在Thinkpad X260上运行一个CNN图像分类的样例程序时,发现速度特别慢,迭代一轮要将近5分钟,那么迭代200轮需要1000分钟,16个小时!在看到TensorFlow相关的书籍时,总是提到GPU加速,对于这样的问题,应该能派上用场吧。TensorFlow目前只支持NVIDIA显卡,笔者手头没有,阿里云上有GPU计算型ECS,便“按量付费”买了一台,开始了一场“坎坷小贵”的验证之旅。坎坷的原因是没有找到一篇完整的指南,遇到各种的版本问题,Tensorflow作为咕果的产品官网打不开;小贵是因为服务器12元/小时,后来看到NVIDIA Tesla P100一块卖40000元,好吧,也不是阿里云抢咱的钱。下面一起来如何在阿里云GPU计算型ECS服务器上运行TensorFlow机器学习。
友情提示:本文中使用的版本已经经过验证,直接使用这些版本可以避免很多“坑”
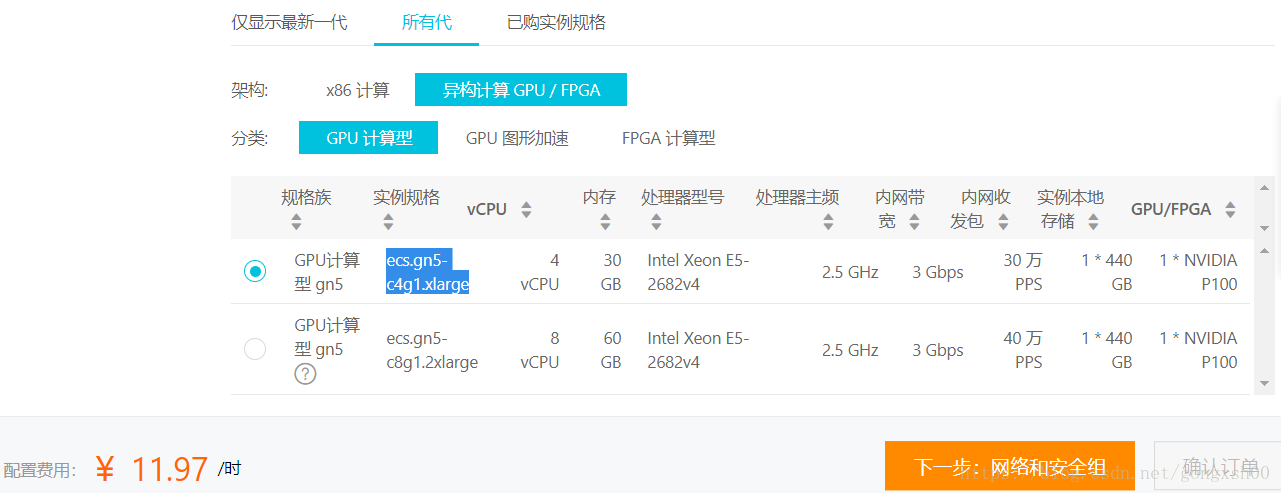
购买阿里云GPU计算型ECS
笔者购买的是ecs.gn5-c4g1.xlarge实例规格,使用Ubuntu 16.04 64位操作系统
安装NVIDIA CUDA Toolkit
NVIDA CUDA Toolkit中含有显卡驱动,不要提前安装显卡驱动,以免冲突。在NVIDA网站上找到CUDA Toolkit 9.0下载地址。
wget https://developer.nvidia.com/compute/cuda/9.0/Prod/local_installers/cuda_9.0.176_384.81_linux-run wget https://developer.nvidia.com/compute/cuda/9.0/Prod/patches/1/cuda_9.0.176.1_linux-run wget https://developer.nvidia.com/compute/cuda/9.0/Prod/patches/2/cuda_9.0.176.2_linux-run
下载后依次执行,执行时可以都接受默认值,或选择y
sh cuda_9.0.176_384.81_linux-run sh cuda_9.0.176.1_linux-run sh cuda_9.0.176.2_linux-run
安装后注意将类库路径添加到LD_LIBRARY_PATH中:
export LD_LIBRARY_PATH=/usr/local/cuda-9.0/lib64
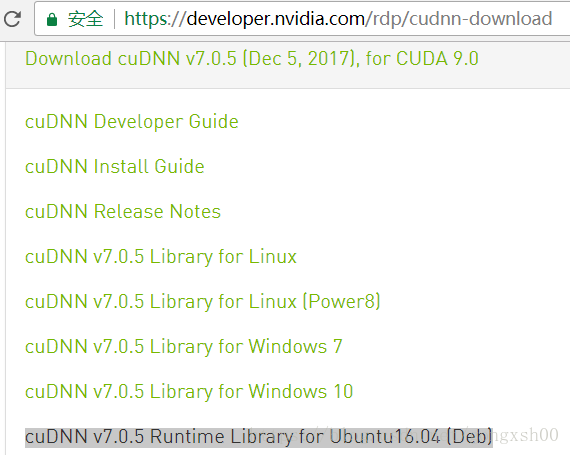
安装cuDNN
先注册一个NVIDIA开发者账号并登录,然后在下载页面https://developer.nvidia.com/rdp/cudnn-download,下载cuDNN v7.0.5 Runtime Library for Ubuntu16.04 (Deb),下载后上传到阿里云服务器
然后执行
dpkg -i libcudnn7_7.0.5.15-1+cuda9.0_amd64.deb
安装TensorFlow GPU版
执行以下的命令,安装兼容的tensorflow-gpu:
apt-get update -y apt-get install -y python3-pip pip3 install --upgrade pip pip3 install tensorflow-gpu
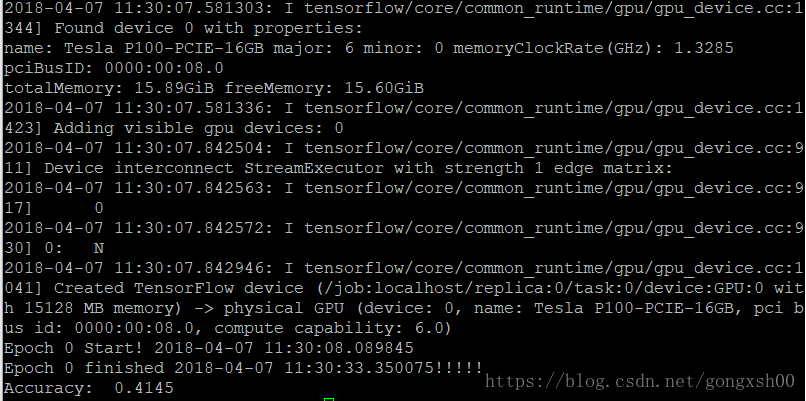
执行TensorFlow训练程序验证
如图,训练一轮的时间已经从Thinkpad上的5分钟加速到了25秒,是否感觉已经从遥不可及变得指日可待了呢?
常见问题汇总
1. ImportError: libcublas.so.9.0: cannot open shared object file: No such file or directory
如果你的服务器上可以搜到libcublas.so.9.0文件,因为类库路径没有添加到LD_LIBRARY_PATH中,可以添加后再试。如果搜索不到,但是存在其它libcublas.so文件,那是版本不兼容,可卸载后重新安装CUDA 9.0再试
2. Loaded runtime CuDNN library: 7102 (compatibility version 7100) but source was compiled with 7005 (compatibility version 7000)
CuDNN版本过高,卸载后安装7.0.5版本即可解决