基于GCS等待事件的优化
gv$session_wait
SELECT inst_id,
event,
p1 FILE_NUMBER,
p2 BLOCK_NUMBER,
WAIT_TIME
FROM gv$session_wait
WHERE event = 'global cache busy';
在RAC里面不是v$session_wait,而是多了一个g,也就是说这是一个全局的,是在RAC上面的多个实例上面查询。通过这个视图可以将所有实例上面的信息查到。如果没有这个g查询到的就是当前连接到的实例的一些信息。
p1是等待数据块所在的文件号。P2是等待的数据块块号。

可以看到结果,两个实例上面都有这个等待事件,这个等待事件存在于文件9,数据块块号是150号。
定位对象
SELECT owner,
segment_name,
segment_type
FROM dba_extents
WHERE file_id = 9
AND 150 between block_id AND block_id+blocks-1;
OWNER SEGMENT_NAME SEGMENT_TYPE
---------- ---------------------------- ---------------
TEST TEST_IND INDEX
可以看到,两个实例都频繁访问到这个索引,正常情况下这些都很正常。
正常情况下等待事件很正常,当用户说系统有问题,这个时候再来处理,如果定位在上面的问题上面,这个时候就要处理了。
减少多个实例访问一个数据块
修改对象,以避免数据块的争用(热块)
•减少每个数据块的行数
•减少数据块的大小
•修改数据块头INITRANS 和 FREELISTS
现在问题就是上面,大量的用户访问索引,而且访问的是相同数据块的索引,比如说一个数据块上面有10个索引键值,大量用户访问这一个数据块,如果可以将这10个键值分到多个数据块上面那么就可以避免对单个数据块的访问过多。
在oracle里面访问的最小单位是数据块,不是行,比如一个数据块特别大32K,那么访问一行都要读取32K的数据块,这样的代价是很大的。为了使得访问的记录在多个数据块里面,一个办法是减小数据块的行数,另外一个就是减小数据块的大小。通过这样,不同用户请求的数据块的时候请求相同数据块的几率就会减小。
在RAC下还有可以使用下面的语句来查看等待事件
-----rac环境:
select t.inst_id,t.EVENT,count(1) from gv$session_wait t
where t.wait_class != 'Idle'
group by t.inst_id,t.EVENT
having count(1)>5
order by 1,count(1) desc;
基于GCS等待事件的优化
一致性读的GCS的性能指标:

当一个实例去请求另外一个实例的时候会发生上面的事情。上面五个指标构成了一致性读所有的环节。
SELECT a.inst_id "Instance",
(a.value+b.value+c.value+d.value)/decode(e.value,0,1, d.value) "BSP
Service Time"
FROM gv$sysstat A,
gv$sysstat B,
gv$sysstat C,
gv$sysstat D,
gv$sysstat E
WHERE A.name = 'global cache cr block serve time'
AND B.name = 'global cache cr block send time'
AND C.name = 'global cache cr block log flush time'
AND D.name = 'global cache cr block receive time'
AND E.name = 'global cache cr blocks served'
AND B.inst_id = A.inst_id
AND C.inst_id = A.inst_id
AND D.inst_id = A.inst_id
AND E.inst_id = A.inst_id
ORDER
BY a.inst_id;
在一个RAC下面,数据块在一致性读的模式下面,一个块从一个实例读取到另外一个实例需要花费的时间。上面计算的值是平均到每一个数据块上面。
– 结果:
Instance BSP Service Time
--------- ----------------
1 1.07933923
2 .636687318
可以看到,对于实例1来说时间是1,对于实例2来说时间是0.6,这个0.6是是实例1提供给实例2一致性读的时间,也就是实例1只花了0.6秒提供给实例2一致性读。所以上面是交叉的,也就是其实实例1处理数据快一些。提供上面的值可以相对的比较两个节点相应的值。
基于GCS等待事件的优化
– 进一步查询,可以看到更深入的信息
SELECT A.inst_id "Instance", (A.value/D.value) "Consistent Read Build",
(B.value/D.value) "Log Flush Wait",(C.value/D.value) "Send Time”
FROM GV$SYSSTAT A, GV$SYSSTAT B,
GV$SYSSTAT C, GV$SYSSTAT D
WHERE A.name = 'global cache cr block build time'
AND B.name = 'global cache cr block flush time'
AND C.name = 'global cache cr block send time'
AND D.name = 'global cache cr blocks served'
AND B.inst_id=a.inst_id
AND C.inst_id=a.inst_id
AND D.inst_id=a.inst_id
ORDER BY A.inst_id;
Instance Consistent Read Build Log Flush Wait Send Time
--------- --------------------- -------------- ----------
1 .00737234 1.05059755 .02203942
2 .04645529 .51214820 .07844674
这个是每个数据块每一个阶段花费的时间。
基于GCS等待事件的优化
– 涉及到Interconnect 性能的指标:
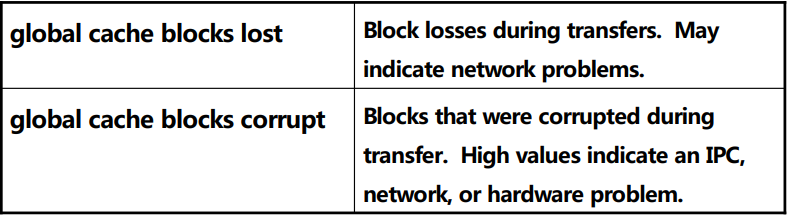
SELECT A.VALUE "GC BLOCKS LOST 1",
B.VALUE "GC BLOCKS CORRUPT 1",
C.VALUE "GC BLOCKS LOST 2",
D.VALUE "GC BLOCKS CORRUPT 2"
FROM GV$SYSSTAT A, GV$SYSSTAT B, GV$SYSSTAT C, GV$SYSSTAT D
WHERE A.INST_ID=1 AND A.NAME='gc blocks lost'
AND B.INST_ID=1 AND B.NAME='gc blocks corrupt'
AND C.INST_ID=2 AND C.NAME='gc blocks lost'
AND D.INST_ID=2 AND D.NAME='gc blocks corrupt'
GC BLOCKS LOST 1 GC BLOCKS CORRUPT 1 GC BLOCKS LOST 2 GC BLOCKS CORRUPT 2
---------------- ------------------- ---------------- -------------------
0 0 652 0
可以看出丢数据块丢掉厉害,该实例的网卡出现了问题。
interconnect的优化
用操作系统层面的命令,看一下interconnect连接是否有问题:
– netstat
– ifconfig
interconnect 有一个专有的私网
interconnect 没有通过public 网络进行数据传输