
# Float用于存储数值,其精度可以通过数字长度和小数长度一对值来进行指定
reader_rating = fields.Float(
'Reader Average Rating',
digits=(14, 4), # Optional precision (total, decimals)
)
# 此外Monetary用于存储货币金额
# 所有字段都有一些通用属性,如我们可以将pages字段丰富为:
pages = fields.Integer(
string='Number of Pages',
default=0,
help='Total book page count',
groups='base.group_user',
states={
'lost': [('readonly', True)]},
copy=True,
index=False,
readonly=False,
required=False,
company_dependent=False,
)
# Char和HTML字段分别一些特殊属性,如:
short_name = fields.Char(
string='Short Title',
size=100, # 仅用于Char字段
translate=False, # Text字段也可使用
required=True)
description = fields.Html(
string='Description',
# 以下均为可选属性
sanitize=True,
strip_style=False,
translate=False,
)
从上例中我们也可以看出字段中可以包含属性:
- string是字段的标题,在UI的视图标签中使用,这是可选项,如未设置,将会通过字段名称以空格替换下划线的标题体显示
- size仅适用于Char字段,用于设置所允许的最大字符数,通常不建议使用
- translate设置为True时该字段为可翻译的,可根据用户界面语言包含不同值
- default用于设置默认值,也可跟一个方法名,如default=_compute_default,方法的定义需在字段定义前
- help设置在UI页面中显示的解释性提示内容
- groups设置可使用该字段的安全组,值为一组安全组的XML ID并以逗号分隔组成的字符串,详情参见关于权限控制的后续文章
- states允许在用户界面动态设置readonly, required, invisible属性,取决于状态字段的设置
- copy用于显示在记录被复制时是否为拷贝,对于非关系型以及Many2one字段默认值为True,而对于One2many以及计算字段默认为False
- index设置为True时,会在数据库为该字段创建索引,它代替了已弃用的select=1属性
- readonly设置字段在用户界面中默认为只读
- required设置字段在用户界面中默认为必填
- sanitize用于HTML字段,它去除具有安全威胁的标签,使用它会对全局的输入进行清理。如需更精细的控制,在设置了sanitize后有一些关键词可用:
- santitize_tags=True:清除不在白名单中的标签(在odoo/odoo/tools/mail.py的allowed_tags中定义)
- sanitize_attributes=True:额外清除白名单以外的属性(在odoo/odoo/tools/mail.py的safe_attrs中定义)
- sanitize_style=True:清除白名单以外的样式属性(在odoo/odoo/tools/mail.py的_style_whitelist中定义)
- strip_style=True:清除所有样式元素
- strip_class=True:清除类属性
- company_dependent用于按公司(company)存储不同的值,它取代了已弃用的Property字段
扩展知识
Selection字段除了可像前例中包含选项外,还可进行方法引用 ,动态获取选项列表,本文稍后会进行演示。
Date和Datetime字段有一些工具方法让操作更加方便,Date拥有的方法:
- fields.Date.from_string(string_value) 将字符串解析为一个日期对象
- fields.Date.to_string(date_value) 将Date对象表示为字符串
- fields.Date.today() 以字符串格式返回当天日期,可用于获取默认值
- fields.Date.context_today(record, timestamp) 按record(或记录集)上下文的时区以字符串格式返回时间戳(未传递timestamp参数时返回日期)
Datetime拥有的方法:
- fields.Datetime.from_string(string_value) 将字符串解析为一个datetime对象
- fields.Datetime.to_string(date_value) 将datetime对象表示为字符串
- fields.Datetime.now() 以字符串格式返回当前日期时间,可用于获取默认值
- fields.Datetime.context_timestamp(record, timestamp) 按record上下文的时区以字符串格式转化无时区时间,该方法不适合获取默认值,但可用于将数据传输到外部系统
除了基础字段外,还有关系型字段:Many2one, One2many以及Many2many,后面会进行更深入的探讨。此外还有自动计算值的字段 compute,也在后面介绍。
细心的读者会发现Odoo模型还会默认创建一些字段,所以在定义模型时请不要使用这些名称。这些字段名包含自动生成的标识符id,还有一些日志审计字段:
- create_date:记录创建的时间截
- create_uid:创建记录的用户
- write_date:最近一次编辑记录的时间截
- write_uid:最近一次编辑记录的用户
这些自动创建的日志字段,可通过加入_log_access=False属性来进行关闭。另一个可添加到模型中的特别字段名是active,它是一个标识记录是否可用的布尔字段:
active = fileds.Boolean('Active', default=True)
默认情况下只有active设为True的才可见,而要获取不可见记录,可通过域控制器[(‘active’, ‘=’, False)],另一种方法是将‘active_test’: False加入到环境上下文中,否则ORM无法获取不可用记录。
小知识:有时无法通过修改上下文来同时获取可见和不可见记录,这时使用[‘|’, (‘active’, ‘=’, True), (‘active’, ‘=’, False)]域。注意[(‘acitve’, ‘in’ (True, False))]并不会像你所预期的起到相似作用。
浮点数字段的精度配置
在使用浮点数字段时,可能需要终端用户来配置精度,下面我们用Decimal Precision Configuration插件来实现,然后在Library Book模型中加上一个成本字段供用户指定精度。
1.首先在后台中点击Apps搜索到Decimal Precision Configuration点击Install进行安装
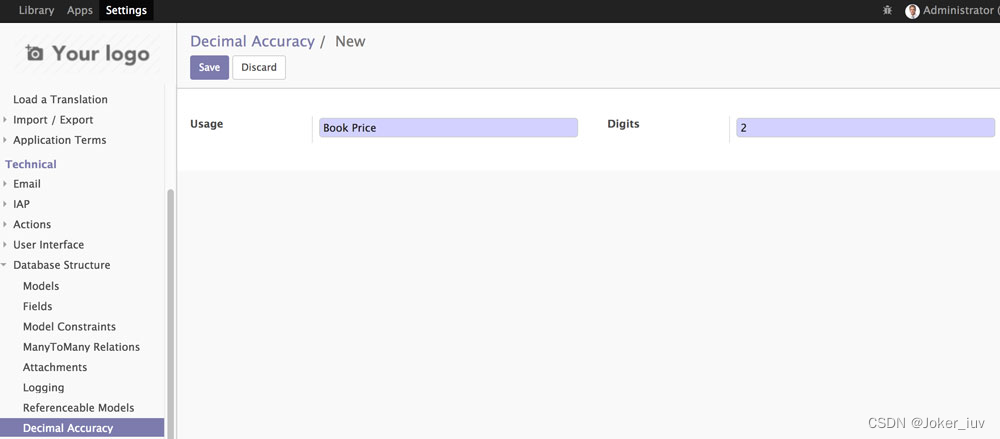
2.开启开发者模式点击Settings > Technical > Database Structure > Decimal Accuracy,添加一个Book Price并设置精度为小数点后两位
3.添加依赖
vi local-addons/my_module/__manifest__.py
# 加入依赖
'depends': ['base', 'decimal_precision'],
4.添加cost_price并使用前述精度设置
vi local-addons/my_module/models/library_book.py
# 相入数字精度
from odoo.addons import decimal_precision as dp
# 通过get_precision方法在Decimal Accuracy中插件前面设置的精度配置
cost_price = fields.Float('Book Cost', dp.get_precision('Book Price'))
通过以上方法可以让终端用户在后台中自行控制精度。
在模型中添加货币(Monetary)字段
Monetary字段需要一个额外的currency字段来存储金额:
vi local-addons/my_module/models/library_book.py
# 在类中添加字段
currency_id = fields.Many2one('res.currency', string='Currency')
retail_price = fields.Monetary(
'Retail Price',
# optional: currency_field='currency_id',
)
更新后可在Settings > Technical > Database Structure > Models中看到相应的变化,currency字段通常使用currency_id,当然也可使用其它名称,此时就需要通过可选的currency_field属性来进行指定。
小技巧:这点非常有用,我们可以通过设置多个fields.Many2one(res.currency)来维护不同货币,比如一个销售订单货币,一个公司结算货币。
为模型添加关系型(relational)字段
Odoo的模型间关系通过关系型字段表示,有三种不同关系:many-to-one(缩写为m2o)、one-to-many(缩写为o2m)、many-to-many(缩写为m2m)。以我们的图书案例而言,每本书有一个出版社,所以书和出版社间是many-to-one的关系;而以出版性的视角来看,其与书的关系为one-to-many;每本书可以有多个作者,而每个作者也可以有多本书,所以作者与书的关系为many-to-many。
Odoo中使用Partner模型res.partner来表示人、机构和地址,所以此处作者和出版社则使用res.partner:
vi local-addons/my_module/models/library_book.py
# 为出版商添加many-to-one字段,many-to-one字段会在数据表中添加一列并存储相关联记录的ID,在数据库层面上会为其创建一个外键约束,以确保所存储的这些ID在关联表为有效引用 。通常应考虑添加索引,默认不会添加,需通过index=True属性来设置
publisher_id = fields.Many2one(
'res.partner', string='Publisher',
# 以下为可选项
# ondelete属性用于决定many-to-one字段相关联记录删除时的操作,如本例中出版社删除后对书本如何操作?默认值为set null,将字段设为空值,还可以为restrict:防止相关联记录的删除,cascade:删除相关联记录
ondelete='set null',
# context和domain在其它关联字段中也有效,主要用于客户端。在通过字段点击到相关联记录视图时,context为客户端上下文添加变更 ,如通过该视图创建新记录时设置默认值
context={
},
# domain为相关联记录添加过滤以控制可用记录
domain=[]
)
# 添加出版商和书的one-to-many(需要继承partner模型)以及书和作者的many-to-many,
class ResPartner(models.Model):
# _inherit在后面会进行更深入的讨论
_inherit = 'res.partner'
# one-to-many与many-to-one相反,其在数据库中并没有体现,更多的是程序端的shortcut来让视图能表示相关联的记录
published_book_ids = fields.One2many(
'library.book', 'publisher_id',
string = 'Published Books'
)
# 书到作者的关系已通过author_ids定义,此处用于添加作者到书的关系
# many-to-many关联不在模型的表中添加列,此类关联在数据库中通过中间表实现,创建新记录时在该表中创建书与作者间的关联,Odoo自动创建关联表,默认表名使用按字母排序的两个模型名加上_rel,当然我们可以使用relation属性来覆盖该默认值
# 注意:如果两表的名称较长,会导致自动生成的名称超PostgreSQL 63个字符的上限,因此建议在两表的表名起过23个字符时使用relation属性来指定一个更短的名称
authored_book_ids = fields.Many2many(
'library.book',
string='Authored Books',
# optional: relation = 'library_book_res_partner_rel'
)
更新后可在Settings > Technical > Database Structure > Models中看到相应的变化
扩展知识
Many2one字段有一个auto_join属性可允许ORM在此字段上使用SQL合并,这会不受用户权限控制以及记录权限的限制。在特定情况下这会提高性能,但一般不建议这么使用。
前述定义关联字段的方式较为简洁,出于介绍的完整性进行如下补充:
One2many字段属性:
-
comodel_name:这个是目标模型标识符并且对于所有关联字段都为必备,但是我们可放在具体位置来定义而无需使用该关键字
-
inverse_name:仅用于One2many,为反向的Many2one关联目标模型字段名
-
limit:仅用于One2many和Many2many,设置用户界面中读取记录数的限制
Many2many字段属性: -
comodel_name:参见前述
-
relation:支持关联的数据表名,覆盖默认自动生成的名称
-
column1:与此模型关联的数据表Many2one字段名
-
column2:与comodel模型关联的数据表Many2one字段名
对于Many2many关联,大多数情况下ORM都会很好地处理这些属性的默认值,甚至发现反向Many2many关联以及已存relation表,并妥善翻转column1和column2的值。但在两种情况下需人为干预,一种情况是在两个模型间需要一个以上的Many2many关联,这时我们需指定relation属性以避免冲突;另一种情况是自动生成的关联表名称长度超过PostgreSQL数据库对象名称的63个字符上限。
自动生成的关联表名称为_rel,但同时还会为关联表主键创建一个索引,标识符为relid_id_key,它同样受63个字符上限的限制。
为模型添加等级(hierarchy)
等级表现为与自身的模型关联,每条记录在同一模型中有一个父级记录以及一些子记录,这可以通过与模型自身的many-to-one关联实现。Odoo还为这类字段添加了Nested set model的支持,激活后在域过滤中使用child_of操作符的查询会有明显的提速。
下面我们来创建一个等级分类树来对书本分类,新增一个library_book_categ.py文件:
- 在__init__.py添加代码以载入该文件
vi local-addons/my_module/models/__init__.py
from . import library_book_categ
2.添加library_book_categ.py文件内容
vi local-addons/my_module/models/library_book_categ.py
from odoo import models, fields, api
class BookCategory(models.Model):
_name = 'library.book.category'
name = fields.Char('Category')
# Many2one关联用于创建引用父记录字段
parent_id = fields.Many2one(
'library.book.category',
string='Parent Category',
# 此处值必须为restrict或cascade
ondelete='restrict',
# 添加索引用于快速发现子记录
index=True)
# One2many关联不会在数据库中添加额外字段,而是在获取所有记录时快捷地把此记录作为父记录
child_ids = fields.One2many(
'library.book.category', 'parent_id',
string='Child Categories')
# 为使用等级的支持,加入如下代码。通过以下三项配置可获取更快的数据读取速度,但同时写入的开销也会更大,第一项配置为True时后两项将会用于存储等级树中的搜索数据;默认使用parent_id字段作为记录的父级,也可通过_parent_name来进行指定,如_parent_name = 'parent_id'
_parent_store = True
parent_left = fields.Integer(index=True)
parent_right = fields.Integer(index=True)
# 防止循环关联,添加如下方法。以下配置防止记录同时存在于上升和下降树级中,这会导致无限循环,models.Model中有一个_check_recursion工具方法可在此处复用
@api.constrains('parent_id')
def _check_hierarchy(self):
if not self._check_recursion():
raise models.ValidationError(
'Error! You cannot create recursive categories.')
扩展知识:以上方法用于“静态”等级中,也就是说常用操作为读取和查询 ,而很少会进行更新。显然图书的分类比较固定,读者也常常会按分类进行搜索,因而非常适用。这么说的原因在于嵌套集模型(Nested Set Model)的使用要求在新类的插入、删除或修改时parent_left和parent_right及其它相关数据库索引均需更新,在并行事务同时运行时这会带来很大的系统开销。
小技巧:在处理动态等级结构时,标准的parent_id和child_ids关联会通过避免表级锁来提高性能。
为模型添加约束验证
模型可通过验证来避免出现非预期情况,这一约束有两种:一种是数据库级的检查,另一种是服务器级的检查。前者仅限于PostgreSQL支持的约束,最常用的就是UNIQUE约束,此外还有CHECK和EXCLUDE约束,如果这些都无满足需求,则可通过书写Python代码在应用Odoo服务器级别的约束。
以下我们会添加一个数据库约束来防止重复的书名,Python模型约束在避免发行日期晚于当前日期:
1.创建一个数据库约束
vi local-addons/my_module/models/library_book.py
...
# _sql_constraints可通过列表来设置约束,每个约束为一个包含三个元素的元组:1.约束标识符后缀,如此处的name_uniq会形成一个library_book_name_uniq约束名;2.在PostgreSQL中修改或创建数据表的SQL指令;3.在违反约束时返回给用户的消息。前面提到过还可以使用其它数据表约束,但请注意如NOT NULL这样的列约束是无法使用的,可在官网获取更多<a href="https://www.postgresql.org/docs/current/static/ddl-constraints.html" target="_blank" rel="noopener">PostgreSQL约束知识</a>
_sql_contraints = [
('name_uniq',
'UNIQUE (name)',
'Book title must be unique.')
]
2.通过python代码在类中添加一个服务器级约束
vi local-addons/my_module/models/library_book.py
from odoo import api
...
# 此处使用@api.contrains装饰器,表示在参数列表中字段发生变化时进行检测,如果检测失败,则抛出ValidationErorr异常
@api.constrains('date_release')
def _check_relase_date(self):
for record in self:
if(record.date_release and record.date_release > fields.Date.today()):
raise models.ValidationErorr('Release date must be the past')
注意:_constraints模型属性依然存在,在8.0版本后弃用,推荐使用@api.constrains装饰器
为模型添加可计算(computed)字段
有时我们需从本记录或关联记录中计算获取字段值,常见的有根据单价和数量计算总价,在Odoo中通过可计算字段来实现。我们将在本例中根据发行日期计算天数来学习这一知识。可计算字段同样也可以被编辑和搜索。
vi local-addons/my_module/models/library_book.py
from datetime import timedelta
from odoo import api
from odoo.fields import Date as fDate
...
# 首先添加新字段,定义方法与普通字段相似,多了一个compute属性来指定执行计算的方法。虽然相似,但可计算字段和普通字段却大不相同,它在运行时动态计算,除非自己添加逻辑,默认是不可写、不可搜索的
age_days = fields.Float(
string='Days Since Release',
# 计算方法应保持为可计算字段设置值,否则会抛出错误并且很难调试,通常if条件语句会导致未能成功赋值
compute='_compute_age',
# 写的支持可通过inverse方法来完成,它使用可计算字段的值来更新原始值
inverse='_inverse_age',
# 通过search属性也可以让未存储计算字段可被搜索。本方法并不是完成实际搜索,而是接收字段用于搜索的操作符和值作为参数,返回替换了搜索条件的域。配合把Date Since Release字段搜索转化为等价于Release Date的搜索。
search='_search_age',
# 可选的store=True配置将字段存入数据库,这时计算后值可像普通字段那样被获取,但借助@api.depends装饰器,ORM可以获知何时需重新计算并更新值,可以理解一个永久缓存。这样字段就可以使用搜索条件、排序、分组,而无需添加search方法了。
store=False,
# compute_sudo=True用于需要提升权限完成计算的情况,需谨慎使用,它会忽略所有权限规则 ,包括多公司设置中的公司隔离规则
compute_sudo=False,
)
# 添加计算逻辑,计算方法是在运行时动态计算的,但ORM采用缓存技术避免每次获取值时的无效运算,因而需要通过@depends装饰器来了解所依赖字段,已在需要时更新缓存中的值。
@api.depends('date_release')
def _compute_age(self):
today = fDate.from_string(fDate.today())
for book in self.filtered('date_release'):
delta = (today - fDate.from_string(book.date_release))
book.age_days = delta.days
# 添加方法用于在可计算字段上完成写的逻辑
def _inverse_age(self):
today = fDate.from_string(fDate.context_today(self))
for book in self.filtered('date_release'):
d = today - timedelta(days=book.age_days)
book.date_release = fDate.to_string(d)
# 添加方法允许可计算字段的搜索
def _search_age(self, operator, value):
today = fDate.from_string(fDate.context_today(self))
value_days = timedelta(days=value)
value_date = fDate.to_string(today - value_days)
# convert the operator
# book with age > value have a date < value_date
operator_map = {
'>': '<', '>=': '<=',
'<': '>', '<=': '>=',
}
new_op = operator_map.get(operator, operator)
return [('date_release', new_op, value_date)]
暴露其它模型中存储的关联字段
Odoo客户端在从服务器中读取数据时,仅能获取查询模型中的字段值,客户端无法像服务器端那样使用点标记来获取数据。但是通过添加为关联字段则可进行获取,下面我们对出版商的城市进行这一操作。
vi local-addons/my_module/models/library_book.py
...
publisher_city = fields.Char(
'Publisher City',
related='publisher_id.city',
readonly=True
)
关联字段和普通字段相似,但多了一个related属性,采取另一套遍历链。本例中通过publisher_id来获取出版社相关记录,然后读取city字段,也以使用更长的链式结构,如publisher_id.country_id.country_code。上面我们还使用了readonly属性,否则的话用户可以修改值,这就会更改掉关联出版商的城市。
扩展知识:
关联字段实际上是可计算字段,仅仅通过快捷方式读取关联模型中的值。既然是可计算字段,store字段也可以用在这里,它也可以引用关联字段中的name, translatable和required等属性。此外还有类似compute_sudo的related_sudo,设为True,字段链式遍历不会进行用户权限检查。
小技巧:在关联字段中使用create()会损害性能,因为计算会等到创建完成后进行。因而如果有One2many关联,比如sale.order和sale.order.line模型,并在line模型中引用order模型中的字段,需在记录创建时显式读取order模型中的字段,而不使用关联字段快捷方式,在有多条line记录尤其应当如此。
使用引用(Reference)字段添加动态关联
使用关联字段,我们需事先决定关联的目标模型(comodel),但这有时需让用户来决定,我们只要设置好想要用到的模型和指向的记录即可,这Odoo中用相用字段来实现
vi local-addons/my_module/models/library_book.py
....
# 按helper方法的定义添加引用字段
ref_doc_id = fields.Reference(
selection='_referencable_models',
string='Reference Document'
)
...
# 添加helper方法来动态创建可选目录模型列表
@api.model
def _referencable_models(self):
models = self.env['res.request.link'].search([])
return [(x.object, x.name) for x in models]
引用字段与many-to-one字段相似,区别在于它允许用户选择指向的模型。目标模型可从selection字段指定的列表中选择,这一列表中需包含一组带有两个参数的元组,第一个参数为模型内部标识符,第二个参数为文字描述。例如
[(‘res.users’, ‘User’), (‘res.partner’, ‘Partner’)]
一般不使用固定列表,我们可以让终端用户来配置模型列表,这也是内置Settings > Technical > Database Structure下的Referencable Models的目的所在,该模型的内置标识符为res.request.link。以上我们使用了一个方法浏览所有可被引用以动态创建给selection属性列表的模型记录,虽然selection后可直接引用方法,但我们这里添加了引号,这种方式更为灵活,它允许方法在声明字段后进行定义。使用了@api.model装饰器是因为在模型级别上操作而非记录集。
注意:这种方式虽然很好用,但负载比较大,比如以列表视图显示大量记录引用字段时会因每个值进行一次单独查询而带来数据库的压力,同时也不能像普通关联字段那样用到数据库的引用完整性。
使用继承为模型添加特征(features)
Odoo的一个重要特性是能够在模块插件中继承其它模块插件的特征,而无需对原特征进行编辑。特征可以为添加字段或方法、修改现存字段或继承已有方法来添加逻辑。这是最常用的继承方法,官方文档中称之为传统/经典继承(traditional/classical inheritance)。我们将一起继承内置的Partner模型,将有作者书本数量添加到可计算字段中。
vi local-addons/my_module/models/library_book.py
class ResPartner(models.Model):
# 使用_inherit则是继承的模型进行修改而非替换,在继承类中定义的方法会替换父类中的,所以想要使用原方法时,需要使用super关键字
_inherit = 'res.partner'
_order = 'name'
authored_book_ids = fields.Many2many(
'library.book',
string='Authored Books',
# optional: relation = 'library_book_res_partner_rel'
)
count_books = fields.Integer(
'Number of Authored Books',
compute='_compute_count_books')
@api.depends('authored_book_ids')
def _compute_count_books(self):
for r in self:
r.count_books = len(r.authored_book_ids)
扩展知识:
使用_inherit传统继承,也可以将父级模型的特征拷贝到新模型中,通过在类中给_name属性加一个不同的标识符即可,如
class LibraryMember(models.Model):
_inherit = 'res.partner'
_name = 'library.member'
新模型会拥有独立于res.partner父模型以外的自己的数据表,因其继承自Partner模型,后续更改也会在新模型中体现。官方文档中称之为原型继承(prototype inheritance),实际应用中很少使用,因为委托继承(delegation inheritance)以更高效的方式满足了这一需求,它无需复制一套数据结构,在后面就会介绍到。
使用抽象模型来复用模型特征
有时会存在想要在多个模型中使用的特殊特征,重复编码不是一个好的代码习惯,那么最好自然是一次编写多次复用。抽象模型可以用于编写通用模型,将其中的特征供其它普通模型继承使用。下面我们编写一个存档特征,它将active字段添加到模型中并开放存档方法供切换active标识。这个起作用是因为active是一个魔术字段,如果在模型中默认存在,active=False的记录会查询中被过滤掉。
Archive特性可以单独成为一个插件,但为了结构简洁,依然使用我们一直以来的library_book.py文件:
# 抽象模型通过models.AbstractModel定义,拥有所有普通模型的属性,不同处在于ORM不会在数据库中创建一个实际表现,因而无法存储数据。它的用处就是作为模板来提供可复用特性。这个抽象模型非常简单,仅包含了一个active字段和一个切换active标识的方法。
class BaseArchive(models.AbstractModel):
_name = 'base.archive'
active = fields.Boolean(default=True)
def do_archive(self):
for record in self:
record.active = not record.active
class LibraryBook(models.Model):
_name = 'library.book'
# _inherit后可接字符串或列表,列表可用于继承多个模型类
_inherit = ['base.archive']
扩展知识
值得一提的是有一个内置抽象模型mail.thread,由mail插件模型提供,它可以在模型中激活讨论特征(用于很多表单底部的信息墙)。除了AbstractModel外,还有一个models.TransientModel。表现类似models.Model,但所创建记录为临时性的,会被服务端定时任务按时清理,其它的都和普通模型相同。对于更为复杂的用户交互(称作向导wizards)它会比较有用,比如要求用户输入内容来运行进程或报告。
使用委托(delegation)继承向另一个模型拷贝特征
传统继承通过_inherit来继承模型特征进行修改,但还存在是修改已存在模型的情况,仅仅是想要使用一些现有特性,这在Odoo中以_inherits用委托继承来实现。传统继承不同于面向对向编程的概念,而委托代理则更为相似,它可以创建包含父级模型特征的新模型,并且支持多态继承,即从两个或以上的模型中继承。
接下来我们来添加图书会员,需要Partner模型中所存在的身份和地址数据,以及开始日期,终止日期和卡号等会员所用到的信息。
vi local-addons/my_module/models/library_book.py
class LibraryMember(models.Model):
_name = 'library.member'
# 字典中的key为所继承的模型,值为进行关联的字段名
_inherits = {
'res.partner': 'partner_id'}
partner_id = fields.Many2one(
'res.partner',
ondelete='cascade')
# 添加一些图书会员需用的字段
date_start = fields.Date('Member Since')
date_end = fields.Date('Termination Date')
member_number = fields.Char()
date_of_birth = fields.Date('Date of Birth')
创建会员时,数据库中会在res_partner表中创建一条新记录,在library_member中创建一条新记录,library_member的partner_id字段设置为在res_partner中创建记录的id。会员记录和新的Partner记录自动关联。那么在删除会员时会发生什么呢?这通过ondelete的值来控制,这里用的cascade表示删除Partner时也会删除Member,更保守的设置是restrict,这时删除Partner并不会删除Member。
要注意委托继承仅能用于字段,无法用于方法。
扩展知识
委托继承的用户模型res.users,继承自res.partner,也就意味着User中存储的一些字段实际存储在Partner模型中(如name字段),创建用户时,也会自动创建一个Partner。
-------------------------------------摘自 Alanhou