总所周知,excel的功能非常强大,能做非常多的数据处理问题。其中,它的数据透视表功能就特别的好用,只要通过拖拽和鼠标点击就能根据需要完成统计问题。
在我们的pandas中,也有那么几个函数,它能够满足我们的数据透视表功能。让我们一起学习一下它们。
- pivot
pandas.pivot(data, *, index=None, columns=None, values=None)
对于一个维度,通过指定你需要的行名(index),列名(columns),和最后想要在二维数据表中展示的是哪些值(values),就会返回一个被重构的dataframe。
excel的数据透视表,就可以把一个维度的数据变成两个维度的数据,如下图显示,一个维度的数据,表示数据的增加只能向下添加。而两个维度的数据,即可以向下添加数据,还可以往右添加数据。

import numpy as np
import pandas as pd
# 创建测试数据
df = pd.DataFrame({'时间':['2020','2020','2020','2021','2021','2021','2022','2022','2022'],
'国家':['国家1','国家2','国家3','国家1','国家2','国家3','国家1','国家2','国家3'],
'销量':np.random.randint(100,1000,size=9)
})
df

# 这两种写法都可以
df.pivot(index='时间',columns='国家')
df.pivot(index='时间',columns='国家',values='销量')

当有多列数据时,你需要展现的就一定要指定出来,否则会都显示。
df = pd.DataFrame({'时间':['2020','2020','2020','2021','2021','2021','2022','2022','2022'],
'国家':['国家1','国家2','国家3','国家1','国家2','国家3','国家1','国家2','国家3'],
'销量':np.random.randint(100,1000,size=9),
'r':['a','a','c','d','e','f','g','h','i']
})
df

df.pivot(index='时间',columns = '国家',values='销量')
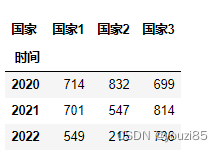
# 这样两种写法结果都一样
df.pivot(index='时间',columns = '国家')
df.pivot(index='时间',columns = '国家',values=['销量','r'])

pivot函数因为无法聚合,所以当index,columns组合具有重复值时,这个函数就不适用了,会报ValueError。
例如:
df = pd.DataFrame({'时间':['2020','2020','2020','2021','2021','2021','2022','2022','2022'],
'国家':['国家1','国家1','国家3','国家1','国家2','国家3','国家1','国家2','国家3'],
'销量':np.random.randint(100,1000,size=9)
})
df

对于这样的数据,调用pivot函数则会报错
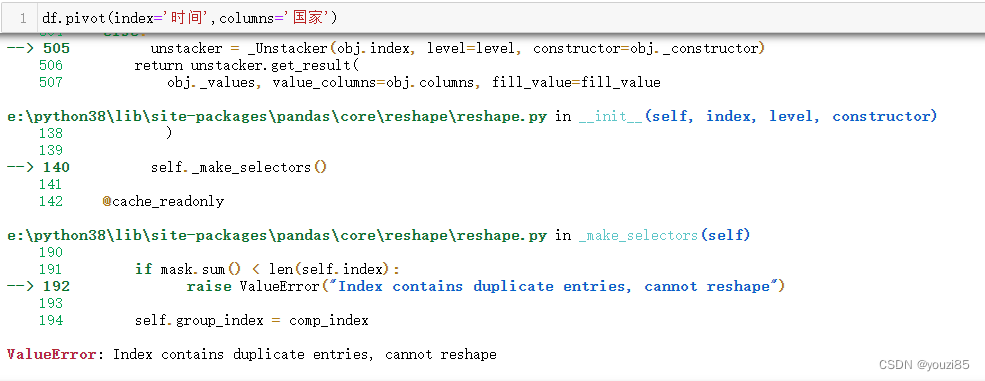
pivot函数是根据索引和列重塑dataframe,每一组index和columns只能有一个唯一值,否则报错。
更强大,更像excel中的数据透视表功能的pivot_table函数,让我们一起看看。
- pivot_table
pivot_table返回的是一个电子表样式的数据透视表的dataframe。数据透视表的中的级别存储在dataframe中index和column的分层索引上。
首先,上面pivot中给到的案例,pivot_table函数也能得到,这里不再重复给出案例。现在看看pivot报错的例子,使用pivot_table可以得到。
df = pd.DataFrame({'时间':['2020','2020','2020','2021','2021','2021','2022','2022','2022'],
'国家':['国家1','国家1','国家3','国家1','国家2','国家3','国家1','国家2','国家3'],
'销量':np.random.randint(100,1000,size=9)
})
df.pivot_table(index='时间',columns='国家',aggfunc='sum')

再来一个案例:
df = pd.DataFrame({"A": ["foo", "foo", "foo", "foo", "foo", "bar", "bar", "bar", "bar"],
"B": ["one", "one", "one", "two", "two", "one", "one", "two", "two"],
"C": ["small", "large", "large", "small", "small", "large", "small", "small", "large"],
"D": [1, 2, 2, 3, 3, 4, 5, 6, 7],
"E": [2, 4, 5, 5, 6, 6, 8, 9, 9]})
df

pd.pivot_table(df,values=['D','E'],index=['A','B'],columns='C',aggfunc={'D':np.sum,
'E':[np.sum,np.mean,np.size]},fill_value=0)

对于同一index和columns值时可以聚合函数,而且可以根据需要,对不同的value值进行不同的聚合操作。功能完全和excel的数据透视图一样,真的很强大。
- crosstab
crosstab也能得到类似数据透视表的dataframe,但是和pivot_table各有优缺点。
还是以上面的测试数据为例。
df = pd.DataFrame({"A": ["foo", "foo", "foo", "foo", "foo", "bar", "bar", "bar", "bar"],
"B": ["one", "one", "one", "two", "two", "one", "one", "two", "two"],
"C": ["small", "large", "large", "small", "small", "large", "small", "small", "large"],
"D": [1, 2, 2, 3, 3, 4, 5, 6, 7],
"E": [2, 4, 5, 5, 6, 6, 8, 9, 9]})
df
# [df['A'],df['B']]:index
# df['C']:columns
# df['D']:values
pd.crosstab([df['A'],df['B']],df['C'],df['D'],aggfunc='sum')

crosstab也可以对数据进行操作,但是若是想pivot_table一样有对两列D、E一起进行操作,crosstab则无法实现。
# 都会报错
pd.crosstab([df['A'],df['B']],df['C'],[df['D'],df['E']],aggfunc='sum')
pd.crosstab([df['A'],df['B']],df['C'],df.loc[:,'D':'E'],aggfunc='sum')
若是想要想用传入两列作为values值,都会报错,无法实现。
but!!! crosstab有优于pivot_table的地方,crosstab有个normalize参数,可以将数据归一化。
当normalize是all或者True时,是对所有数据进行归一化。
当normalize是index时,针对每一行归一化
当normalize是columns时,是针对每一列进行归一化。
话不多说,给个例子,还是上面的数据。
# 针对index
pd.crosstab([df['A'],df['B']],df['C'],df['D'],aggfunc='sum',normalize='index')

# 针对columns
pd.crosstab([df['A'],df['B']],df['C'],df['D'],aggfunc='sum',normalize='columns')

# 针对所有数据,并且添加行列边距
pd.crosstab([df['A'],df['B']],df['C'],df['D'],aggfunc='sum',margins=True,normalize='all')

这不直接把各个部分的占比都给你算出来了吗?
还有一点crosstab优于pivot_table的地方,分别查看这两个函数,pivot_table是将数据用data传入,所以基本就是一张表中的数据。但是crosstab是将index,columns,values分别传入。这样,你的数据来源就可以来自几张不同的表,只要这几张表具有相同的行数就可以了。
# 测试数据
df = pd.DataFrame({"A": ["foo", "foo", "foo", "foo", "foo", "bar", "bar", "bar", "bar"],
"B": ["one", "one", "one", "two", "two", "one", "one", "two", "two"],
"C": ["small", "large", "large", "small", "small", "large", "small", "small", "large"],
"D": [1, 2, 2, 3, 3, 4, 5, 6, 7],
"E": [2, 4, 5, 5, 6, 6, 8, 9, 9]})
c = np.array(["dull", "dull", "shiny", "dull", "shiny",
"shiny", "dull", "shiny", "shiny"],
dtype=object)
# 对crosstab结果计数
# A为index
# B和C为columns
pd.crosstab(df['A'],[df['B'],c],rownames=['a'],colnames=['b','c'])

# 也可以对某一列数据求和操作
# A为index
# B和C为columns
# D是data
pd.crosstab(df['A'],[df['B'],c],df['D'],rownames=['a'],colnames=['b','c'],aggfunc='sum')

由执行结果可以看出,crosstab不需要数据来源于同一张表。这个功能已经超过了excel的数据透视图了。excel的数据透视图是无法引用分开的数据进行操作的。
上面的函数是将一个维度的数据变成2个维度的数据。接下来,我们一起学习将两个维度的数据转变为一个维度的。
- melt
我们将上面得到的数据透视表再转回一个维度的数据。
案例一:
# 原来的数据
df = pd.DataFrame({'时间':['2020','2020','2020','2021','2021','2021','2022','2022','2022'],
'国家':['国家1','国家2','国家3','国家1','国家2','国家3','国家1','国家2','国家3'],
'销量':np.random.randint(100,1000,size=9),
'r':['a','a','c','d','e','f','g','h','i']
})
d1 = df.pivot(index='时间',columns = '国家',values='销量')
d1
再看一眼得到的d1数据。

pd.melt(d1,value_vars=['国家1','国家2','国家3'],ignore_index=False)

时间是index列,除去index列,所有的数据都要从进行列变行的转变,所以id_vars不赋值,value_vars将各列名字传入,然后保留索引,就能得到想要的结果。
案例二:
df = pd.DataFrame({"A": ["foo", "foo", "foo", "foo", "foo", "bar", "bar", "bar", "bar"],
"B": ["one", "one", "one", "two", "two", "one", "one", "two", "two"],
"C": ["small", "large", "large", "small", "small", "large", "small", "small", "large"],
"D": [1, 2, 2, 3, 3, 4, 5, 6, 7],
"E": [2, 4, 5, 5, 6, 6, 8, 9, 9]})
d2 = pd.pivot_table(df,values=['D','E'],index=['A','B'],columns='C',aggfunc=np.sum)
d2

对于有复合索引情况的数据,我们可以将复合索引以元组的方式写入列表,也能得到最后的结果。
pd.melt(d2,value_vars=[('D','large'),('D','small'),('E','large'),('E','small')],ignore_index=False)

看到这里,你们是不是对这几个函数有所了解了呢,具体用法还可以参考官方文档 。
本文到这里就结束了,感谢您的阅读~