目录
一. 前期准备
二. 跑case且分析覆盖率
三. 更换随机种子提高覆盖率
四. 再次分析覆盖率
五. 写定向激励去提高覆盖率
六. 覆盖率到100%
一. 前期准备
前期准备工作包括验证环境的搭建,定义功能覆盖率,准备makefile脚本。熟悉常用命令。
根据自定义的makefile脚本,主要用到三个命令:
| 任务 | 命令 |
| 跑一次case | make comp elab run COV=1 TESTNAME=... |
| 合并覆盖率 | make mergecov |
| 打开DVE分析覆盖率 | make dvecov |
| 用sh脚本跑case | source ... |
注意: makefile里面是否给随机种子+ntb_random_seed,必须加上随机种子,这样在多次跑相同case的时候才会产生不同的随机种子。
用sh脚本跑case需要提前准备一个sh脚本(方便一次跑多个case),在terminal下touch my_test1即可创建一个名为my_test1的文档,一般我习惯命名为my_test1,my_test2。在文档中将多条case和合并覆盖率和打开DVE分析的命令放在其中,随后在terminal中source my_test1则可自动执行下面指令。
一个sh脚本控制的文档

二. 跑case且分析覆盖率
跑一次冒烟测试


跑一次不同地址的测试


跑一次不同位宽的数据测试


字不对齐测试


复位测试


在跑完不同的case后,覆盖率增长如下表
| 测试 |
代码覆盖率 |
功能覆盖率 |
| 冒烟测试 |
71.34 |
20.07 |
| 不同地址 |
76.34 |
39.80 |
| 不同位宽 |
79.68 |
52.30 |
| 字不对齐测试 |
96.68 |
71.05 |
| 复位测试 |
96.78 |
71.05 |
字不对齐测试后,代码覆盖率增长比较快,主要是在这个case中首次将data的高16位赋值了,前面三个case的赋值主要在低16位,于是data高位的代码toggle覆盖到了。但是覆盖率没有达到100%,于是我们尝试更换随机种子重新跑。
三. 更换随机种子提高覆盖率
为了提高覆盖率,可以更换随机种子将中间三个case再跑四次(这里可以用到sh脚本),但是覆盖率提升并不大,代码覆盖率没变,功能覆盖率从71.05%提高到72.37%。

四. 再次分析覆盖率
于是我们分析查看哪些地方没有覆盖到,先分析代码覆盖率的toggle;

- 此时HWDATA和HRDATA在某些位置的toggle还没有覆盖,可以写定向激励去覆盖,依次发送HWDATA的值为32’h0000_0000,32’hFFFF_FFFF, 32’h0000_0000,实现各个bit位的0->1,1->0跳转;
- HREADY,HREADYOUT由于DUT的行为恒1,所以可以exclude掉;
- HRESP由于设计的DUT恒0,所以可以exclude掉;
- HSELBRAM可以给初值1,在复位任务中非阻塞赋值将其置0,随后释放的时候置1;
- HTRANS由于DUT不支持突发传输,所以并没有BUSY和SEQ状态,可以exclude掉;
然后分析功能覆盖率:

可以看到多次随机但仍然没有随机到addr_end,边界地址难以覆盖到,所以应该写一个定向激励去覆盖边界地址,同时发现非法地址没有覆盖,因为我们本身并没有写非法地址的激励,所以我们另外写一个seq,里面去覆盖这三个点。
注意:主要exclude掉的应该是设计的行为导致的必然不可能出现的情况。
五. 写定向激励去提高覆盖率
写定向激励去满足HWDATA和HRDATA的toggle。

写定向激励去满足功能覆盖率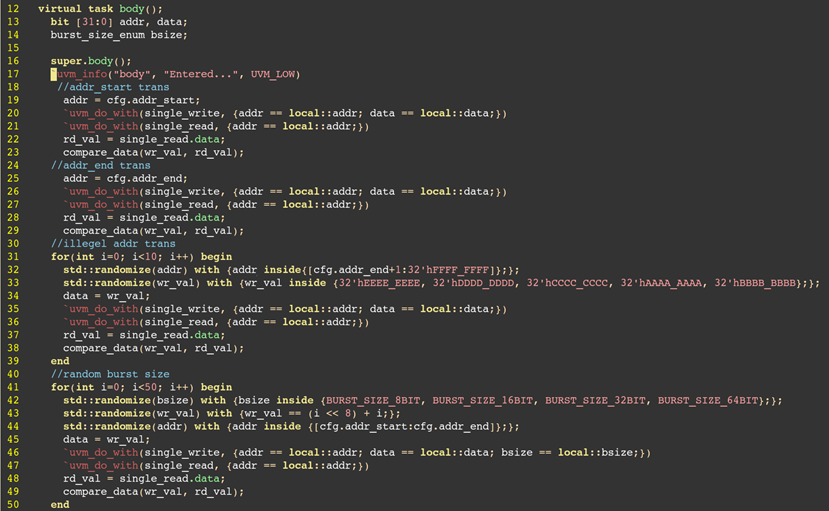
注意:新写seq,test,且两个sv文件都要放入到头文件svh里面,在test中挂载对应的seq。
六. 覆盖率到100%
将新写的两个test放到另一个文档里面my_test2。

在重新跑完定向的激励后,导入之前exclude的文件,最后发现功能覆盖率和代码覆盖率均达到100%
