简介:
HAVING COUNT() 是 SQL 中用于筛选分组结果的关键字,它通常与 GROUP BY 一起使用。HAVING COUNT() 的作用是对分组后的结果进行过滤,只保留满足条件的分组结果。
在没有分组的情况下having和Where 类似。有分组的时候 Where对分组前内容过滤,having是分组后的内容进行筛选。having 里面可以写聚合函数。
说明:
主表 CUSTOM_CABINETS 订单表
副表 CUSTOM_CABINETS_BRAND 品牌表
一、关联查询全部数据
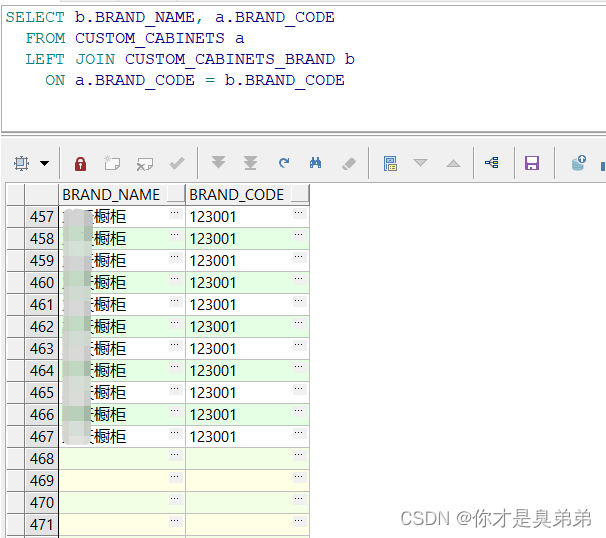
注意: 查询两表相同的数据用inner join,我这里就用left join 为了复现问题。
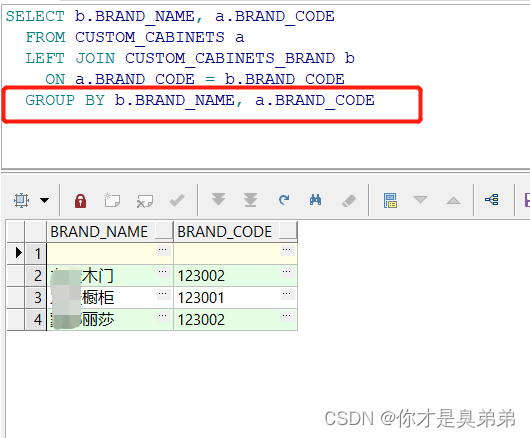
二、关联查询 加Group by 分组
对品牌名称 主表.BRAND_NAME 和 品牌编码 副表.BRAND_CODE 进行分组后 ,查询后有一行空数据,说明我主表数据 存在没有品牌编码(编码 对应 品牌名称)的行,所以现在看到 分组后的数据有NULL。
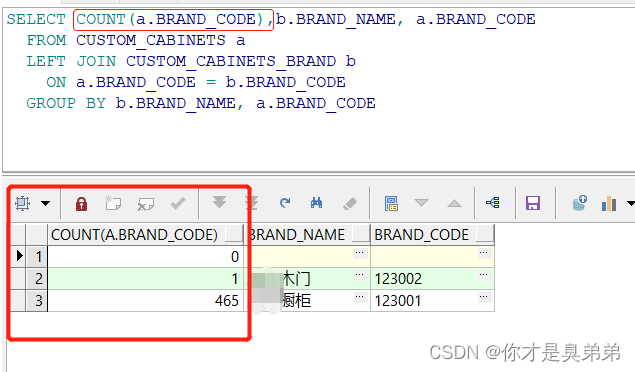
主表统计一下count(a.BRAND_CODE) ,为了更清晰些。
三、关联查询 加 HAVING COUNT 函数
注意重点: group by 分组后 在用having count(*) > 0 进行筛选查询
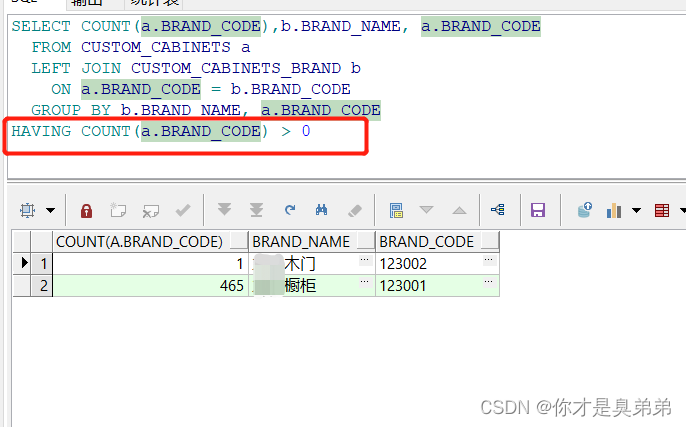
通过 HAVING COUNT(a.BRAND_CODE) > 0 筛选 表中想要的数据 排除NULL 。
总结:
- ①使用 INNER JOIN 将两个表连接起来,连接条件为需要进行计数的列。
SELECT column1, column2, ..., COUNT(column_name)
FROM table1
INNER JOIN table2 ON table1.column_name = table2.column_name
GROUP BY column1, column2, ...
HAVING COUNT(column_name) > 0;- ②在 GROUP BY 子句中指定需要进行计数的列,并使用 COUNT() 函数对这些列进行计数。
SELECT column1, column2, ..., COUNT(column_name)
FROM table1
GROUP BY column1, column2, ...
HAVING COUNT(column_name) > 0;- ③在 HAVING COUNT() 子句中指定计数条件,只保留计数结果大于等于 0 的分组结果。
SELECT column1, column2, ..., COUNT(column_name)
FROM table1
GROUP BY column1, column2, ...
HAVING COUNT(column_name) > 0;