No-SQL:
(1)这些系统大部分是由互联网公司研发,研发目标是支持某公司的某类重要的应用。
(2)放弃使用关系型系统,转而开发专门的系统以支持目标应用。
(1)这些系统大部分是由互联网公司研发,研发目标是支持某公司的某类重要的应用。
(2)放弃使用关系型系统,转而开发专门的系统以支持目标应用。
(3)针对目标应用进行开发,简化了许多关系型系统的功能,以提高系统性能和降低研发成本。不支持完全的SQL,不支持完全的ACID。
Key-Value Store:一种分布式数据存储系统。数据形式为<key, value>,支持Get/Put操作。
一、Dynamo:Amazon公司开发。
<1> 数据模型:最简单的<key, value>。key=primary key,唯一确定这个记录;value,大小通常小于1MB。<2> 操作:Put(key,version,value);Get(key)->(value,version)
<3> ACID:无Transaction概念,仅支持单个<key, value>操作的一致性。
<4> 系统结构:
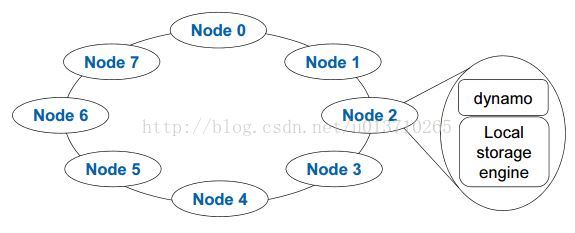
每个node上由local storage engine+dynamo软件层组成。
<5> 数据分布:Consistent Hashing(p2p的关键技术)
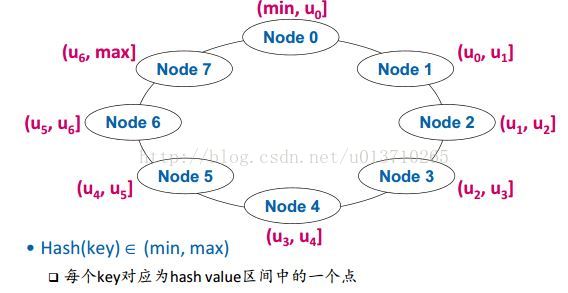
备份:3副本备份。Put带Node j上的数据,要备份到Node j+1和Node j+2上。所以一个Node j上实际存储的数据是(uj-3, uj)。
<6> Quorum机制
如果有N个副本,写的时候保证至少写了W个副本;读的时候至少从R个副本读了数据,满足R+W>N,那么一定读到了最新的数据。这样可以实现读写的一致性。
<7> Eventual Consisitency
系统会最终保证每个<key, value>的N个副本都写成功,都变得一致。
二、Bigtable/HBase:BigTable起源于Google公司,Hbase是开源实现。
<1> 数据模型:<row key, column family:column key, version, value>Key包括row key与column两个部分。所有的row key是按顺序存储的。其中,column又有column family前缀;column family需要事先声明,种类有限;column key可以有很多。具体存储时,每个column family将分开存储,类似列式存储。
<2> 操作
Get:给定row key,column family,column key;读取value。
Put:给定row key,column family,column key;创建或更新value。
Scan:给定一个范围,读取这个范围内所有row key的value。Row key是排序存储的。
Delete:删除一个指定的value。
<3> 系统架构
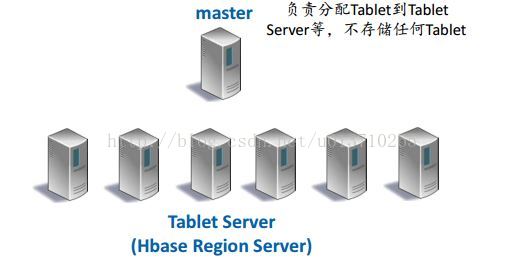
Tablet是一个分布式Bigtable表的一部分。Hbase中Tablet被称为Region。
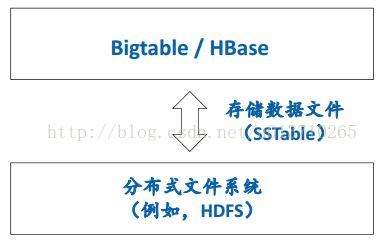
数据冗余由下层的分布式文件系统提供。所以,在BigTable中每个Tablet仅存一份。
三、Cassandra:Facebook开发,后成为Apache开源项目。
基于Java实现。