MIM无法从更大的数据中获益?本文系统地研究了不同模型大小和训练长度下 MIM 方法的数据缩放能力,验证了掩码图像建模 (MIM) 不仅具有模型缩放的能力,也同样具有数据缩放的能力。
本文是一篇实验探究类的工作,研究的问题是自监督学习 (掩码图像建模类方法) 的数据缩放问题。
自监督学习的一个重要目标是:让预训练的模型能够从大量的数据中获益。但是最近的自监督方法,掩码图像建模 (masked image modeling, MIM) 被怀疑无法从更大的数据中获益。
这项工作中作者通过大量实验打破了这种误解,数据规模从 ImageNet-1K 的 10% 到完整 ImageNet-22K,模型大小从4900万到10亿,训练长度从 125K 个 iteration 到 500K 个 iteration。作者的研究表明:
-
掩模图像建模也需要更大的数据: 作者观察到,非常大的模型在相对较小的数据下往往会过拟合。
-
训练时间的问题: 通过掩模图像建模训练的大模型,可以通过更长的训练,从更多的数据中受益。
-
预训练中的 validation loss 是衡量模型在多个任务上的微调效果的良好指标: 这种观察使我们能够对我们预训练的模型进行廉价的预评估,而不必每次都在下游任务上进行评估,因为太昂贵。
1 掩码图像建模中的数据缩放
论文名称:On Data Scaling in Masked Image Modeling (CVPR 2023)
论文地址:
https://arxiv.org/pdf/2206.04664.pdf
1.1 背景和动机
在 NLP 领域,缩放模型容量和数据大小使得过去几年的语言模型取得了显著的改进,其背后的方法是掩码图像建模 (Masked Image Modeling, MIM),这个方法取得成功的部分原因可能是:它能够从近乎无限量级的数据中获益。
在 CV 领域,由于缺乏有效的自监督方法,很多工作大多基于图像分类任务,巨大的打标签成本,以及标签有限的信息量限制了人们对视觉模型的缩放,从而使计算机视觉的进展大大落后于NLP领域。
由于 MAE 和 SimMIM 的诞生,掩码图像建模 (Masked Image Modeling, MIM) 的自监督视觉预训练方法在各种下游计算机视觉任务上令人印象深刻的性能。鉴于其与 NLP 中主要的预训练方法 Masked Language Modeling, MLM 高度相似,本文希望掩模图像建模能够提高视觉模型的缩放性能。具体来说,作者关注的是缩放能力的两个方面,即:模型的缩放和数据的缩放。
MIM 方法已经被证明能够很好地扩大模型的容量,但其从较大数据中获益的能力还尚不清楚。但是,MIM 方法究竟能否从大数据集中获益?这个问题至关重要,因为自监督学习的重要标志是能够利用几乎无限的数据,如果不能从更大的数据中受益,可能会阻碍掩模图像建模的未来潜力。
所以,本文系统地研究了不同模型大小和训练长度下 MIM 方法的数据缩放能力。通过大量实验本文发现:
-
掩模图像建模也需要更大的数据: 作者观察到,大模型使用相对较小的数据训练时会过拟合,验证集损失增加。过拟合问题将导致微调性能下降。
-
训练时间的问题: 通过掩模图像建模训练的大模型,可以通过更长的训练,从更多的数据中受益。当训练长度较短时,使用大数据集和小数据集的性能差异不显著。但是如果是训练得比较充分,更多的数据训练得到的模型表现就更好了。此外,随着数据量的增加,大模型的微调性能饱和速度比小模型慢。
-
预训练中的验证集的损失是衡量模型在多个任务上的微调效果的良好指标: 作者观察到预训练时的 validation loss 和多个任务的微调性能之间存在很强的相关性。这一发现表明,验证集的损失是衡量模型训练程度的一个很好的指标,借助它可以方便地评估模型适不适合下游任务,而无需再微调,这样可以节约评估的开销。
这些结果表明,掩码图像建模 (MIM) 不仅具有模型缩放的能力,也同样具有数据缩放的能力。本文打破了以往研究中怀疑掩码图像建模不能从更多数据中受益的误解。我们希望这些发现将加深对掩模图像建模的理解。
1.2 掩码图像建模方法

1.3 模型架构
本研究使用 Swin Transformer V2[1] 作为视觉编码器。由于其通用性和可扩展性,作者在多个下游任务上评估了一系列模型大小的 SwinV2 模型 (参数数量范围从 ∼50M 到 ∼1B, FLOPs 范围从 ∼9G 到 ∼190G)。详细的模型规格如下图1所示。作者使用了一种新的变体 SwinV2-g (giant),其参数数量介于 SwinV2-L 和30亿参数的 SwinV2-G (Giant) 之间。
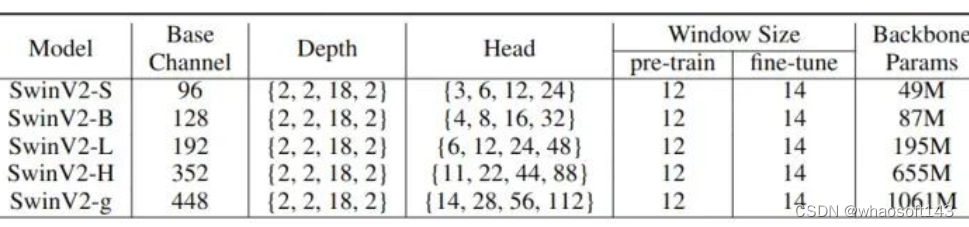
图1:本研究使用的模型架构
1.4 预训练数据集
为了研究数据大小对掩码图像建模的影响,作者构建了不同大小的数据集,使用 ImageNet-1K 和 ImageNet-22K 的训练集作为两个大规模的数据集,并随机抽取 ImageNet-1K 训练集中 10%、20%、50% 的图像作为较小的数据集。本研究中使用的所有预训练数据集的细节和统计如下图2所示。 图2:本研究使用的预训练数据集
图2:本研究使用的预训练数据集
1.5 预训练细节
所有实验训练的 iteration 数为 {125K, 250K, 500K},Batch Size 为2048,在预训练阶段,对所有模型使用相同的超参数,预训练的训练细节和超参数如下图3所示。由于实验数量较多,作者在预训练中对学习率使用 step scheduler。对于不同的 training ieration,前7/8是第1步,后1/8是第2步,二者的区别是学习率乘以0.1。本文使用与 SimMIM 相同的数据增强策略:Crop scale 为 [0.67,1],Resize ratio 为 [3/ 4,4 /3],随机翻转概率为0.5。
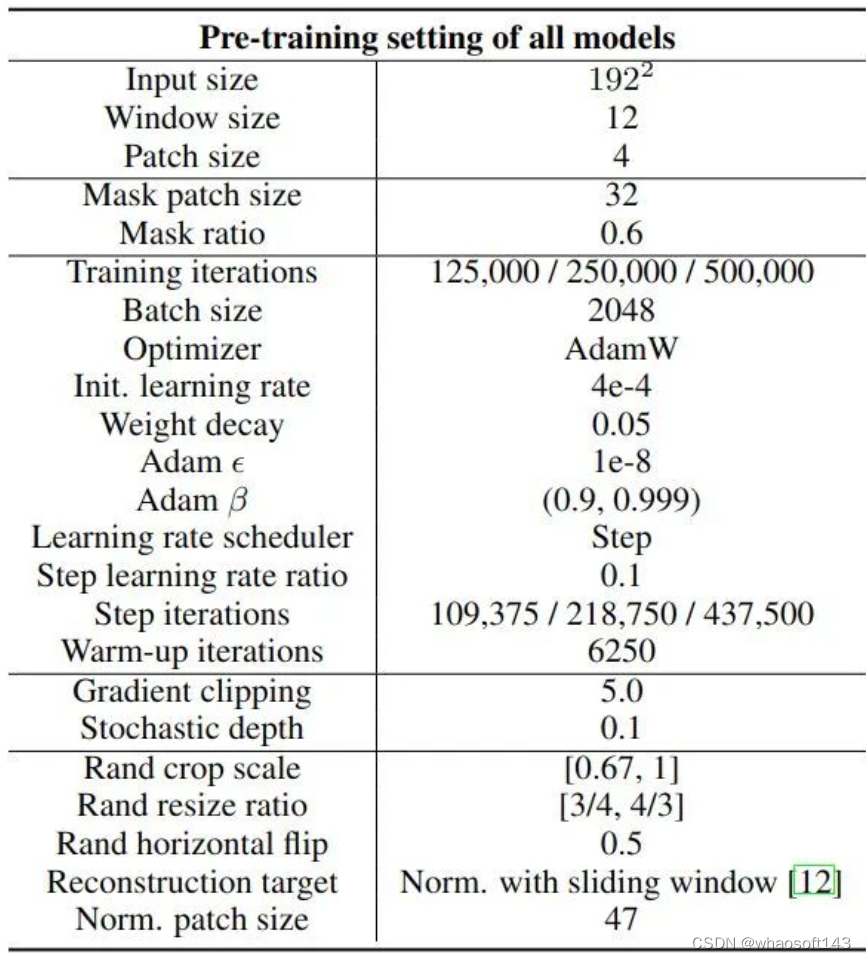
图3:预训练的训练细节和超参数
1.6 微调的下游任务
用于评估预训练模型的微调下游任务有:
ImageNet-1K 图像分类
训练超参数
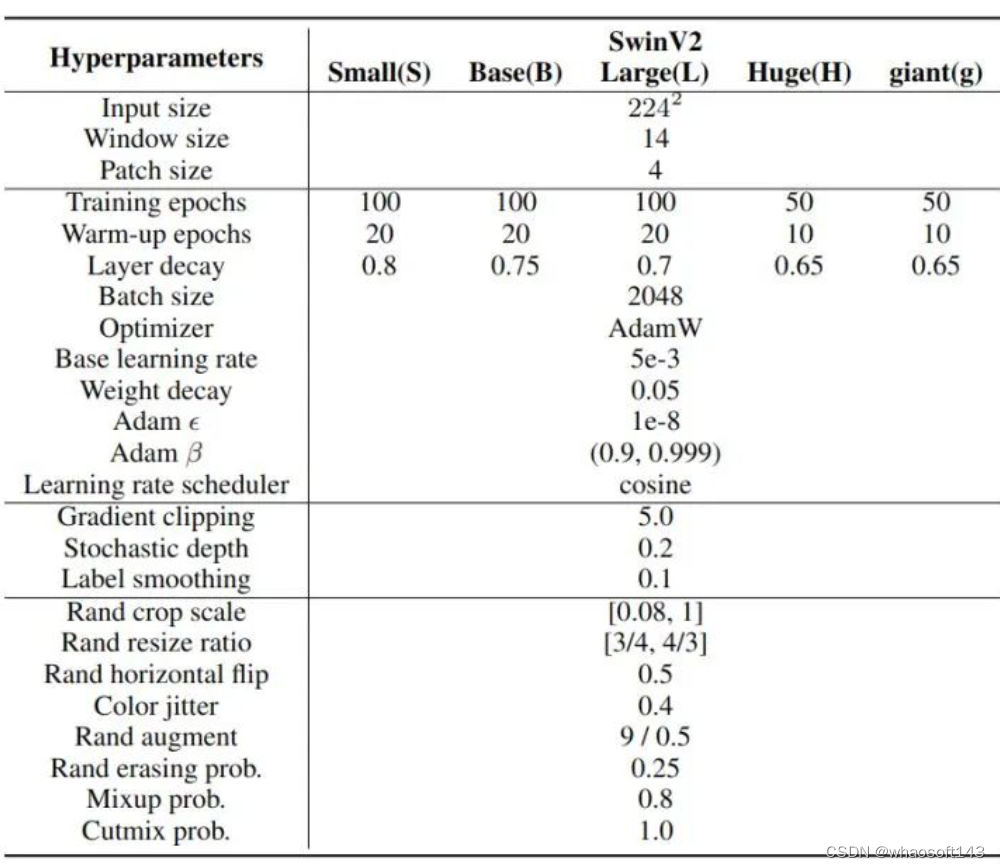 图4:ImageNet-1K 图像分类训练超参数
图4:ImageNet-1K 图像分类训练超参数
iNaturalist 2018 长尾细粒度图像分类数据集
训练超参数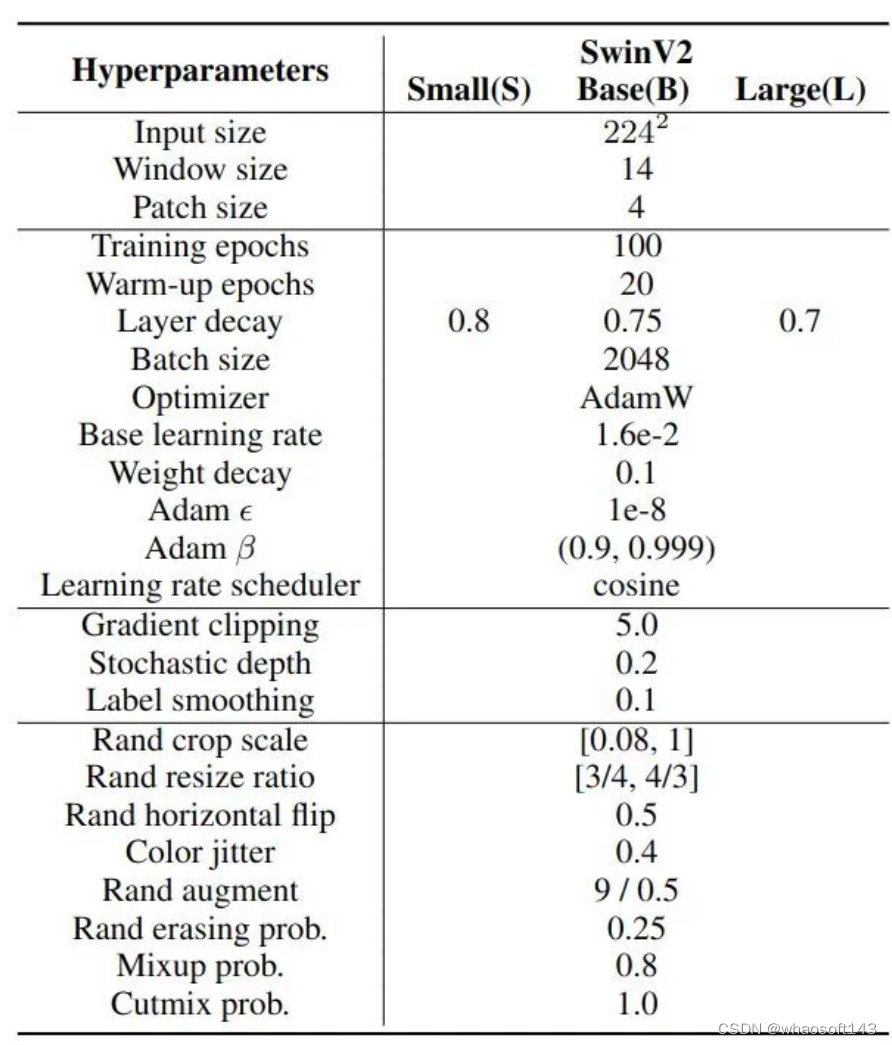 图5:iNaturalist 2018 长尾数据集图像分类训练超参数
图5:iNaturalist 2018 长尾数据集图像分类训练超参数
COCO 目标检测和实例分割
训练超参数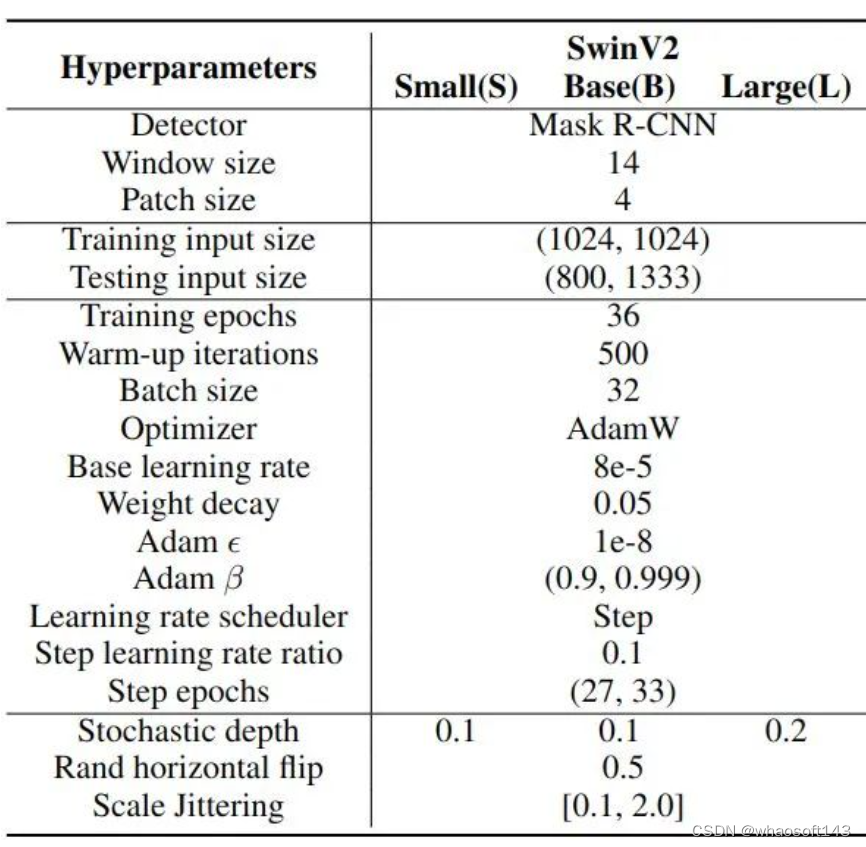 图6:COCO 目标检测和实例分割
图6:COCO 目标检测和实例分割
ADE20K 语义分割
训练超参数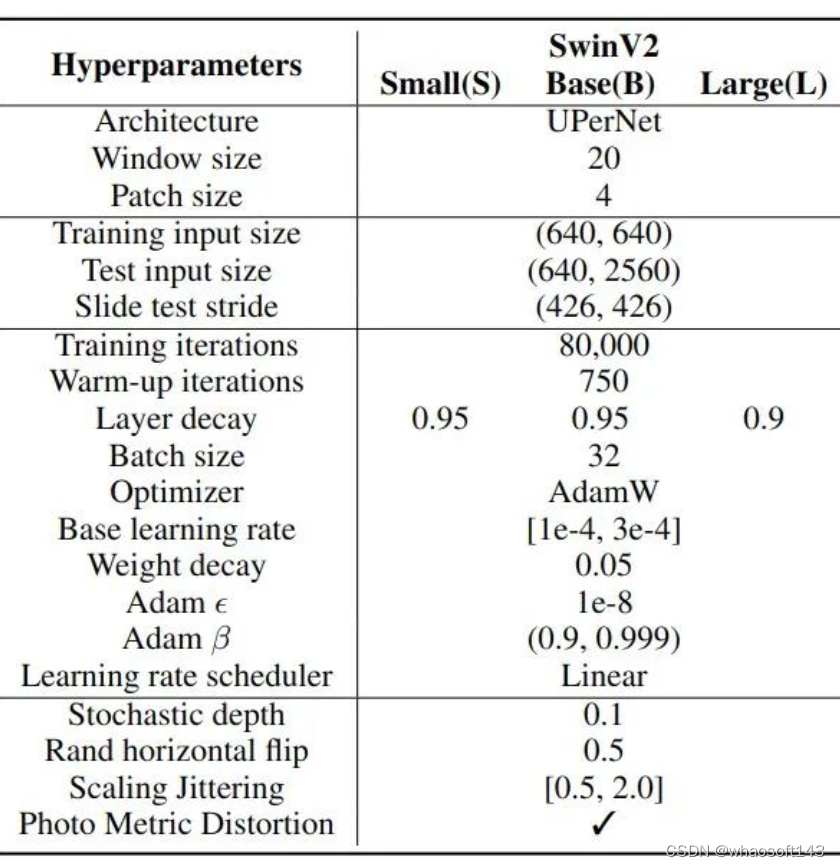 图7:ADE20K 语义分割训练超参数
图7:ADE20K 语义分割训练超参数
1.7 实验结果1:MIM 对大型数据集的要求仍然很高
如下图8,9所示是 training loss 和 validation loss 与 ImageNet-1K 微调精度之间的关系。
 图8:不同模型,数据规模,和训练长度下的 training loss,validation loss,ImageNet-1K 微调精度和训练长度之间的关系,更大的圆点代表更大的模型
图8:不同模型,数据规模,和训练长度下的 training loss,validation loss,ImageNet-1K 微调精度和训练长度之间的关系,更大的圆点代表更大的模型
从图8可以看出,随着训练成本的增加,部分模型的 training loss 显著下降,但是 validation loss 显著上升,即使使用 ImageNet-1K 的 50% 的图像,也存在过拟合现象。从图9可以看出,过拟合导致的微调性能显著下降。
 图9:不同模型,数据规模,和训练长度下的 training loss,validation loss,ImageNet-1K 微调精度和训练长度之间的关系
图9:不同模型,数据规模,和训练长度下的 training loss,validation loss,ImageNet-1K 微调精度和训练长度之间的关系
此外,作者在下图10中给出了每个模型的最佳微调性能。可以发现,当使用小数据集进行训练时,大型模型的表现甚至不如小型模型。例如,SwinV2-H 在 IN1K (20%) 的最佳 top-1 精度为84.4,比 SwinV2-L 的最佳性能差了0.3。而且,使用更多的数据可以获得更好的性能。这些观察结果表明,MIM 的预训练方法也是需要大数据集的。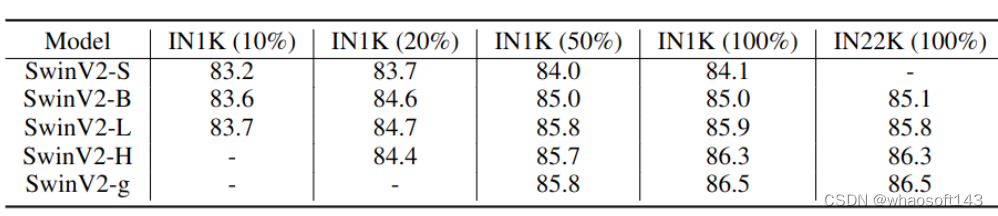
图10:每个模型的最佳 ImageNet-1K 微调性能
1.8 实验结果2:训练长度也很重要,较大的模型可以在较长的训练长度下从更多的数据中受益
如上图9的第3行所示,通过比较不同数据大小预训练的模型的性能,作者发现:与较小的模型相比,大模型的微调性能随着数据大小的增加而饱和得更慢。例如,在 IN1K (50%) 上预训练的 SwinV2-S 模型具有与在 IN1K (100%) 上预训练模型非常相似的微调性能。相比之下,在 IN1K (50%) 和 IN1K (100%) 上预训练的 SwinV2-H 模型之间的性能差异接近0.5,这对于 ImageNet-1K 分类来说是一个显著的差距。
而且,在较短的训练长度下,使用更多数据对预训练的改善并不显著。比如,训练 500K iteration,SwinV2-H 在 IN1K (50%) 和 IN1K (100%) 上的实验结果存在明显的性能差距。但是当训练 120K iteration 时,SwinV2-H 在 IN1K (50%) 和 IN1K (100%) 上的实验结果的差距小于 0.1。这一观察表明,虽然更大的模型可以从更多的数据中受益,但训练长度也必须同时增加。
1.9 实验结果3:其他任务的验证
除了 ImageNet-1K 图像分类,作者还评估了 MIM 预训练的 SwinV2-S, SwinV2-B 和 SwinV2-L 在 iNaturalist 2018 细粒度图像分类,ADE20K 语义分割和 COCO 目标检测和实例分割上的效果。如下图11所示,随着训练成本的增加,一些模型显示出过拟合的迹象。除此之外,如图12,13,14所示,随着数据量的增加,较小的模型迅速达到饱和,而较大的模型在经过足够的训练后,可以从更多的数据中持续受益。这些结果表明,在 ImageNet-1K 上得出的结论广泛适用于其他视觉任务。
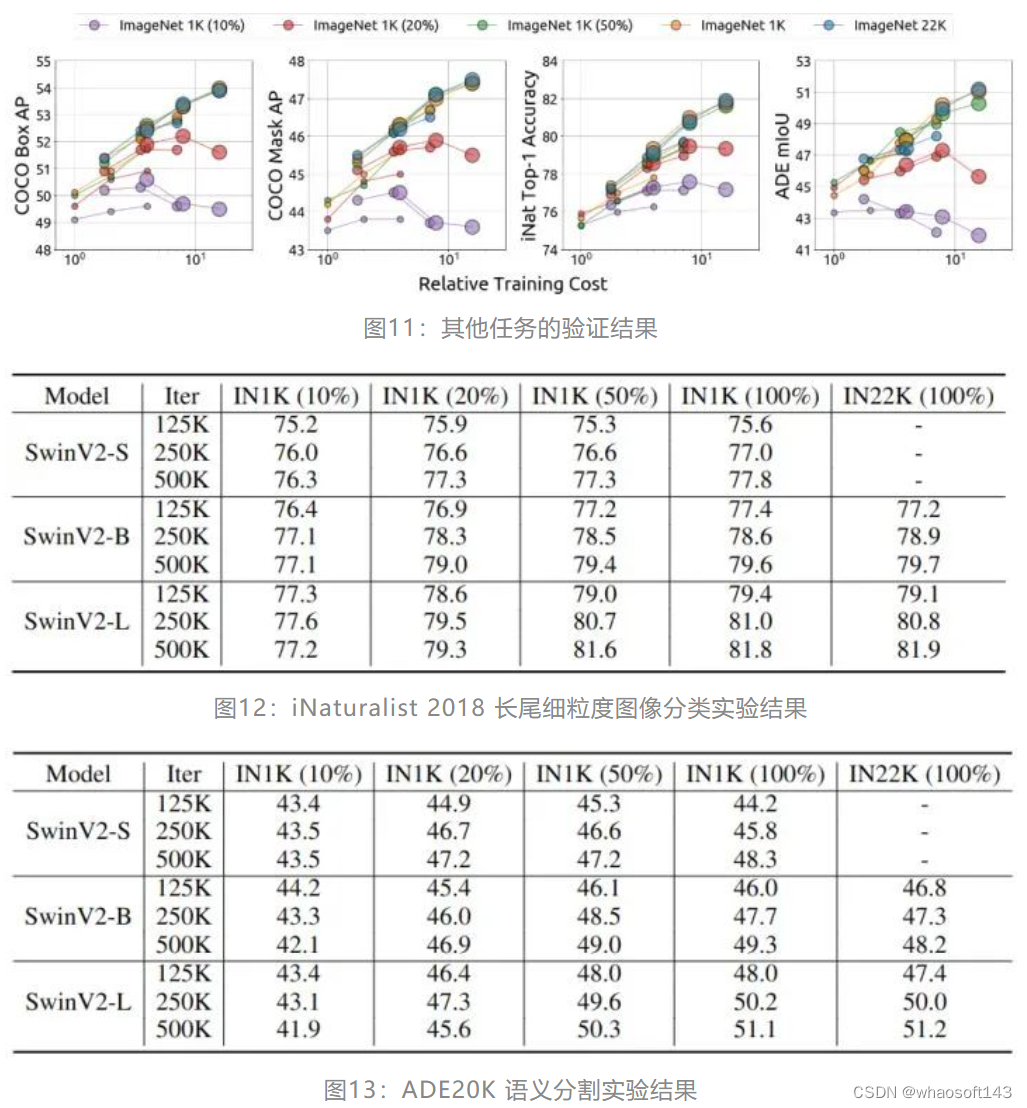
 1.10 预训练损失和微调性能之间的关系
1.10 预训练损失和微调性能之间的关系
作者还探索了 MIM 训练中的预训练的损失是否是其微调性能的良好指标。如下图15所示是所有模型的 training 和 validation loss 曲线。
对于过拟合模型 (绿圈),training loss 与下游任务的微调性能之间的相关性为负,validation loss 与下游任务的微调性能之间的相关性为正。
对于非过拟合模型 (红圈),training loss 与下游任务的微调性能之间的相关性为负,validation loss 与下游任务的微调性能之间的相关性为正。training loss 和 validation loss 与下游任务的微调性能之间的相关性都为正。
以上结果说明在多个任务上,预训练中的 validation loss 是衡量模型在多个任务上的微调效果的良好指标。
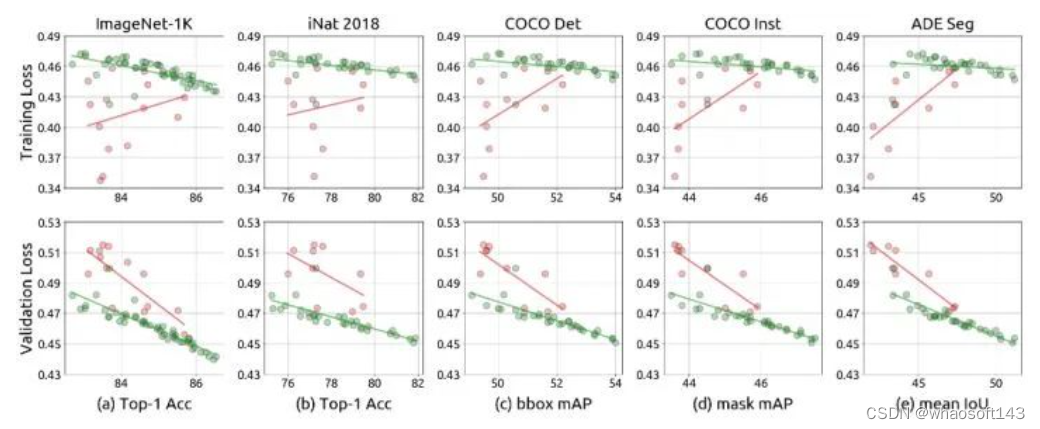 图15:预训练损失和微调性能之间的关系
图15:预训练损失和微调性能之间的关系
以上发现的量化指标如图16所示。图16表格中的数据是5种下游任务的 Pre-training losses 和微调结果的 Pearson correlation coefficients。可以看到,对于图16的5种下游任务,预训练的 validation loss 都和下游任务微调性能的负相关性的 Pearson correlation 较低。

图16:5种下游任务的 Pre-training losses 和微调结果的 Pearson correlation coefficients
总结 whaosoft aiot http://143ai.com
本文是一篇实验探究类的工作,研究的问题是自监督学习 (掩码图像建模类方法) 的数据缩放问题,系统地探究了不同模型大小和训练长度下掩模图像建模的数据缩放能力。作者证明了 MIM 的自监督学习方法不仅仅是模型可扩展的,也是数据可扩展的。这挑战了以往文献的结论,即 MIM 可能不需要大的数据集。这背后的原因是他们忽略了一个关键因素,即训练长度。除此之外,还观察到 MIM 的 validation loss 与微调性能之间存在很强的相关性。这一观察结果表明,validation loss 可以被认为是评估预训练模型的一个很好的代理指标,所以这种观察使我们能够对我们预训练的模型进行廉价的预评估,而不必每次都在下游任务上进行评估,因为太昂贵。