写在前面
在前面学完单链表后,我们思考这样一个问题,单链表和顺序表比起来,功能确实相当强大,有很多优势,但是于此同时,我们也应思考下面的问题
单链表有什么不足的地方?
如果你把单链表的各个函数都自己实现过,那么下面的问题你一定有相同的感悟
- 单链表实现尾插尾删等操作,需要寻找尾部节点,而寻找尾部节点是一个相当繁琐的过程,需要从前向后寻找尾
- 单链表实现插入功能,对于单链表来说,通常实现的是在pos后插入,而不在pos前插入,原因就在于pos向前插入需要寻找前面的节点,而这个节点只能从前向后遍历寻找
- 单链表在实现函数时,要时时刻刻想到链表为空的情况,对于链表为空的情况要有特殊的处理方式
那么能不能想办法解决下面这些问题?
- 找尾部节点方便
- 找一个节点的上一个节点方便
- 不需要考虑空链表的空指针问题
于是数据结构中对于双向循环链表就解决了这个问题
双向循环链表的构造布局
带有哨兵位的布局
首先介绍什么是哨兵位
和它的名字一样,所谓哨兵位就是一个站哨的位置,它并不属于真实的队伍中的成员,而在链表中也是如此,在前面总结单链表所学的知识时,没有引入哨兵位的链表,而是直接用空链表进行写入,这样的目的不仅仅在于方便后续的OJ练习,同时也是适应特殊情况,为后续的c++学习做铺垫
而在双向循环链表中我们引入哨兵位的概念,作为哨兵的位置,它本身并不属于链表中的一部分,只是充当一个头的位置
哨兵位怎么设置?
链表的每一个节点我们都是通过结构体创建出来的,而很明显,哨兵位也是链表的节点,就意味着哨兵位也有指针部分和数据部分,那么对于数据部分我们应该怎么对它定义?
在一部分书中,哨兵位的数字部分会定义的链表的长度,也就是链表中元素的个数,这样乍一看似乎还不错,借助这个哨兵位还能获取到链表的长度
但是这样真的没问题吗?
事实上这是存在一定的问题的,假设这里选取的是char类型的数据类型,对于char类型的数据范围是从-128到127(char类型占1个字节决定的) 那么这里就有了一个新的问题,假设链表中存储的是char类型的数据,那么假设链表的长度为128呢?那么就会导致链表的实际长度和存储长度有很大差距
于是这里对于哨兵位我并不对它的数据部分有特殊的意义,单纯给它赋予一个值-1
带哨兵位的双向循环链表如下
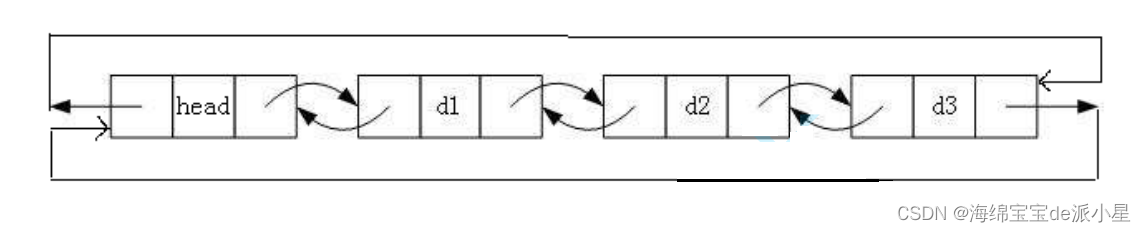
上面就是双向循环链表的示意图,从中可以看出,每一个节点可以轻松找到它的下一个节点,以及最后一个节点和头节点是循环在一起的
既然是双向的链表,那么在定义结构体的过程就和单链表有所不同,这里的指针部分应该有两个,prev和next部分,那么结构体的定义如下
typedef int LTDataType;
typedef struct ListNode
{
LTDataType _data;
struct ListNode* _next;
struct ListNode* _prev;
}ListNode;
这样就实现了对链表的定义,prev和next均有
和单链表相同,双向循环链表也离不开增删查改的基本操作,那么这里我们一个一个来实现这些功能
链表的构建
链表的构建就是构建一个phead的哨兵位节点,这个过程还是很简单的
ListNode* ListCreate()
{
ListNode* phead = (ListNode*)malloc(sizeof(ListNode));
if (phead == NULL)
{
perror("malloc fail");
}
assert(phead);
phead->_data = -1;
phead->_next = phead;
phead->_prev = phead;
return phead;
}
链表的销毁
有创建就离不开销毁,销毁的过程和单链表基本相似,都是通过指针把一个节点单独拿出来,free后再置空,代码实现如下
void ListDestory(ListNode* pHead)
{
assert(pHead);
ListNode* cur = pHead->_next;
while (cur != pHead)
{
ListNode* next = cur->_next;
free(cur);
cur = next;
}
}
链表的输出
链表要打印在屏幕上的基本思路也和单链表基本一致,但需要注意的是,单链表的截止条件是当指针访问到空,而双向循环链表的条件是指针访问到头
void ListPrint(ListNode* pHead)
{
assert(pHead);
ListNode* cur = pHead->_next;
printf("guard<==>");
while (cur != pHead)
{
printf("%d<==>", cur->_data);
cur = cur->_next;
}
printf("\n");
}
这样,双向循环链表也可以进行可视化管理了,那么下面就开始实现增删查改四大功能
链表的尾插
和单链表相似,但和它比起来更加简单,示意图如下:
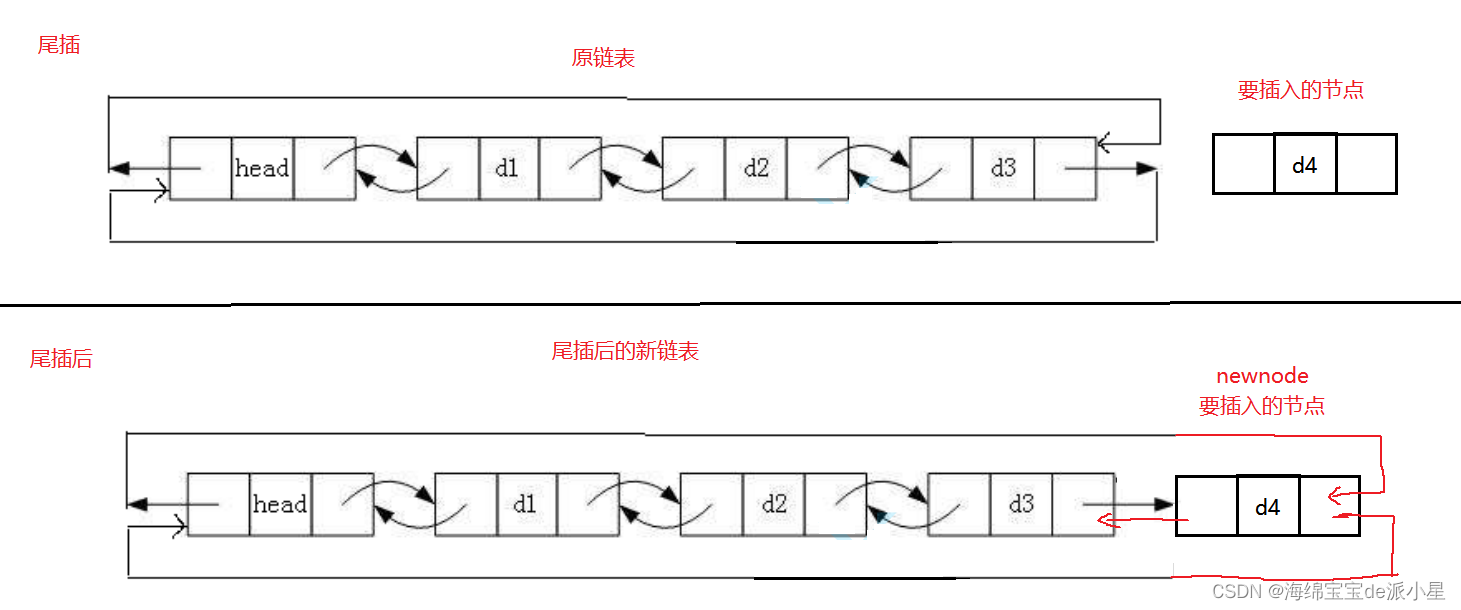
那么代码是如何实现的?代码实现如下
ListNode* BuyListnode(LTDataType x)
{
ListNode* phead = (ListNode*)malloc(sizeof(ListNode));
if (phead == NULL)
{
perror("malloc fail");
}
assert(phead);
phead->_data = x;
phead->_next = NULL;
phead->_prev = NULL;
return phead;
}
void ListPushBack(ListNode* pHead, LTDataType x)
{
assert(pHead);
ListNode* newnode = BuyListnode(x);
ListNode* prevnode = pHead->_prev;
prevnode->_next = newnode;
newnode->_prev = prevnode;
newnode->_next = pHead;
pHead->_prev = newnode;
}
对比单链表的尾插不难发现,这个过程比单链表简单了很多,首先对于空链表的判断就更为简单,同时双向循环链表由于存在双向箭头,导致插入是很便利的,这个过程在pos位置插入时候会体现出双向链表特有的优势
链表的尾删
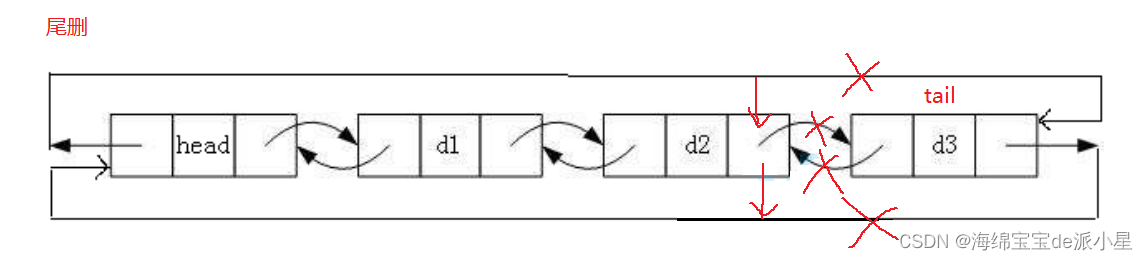
代码实现如下
bool LTempty(ListNode* pHead)
{
assert(pHead);
return pHead->_next == pHead;
}
void ListPopBack(ListNode* pHead)
{
assert(pHead);
assert(!LTempty(pHead));
ListNode* tail = pHead->_prev;
pHead->_prev = tail->_prev;
tail->_prev->_next = pHead;
free(tail);
tail = NULL;
}
== 这里我们对bool返回值的函数进行补充==
bool值意为真和假,在进行尾删时,我们需要首先进行判断链表到底是否为空,但由于双向循环链表,于是我们并不能直观通过判断空指针,这里封装了一个函数,用来判断是否为空,如果为空就返回真,如果不为空就返回假,那么我们在函数体内断言只需要看它不为空即可
链表的头插
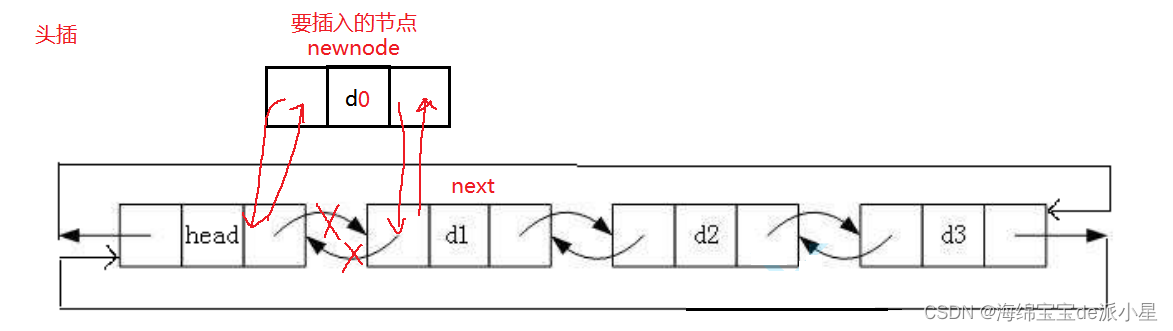
代码实现如下:
void ListPushFront(ListNode* pHead, LTDataType x)
{
assert(pHead);
ListNode* next = pHead->_next;
ListNode* newnode = BuyListnode(x);
assert(newnode);
pHead->_next = newnode;
newnode->_prev = pHead;
next->_prev = newnode;
newnode->_next = next;
}
链表的头删
从头删中其实就体现出了双向链表的优越性
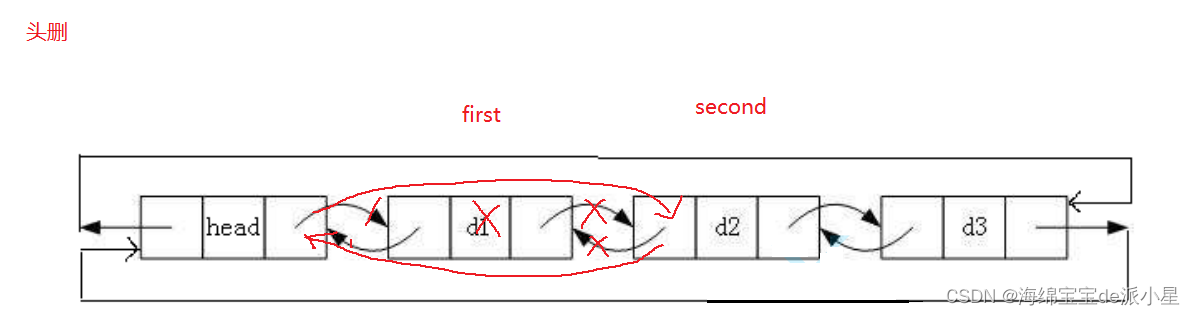
void ListPopFront(ListNode* pHead)
{
assert(pHead);
assert(!LTempty(pHead));
ListNode* first = pHead->_next;
ListNode* second = first->_next;
pHead->_next = second;
second->_prev = pHead;
free(first);
first = NULL;
}
链表的查找
和单链表基本类似,这里不多介绍
ListNode* ListFind(ListNode* pHead, LTDataType x)
{
assert(pHead);
ListNode* cur = pHead->_next;
while (cur->_data != x)
{
cur = cur->_next;
}
return cur;
}
链表的插入
在pos前插入的原理如下
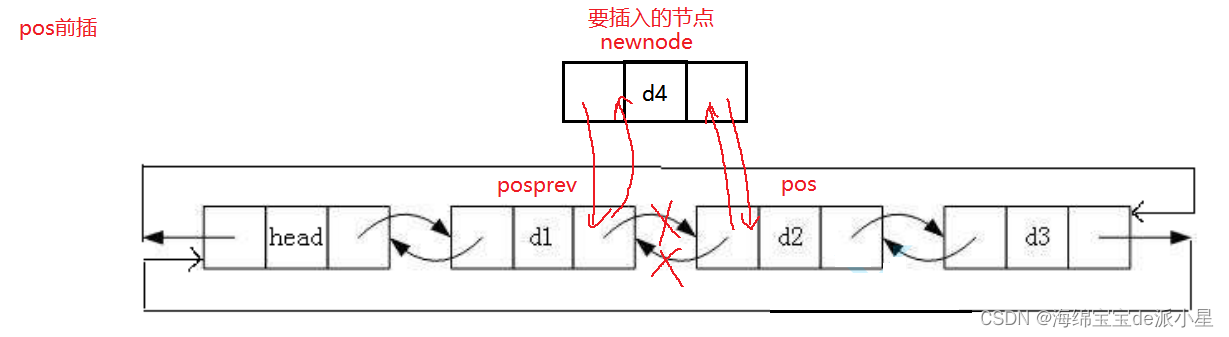
从中和单链表一对比就能够体现出双向链表的优越的地方,在单链表中我们通常不在pos前插入,原因就是pos前面的节点并不方便寻找,而双向链表就解决了这个问题
代码实现如下
void ListInsert(ListNode* pos, LTDataType x)
{
ListNode* posprev = pos->_prev;
ListNode* newnode = BuyListnode(x);
assert(newnode);
assert(pos);
posprev->_next = newnode;
newnode->_prev = posprev;
newnode->_next = pos;
pos->_prev = newnode;
}
链表的删除
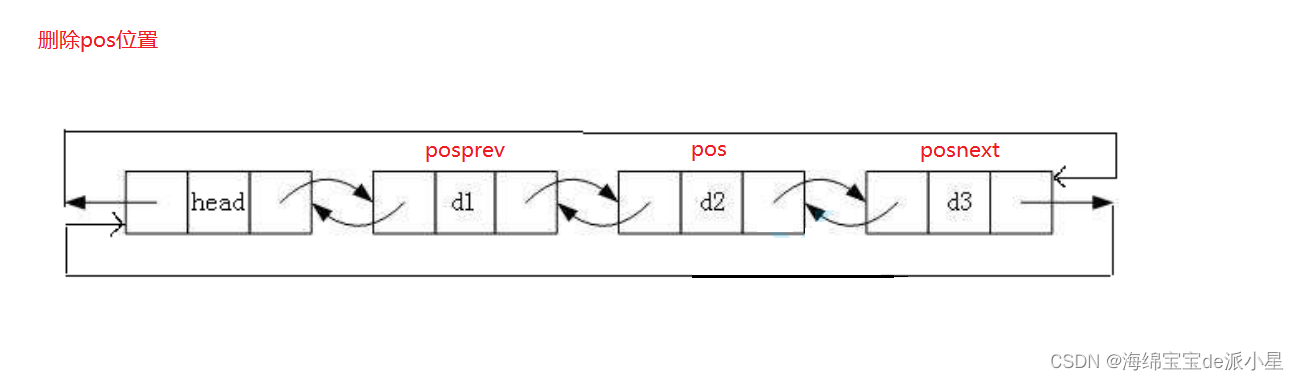
这里和单链表的删除相似,不多描述
void ListErase(ListNode* pos)
{
assert(pos);
ListNode* posprev = pos->_prev;
ListNode* posnext = pos->_next;
posprev->_next = posnext;
posnext->_prev = posprev;
free(pos);
pos = NULL;
}
自此,双向循环链表就实现完毕了,和单链表比起来,双向循环链表确实有它独特强大的地方,而真正使用什么数据结构还需要根据实际情况进行设计