前言
随着项目不断迭代,使用人数的不断增加。数据库中某些表数据正在逐步膨胀,往单表千万迅速靠拢。所以最近领导也在考虑做一下分库分表,写此文章记录下来。
一、什么是分库分表?
分库:从单个数据库拆分成多个数据库的过程,将数据散落在多个数据库中。
分表:从单张表拆分成多张表的过程,将数据散落在多张表内。
二、为什么分库分表?
随着平台的业务发展,数据可能会越来越多,甚至达到亿级。以MySQL为例,单库数据量在5000万以内性能比较好,超过阈值后性能会随着数据量的增大而明显降低。单表的数据量超过1000w,性能也会下降严重。这就会导致查询一次所花的时间变长,并发操作达到一定量时可能会卡死,甚至把系统给拖垮。
三、怎么选择分库分表策略?
| 切分方案 | 解决的问题 |
|---|---|
| 只分库不分表 | 数据库读?写QPS过高,数据库连接数不足 |
| 只分表不分库 | 单表数据过大,存储性能遇到瓶颈 |
| 即分库又分表 | 连接数不足+数据量过大引起的存储性能瓶颈 |
四、分库分表方式及带来的问题?
分库分表有效的缓解了大数据、高并发带来的性能和压力,也能突破网络IO、硬件资源、连接数的瓶颈,但同时也带来了一些问题。
4.1、事务一致性问题
由于分库分表把数据分布在不同库甚至不同服务器,不可避免会带来分布式事务问题,我们需要额外编程解决该问题。
4.2、跨节点join
在没有进行分库分表前,我们检索商品时可以通过以下SQL对店铺信息进行关联查询:
SELECT p.*,s.[店铺名称],s.[信誉]
FROM [商品信息] p
LEFT JOIN [店铺信息] s ON p.id = s.[所属店铺]
WHERE...ORDER BY...LIMIT...
但经过分库分表后,[商品信息]和[店铺信息]不在一个数据库或一个表中,甚至不在一台服务器上,无法通过sql语句进行关联查询,我们需要额外编程解决该问题。
4.3、跨节点分页、排序和聚合函数
跨节点多库进行查询时,limit分页、order by排序以及聚合函数等问题,就变得比较复杂了。需要先在不同的分片节点中将数据进行排序并返回,然后将不同分片返回的结果集进行汇总和再次排序。例如,进行水平分库后的商品库,按ID倒序排序分页,取第一页:
以上流程是取第一页的数据,性能影响不大,但由于商品信息的分布在各数据库的数据可能是随机的,如果是取第N页,需要将所有节点前N页数据都取出来合并,再进行整体的排序,操作效率可想而知,所以请求页数越大,系统的性能也会越差。
在使用Max、Min、Sum、Count之类的函数进行计算的时候,与排序分页同理,也需要先在每个分片上执行相应的函数,然后将各个分片的结果集进行汇总和再次计算,最终将结果返回。
4.4、主键避重
在分库分表环境中,由于表中数据同时存在不同数据库中,主键值平时使用的自增长将无用武之地,某个分区数据库生成的ID无法保证全局唯一。因此需要单独设计全局主键,以避免跨库主键重复问题。
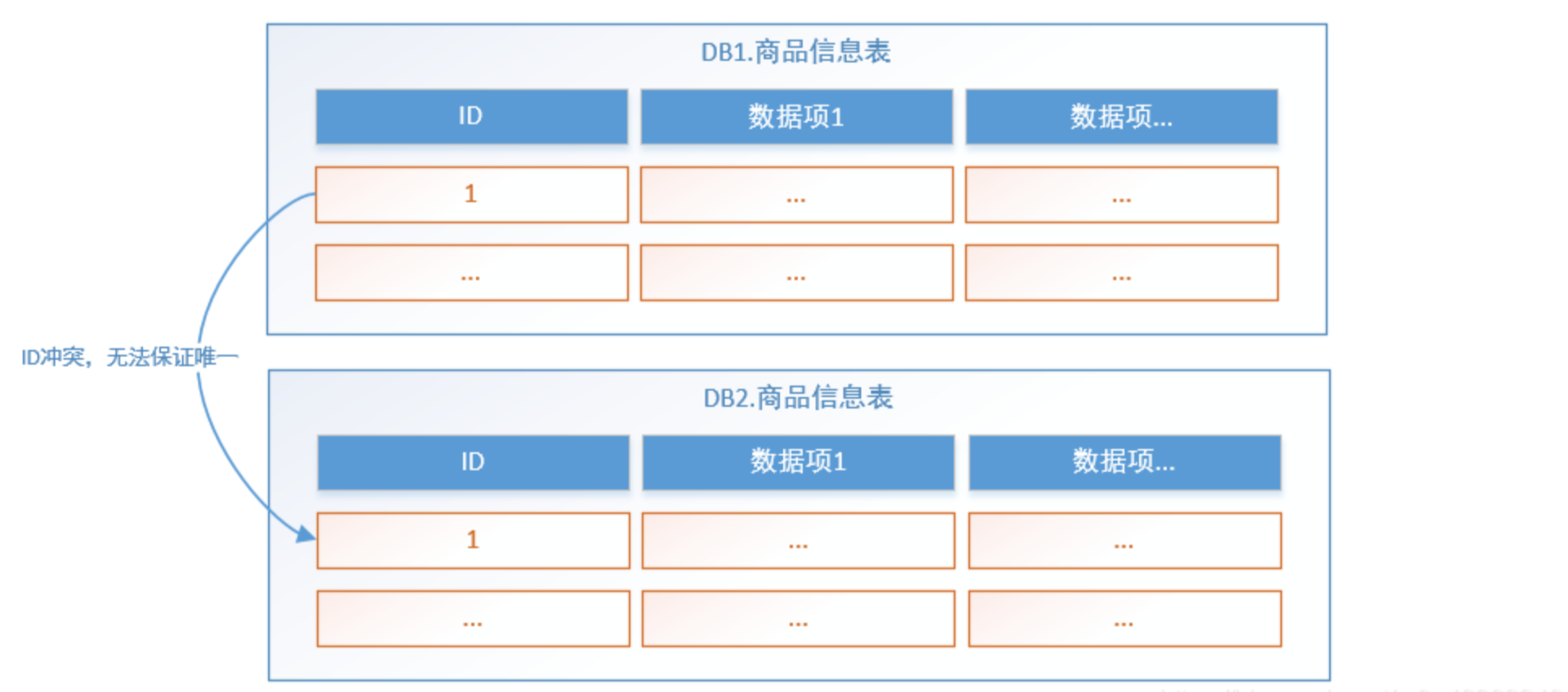
由于分库分表之后,数据被分散在不同的服务器、数据库和表中。因此,对数据的操作也就无法通过常规方式完成,并且它还带来了一系列的问题。我们在开发过程中需要通过一些中间件解决这些问题,市面上有很多中间件可供我们选择,其中Sharding-JDBC和mycat较为流行。
五、使用分库分表组件帮我们解决一些问题
分库分表的技术方案总体上来讲分为两大类:应用层依赖类中间件、中间层代理类中间件。
我们选择技术方案时主要考虑的是,开源、开发成本、学习成本、技术复杂度,技术使用人数,参考资料的多少等方面。
由于我本人也不是每样技术都有用过。所以在这里只是在能力范围内做一个初步了解,并进行选型。目前这些组件对于分库分表的一些主要问题都有相对完善的解决方案,区别的只是一些细节的问题。又结合目前项目所在只需要轻量级的分库分表。所以我还是比较偏向成本较低,复杂度较低的方案。
目前市面上使用较多的是,mycat及sharding-jdbc。mycat属于中间层代理类中间件、sharding-jdbc属于应用层依赖类中间件
5.1. Atlas
奇虎360
关键词:分库分表 Atlas
百度为您找到相关结果约707,000个
中间层代理类中间件
https://github.com/Qihoo360/Atlas
github上最后维护时间为4年前
-
优点
- 实现了读写分离(并通过hint/master/可强制⾛主库,并且加⼊了权重配置可进⾏读的负载均衡
- ⾃⾝维护了⼀套连接池,减少了创建连接带来的性能消耗
- ⽀持DB动态上下线,⽅便横向扩展
- ⽀持ip过滤,实现了简单的权限控制
- 可记录所有sql,实现了简单的审计功能
-
缺点
- 使⽤atlas⽐直连DB,性能损耗⼤概是30%-35%左右
- 使⽤atlas⽐直连DB,响应时间⼤概是直连DB的1.5~2倍
- 对分表的⽀持不是太好,不支持不同库间分表
- atlas配置暂时不⽀持配置参数的动态加载,如果修改了配置需要重启atlas,这可能会对业务有⼀点的影响(不过⼀般可以做ha或者业务低峰进⾏重启,这个问题不是特别迫切)总的来说作为⼀款开源mysql proxy,atlas总体表现还是不错的,持续压测3天都⽐较稳定,只是对分表的⽀持不是太好(⽐如不⽀持基于时间的分表模式),⼀般没有太⾼并发和对响应时间严格要求的业务可以考虑尝试使⽤
5.2. Cobar
阿里
关键词:分库分表 Cobar
百度为您找到相关结果约936,000个
中间层代理类中间件
https://github.com/alibaba/cobar/
github上最后维护时间为3年前
槽点貌似很多,讲不完哈哈
https://www.modb.pro/db/175242
5.3. TDDL
阿里
关键词:分库分表 TDDL
百度为您找到相关结果约1,080,000个
应用层依赖类中间件
https://github.com/alibaba/tb_tddl
github上TDDL处于停滞状态,应该是部分功能不开源了吧。
TDDL 必须要依赖 diamond 配置中心( diamond 是淘宝内部使用的一个管理持久配置的系统,目前淘宝内部绝大多数系统的配置)
5.4. heisenberg
百度
关键词:分库分表 heisenberg
百度为您找到相关结果约74,900个
中间层代理类中间件
资料少之又少,不考虑。
5.5. Oceanus
58同城
关键词:分库分表 Oceanus
百度为您找到相关结果约118,000个
https://github.com/wuba/Oceanus
github上最后维护时间为3年前
资料较少,不考虑。
5.6. OneProxy
原支付宝首席架构师楼方鑫开发
关键词:分库分表 OneProxy
百度为您找到相关结果约139,000个
应该是不开源的
5.7. vitess
YouTube
关键词:分库分表 vitess
百度为您找到相关结果约177,000个
中间层代理类中间件
https://github.com/vitessio/vitess
github当前活跃
Vitess是一个用于部署、扩展和管理大型MySQL实例集群的数据库解决方案。是开源的,在github上有很多星星,但是国内的应用较少,资料不多。技术架构复杂,这位更是重量级。
5.8. TSharding
蘑菇街
关键词:分库分表 TSharding
百度为您找到相关结果约100,000个
https://github.com/baihui212/tsharding
github上最后维护时间为5年前
应该也是不开源了
资料少之又少,不考虑
5.9. dal
携程
关键词:分库分表 dal
百度为您找到相关结果约315,000个
应用层依赖类中间件
https://github.com/ctripcorp/dal
github当前活跃,提供部分教程及demo(需要科学上网)
开源范围包括代码生成器,Java客户端和C#客户端。
国内资料少,需要科学上网。
5.10. zdal
支付宝
关键词:分库分表 zdal
百度为您找到相关结果约30,600个
中间层代理类中间件
国内资料少,应该不开源。
5.11.MyCat
基于cobar社区开源
关键词:分库分表 MyCat
百度为您找到相关结果约9,030,000个
中间层代理类中间件
http://mycatone.top/
社区当前活跃,无需科学上网
资料很多也开源,可以考虑。
5.11.1不支持项
-
DDL语句
- 不支持修改拆分键
- 支持物理库的视图视为普通表来使用
- 仅普通表支持外键
- DML语句
-
DELETE语句
- 不支持涉及分布式运算的子查询。
- 不支持多表delete。
-
UPDATE语句
- 不支持涉及分布式运算的子查询。
- 不支持多表update。
-
SELECT语句
- 对于for update语句会把sql中出现的表都加锁。
- 具体是行锁还是表锁要看sql语句。
- 不支持SELECT INTO OUTFILE。
-
SET语句
- 支持SET SESSION级别的变量,但是不能被预处理语句引用变量,只有autocommit变量具有正确语义
- 不支持SET GLOBAL级别的变量
- 不支持SET USER级别的变量
-
SHOW语句
-
所有SHOW语句都视为兼容性SQL进行处理,发往prototype节点处理,所以不具备分布式语义高级功能
-
不支持用户自定义数据类型(改代码), 自定义函数(改代码)
-
支持物理视图,但是不支持Mycat中的逻辑视图
-
有限支持存储过程
-
不支持游标
-
不支持触发器
-
5.12.Sharding-jdbc
当当开源,已加入apache豪华套餐
关键词:分库分表 Sharding-jdbc
百度为您找到相关结果约4,240,000个
应用层依赖类中间件
https://shardingsphere.apache.org/
社区当前活跃,无需科学上网
资料很多也开源,可以考虑。
更多参考之前写的:分库分表 Sharding-JDBC
5.12.1不支持项
-
DataSource 接口
- 不支持 timeout 相关操作。
-
Connection 接口
- 不支持存储过程,函数,游标的操作;
- 不支持执行 native SQL;
- 不支持 savepoint 相关操作;
- 不支持 Schema/Catalog 的操作;
- 不支持自定义类型映射。
-
Statement 和 PreparedStatement 接口
- 不支持返回多结果集的语句(即存储过程,非 SELECT 多条数据);
- 不支持国际化字符的操作。
-
ResultSet 接口
- 不支持对于结果集指针位置判断;
- 不支持通过非 next 方法改变结果指针位置;
- 不支持修改结果集内容;
- 不支持获取国际化字符;
- 不支持获取 Array。
-
JDBC 4.1
- 不支持 JDBC 4.1 接口新功能。
六、详细比较
| 主要指标 | Sharding-jdbc | Mycat |
|---|---|---|
| ORM支持 | 适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC | 任意 |
| 事务 | 自带XA、两(三)阶段事务、柔性事务BASE(最终一致) | XA事务 |
| 分库 | 支持 | 支持 |
| 分表 | 支持 | 支持 |
| 开发 | 集成springboot较好,代码入侵中(需要写些配置类等) | 开发成本小,代码入侵小 |
| 所属公司 | 当当网开源,加入apache | 基于阿里Cobar二次开发,社区维护 |
| 数据库支持 | 支持任意实现 JDBC 规范的数据库,目前支持 MySQL,PostgreSQL,Oracle,SQLServer 以及任何可使用 JDBC 访问的数据库 | Mysql、Oracle、 SQL Server、DB2、mongodb |
| 活跃度 | 活跃度高 | 社区活跃度很高,一些公司已在使用 |
| 监控 | 有 | 有 |
| 读写分离 | 支持 | 支持 |
| 资料 | 资料少、github、官网、网上讨论贴 | 资料多,github、官网、Q群、书籍 |
| 运维 | 维护成本低 | 维护成本高 |
| 限制 | 部分JDBC方法不支持、SQL语句限制 | SQL语句限制 |
| 连接池 | 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, HikariCP 等 | 无要求 |
| 配置难度 | 一般 | 复杂 |
总结
挑选了两个使用最多的进行了比较,综合来看的话感觉还是Sharding-jdbc更省事一些,无需部署中间件,只通过引入jar包进行分库分表操作,省去一些事情。而且多一个中间件的话系统稳定性也会降低了。对与目前来说,只需要轻量级的分库分表,功能不需要太多,所以还是选择Sharding-jdbc合适些。