深度学习的发展对个科学领域产生了深远的影响。它不仅在自然语言处理(NLP)和计算机视觉(CV)等人工智能领域显示出显著的价值,而且在电子商务、智慧城市和药物发现等更广泛的应用领域也取得了巨大的成功。随着卷积神经网络(CNN)、递归神经网络(RNN)、长-短期记忆(LSTM)和生成对抗网络(GAN)等多种深度学习模型的出现,简化各种DL模型的编程以实现其广泛采用至关重要。
在工业界和学术界的不断努力下,一些流行的DL框架被提出,如TensorFlow、PyTorch、MXNet和CNTK,以简化各种DL模型的实现。尽管上述DL框架根据其设计中的权衡有其优点和缺点,但是在跨现有DL模型支持新兴DL模型时,互操作性对于减少冗余工程工作变得非常重要。为了提供互操作性,ONNX被提出,它定义了表示DL模型的统一格式,以便于不同DL框架之间的模型转换。
为了解决DL库和工具的缺点,减轻手动优化每个DL硬件上的DL模型的负担,DL社区正在促进特定领域的编译器的发展。目前工业界和学术界已经提出了几种流行的DL编译器,如TVM、Tensor Comprehension、Glow、nGraph和XLA。DL编译器将DL框架中描述的模型定义作为输入,并在各种DL硬件上生成有效的代码实现作为输出。针对模型规范和硬件架构,对模型定义和具体代码实现之间的转换进行了高度优化。具体来说,它们结合了面向DL的优化,例如层和运算操作符融合(比如Conv+BatchNorm),这使得代码生成效率更高。此外,现有的DL编译器还利用了来自通用编译器(例如LLVM)的成熟工具链,这在不同的硬件架构中提供了更好的可移植性。与传统编译器类似,DL编译器也采用了前端、中间代码和后端的分层设计。然而,DL编译器的独特性在于多层次IRs和DL特定优化的设计。
- 深度学习框架

图1.深度学习框架
图1展示了DL框架的前景,包括当前流行的框架、历史框架和ONNX支持的框架。
TensorFlow:在所有DL框架中,TensorFlow对语言接口的支持最全面,包括C++、Python、Java、Go、R和Haskell。为了降低使用TensorFlow的复杂性,Google采用Keras作为TensorFlow核心的前端。
Keras:一个高级神经网络库,用于快速构建DL模型,用纯Python编写。尽管Keras本身不是DL框架,但它提供了一个与TensorFlow、MXNet、Theano和CNTK集成的高级API。使用Keras,DL开发人员只需几行代码就可以构建一个神经网络。然而,Keras由于过度封装而不够灵活,这使得添加操作符或获取低级数据信息非常困难。
PyTorch:Facebook用Python重写了基于Lua的DL框架Torch,并在Tensor级别上重构了所有模块,从而发布了PyTorch。作为最流行的动态框架,PyTorch在Python中嵌入了用于构建动态数据流图的原语,其中控制流在Python解释器中执行。PyTorch 1.0集成了PyTorch 0.4和Caffe2的代码库,创建了一个统一的框架。这使得PyTorch能够吸收Caffe2的优点,以支持高效的图形执行和移动部署。
Caffe/Caffe2:Caffe是加州大学伯克利分校为深度学习和图像分类而设计的。Caffe有命令行、Python和matlab的api。Caffe的简单性使得源代码易于扩展,适合开发人员深入分析。因此,Caffe主要定位于研究,这使得它从一开始就流行至今。Caffe2是建立在原来的Caffe项目上的。Caffe2在代码结构上类似于TensorFlow,尽管它的API更轻,并且更容易访问计算图中的中间结果。
MXNET:MXNET支持多种语言API,包括Python、C++、R、Julia、Matlab和JavaScript。它旨在实现可扩展性,并从减少数据加载和I/O复杂性的角度进行设计。MXNet提供了不同的范例:像caffe和Tensorflow这样的声明式编程以及像PyTorch这样的命令式编程。 CNTK:可以通过Python和C++的API来使用,或者可以使用自己的脚本语言(即脑力脚本)。CNTK的设计易于使用和生产,为生产中的大规模数据做好了准备。它使用类似于TensorFlow和Caffe的静态计算图,其中DL模型通过有向图被视为一系列计算步骤。
Paddle-Paddle:原始设计类似于Caffe,每个模型可以表示为一组层。然而,Paddle-Paddlev2引用了TensorFlow的操作符概念,它将层分解为更细粒度的操作符,从而支持更复杂的DL模型。而paddle Fluid与PyTorch类似,因为它提供了自己的解释器,从而避免了Python解释器的有限性能。
ONNX:开放式神经网络交换(ONNX)定义了一个可伸缩的计算图模型,因此由不同DL框架构建的计算图可以很容易地转换成ONNX。使用ONNX,在DL框架之间转换模型变得更容易。例如,它允许开发人员构建MXNet模型,然后使用PyTorch运行模型进行推理。如图1所示,ONNX已经集成到PyTorch、MXNet、paddle等中。对于一些尚未直接支持的DL框架(例如TensorFlow和Keras),ONNX向它们添加了转换器。
已经淘汰的框架:由于DL社区的快速发展,许多历史DL框架不再活跃。例如,PyTorch已经取代了Torch。作为最古老的DL框架之一,Theano已经不再维护。Chainer曾经是动态计算图的首选框架,但是被具有类似特征的MXNet、PyTorch和TensorFlow所取代。
- 深度学习编译器架构设计
DL编译器的通用设计架构主要包含两部分:前端和后端,如图2所示。中间代码(IR)分布在前端和后端。通常,IR是程序的抽象,用于程序优化。具体地说,DL模型在DL编译器中被转换成多级IR,其中高层IR驻留在前端,而底层IR驻留在后端。编译器前端基于高层IR,负责与硬件无关的转换和优化。基于底层IR,编译器后端负责特定于硬件的优化、代码生成和编译。
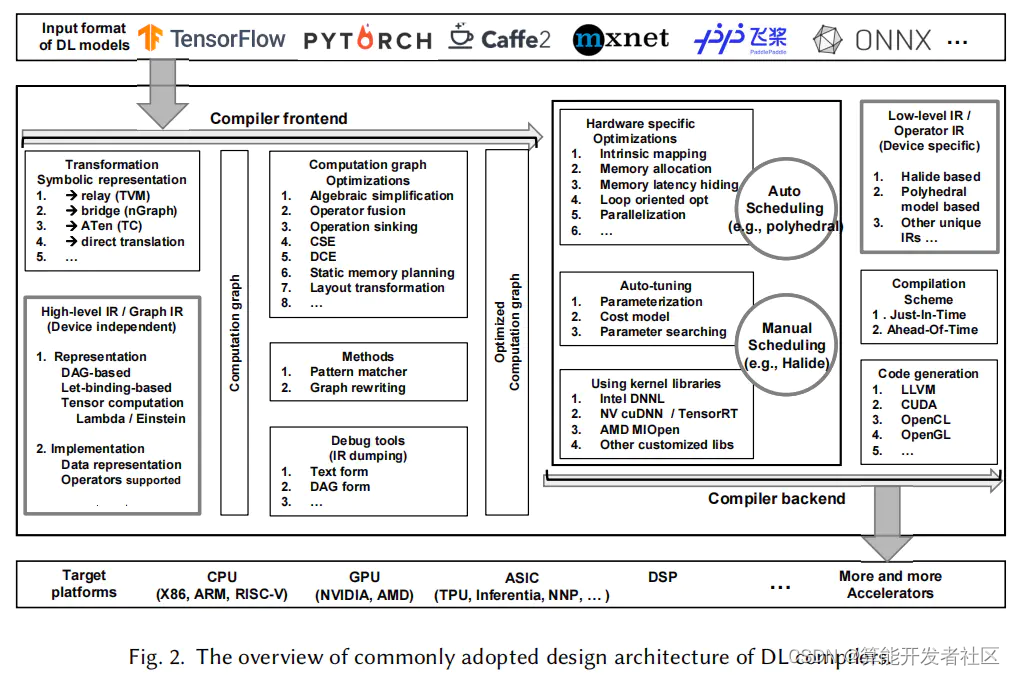
图2.一般采用的DL编译器设计体系结构概述
高层IR:也称为图IR,表示计算和控制流,与硬件无关。高层IR的设计挑战是计算和控制流的抽象能力,它可以捕获和表示各种DL模型。高层IR的目标是建立控制流以及操作符和数据之间的依赖关系,并为图级优化提供接口。它还包含用于编译的丰富语义信息,并为自定义操作符提供可扩展性。
低层IR:设计用于针对不同硬件目标的特定硬件优化和代码生成。因此,底层IR应该足够细粒度,以反映硬件特性并表示特定于硬件的优化。它还应该允许在编译器后端使用成熟的第三方工具链,如 Halide, polyhedral和LLVM。
前端从现有的DL框架中获取一个DL模型作为输入,然后将该模型转换为计算图表示(如图IR)。前端需要实现各种格式转换,以支持不同框架中的不同格式。计算图优化结合了通用编译器的优化技术和DL特有的优化技术,减少了计算图的冗余,提高了计算效率。这种优化可分为节点级(例如nop消除和零维张量消除)、块级(例如代数简化、算子融合和算子下沉)和数据流级(例如CSE、DCE、静态内存规划和布局转换)。在前端之后,生成优化的计算图并传递给后端。
后端将高层IR转换为底层IR,并执行特定于硬件的优化。一方面,它可以直接将高层IR转换为第三方工具链(如LLVM IR),以利用现有的基础设施进行通用优化和代码生成。另一方面,它可以利用DL模型和硬件特性的先验知识,通过定制的编译过程更有效地生成代码。常用的硬件优化包括硬件内部映射、内存分配和获取、内存延迟隐藏、并行化以及面向循环的优化。为了在较大的优化空间中确定最优参数设置,现有的DL编译器普遍采用两种方法:自动调度(如polyhedral)和自动调整(如AutoTVM)。