python在读写matlab文件时常用到scipy.io文件,但是,针对存储版本为“matlab-v7.3”的文件,必须用h5py模块。
博主想处理 The Street View House Numbers (SVHN) 的format 1 数据集,用bounding box 剪裁出图像中的文字,发现里面的 bounding box 是.mat文件,且存储版本为 matlab-v7.3, 需要用h5py读取。网上搜了一圈,发现那些教程太老了,不适用于 h5py 3.1.0的版本,费了一番功夫才读出来。记录一下。
数据集
- 数据集的说明:http://ufldl.stanford.edu/housenumbers/
- 训练集的压缩包:http://ufldl.stanford.edu/housenumbers/train.tar.gz
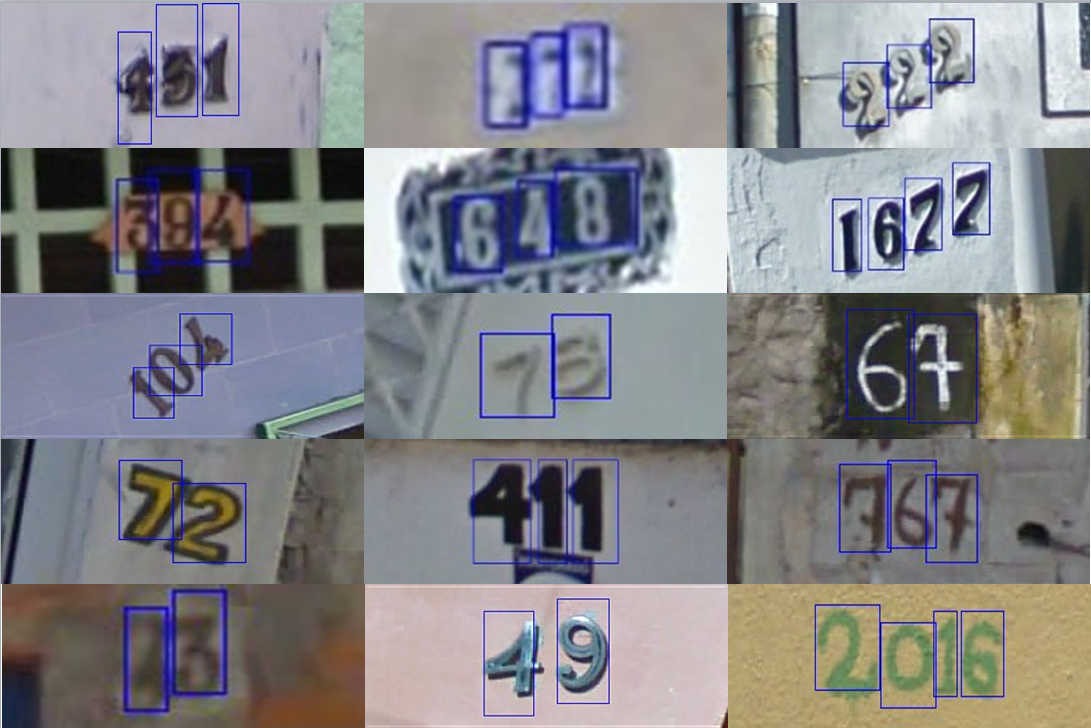
总而言之,就是要用 bouding box 把数字圈出来,一张图像中可能有多个数字,就有多个bounding box
初步尝试
读取
下载数据集后,用 tar -xzvf 解压缩。以下代码运行在jupyter notebook中。
引入包和文件路径,读取.mat文件:
import h5py
data_path = "./train/digitStruct.mat"
f = h5py.File(data_path, 'r')
f.keys()
<KeysViewHDF5 [’#refs#’, ‘digitStruct’]>
以下是一些乱七八糟的尝试,如果没兴趣看的话可以跳到下一个分割线处,PC端可以直接 ctrl+F 搜索:再尝试。
#refs#
查看到有两类key:’#refs#’ 和 ‘digitStruct’,先来看一下第一个 ‘#refs#’ 里是什么。
list(f.keys())[0]
‘#refs#’
f[list(f.keys())[0]]
<HDF5 group “/#refs#” (100005 members)>
看输出,可能是列名和行名
f[list(f.keys())[0]].keys()
<KeysViewHDF5 [’#a’, ‘#b’, ‘#c’, ‘#d’, ‘0’, ‘00’, ‘00b’, ‘00c’, ‘00d’, ‘00e’, ‘00f’, ‘00g’, ‘00h’, ‘00i’, ‘00j’, ‘00k’, ‘00l’, ‘00m’, ‘00n’, ‘00o’, ‘00p’, ‘00q’, ‘00r’, ‘00s’, ‘00t’, ‘00u’, ‘00v’, ‘00w’, ‘00x’, ‘00y’, ‘00z’, ‘01’, ‘01b’, ‘01c’, ‘01d’, ‘01e’, ‘01f’, ‘01g’, ‘01h’, ‘01i’, ‘01j’, ‘01k’, ‘01l’, ‘01m’, ‘01n’, ‘01o’, ‘01p’, ‘01q’, ‘01r’, ‘01s’, ‘01t’, ‘01u’, ‘01v’, ‘01w’, ‘01x’, ‘01y’, ‘01z’, ‘02’, ‘02b’, ‘02c’, ‘02d’, ‘02e’, ‘02f’, ‘02g’, ‘02h’, ‘02i’, ‘02j’, ‘02k’, ‘02l’, ‘02m’, ‘02n’, ‘02o’, ‘02p’, ‘02q’, ‘02r’, ‘02s’, ‘02t’, ‘02u’, ‘02v’, ‘02w’, ‘02x’, ‘02y’, ‘02z’, ‘03’, ‘03b’, …>
选择其中的一个键值 '#a’来看看:
f[list(f.keys())[0]]['#a']
<HDF5 group “/#refs#/#a” (100001 members)>
f[list(f.keys())[0]]['#a'].keys()
<KeysViewHDF5 [‘0’, ‘00’, ‘00b’, ‘00c’, ‘00d’, ‘00e’, ‘00f’, ‘00g’, ‘00h’, ‘00i’, ‘00j’, ‘00k’, ‘00l’, ‘00m’, ‘00n’, ‘00o’, ‘00p’, ‘00q’, ‘00r’, ‘00s’, ‘00t’, ‘00u’, ‘00v’, ‘00w’, ‘00x’, ‘00y’, ‘00z’, ‘01’, ‘01b’, ‘01c’, ‘01d’, ‘01e’, ‘01f’, ‘01g’, ‘01h’, ‘01i’, ‘01j’, ‘01k’, ‘01l’, ‘01m’, ‘01n’, ‘01o’, ‘01p’, ‘01q’, ‘01r’, ‘01s’, ‘01t’, ‘01u’, ‘01v’, ‘01w’, ‘01x’, ‘01y’, ‘01z’, ‘02’, ‘02b’, ‘02c’, ‘02d’, ‘02e’, ‘02f’, ‘02g’, ‘02h’, … >
f[list(f.keys())[0]]['#a']['0'][:]
array([[32.]])
f[list(f.keys())[0]]['#a']['00'].keys()
<KeysViewHDF5 [‘height’, ‘label’, ‘left’, ‘top’, ‘width’]>
应该没什么用处,就是有五种key来标记 bounding box 和 label.
搜索了一圈,找到了一个简单查看层级关系的方法:
def printname(name):
print(name)
f.visit(printname)
输出了一堆东西
……
#refs#/#a/16o
#refs#/#a/16o/height
#refs#/#a/16o/label
#refs#/#a/16o/left
#refs#/#a/16o/top
#refs#/#a/16o/width
#refs#/#a/16p
#refs#/#a/16q
#refs#/#a/16r
#refs#/#a/16s
#refs#/#a/16t
#refs#/#a/16u
#refs#/#a/16v
#refs#/#a/16w
#refs#/#a/16w/height
#refs#/#a/16w/label
#refs#/#a/16w/left
#refs#/#a/16w/top
#refs#/#a/16w/width
……
digitStruct
再来看看 digitStruct.
……【这里写的有问题,删了】
乱七八糟的尝试到此为止,以下重新开始。
再尝试
Matlab
看到这里还是一头雾水,没办法还是得先用matlab看看数据格式。
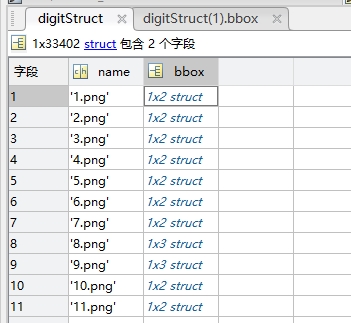
name是图像的名字,bbox是图像中的包围盒(bounding box),是object对象(套娃了另一个表)
再点进一个包围盒,就是 height, left, top, width 对应包围盒的高度,左上角点的横坐标,左上角点的纵坐标,宽度,label是数字的标签。
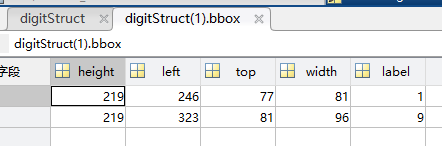
读取
def printname(name):
print(name)
f['digitStruct'].visit(printname)
bbox
name
这次和matlab上看到的一样了。
name
.value这种方法在3.1.0的h5py中已经废弃,这里参考 h5py 将 mat 数据集中的 转成 string,读取名字:
digitStructName = f['digitStruct']['name']
digitStructBbox = f['digitStruct']['bbox']
for i in range(digitStructName.shape[0]):
# name = ''.join([chr(v[0]) for v in data[names[i][0]].value])
# .value 这种方法已经废弃了
name = ''.join([chr(v[0]) for v in f[(digitStructName[i][0])]])
print(name)
1.png
2.png
3.png
4.png
…
终于可以正常读取了name了,定义一个函数:
def getName(n):
# name = ''.join([chr(v[0]) for v in data[names[i][0]].value])
# .value 这种方法已经废弃了
name = ''.join([chr(v[0]) for v in f[(digitStructName[n][0])]])
print(name)
return name
getName(3)
接下来是bbox
bbox
先看看第一个图像的bbox
bb = digitStructBbox[0].item()
bb
<HDF5 object reference>
attr = f[bb]["height"]
attr
<HDF5 dataset “height”: shape (2, 1), type “|O”>
刚才在matlab上已经看到,因为这个图像中有两个数字,所以shape的第0维是2.
读取
for j in range(len(attr)):
print(f[attr[j].item()][0][0])
219.0
219.0
和 matlab 上看到的一样
用同样的方式就可以读取height, label 等。
定义一个函数(以下参考了github上的SVHN预处理代码):
def bboxHelper(attr):
if len(attr) > 1:
attr = [f[attr[j].item()][0][0] for j in range(len(attr))]
else:
attr = [attr[0][0]]
return attr
def getBbox(n):
bbox = {
}
bb = digitStructBbox[n].item()
# bbox = bboxHelper(f[bb]["label"])
bbox['height'] = bboxHelper(f[bb]["height"])
bbox['label'] = bboxHelper(f[bb]["label"])
bbox['left'] = bboxHelper(f[bb]["left"])
bbox['top'] = bboxHelper(f[bb]["top"])
bbox['width'] = bboxHelper(f[bb]["width"])
return bbox
getBbox(3)
{‘height’: [34.0, 34.0],
‘label’: [9.0, 3.0],
‘left’: [57.0, 72.0],
‘top’: [13.0, 13.0],
‘width’: [15.0, 13.0]}
至此,读取的操作应该没有问题了。用循环建立字典:
image_dict = {
}
for i in range(len(digitStructName)):
image_dict[getName(i)] = getBbox(i)
汇总:
import h5py
import numpy as np
data_path = "./train/digitStruct.mat"
f = h5py.File(data_path, 'r')
def printname(name):
print(name)
f['digitStruct'].visit(printname) # bbox, name
digitStructName = f['digitStruct']['name']
digitStructBbox = f['digitStruct']['bbox']
def getName(n):
# name = ''.join([chr(v[0]) for v in data[names[i][0]].value])
# .value 这种方法已经废弃了
name = ''.join([chr(v[0]) for v in f[(digitStructName[n][0])]])
return name
def bboxHelper(attr):
if len(attr) > 1:
attr = [f[attr[j].item()][0][0] for j in range(len(attr))]
else:
attr = [attr[0][0]]
return attr
def getBbox(n):
bbox = {
}
bb = digitStructBbox[n].item()
# bbox = bboxHelper(f[bb]["label"])
bbox['height'] = bboxHelper(f[bb]["height"])
bbox['label'] = bboxHelper(f[bb]["label"])
bbox['left'] = bboxHelper(f[bb]["left"])
bbox['top'] = bboxHelper(f[bb]["top"])
bbox['width'] = bboxHelper(f[bb]["width"])
return bbox
image_dict = {
}
for i in range(len(digitStructName)):
image_dict[getName(i)] = getBbox(i)
完整代码
最后,再放上来一个完整的SVHN format1的预处理代码 preprocess.py,主要参考了参考文献3的GitHub代码,文件路径为:
.
|--- preprocess.py
|--- train
|--- test
import glob
import os
import pickle
import cv2
import h5py
import numpy as np
import torchvision
import torchvision.transforms as transforms
from tqdm import tqdm
class DataPreprocess():
def __init__(self, set_type):
self.set_type = set_type
self.transform = transforms.Compose(
[transforms.ToPILImage(),
transforms.Resize((32, 32)),
transforms.ToTensor()])
self.digitStructName = None
self.digitStructBbox = None
self.f = None
self.preprocess()
def preprocess(self):
print('Preprocess set:', self.set_type)
data_dir = f"./{self.set_type}/" # 数据集所在文件夹名称
cache_dir = './cache' # 用于存放处理好的数据
print('Data directory is ', data_dir)
self.f = h5py.File(os.path.join(data_dir, 'digitStruct.mat'), 'r')
self.digitStructName = self.f['digitStruct']['name']
self.digitStructBbox = self.f['digitStruct']['bbox']
print('\nGetting name and bbox ...')
os.makedirs(cache_dir, exist_ok=True)
cache_image_dir = os.path.join(cache_dir, f'image_dict_{self.set_type}.pkl')
if os.path.exists(cache_image_dir):
# 读取已经处理好的
image_dict = pickle.load(open(cache_image_dir, 'rb'))
else:
# 处理
image_dict = {
}
for i in tqdm(range(len(self.digitStructName))):
image_dict[self.getName(i)] = self.getBbox(i)
with open(cache_image_dir, 'wb') as w:
pickle.dump(image_dict, w)
print('Done.\n\nPreprocessing ...')
fnames = glob.glob(os.path.join(data_dir, '*.png'))
save_dir = f"./{self.set_type}_new/"
os.makedirs(save_dir, exist_ok=True)
print('Save to ', save_dir)
n_drop = 0
for i in tqdm(range(len(fnames))):
image = cv2.imread(fnames[i])
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # because "torchvision.utils.save_image" use RGB
_, fname = os.path.split(fnames[i])
digit_dict = image_dict[fname]
fname = fname.split('.')[0]
for j in range(len(digit_dict['label'])):
label = int(digit_dict['label'][j])
if label == 10:
label = 0
left = int(digit_dict['left'][j])
upper = int(digit_dict['top'][j])
right = int(left + digit_dict['width'][j])
lower = int(upper + digit_dict['height'][j])
if left < 0 or upper < 0:
n_drop += 1
continue
img = image[upper:lower, left:right, :]
img = self.transform(img)
# 把图片以 1_0.jpg的格式存储,1是原始的图像名,0是它的标签
save_file = os.path.join(save_dir, f'{fname}_{label}.jpg')
torchvision.utils.save_image(img, save_file)
print(f'Done.(Drop {n_drop} digits for the negative coordinate.)\n')
def getName(self, n):
# 从 mat 中获取图像name e.g. 1.png
return ''.join([chr(v[0]) for v in self.f[(self.digitStructName[n][0])]])
def bboxHelper(self, attr):
# 根据attr从bbox中取值,attr 可能是 height/left/top/width/label
if len(attr) > 1:
attr = [self.f[attr[j].item()][0][0] for j in range(len(attr))]
else:
attr = [attr[0][0]]
return attr
def getBbox(self, n):
# 从 mat 中获取 digit 的bbox
bbox = {
}
bb = self.digitStructBbox[n].item()
bbox['height'] = self.bboxHelper(self.f[bb]["height"])
bbox['left'] = self.bboxHelper(self.f[bb]["left"])
bbox['top'] = self.bboxHelper(self.f[bb]["top"])
bbox['width'] = self.bboxHelper(self.f[bb]["width"])
bbox['label'] = self.bboxHelper(self.f[bb]["label"])
return bbox
def loadData(set_type, reload=False):
print(f'Loading {set_type} data ...')
cache_dir = './cache'
cache_dataset_dir = os.path.join(cache_dir, f'{set_type}.pkl')
if os.path.exists(cache_dataset_dir) and not reload:
# 读取已经处理好的
print('Existed.')
dataset = pickle.load(open(cache_dataset_dir, 'rb'))
else:
new_data_dir = f"./{set_type}_new/"
fnames = glob.glob(os.path.join(new_data_dir, '*'))
dataset = {
}
x = []
y = []
for i in tqdm(range(len(fnames))):
fname = fnames[i]
_, label = os.path.split(fname)
label = int(label.split('.')[0].split('_')[1])
y.append(label)
image = cv2.imread(fname)
x.append(image)
dataset['data'] = np.array(x)
dataset['label'] = np.array(y)
with open(cache_dataset_dir, 'wb') as w:
pickle.dump(dataset, w)
print('Shape of x:', dataset['data'].shape, '\t|\tShape of y:', dataset['label'].shape)
print('Done.')
return dataset
if __name__ == '__main__':
preprocess_train = DataPreprocess(set_type='train')
preprocess_test = DataPreprocess(set_type='test')
# train = loadData(set_type='train', reload=True)
# test = loadData(set_type='test', reload=True)
# print(train.shape)
# print(test.shape)
代码会创建文件夹 train_new 和 test_new,存放处理后的图像,这里将图像都变化为 32 × 32 32\times32 32×32
参考资料: