
模板和STL简介
1. 泛型编程
泛型编程是一种编程范式,旨在实现可重用、通用和高度抽象的代码。它允许程序员编写与数据类型无关的代码,以便在不同的数据类型上进行操作,而无需为每种数据类型重复编写代码。
在传统的编程中,通常需要为每种数据类型编写特定的代码。例如,如果要实现一个排序算法,可能需要为整数、浮点数和字符串等不同的数据类型分别编写排序代码。这种方法效率低下且容易导致代码冗余。
泛型编程通过引入类型参数(type parameter)来解决这个问题。类型参数使得代码可以适用于多种不同的数据类型,而不是针对特定的类型。通过泛型,可以在编写一次代码后,用不同的数据类型实例化它,从而实现代码的复用性。
在很多编程语言中,泛型编程可以通过以下方式实现:
泛型函数:允许在函数定义中使用类型参数,从而实现对不同类型的通用操作。
泛型类:允许在类定义中使用类型参数,使得类的属性和方法可以用于不同类型的数据。
泛型接口:类似于泛型类,但定义了一组规范,供实现了该接口的类使用类型参数。
泛型方法:允许在方法内使用类型参数,使得方法在调用时可以适用于不同的数据类型。
泛型编程的优点包括提高代码的可读性、可维护性和可扩展性,同时减少代码的重复编写。许多现代编程语言,如 Java、C++、C#、Python 和 Rust,都支持泛型编程,使得开发人员能够更有效地编写通用且高效的代码。
根据前面的知识,如果我们要实现各类型的交换函数可能会写出下面的代码:
void Swap(int& left, int& right)
{
int temp = left;
left = right;
right = temp;
}
void Swap(double& left, double& right)
{
double temp = left;
left = right;
right = temp;
}
void Swap(char& left, char& right)
{
char temp = left;
left = right;
right = temp;
}
......
使用函数重载虽然可以实现,但是有一下几个不好的地方:
- 重载的函数仅仅是类型不同,代码复用率比较低,只要有新类型出现时,就需要用户自己增加对应的函数
- 代码的可维护性比较低,一个出错可能所有的重载均出错
那能否告诉编译器一个模子,让编译器根据不同的类型利用该模子来生成代码呢?
下面就来介绍泛型编程的基础——模板
2. 函数模板
2.1 函数模板概念
函数模板代表了一个函数家族,该函数模板与类型无关,在使用时被参数化,根据实参类型产生函数的特定类型版本。
C++ 模板可以通过它与活字印刷术之间的关联来理解。
活字印刷术是一项革命性的发明,活字印刷术最早是由中国北宋时期的印刷家毕昇(Bi Sheng)在11世纪中期发明的。毕昇的活字印刷术是通过雕刻单个汉字的木质或陶质印刷块,然后将这些印刷块组合成词句,并在纸张上进行印刷。这种技术大大提高了书籍的生产效率,使得大规模的书籍印刷成为可能。在活字印刷术之前,书籍复制是通过手工抄写完成的,费时费力且容易出错。活字印刷术的出现使得书籍大规模生产和传播成为可能,对于人类知识的传承和文化的发展产生了深远的影响。
C++ 模板在计算机编程领域也是一种革命性的技术。C++ 模板是一种用于创建通用代码的机制,它允许程序员编写与数据类型无关的代码。类似于活字印刷术中可移动的字母块,C++ 模板中的代码块也可以在编译时根据不同的数据类型进行实例化,从而实现通用性和高效性。
在 C++ 中,可以使用类模板和函数模板。类模板允许定义通用的类,而函数模板允许定义通用的函数。通过使用模板,可以在编写一次代码后,对不同的数据类型进行实例化,从而实现代码的复用。

2.1 函数模板格式
template<typename T1, typename T2,......,typename Tn> 返回值类型 函数名(参数列表){}
现在我们用模板来改造上面的交换函数:
#include <iostream>
using namespace std;
template<typename T>
void Swap(T& left, T& right)
{
T temp = left;
left = right;
right = temp;
}
int main() {
int i = 1;
int j = 2;
double a = 2.3;
double b = 1.2;
char x = 'w';
char y = 'q';
Swap(i, j);
Swap(a, b);
Swap(x, y);
cout << i << ' ' << j << endl;
cout << a << ' ' << b << endl;
cout << x << ' ' << y << endl;
return 0;
}

注意:typename是用来定义模板参数关键字,也可以使用class(切记:不能使用struct代替class)
2.3 函数模板的原理
那么如何解决上面的问题呢?大家都知道,瓦特改良蒸汽机,人类开始了工业革命,解放了生产力。机器生产淘汰掉了很多手工产品。本质是什么,重复的工作交给了机器去完成。有人给出了论调:懒人创造世界。
函数模板的原理在于通过模板实例化,使得编译器可以根据不同的数据类型生成对应的函数代码,从而实现对不同数据类型的通用操作。函数模板为我们提供了一种强大的方式来编写通用、灵活且高效的代码,使得我们可以在一次编写后,用不同的数据类型实例化函数,实现代码的复用和高效性。
函数模板是一个蓝图,它本身并不是函数,是编译器用使用方式产生特定具体类型函数的模具。所以其实模板就是将本来应该我们做的重复的事情交给了编译器。

在编译器编译阶段,对于模板函数的使用,编译器需要根据传入的实参类型来推演生成对应类型的函数以供调用。比如:当用double类型使用函数模板时,编译器通过对实参类型的推演,将T确定为double类型,然后产生一份专门处理double类型的代码,对于字符类型也是如此。
我们可以看到函数模板在汇编中的具体实现如下图:
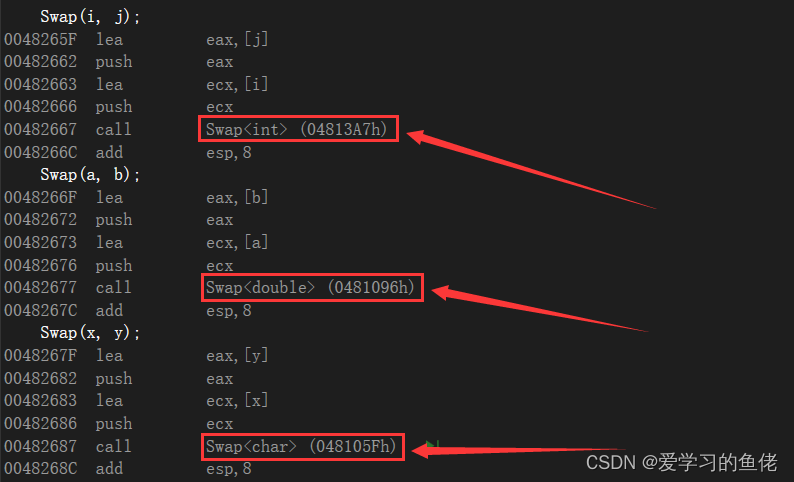
可以看到函数模板在面对不同类型时调用的不是一个函数,而是通过类型推演调用的不同函数,实际在C++的库中已包含的交换函数swap()就是通过模板实现的。
2.4 函数模板的实例化
用不同类型的参数使用函数模板时,称为函数模板的实例化。模板参数实例化分为:隐式实例化和显式实例化。
- 隐式实例化:让编译器根据实参推演模板参数的实际类型
#include <iostream>
using namespace std;
template<class T>
T Add(const T& left, const T& right)
{
return left + right;
}
int main()
{
int a1 = 10;
double d1 = 20.0;
Add(a1, d1);
return 0;
}
该语句不能通过编译,因为在编译期间,当编译器看到该实例化时,需要推演其实参类型通过实参a1将T推演为int,通过实参d1将T推演为double类型,但模板参数列表中只有一个T,编译器无法确定此处到底该将T确定为int 或者 double类型而报错
注意:在模板中,编译器一般不会进行类型转换操作,因为一旦转化出问题,编译器就需要背黑锅
此时有两种处理方式:1. 用户自己来强制转化 2. 使用显式实例化
#include <iostream>
using namespace std;
template<class T>
T Add(const T& left, const T& right)
{
return left + right;
}
int main()
{
int a1 = 10;
double d1 = 20.0;
Add((double)a1, d1);
Add(a1, (int)d1);
return 0;
}
- 显式实例化:在函数名后的<>中指定模板参数的实际类型
#include <iostream>
using namespace std;
template<class T>
T Add(const T& left, const T& right)
{
return left + right;
}
int main()
{
int a1 = 10;
double d1 = 20.0;
Add<double> (a1, d1);
Add<int> (a1, d1);
return 0;
}
如果类型不匹配,编译器会尝试进行隐式类型转换,如果无法转换成功编译器将会报错。
2.5 模板参数的匹配原则
- 一个非模板函数可以和一个同名的函数模板同时存在,而且该函数模板还可以被实例化为这个非模板函数
// 专门处理int的加法函数
int Add(int left, int right)
{
return left + right;
}
// 通用加法函数
template<class T>
T Add(T left, T right)
{
return left + right;
}
void Test()
{
Add(1, 2); // 与非模板函数匹配,编译器不需要特化
Add<int>(1, 2); // 调用编译器特化的Add版本
}
- 对于非模板函数和同名函数模板,如果其他条件都相同,在调动时会优先调用非模板函数而不会从该模板产生出一个实例。如果模板可以产生一个具有更好匹配的函数, 那么将选择模板
// 专门处理int的加法函数
int Add(int left, int right)
{
return left + right;
}
// 通用加法函数
template<class T1, class T2>
T1 Add(T1 left, T2 right)
{
return left + right;
}
void Test()
{
Add(1, 2); // 与非函数模板类型完全匹配,不需要函数模板实例化
Add(1, 2.0); // 模板函数可以生成更加匹配的版本,编译器根据实参生成更加匹配的Add函数
}
- 模板函数不允许自动类型转换,但普通函数可以进行自动类型转换
3. 类模板
类模板(Class Template)是 C++ 中用于创建通用类的机制。类模板允许我们定义一个通用的类模板,其中的数据类型可以通过模板参数来指定,从而实现对不同数据类型的通用操作。
比如我们要在一个文件内同时实现两个存储不同类型的栈,这时我们需要定义多个类
typedef char STDataType;
class Stack
{
private:
STDataType* _a;
int top;
int capacity;
};
class Stacki
{
private:
int* _a;
int top;
int capacity;
};
class Stackc
{
private:
char* _a;
int top;
int capacity;
};
int main()
{
Stackc st1; // char
Stacki st2; // int
return 0;
}
但是我们发现这个结构极其的相似,这时我们就可以使用类模板来解决此类问题
3.1 类模板的定义格式
template<class T1, class T2, ..., class Tn>
class 类模板名
{
// 类内成员定义
};
比如下面使用模板实现的栈类
#include<iostream>
#include<string>
#include <assert.h>
using namespace std;
template<typename T>
class Stack
{
public:
Stack(size_t capacity = 0)
{
if (capacity > 0)
{
_a = new T[capacity];
_capacity = capacity;
_top = 0;
}
}
~Stack()
{
delete[] _a;
_a = nullptr;
_capacity = _top = 0;
}
void Push(const T& x);
void Pop()
{
assert(_top > 0);
--_top;
}
bool Empty()
{
return _top == 0;
}
const T& Top()
{
assert(_top > 0);
return _a[_top - 1];
}
private:
T* _a = nullptr;
size_t _top = 0;
size_t _capacity = 0;
};
// 注意:类模板中函数放在类外进行定义时,需要加模板参数列表
template<class T>
void Stack<T>::Push(const T& x)
{
if (_top == _capacity)
{
size_t newCapacity = _capacity == 0 ? 4 : _capacity * 2;
// 1、开新空间
// 2、拷贝数据
// 3、释放旧空间
T* tmp = new T[newCapacity];
if (_a)
{
memcpy(tmp, _a, sizeof(T)*_top);
delete[] _a;
}
_a = tmp;
_capacity = newCapacity;
}
_a[_top] = x;
++_top;
}
注意:
- 模板不支持分离编译(声明放在.h 定义放在.cpp)
- 模板在同一个文件中,是可以声明和定义分离的
3.2 类模板的实例化
类模板实例化与函数模板实例化不同,类模板实例化需要在类模板名字后跟<>,然后将实例化的类型放在<>中即可,类模板名字不是真正的类,而实例化的结果才是真正的类。
Stack<int> st1;
Stack<char> st2;
Stack类名,Stack<int>才是类型
4.什么是STL
STL 是 C++ 标准模板库(Standard Template Library)的缩写,是 C++ 标准库中的一个重要组成部分。STL 提供了一组通用的模板类和函数,用于实现常用的数据结构和算法,如向量(vector)、链表(list)、映射(map)、排序、查找等,它不仅是一个可复用的组件库,而且是一个包罗数据结构与算法的软件框架。。
STL 的主要目标是提供一种通用、高效、可重用的编程工具,使得 C++ 开发者能够更轻松地编写高质量的代码。它将常用的数据结构和算法抽象为模板类和函数,允许开发者在不考虑底层实现的情况下,直接使用这些通用的容器和算法。这种设计使得 STL 可以提供高效的运行时性能,并且使得代码更易于维护和扩展。
STL 主要包含以下三个组件:
- 容器(Containers):容器是用于存储数据的数据结构,如向量(vector)、链表(list)、队列(queue)、映射(map)等。容器提供了一种统一的接口来操作数据,使得开发者可以方便地对数据进行增删改查操作。
- 算法(Algorithms):算法是用于对数据进行各种操作和处理的函数模板,如排序、查找、遍历等。STL 提供了丰富的算法,开发者可以直接调用这些算法来实现常见的操作,而无需自己实现复杂的算法。
- 迭代器(Iterators):迭代器是用于遍历容器中元素的对象,类似于指针。迭代器提供了一种统一的方式来访问容器中的元素,使得开发者可以不依赖于具体的容器实现,而只关注元素的访问和操作。
STL 是 C++ 标准库的核心组件之一,它广泛应用于 C++ 编程中,为开发者提供了强大的工具来处理数据和实现算法。STL 的使用不仅提高了代码的效率和可读性,而且使得 C++ 程序更易于维护和扩展
5. STL的版本
原始版本
Alexander Stepanov、Meng Lee 在惠普实验室完成的原始版本,本着开源精神,他们声明允许任何人任意运用、拷贝、修改、传播、商业使用这些代码,无需付费。唯一的条件就是也需要向原始版本一样做开源使用。 HP 版本–所有STL实现版本的始祖。
P. J. 版本
由P. J. Plauger开发,继承自HP版本,被Windows Visual C++采用,不能公开或修改,缺陷:可读性比较低,符号命名比较怪异。
RW版本
由Rouge Wage公司开发,继承自HP版本,被C+ + Builder 采用,不能公开或修改,可读性一般。
SGI版本
由Silicon Graphics Computer Systems,Inc公司开发,继承自HP版 本。被GCC(Linux)采用,可移植性好,可公开、修改甚至贩卖,从命名风格和编程 风格上看,阅读性非常高。作者学习STL要阅读部分源代码,主要参考的就是这个版本。
6. STL的六大组件

STL(C++ 标准模板库)由六大组件组成,每个组件都有其特定的功能和用途。这些组件是:
- 容器(Containers):容器是用于存储和管理数据的数据结构。STL 提供了多种容器,包括:
向量(vector):动态数组,支持随机访问和尾部插入、删除。
链表(list):双向链表,支持高效的插入和删除操作。
集合(set):有序不重复元素的集合,支持插入、删除和查找操作。
映射(map):键-值对的映射表,支持根据键进行查找、插入和删除操作。
栈(stack):后进先出(LIFO)的数据结构,支持压入和弹出操作。
队列(queue):先进先出(FIFO)的数据结构,支持入队和出队操作。
- 算法(Algorithms):算法组件提供了一组通用的算法,用于处理容器中的数据。这些算法包括:
排序(sort):对容器中的元素进行排序。
查找(find):在容器中查找特定元素。
遍历(for_each):对容器中的每个元素执行相同的操作。
汇总(accumulate):对容器中的元素进行求和或者其他汇总操作。
删除(remove):从容器中删除特定元素。
归并(merge):合并两个有序容器。
-
迭代器(Iterators):迭代器用于遍历容器中的元素。它提供了一种统一的接口,使得开发者可以不依赖于具体的容器实现,而只关注元素的访问和操作。迭代器分为输入迭代器、输出迭代器、前向迭代器、双向迭代器和随机访问迭代器等不同的类型,支持不同程度的元素遍历。
-
仿函数(Functors):仿函数是一种行为类似函数的对象,也称为函数对象。STL 中的算法通常可以接受仿函数作为参数,用于定义算法的具体操作。例如,STL 中的排序算法可以接受一个比较函数作为参数,以指定元素的排序规则。
-
配置器(Allocators):配置器用于控制容器在内存中分配和释放内存的方式。STL 允许开发者自定义配置器,以满足特定的内存管理需求。
-
适配器(Adapters):适配器是用于将容器和算法之间的接口进行适配的工具。例如,STL 提供了栈适配器(stack adapter)和队列适配器(queue adapter),用于将容器的接口转换为栈和队列的接口。
这六大组件共同构成了 C++ 标准模板库,它们相互配合,使得 C++ 开发者能够更轻松地编写高质量的代码,并提供了丰富的功能和灵活性,使得 C++ 程序更易于维护和扩展。
7.STL的重要性
STL(C++ 标准模板库)在笔试面试和工作中具有重要的地位和价值。以下是其在这两个方面的重要性:
在笔试面试中的重要性:
- 基础知识考察:STL 是 C++ 标准库的核心组成部分,面试官通常会考察面试者对 STL 容器、算法、迭代器等的理解和应用能力。熟练掌握 STL 的使用将有助于应对笔试和面试中的相关问题。
- 代码简洁性:STL 提供了一组通用的容器和算法,使得开发者能够用简洁高效的方式处理常见的数据结构和算法问题。在笔试面试中,展示熟练使用 STL 可以展现出代码简洁性和高效性。
- 抽象思维:STL 是泛型编程的典型代表,使用模板类和函数实现通用的代码。对于面试者来说,理解和应用 STL 可以展示出抽象思维和灵活的编程能力。
在工作中的重要性:
- 提高开发效率:STL 提供了一套丰富的数据结构和算法,使得开发者能够快速实现常见的功能,而无需从头编写代码。这将大大提高开发效率,减少代码量和开发周期。
- 代码质量和可维护性:STL 的代码经过广泛的测试和优化,是高质量和可靠的。使用 STL 可以减少手动编写代码导致的错误,并提高代码的可维护性。
- 标准化和通用性:STL 是 C++ 标准库的一部分,因此它在不同平台和编译器上都具有通用性。使用 STL 编写的代码可以更容易地在不同环境下移植和复用。
- 资源共享:STL 是广泛使用的编程工具,许多 C++ 开发者都熟悉和使用它。在工作中,使用 STL 可以方便团队之间的代码共享和合作开发。
总体而言,STL 在笔试面试和工作中都具有重要的地位。掌握和熟练使用 STL 可以提高编程能力,提高开发效率,同时也是在 C++ 开发中的一项基本技能。对于 C++ 开发者来说,学习和应用 STL 是必不可少的。
8.如何更好地学习STL
学习STL是C++开发中非常重要的一步,以下是一些建议,可以帮助你更好地学习STL:
- 熟悉STL的组件:了解STL的主要组件,包括容器(Containers)、算法(Algorithms)、迭代器(Iterators)、仿函数(Functors)、配置器(Allocators)和适配器(Adapters)。明确每个组件的作用和用法是学习STL的基础。
- 阅读官方文档:C++标准库有详细的官方文档,您可以查阅C++的官方文档或者其他权威的STL参考资料。官方文档会提供每个STL组件的详细说明、使用示例以及注意事项。
- 编写示例代码:通过编写简单的示例代码来熟悉STL的使用。尝试使用各种容器和算法,比如向量、链表、排序、查找等,从而加深对STL的理解。
- 阅读源代码:可以通过阅读STL的源代码来深入了解其内部实现。尽管STL的实现可能比较复杂,但通过阅读源代码,您可以学习到STL的一些设计思想和优化技巧。
- 解决实际问题:将STL应用于实际项目中,解决一些实际的问题。通过实践中的应用,可以更好地理解STL的实际用途和优势。
- 学习STL高级特性:一旦熟悉了基本的STL用法,可以进一步学习STL的一些高级特性,比如自定义仿函数、自定义容器和配置器等。
- 学习其他人的经验:参与C++社区的讨论,阅读其他人的STL使用经验和技巧,也是学习STL的一种有效途径。
- 练习和复习:学习STL需要持续的练习和复习。保持每天都进行一些STL的学习和练习,有助于更深入地掌握这个重要的C++库。
记住,学习STL可能需要一定的时间和实践,但是掌握STL将使您成为更高效和熟练的C++开发者。逐步积累经验和应用,你会发现STL是一个非常强大和有用的工具,能够极大地提升您的编程效率和质量。

9.STL的缺陷
虽然STL(C++标准模板库)是一个非常强大且广泛使用的工具,但它也有一些缺陷和局限性。以下是STL的一些缺陷:
- 学习曲线较陡:STL使用泛型编程和模板类来实现通用性,这可能导致初学者在学习过程中面临一定的困难。理解模板类和函数的工作原理需要对C++的泛型编程有一定的了解。
- 编译时间较长:由于STL使用了模板类和函数,编译器需要在实例化模板时生成对应的代码,这可能导致编译时间变长。
- 内存占用较大:STL的某些容器可能对内存使用较多。例如,STL的向量(vector)使用动态数组,可能在实际使用时占用更多的内存空间。
- 性能问题:尽管STL的算法和容器经过了优化,但在某些情况下,手动实现特定的算法或容器可能会更高效。STL的通用性有时会导致性能上的一些损失。
- 不适合特定领域:对于某些特定领域,STL可能不是最佳选择。例如,在实时系统或低内存设备中,STL的通用性和一些额外开销可能不适用。
- 可移植性问题:虽然STL是C++的标准库,但在不同的编译器和平台上,STL的实现可能有所不同,这可能会导致一些可移植性问题。
- STL库的更新太慢了。这个得严重吐槽,上一版靠谱是C++98,中间的C++03基本一些修订。C++11出来已经相隔了13年,STL才进一步更新。
- STL现在都没有支持线程安全。并发环境下需要我们自己加锁。且锁的粒度是比较大的。
尽管STL存在一些缺陷,但它在大多数情况下仍然是一个非常有用的工具。使用STL可以加快开发速度,提高代码质量,并且在许多情况下,STL的性能和内存使用是可以接受的。对于C++开发者来说,熟练掌握STL是一项非常重要的技能。同时,了解STL的缺陷和局限性也有助于开发者在实际项目中做出更合适的选择。
结语
有兴趣的小伙伴可以关注作者,如果觉得内容不错,请给个一键三连吧,蟹蟹你哟!!!
制作不易,如有不正之处敬请指出
感谢大家的来访,UU们的观看是我坚持下去的动力
在时间的催化剂下,让我们彼此都成为更优秀的人吧!!!
