参考资料:
AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE [论文链接]
[论文源代码]
1. 研究动机(Motivation)
作者成文时,学界有一种约定俗成的做法,即用CNN(卷积)来处理图片数据,使用Transformer来处理语言数据。这里读者不妨思考一下为什么会出现这种习惯,下面是我的理解。CNN的优越在于卷积核的设计,它兼具有多尺度感受野和权值共享的功能,使得多层CNN能够高效地提取出一个图片的视觉特征。Transformer的成功在于Self-Atten这个宛如神助的设计结构,它使得人工神经网络对于序列数据的处理彻底摒弃了循环神经网络(LSTM,RNN)的串行性(这里尤指编码侧,解码侧还是有很多成功的自回归设计)。
因此作者自然而然的想到,能否针对图片这种数据结构设计一个利用Transformer的网络来提取图片的特征?ViT应运而生!
2. 挑战(Chanllenge)
开创性的网络结构,想出网络架构就是最大的挑战。
3. 点子(Idea)
Transformer这个结构本质上是用于处理序列数据的,其输入是token的序列,那么在图片中,这个token要如何去找呢?作者给出了点子,即把图片分割成16×16的image patchs,每个image patch展平使用MLP提取一个特征向量。这些特征向量再和Positional Embedding拼到一起,就构成了Transformer(Encoder)结构的输入:tokens!
4. 方法(Method)
模型架构图如下所示:
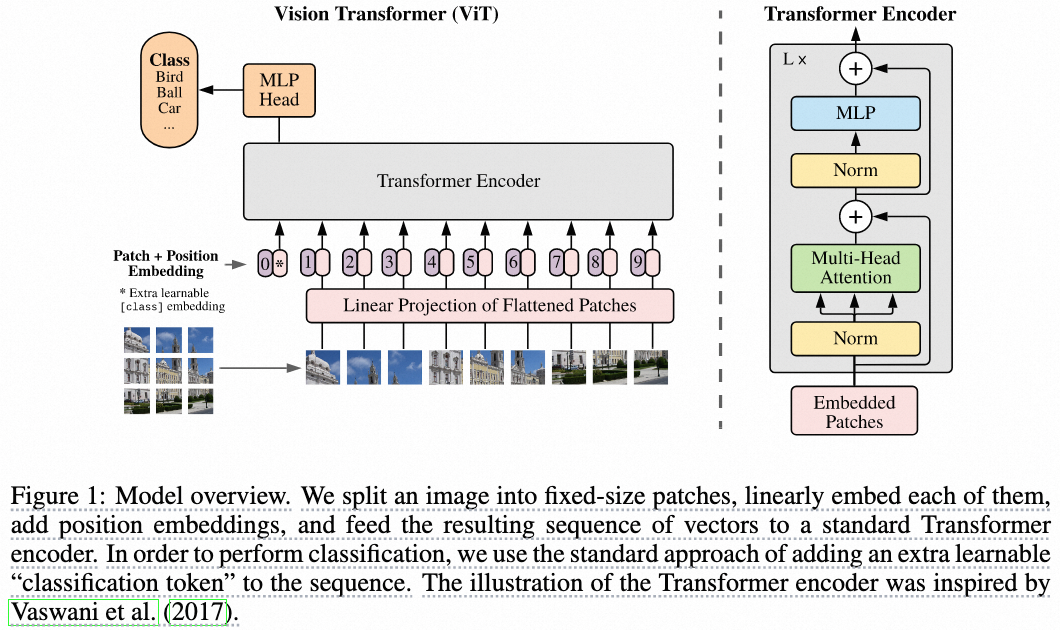
看到这个网络图我想用三个词来描述:简洁,直观和合理,模型结构一目了然。
1)首先将图片分片,然后分别提取一个特征向量。
2)与[CLASS] token拼在一起后喂给串联的Transformer Encoder Layer。
3)经过最后一层Transformer Encoder Layer之后,[CLASS] token对应的特征,作为图片的表征。
4)接上预测头完成分类任务。
关于方法我再提两个需要注意的点,一个是这个[CLASS] token,它的来由实际上是bert,位于句首。实际上不用[CLASS] token对应的特征行不行?我直接用一个pooling操作好像也能获取对于这个图片的一个表征(?),以及这个[CLASS] token对应的embedding是一个可学习的参数~
第二点是,文章中提出的Transformer实际上也只是Transformer Encoder,这个和Bert是一样的。Transformer原文中是有一个encoder和一个decoder的,这里只用到了Encoder来提取图片表征,需要注意!毕竟如果加上Encoder的描述,ViTE,显然不太优雅。
4. 结果(Result)
1)在数据量较少的情况下,未能超过ResNet这些SOTA结构
2)在数据量很多的情况下,超过了SOTA模型(CNN-based)
上述效果对比应该都是在分类,也就是识别任务上。
具体结果图就不放了,ViT在CLIP等其他需要提取视觉特征的模型上大放异彩,已经充分证明了它的高效性。