线性表--顺序表 C语言实现
从顺序表开始探索数据结构的魅力
顺序表作为线性表中的一类,可以说是数据结构中最简单的、最基础的一种结构。很多书籍都以此作为开篇,来讲述数据结构的魅力。作为数据结构的开篇,有必要好好学习这一内容,这样才能养成良好的数据结构思维习惯。数据结构从本质上讲,就是定义一种性质,并且在后续的操作中维护这一性质,从而达到特定的目的。
数组杂谈
顺序表实际上可以看作一个“高级”的数组,这是因为数组的性质正好满足顺序表的定义,因而在讨论顺序表前,我们先来看看数组的使用和它的不足。
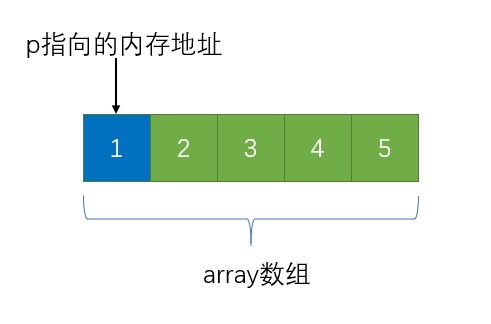
数组名和指向数组头的指针
数组名和指向数组头的指针很多时候是可以混为一谈的,但严谨的讲,两者是不同的。
我们来看一个代码:
#include <stdio.h>
int main() {
int array[] = {
1,2,3,4,5};
int *p = array;
printf("sizeof(array) = %d\n",sizeof(array));
printf("sizeof(p) = %d\n",sizeof(p));
return 0;
}
在64位机下输出的结果是:
sizeof(array) = 20
sizeof(p)= 8
可以看出,数组名指的是整个数组,其中包含着一个数组占用内存了多少内存,我们可以通过数组名,获取数组中拥有多少个元素。而指向数组头的指针,本质是一个指针变量,它所占的字节数是固定的。
遍历整个数组
如果只是在数组定义的作用域中,遍历数组是十分简单的,只需要一个数组名即可。
#include <stdio.h>
int main() {
int array[] = {
1,2,3,4,5};
int size = sizeof(array) / sizeof(int);
for (int i = 0; i < size;i++) {
printf("%d ",array[i]);
}
printf("\n");
return 0;
}
但想要跨作用域来实现相同的功能,往往会利用到函数,结合传递参数来实现。但C语言中,我们传递的是一个数组名,但编译器会把它变成一个地址进行传递,从而丢失了数组的长度信息。因此下面的做法明显是错误的:
#include <stdio.h>
void order(int array[]) {
int size = sizeof(array) / sizeof(int);
for (int i = 0; i < size;i++) {
printf("%d ",array[i]);
}
printf("\n");
}
int main() {
int array[] = {
1,2,3,4,5};
order(array);
return 0;
}
而为了避免这样的错误,常见的做法,是把数组的长度作为参数,传递给函数。如下:
#include <stdio.h>
void order(int array[],int size) {
for (int i = 0; i < size;i++) {
printf("%d ",array[i]);
}
printf("\n");
}
int main() {
int array[] = {
1,2,3,4,5};
int size = sizeof(array) / sizeof(int);
order(array,size);
return 0;
}
从这里我们已经能发现数组的第一个短板了:数组的长度信息会在传参中丢失
数组下标越界访问
数组的下标越界是一种很常见的错误。在C语言规范中,这属于一种未定义行为。各个编译器对其进行的处理各不相同。但有一点是明确的,这样的操作是很危险的。
#include <stdio.h>
#define SIZE 5
int main() {
int array[SIZE] = {
1,2,3,4,5};
for (int i = 0;i < SIZE + 1;i++) {
printf("%d ",array[i]);
}
printf("\n");
return 0;
}
上面的代码,可以很容易看出,当遍历执行到最后一次,访问的位置是array[5],这明显是下标越界了,我们并不清楚这一块内存中的数值具体是多少。但这个问题在编译期间是不会被发现的,甚至在运行时也很难察觉,因此数组的第二个不足也呼之欲出:数组下标的越界访问是未定义行为,我们无法对其进行有效的防护。
数组中存在无效数据
很多时候,我们为了图省力,一口气开辟一个很大的数组,但实际运行中,只有其中的一部分被使用了(我们假设用的时候一定是从前往后使用的),那么访问没被使用的数组空间同样是一件危险的事。这实际是编程技巧带来的隐患。
打个比方:假设我们要按天记录今年的收入,我们理所当然的会以年作单位,直接拿出一个大本子进行记录,假设今天是4月1号,这时我想查阅5月1号的收入,这时我们能在账单上找到这个日子对应的账单,但我们并没有记录到这一天,所有查阅是可以的,但里面的信息是无效的。
数组存在的问题
通过前面的三个例子。我们已经得出了普通数组存在的缺陷了,主要有两点:
- 数组的长度信息会在传参中丢失
- 数组下标的越界访问是未定义行为,我们无法对其进行有效的防护
还有一个是编程技巧带来的隐患:
- 数组中有些数据是无效的
解决数组存在的不足
既然明确的知道了数组存在的不足,我们就可以对症下药,逐个解决它们。
解决前两个问题的方式前面就提到了,就是增加一个size字段,这样不仅能知晓数组的长度,也能避免下标越界。
而由编程技巧带来的隐患,可以通过增加一个length字段解决。这个字段记录数组前length个数据是有效的,超过length的部分对我们而言是无效数据。
根据上面的分析,我们就可以着手写代码了:
#include <stdio.h>
#define SIZE 100
int main() {
int array[SIZE] = {
0};
int size = sizeof(array) / sizeof(int); //记录array的长度
int length = 0; //记录array中有效数据的个数
return 0;
}
通过对size、length字段的使用,我们可以让数组的操作更加安全,也弥补了数组的先天不足。
至此,实际上我们已经完成了顺序表的结构定义。顺序表其实就是通过数组增加两个字段,达到了比数组更加安全、可靠的目的。
线性表–顺序表
这里有必要理清一下线性表和顺序表之间的关系。
线性表是逻辑结构层面的概念,指的是元素间的关系是一对一的。
顺序表是物理结构层面的概念,指的是元素存储在一段连续的内存空间中,而数组正好就有这样的性质。
线性表的定义:
线性表(linear list)也被成为有序表(ordered list),它的每一个实例都是元素的一个有序集合。每一个实例的形式为 ( e 0 , e 1 , e 2 , . . . e n − 1 ) (e_0,e_1,e_2,...e_{n-1}) (e0,e1,e2,...en−1)
其中n是有穷自然数, e i e_i ei是线性表的元素,i是元素 e i e_i ei的索引,n是线性表的长度。
可知索引是从0开始的,到n-1结束。
顺序表的结构定义
顺序表实际上就是用一段连续的内存空间实现的线性表,而数组就是不二的选择。其实前面在分析数组的时候,我们就已经把顺序表的结构定义描述出来了,我们将其封装成一个结构体,方便后续操作。
typedef struct SequentialList{
int *array; //数组
int size; //记录数组的长度
int length; //记录array中有效数据的个数
}SequentialList;
顺序表的相关操作
顺序表的基本操作有:
- 创建顺序表
- 销毁顺序表
- 判空操作
- 按一个给定索引查找一个元素
- 按一个给定索引插入一个元素
- 按一个给定索引删除一个元素
- 遍历输出顺序表中的全部元素
等等。接下来我们逐一来实现。
创建和销毁顺序表
因为C语言是没有GC机制的,因而这两个操作往往是成对出现的,我们就一起实现了。
创建顺序表
在创建之前,我们需要清楚的知道,我们需要初始化哪些量,及它们的值各为多少。
不难想到,数组的长度是可以自定义的,我们需要通过传参来控制,并且需要为其开辟相应的内存空间。size字段记录的就是数组长度,也可以确定。而初始化后的顺序表,其有效的元素个数为0,length的值也就确定了。
SequentialList *createSequentialList(int _size) {
SequentialList *sl = (SequentialList*)malloc(sizeof(SequentialList));
sl->array = (int*)malloc(sizeof(int) * _size);
sl->size = _size;
sl->length = 0;
return sl;
}
销毁顺序表
销毁的操作很简单,就是回收堆上的内存,防止内存泄漏。
void destroySequentialList(SequentialList *sl) {
if (sl == NULL) return;
free(sl->array); //回收数组所占内存
free(sl); //回收顺序表对象的内存
return;
}
判空操作
判空操作实际上是一个辅助操作,我们只要知道现在的有效数据个数是不是0,就可以判断了。
int is_empty(SequentialList *sl) {
if (sl == NULL) return -1;
return sl->length == 0;
}
按一个给定索引查找一个元素
之间根据下标返回元素即可,但需要注意数据索引的有效范围应当是0到length - 1的。
int getElement(SequentialList *sl,int index) {
if (sl == NULL) return -1;
if (index < 0 || index > sl->length) return -1;
return sl->array[index];
}
按一个给定索引插入一个元素
同样需要注意索引的合法取值,应为0到length(因为是插入,插入到末尾是合理的)。同时,插入操作,需要让索引后面的所有值,都依次向后一位,这样才有空的位置可供插入。而向后一位的顺序应当是最后一位开始移动的。
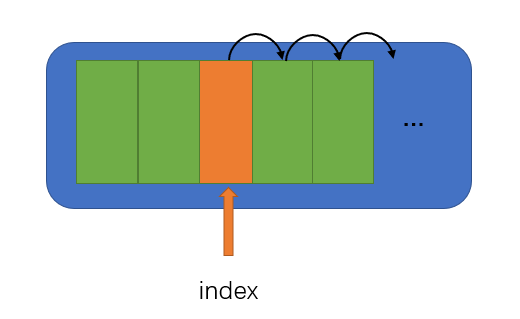
int insert(SequentialList *sl,int index,int element) {
if (sl == NULL) return 0;
if (index < 0 || index > sl->length) return 0;
if (sl->length == sl->size) return 0;
for (int i = sl->length;i > index; i--) {
sl->array[i] = sl->array[i - 1];
}
sl->array[index] = element;
sl->length++;
return 1;
}
按一个给定索引删除一个元素
技巧和插入差不多,不同的是,这次元素的移动方向是从索引的后一个元素开始,统一往前移动一位。
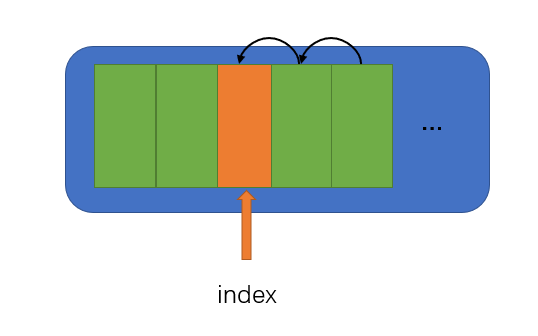
int erase(SequentialList *sl,int index) {
if (sl == NULL) return 0;
if (index < 0 || index > sl->length) return 0;
for (int i = index + 1; i < sl->length; i++) {
sl->array[i - 1] = sl->array[i];
}
sl->length--;
return 1;
}
遍历输出顺序表中的全部元素
void display(SequentialList *sl) {
if (sl == NULL) return;
if (is_empty(sl)) return;
for(int i = 0; i < sl->length; i++) {
printf("%d ",sl->array[i]);
}
printf("\n");
return;
}
顺序表的整体实现
#include <stdio.h>
#include <stdlib.h>
//顺序表结构定义
typedef struct SequentialList{
int *array; //数组
int size; //记录数组的长度
int length; //记录array中有效数据的个数
}SequentialList;
//创建顺序表
SequentialList *createSequentialList(int _size) {
SequentialList *sl = (SequentialList*)malloc(sizeof(SequentialList));
sl->array = (int*)malloc(sizeof(int) * _size);
sl->size = _size;
sl->length = 0;
return sl;
}
//销毁顺序表
void destroySequentialList(SequentialList *sl) {
if (sl == NULL) return;
free(sl->array); //回收数组所占内存
free(sl); //回收顺序表对象的内存
return;
}
//判空操作
int is_empty(SequentialList *sl) {
if (sl == NULL) return -1;
return sl->length == 0;
}
//按一个给定索引查找一个元素
int getElement(SequentialList *sl,int index) {
if (sl == NULL) return -1;
if (index < 0 || index > sl->length) return -1;
return sl->array[index];
}
//按一个给定索引插入一个元素
int insert(SequentialList *sl,int index,int element) {
if (sl == NULL) return 0;
if (index < 0 || index > sl->length) return 0;
if (sl->length == sl->size) return 0;
for (int i = sl->length;i > index; i--) {
sl->array[i] = sl->array[i - 1];
}
sl->array[index] = element;
sl->length++;
return 1;
}
//按一个给定索引删除一个元素
int erase(SequentialList *sl,int index) {
if (sl == NULL) return 0;
if (index < 0 || index > sl->length) return 0;
for (int i = index + 1; i < sl->length; i++) {
sl->array[i - 1] = sl->array[i];
}
sl->length--;
return 1;
}
//遍历输出顺序表中的全部元素
void display(SequentialList *sl) {
if (sl == NULL) return;
if (is_empty(sl)) return;
for(int i = 0; i < sl->length; i++) {
printf("%d ",sl->array[i]);
}
printf("\n");
return;
}
int main() {
SequentialList *sl = createSequentialList(100); //创建顺序表
for (int i = 0; i < 10; i++) {
if (!insert(sl,i,i)) //按一个给定索引插入一个元素
return -1; //插入失败
}
display(sl); //遍历输出顺序表中的全部元素
for (int i = 0;i < 5; i++) {
if (!erase(sl,0)) //按一个给定索引删除一个元素
return -1; //删除失败
}
display(sl); //遍历输出顺序表中的全部元素
for (int i = 0; i < sl->length; i++) {
printf("索引%d对应的数据为:%d\n",i,getElement(sl,i)); //按一个给定索引查找一个元素
}
destroySequentialList(sl); //销毁顺序表
return 0;
}
顺序表的优缺点
顺序表因为是由连续内存空间实现的,它的优缺点很明显
优点:查找操作快,之间下标索引,时间复杂度O(1)
缺点:插入、删除操作慢,需要遍历整个数组,时间复杂度O(n)
后记
C语言的数组存在的缺陷,在很多语言中其实已经被消除了。Java、C#等语言的数组本身就带有长度等信息。但这不影响我们的顺序表学习,数据结构归根结底学的是一种思维逻辑,一旦理解了某个结构存在的意义,以及其现实的用途,我们才能把它用到合适的地方中去,发挥它真正的作用。