本文主要从性能角度考虑 RocketMQ 的实现。
整体架构

这是网络上流行的 RocketMQ 的集群部署图。
RocketMQ 主要由 Broker、NameServer、Producer 和 Consumer 组成的一个集群。
**NameServer:整个集群的注册中心和配置中心,管理集群的元数据。包括 Topic 信息和路由信息、Producer 和 Consumer 的客户端注册信息、Broker 的注册信息。**Broker:负责接收消息的生产和消费请求,并进行消息的持久化和消息的读取。**Producer:负责生产消息。**Consumer:负责消费消息。在实际生产和消费消息的过程中,NameServer 为生产者和消费者提供 Meta 数据,以确定消息该发往哪个 Broker 或者该从哪个 Broker 拉取消息。有了 Meta 数据后,生产者和消费者就可以直接和 Broker 交互了。这种点对点的交互方式最大限度降低了消息传递的中间环节,缩短了链路耗时。
网络模型
RocketMQ 使用 Netty 框架实现高性能的网络传输。
基于 Netty 实现网络通信模块
Netty 主要特点
**具有统一的 API,用户无需关心 NIO 的编程模型和概念。通过 Netty 的 ChannelHandler 可以对通信框架进行灵活的定制和扩展。**Netty 封装了网络编程涉及的基本功能:拆包解包、异常检测、零拷贝传输。**Netty 解决了 NIO 的 Epoll Bug,避免空轮询导致 CPU 的 100% 利用率。**支持多种 Reactor 线程模型。**使用范围广泛,有较好的的开源社区支持。Hadoop、Spark、Dubbo 等项目都集成 Netty。**Netty 的高性能传输的体现
非阻塞 IORactor 线程模型**零拷贝。使用 FileChannel.transfer 避免在用户态和内核态之间的拷贝操作;通过 CompositeByteBuf 组合多个 ByteBuffer;通过 slice 获取 ByteBuffer 的切片;通过 wrapper 把普通 ByteBuffer 封装成 netty.ByteBuffer。**RocketMQ 网络模型
RocketMQ 的 Broker 端基于 Netty 实现了主从 Reactor 模型。架构如下:

具体流程:
eventLoopGroupBoss 作为 acceptor 负责接收客户端的连接请求eventLoopGroupSelector 负责 NIO 的读写操作NettyServerHandler 读取 IO 数据,并对消息头进行解析disatch 过程根据注册的消息 code 和 processsor 把不同的事件分发给不同的线程。由 processTable 维护(类型为 HashMap)业务线程池隔离
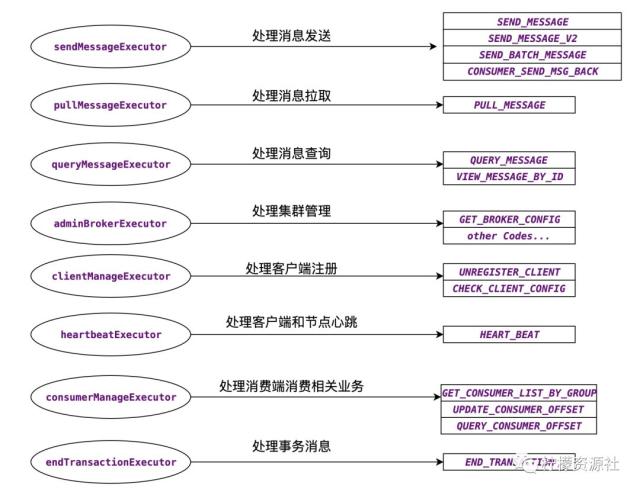
RocketMQ 对 Broker 的线程池进行了精细的隔离。使得消息的生产、消费、客户端心跳、客户端注册等请求不会互相干扰。如下是各个业务执行线程池和 Broker 处理的报文类型的对应关系,从下图中我们也可以看出 Broker 的核心功能点。
消息的生产
RocketMQ 支持三种消息发送方式:同步发送、异步发送和 One-Way 发送。One-Way 发送时客户端无法确定服务端消息是否投递成功,因此是不可靠的发送方式。
客户端发送时序图

流程说明
**客户端 API 调 DefaultMQProducer 的 send 方法进行消息的发送。**makeSureStateOk 检查客户端的发送服务是否 ok。RocketMQ 客户端维护了一个单例的 MQClientInstance,可通过 start 和 shutdown 来管理相关的网络服务。**tryToFindTopicPublishInfo 用来获取 Topic 的 Meta 信息,主要是可选的 MessageQueue 列表。**selectOneMessageQueue 根据当前的故障容错机制,路由到一个特定的 MessageQueue。**sendKernelImpl 的核心方法是调用 NettyRemotingClient 的 sendMessage 方法,该方法中会根据用户选择的发送策略进行区别处理,时序图中只体现了同步发送的方式。**invokeSync 通过调用 Netty 的 channel.writeAndFlush 把消息的字节流发送到 TCP 的 Socket 缓冲区,至此客户端消息完成发送。三种发送方式实现上的区别
**同步发送:注册 ResponseFuture 到 responseTable,发送 Request 请求,并同步等待 Response 返回。**异步发送:注册 ResponseFuture 到 responseTable,发送 Request 请求,不需要同步等待 Response 返回,当 Response 返回后会调用注册的 Callback 方法,从而异步获取发送的结果。**One-Way:发送 Request 请求,不需要等待 Response 返回,不需要触发 Callback 方法回调。**客户端故障容错机制
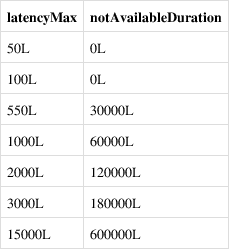
MQFaultStrategy 实现了基于 RT 耗时的容错策略。当某个 Broker 的 RT 过大时,认为该 Broker 存在问题,会禁用该 Broker 一段时间。latencyMax 和 notAvailableDuration 的对应关系如下图:
客户端高效发送总结
One-Way 的发送方式是效率最高的,不需要同步等待过程,也不需要额外 CallBack 调用开销,但是消息发送不可靠MQClientInstance 的单例模式统一管理维护网络通道,发送消息前只需要做一次服务状态可用性检查即可Topic 的 Meta 信息在本地建立缓存,避免每次发送消息从 NameServer 拉取 Meta 数据高效的故障容错机制,保证消息发送失败时进行快速重发Broker 接收消息时序图

流程说明
**Broker 通过 Netty 接收 RequestCode 为 SEND_MESSAGE 的请求,并把该请求交给 SendMessageProcessor 进行处理。**SendMessageProcessor 先解析出 SEND_MESSAGE 报文中的消息头信息(Topic、queueId、producerGroup 等),并调用存储层进行处理。**putMessage 中判断当前是否满足写入条件:Broker 状态为 running;Broker 为 master 节点;磁盘状态可写(磁盘满则无法写入);Topic 长度未超限;消息属性长度未超限;pageCache 未处于繁忙状态(pageCachebusy 的依据是 putMessage 写入 mmap 的耗时,如果耗时超过 1s,说明由于缺页导致页加载慢,此时认定 pageCache 繁忙,拒绝写入)。**从 MappedFileQueue 中选择已经预热过的 MappedFile。**AppendMessageCallback 中执行消息的操作 doAppend,直接对 mmap 后的文件的 bytbuffer 进行写入操作。**Broker 端对写入性能的优化
自旋锁减少上下文切换
RocketMQ 的 CommitLog 为了避免并发写入,使用一个 PutMessageLock。PutMessageLock 有 2 个实现版本:PutMessageReentrantLock 和 PutMessageSpinLock。
PutMessageReentrantLock 是基于 java 的同步等待唤醒机制;PutMessageSpinLock 使用 Java 的 CAS 原语,通过自旋设值实现上锁和解锁。RocketMQ 默认使用 PutMessageSpinLock 以提高高并发写入时候的上锁解锁效率,并减少线程上下文切换次数。
MappedFile 预热和零拷贝机制
RocketMQ 消息写入对延时敏感,为了避免在写入消息时,CommitLog 文件尚未打开或者文件尚未加载到内存引起的 load 的开销,RocketMQ 实现了文件预热机制。
Linux 系统在写数据时候不会直接把数据写到磁盘上,而是写到磁盘对应的 PageCache 中,并把该页标记为脏页。当脏页累计到一定程度或者一定时间后再把数据 flush 到磁盘(当然在此期间如果系统掉电,会导致脏页数据丢失)。RocketMQ 实现文件预热的关键代码如下:
publicvoidwarmMappedFile(FlushDiskType type, int pages){ByteBuffer byteBuffer = this.mappedByteBuffer.slice();int flush = 0;long time = System.currentTimeMillis();for (int i = 0, j = 0; i < this.fileSize; i += MappedFile.OS_PAGE_SIZE, j++) {byteBuffer.put(i, (byte) 0);// force flush when flush disk type is syncif (type == FlushDiskType.SYNC_FLUSH) {if ((i / OS_PAGE_SIZE) - (flush / OS_PAGE_SIZE) >= pages) {flush = i;mappedByteBuffer.force();}}…}// force flush when prepare load finishedif (type == FlushDiskType.SYNC_FLUSH) {log.info(“mapped file warm-up done, force to disk, mappedFile={}, costTime={}”,this.getFileName(), System.currentTimeMillis() - beginTime);mappedByteBuffer.force();}this.mlock();}代码分析
**对文件进行 mmap 映射。**对整个文件每隔一个 PAGE_SIZE 写入一个字节,如果是同步刷盘,每写入一个字节进行一次强制的刷盘。**调用 libc 的 mlock 函数,对文件所在的内存区域进行锁定。(系统调用 mlock 家族允许程序在物理内存上锁住它的部分或全部地址空间。这将阻止 Linux 将这个内存页调度到交换空间(swap space),即使该程序已有一段时间没有访问这段空间)。**同步和异步刷盘
RocketMQ 提供了同步刷盘和异步刷盘两种机制。默认使用异步刷盘机制。
当 CommitLog 在 putMessage() 中收到 MappedFile 成功追加消息到内存的结果后,便会调用 handleDiskFlush() 方法进行刷盘,将消息存储到文件中。handleDiskFlush() 便会根据两种刷盘策略,调用不同的刷盘服务。
抽象类 FlushCommitLogService 负责进行刷盘操作,该抽象类有 3 种实现:
GroupCommitService:同步刷盘FlushRealTimeService:异步刷盘CommitRealTimeService:异步刷盘并且开启 TransientStorePool每个实现类都是一个 ServiceThread 实现类。ServiceThread 可以看做是一个封装了基础功能的后台线程服务。有完整的生命周期管理,支持 start、shutdown、weakup、waitForRunning。
同步刷盘流程
所有的 flush 操作都由 GroupCommitService 线程进行处理当前接收消息的线程封装一个 GroupCommitRequest,并提交给 GroupCommitService 线程,然后当前线程进入一个 CountDownLatch 的等待**一旦有新任务进来 GroupCommitService 被立即唤醒,并调用 MappedFile.flush 进行刷盘。底层是调用 mappedByteBuffer.force ()**flush 完成后唤醒等待中的接收消息线程。从而完成同步刷盘流程异步刷盘流程
**RocketMQ 每隔 200ms 进行一次 flush 操作(把数据持久化到磁盘)当有新的消息写入时候会主动唤醒 flush 线程进行刷盘当前接收消息线程无须等待 flush 的结果。**消息消费
高性能的消息队列应该保证最快的消息周转效率:即发送方发送的一条消息被 Broker 处理完之后应该尽快地投递给消息的消费方。
消息存储结构
RocketMQ 的存储结构最大特点:
**所有的消息写入转为顺序写(相比于 Kafka,RocketMQ 即使对于 1w+ 以上的 Topic 也能够应付自如)**读写文件分离。通过 ReputMessageService 服务生成 ConsumeQueue

结构说明
**ConsumeQueue 与 CommitLog 不同,采用定长存储结构,如下图所示。为了实现定长存储,ConsumeQueue 存储了消息 Tag 的 Hash Code,在进行 Broker 端消息过滤时,通过比较 Consumer 订阅 Tag 的 HashCode 和存储条目中的 Tag Hash Code 是否一致来决定是否消费消息。**ReputMessageService 持续地读取 CommitLog 文件并生成 ConsumeQueue。顺序消费与并行消费
串行消费和并行消费最大的区别在于消费队列中消息的顺序性。顺序消费保证了同一个 Queue 中的消费时的顺序性。RocketMQ 的顺序性依赖于分区锁的实现。消息消费有推拉两种模式,我们这里只考虑推这种模式
并行消费
**并行消费的实现类为 ConsumeMessageConcurrentlyService。**PullMessageService 内置一个 scheduledExecutorService 线程池,主要负责处理 PullRequest 请求,从 Broker 端拉取最新的消息返回给客户端。拉取到的消息会放入 MessageQueue 对应的 ProcessQueue。**ConsumeMessageConcurrentlyService 把收到的消息封装成一个 ConsumeRequest,投递给内置的 consumeExecutor 独立线程池进行消费。**ConsumeRequest 调用 MessageListener.consumeMessage 执行用户定义的消费逻辑,返回消费状态。**如果消费状态为 SUCCESS。则删除 ProcessQueue 中的消息,并提交 offset。**如果消费状态为 RECONSUME。则把消息发送到延时队列进行重试,并对当前失败的消息进行延迟处理。串行消费
**串行消费的实现类为 ConsumeMessageOrderlyService。**PullMessageService 内置一个 scheduledExecutorService 线程池,主要负责处理 PullRequest 请求,从 Broker 端拉取最新的消息返回给客户端。拉取到的消息会放入 MessageQueue 对应的 ProcessQueue。**ConsumeMessageOrderlyService 把收到的消息封装成一个 ConsumeRequest,投递给内置的 consumeExecutor 独立线程池进行消费。**消费时首先获取 MessageQueue 对应的 objectLock,保证当前进程内只有一个线程在处理对应的的 MessageQueue, 从 ProcessQueue 的 msgTreeMap 中按 offset 从低到高的顺序取消息,从而保证了消息的顺序性。**ConsumeRequest 调用 MessageListener.consumeMessage 执行用户定义的消费逻辑,返回消费状态。**如果消费状态为 SUCCESS。则删除 ProcessQueue 中的消息,并提交 offset。**如果消费状态为 SUSPEND。判断是否达到最大重试次数,如果达到最大重试次数,就把消息投递到死信队列,继续下一条消费;否则消息重试次数 + 1,在延时一段时间后继续重试。**可见,串行消费如果某条消息一直无法消费成功会造成阻塞,严重时会引起消息堆积和关联业务异常。
Broker 端的 PullMessage 长连接实现
消息队列中的消息是由业务触发而产生的,如果使用周期性的轮询,不能保证每次都取到消息,且轮询的频率过快或者过慢都会对消息的延时有严重的影响。因此 RockMQ 在 Broker 端使用长连接的方式处理 PullMessage 请求。具体实现流程如下:
**PullRequest 请求中有个参数 brokerSuspendMaxTimeMillis,默认值为 15s,控制请求 hold 的时长。**PullMessageProcessor 接收到 Request 后,解析参数,校验 Topic 的 Meta 信息和消费者的订阅关系。对于符合要求的请求,从存储中拉取消息。**如果拉取消息的结果为 PULL_NOT_FOUND,表示当前 MessageQueue 没有最新消息。**此时会封装一个 PullRequest 对象,并投递给 PullRequestHoldService 内部线程的 pullRequestTable 中。**PullRequestHoldService 线程会周期性轮询 pullRequestTable,如果有新的消息或者 hold 时间超时 polling time,就会封装 Response 请求发给客户端。**另外 DefaultMessageStore 中定义了 messageArrivingListener,当产生新的 ConsumeQueue 记录时候,会触发 messageArrivingListener 回调,立即给客户端返回最新的消息。长连接机制使得 RocketMQ 的网络利用率非常高效,并且最大限度地降低了消息拉取时的等待开销。实现了毫秒级的消息投递。
RocketMQ 的其他性能优化手段
关闭偏向锁
在 RocketMQ 的性能测试中,发现存在大量的 RevokeBias 停顿,偏向锁主要是消除无竞争情况下的同步原语以提高性能,但考虑到 RocketMQ 中该场景比较少,便通过 - XX:-UseBiasedLocking 关闭了偏向锁特性。
在没有实际竞争的情况下,还能够针对部分场景继续优化。如果不仅仅没有实际竞争,自始至终,使用锁的线程都只有一个,那么,维护轻量级锁都是浪费的。偏向锁的目标是,减少无竞争且只有一个线程使用锁的情况下,使用轻量级锁产生的性能消耗。轻量级锁每次申请、释放锁都至少需要一次 CAS,但偏向锁只有初始化时需要一次 CAS。
偏向锁的使用场景有局限性,只适用于单个线程使用锁的场景,如果有其他线程竞争,则偏向锁会膨胀为轻量级锁。当出现大量 RevokeBias 引起的小停顿时,说明偏向锁意义不大,此时通过 - XX:-UseBiasedLocking 进行优化,因此 RocketMQ 的 JVM 参数中会默认加上 - XX:-UseBiasedLocking。
写在最后
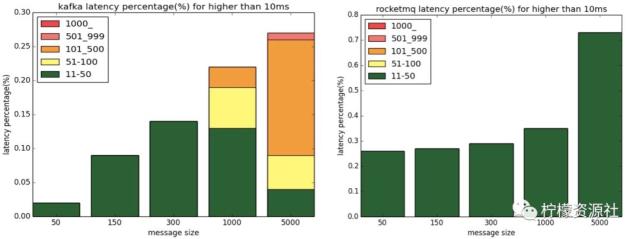
最后附上阿里中间件的延时性能对比。RocketMQ 在低延迟方面依然具有领先地位,如下图所示,RocketMQ 仅有少量 10~50ms 的毛刺延迟,Kafka 则有不少 500~1000ms 的毛刺。