random是numpy中超好用的随机数模块,在数据分析中,我们不可避免需要一些随机值,如果自己手动输入,不仅不方便,还不随机。现在我们来一起学习一下这个模块。
简单随机数
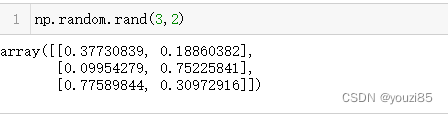
- rand(d0, d1, …, dn)
传入的参数是指定输出的矩阵的shape,数组的元素的取值范围是在[0,1)的左闭右开的浮点数。
np.random.rand(3,2)
每一次执行都能得到不同的值。
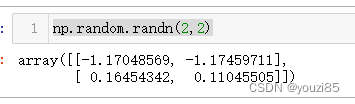
- randn(d0, d1, …, dn)
传入的参数是指定矩阵shape,不传默认返回一个随机值。返回的元素是来自标准正态分布(均值0和方差1)的浮点数。
np.random.randn(2,2)
- randint(low[, high, size, dtype])
返回[low,high)的“离散均匀”分布的随机整数,矩阵的形状由size指定。如果不给high的值,那么数值默认是从[0,low)取值。size可以是int或者int元祖,若是不给出,则默认返回一个随机值。
np.random.randint(3,size=3)
np.random.randint(3,7,size=(3,2))

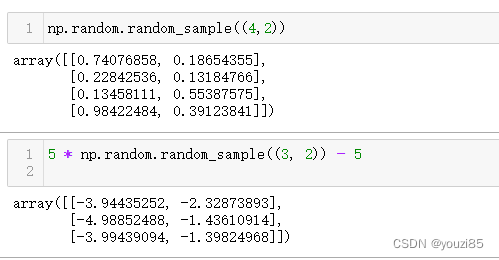
- random_sample([size])
返回一个在[0.0,1.0)左闭右开区间内连续均匀分布的随机浮点数。
和rand的区别是rand传入的维度是各个维度之间用逗号隔开,而random_sample的size则是传入一个元组。
np.random.random_sample((4,2))
5 * np.random.random_sample((3, 2)) - 5
- choice(a[, size, replace, p])
从给定的一位数组中生成随机样本。
其中还可以给定数组a中每个元素的相关概率,若是不给出,则默认所有元素都是在a中均匀分布的。
a = ['特等奖','一等奖','二等奖','三等奖','谢谢惠顾']
np.random.choice(a,(6,))
np.random.choice(a,(6,),p=[0.01,0.1,0.15,0.2,0.54])

注意:当出现以下情况,会报ValueError:
- a是一个数字,并且a小于0
- a或者p不是一维的
- a是一个空数组
- p不是概率向量
- a和p的长度不一致
- 当replace=False(默认是True)时,样本量(size指定的值)大于总体数量(a)大小
洗牌
- shuffle(x)
直接打乱该序列的内容,没有返回值。

(频数或频率的)分布
-
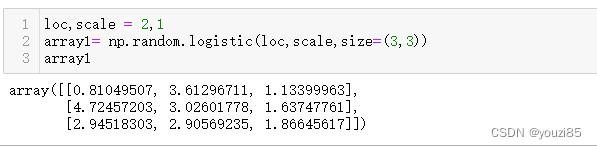
logistic([loc, scale, size])
从逻辑分布中抽取样本。
样本是从具有指定参数,loc(位置或均值,也为中位数)和scale(>0)的逻辑分布中抽取的。
逻辑分布的概率密度公式:

-
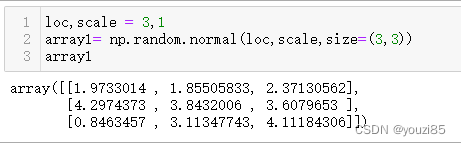
normal([loc, scale, size])
从正态(高斯)分布中抽取随机样本。默认均值是0.0,标准差是1.0。
正态分布概率密度:

-
standard_normal([size])
从标准正态分布中抽取随机样本,这个就是normal的一个默认值特例。

-
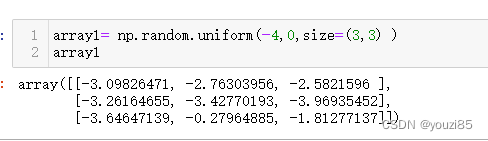
uniform([low, high, size])
从均匀分布中抽取样本。样本均匀分布在[low.high)左闭右开区间。low默认值是0.0,high默认值是1.0
均匀分布的概率密度函数:
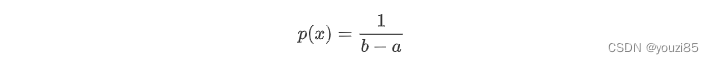
uniform的抽样和前面简单随机数的几个函数很相似,但是前面是返回0-1范围内的值,uniform函数可以自己指定数据变化范围。
随机数种子
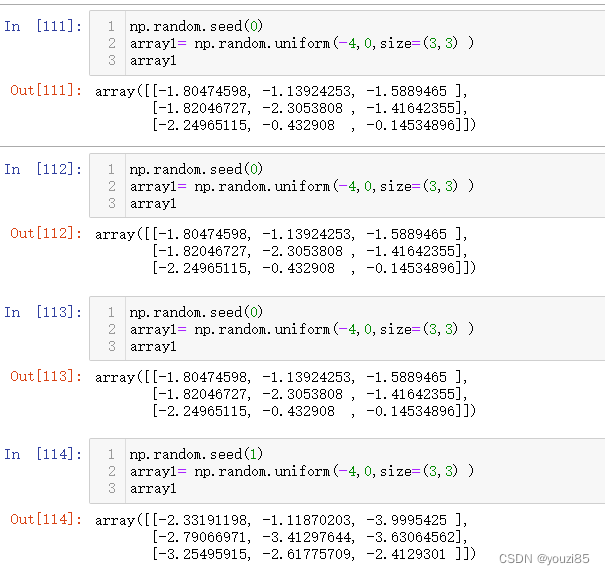
seed([seed])
当我们做数据分析,还有数据建模时,可能要通过调节参数值使模型更准确,但是用random模块每次数据都不一样,若是想保证在本次调节时样本数据一致,可使用seed函数。
当在同一个种子下,不管执行几次,得到的结果都是一样的。
另外,这个产生的随机数都是多位小数,如果你觉得看起来很累,可以设置自己想要精确到什么小数位。
np.set_printoptions(precision=2) # precision=2表示保留两位小数
array1= np.random.rand(4)
array1
如果你还有想了解random模块的其他函数,可以查看官方文档:
https://numpy.org/devdocs/reference/random/legacy.html#numpy.random.RandomState
好了,本文到这里就结束了,希望你对random模块有所了解。
感谢您的阅读~