一、Kettle 实战案例
上篇文章对 Kettle 的查询、连接、统计、脚本算子进行了介绍,对 Kettle 的大部分算子都应该有了相应的了解,下面我们基于 Kettle 实战案例,拉取 CSDN 博客列表的全部数据,存放至 Excel 文件中。
实验之前先看下 CSDN 列表调用的哪个接口:
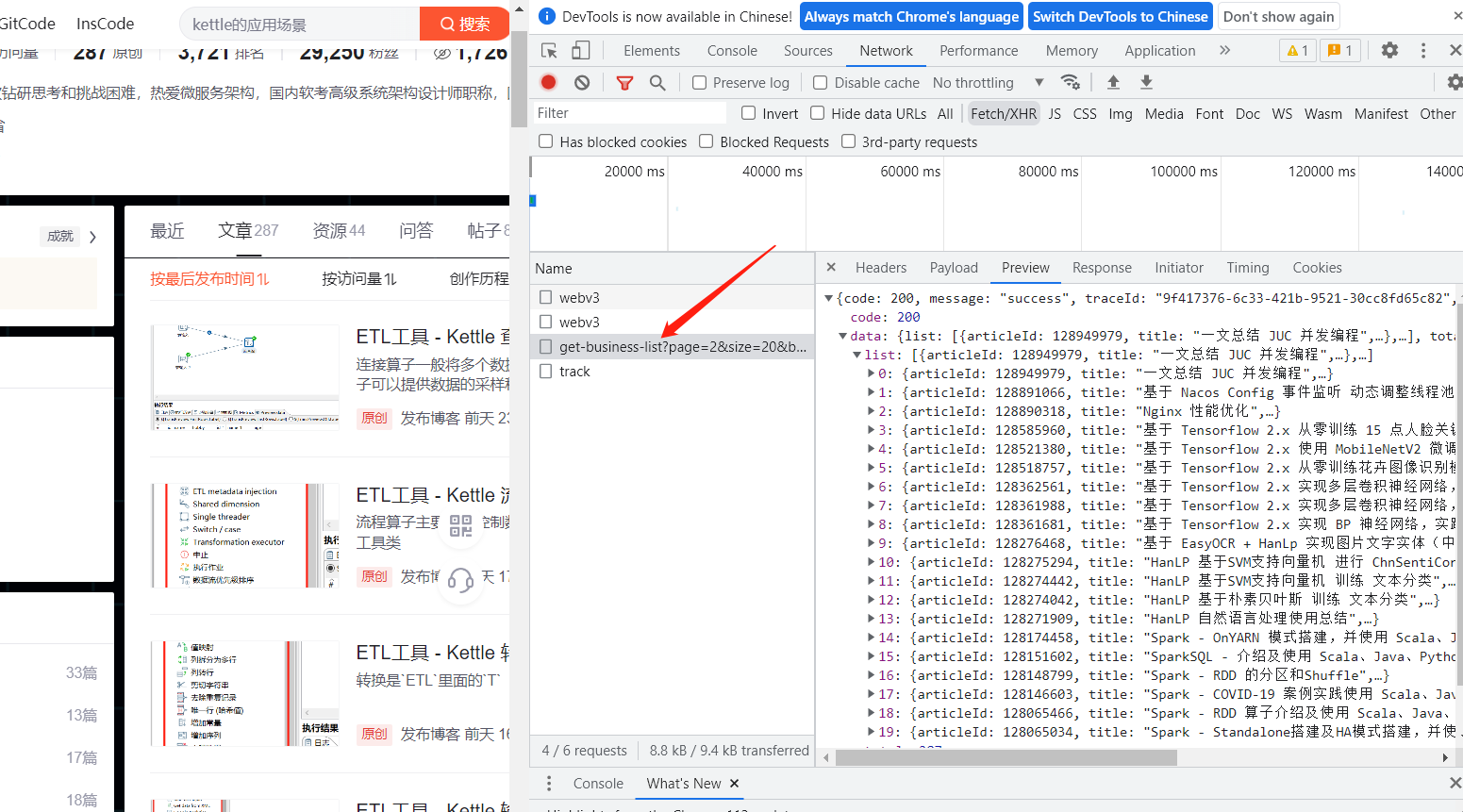
就是这个
https://blog.csdn.net/community/home-api/v1/get-business-list?page=1&size=20&businessType=blog&orderby=&noMore=false&year=&month=&username=qq_43692950
其中 page 参数也就是当前页,size 一页的大小,如果我们要获取全部的数据,肯定需要对这两个参数进行修改。
下面看下返回的结构:
{
"code": 200,
"message": "success",
"traceId": "b1e8ccb0-2e39-4834-bacd-b52a260bb521",
"data": {
"list": [
{
"articleId": 130450076,
"title": "ETL工具 - Kettle 查询、连接、统计、脚本算子介绍",
"description": "连接算子一般将多个数据集通过关键字进行连接,类似 `SQL` 中的连接操作,统计算子可以提供数据的采样和统计功能,脚本算子可以通过程序代码完成一些复杂的操作",
"url": "https://xiaobichao.blog.csdn.net/article/details/130450076",
"type": 1,
"top": false,
"forcePlan": false,
"viewCount": 313,
"commentCount": 0,
"editUrl": "https://editor.csdn.net/md?articleId=130450076",
"postTime": "2023-04-30 23:12:13",
"diggCount": 1,
"formatTime": "前天 23:12",
"picList": [
"https://img-blog.csdnimg.cn/2e817e14046f4cba9663c89978198f12.png"
]
}
],
"total": 287
}
}
先不考虑分页的话我们怎么拿到数据呢,首先第一步可以通过 REST client 工具访问该接口获取到数据,然后根据拿到的结果使用 JSON input 进行解析,最后就可以输出到 Excel 文件中了。
那接口是分页的设计,我们怎么获取全部数据呢,下面有三个方案:
- 直接给个很大的
size,数据少的情况可以实现不灵活。 - 每次都获取下一页,递归的形式直到获取的数据为空时停止。
- 根据接口中的
total参数,计算出总页数,然后递归的形式对页数进行+1,直到等于最大页。
第一种方案不太灵活,下面我们对二三两个方案进行实践下:
二、递归直到获取数据为空时停止 方案
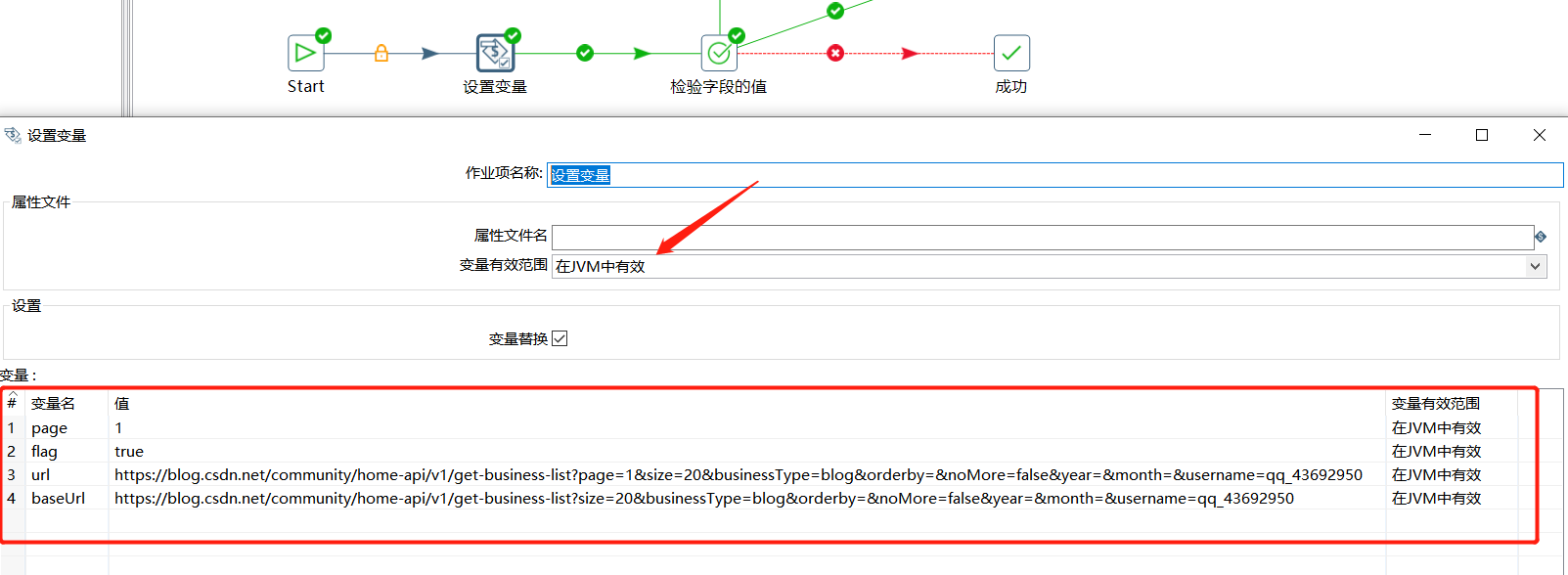
这里我们定义四个变量,分别如下:
| 变量 | 初始值 | 说明 |
|---|---|---|
| page | 1 | 第几页 |
| flag | true | 是否获取数据不为空 |
| url | https://blog.csdn.net/community/home-api/v1/get-business-list?page=1&size=20&businessType=blog&orderby=&noMore=false&year=&month=&username=qq_43692950 |
每次请求的url |
| baseUrl | https://blog.csdn.net/community/home-api/v1/get-business-list?size=20&businessType=blog&orderby=&noMore=false&year=&month=&username=qq_43692950 |
去除分页参数后的url |
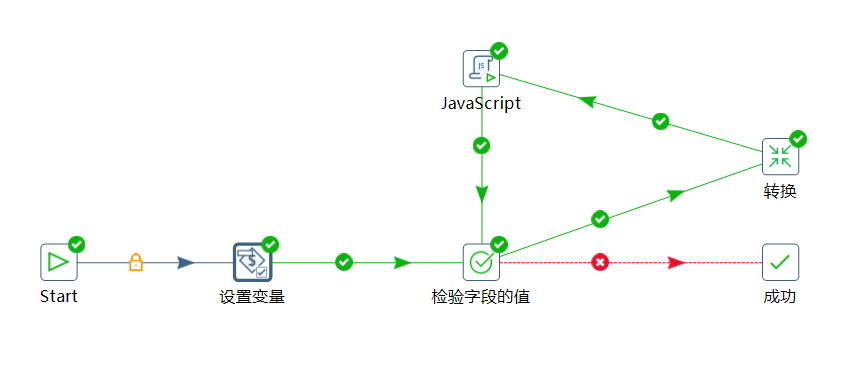
先看一下总的作业设计图:
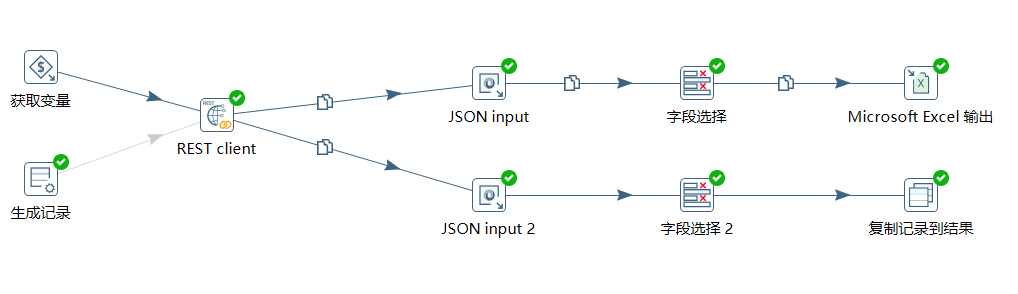
转换设计图:
2.1 作业设计过程
使用设置变量添加上面几个变量信息:
这里我们主要通过 flag 判断是否需要进行下一步,所以使用检验字段的值判断 flag 是否为 true :
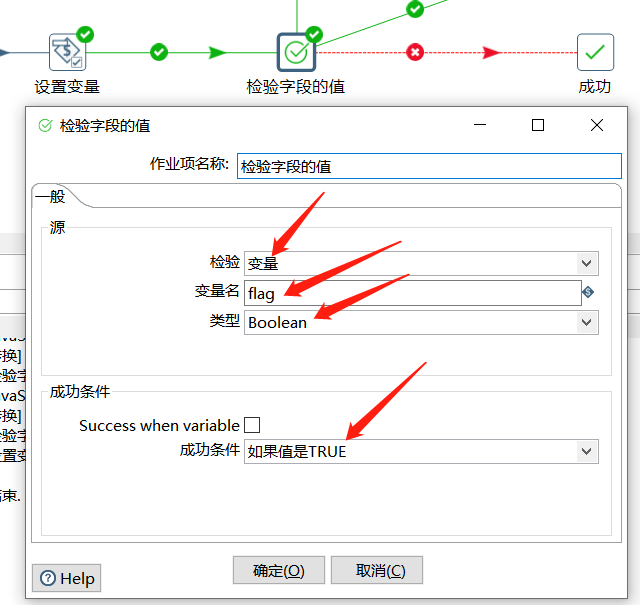
如果为 true 的话就执行转化进行具体的获取数据写数据的操作,这里转换返回的结果把接口返回的 $.data.list 值返回出来:
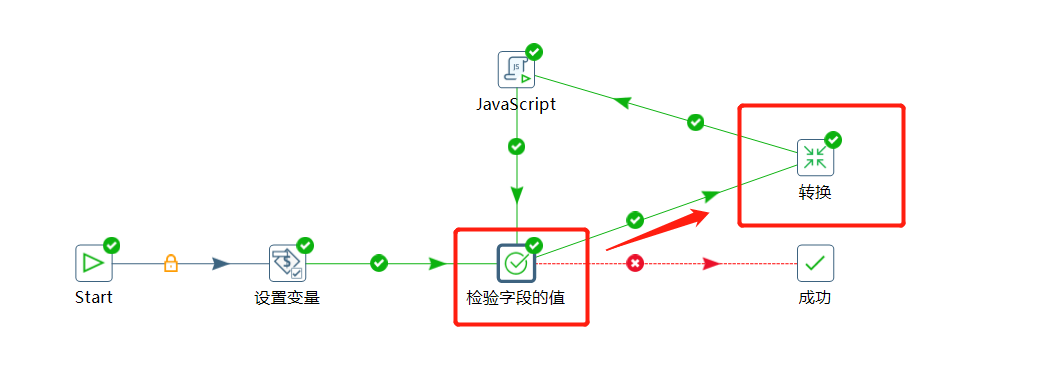
如果转换的结果是 [] 就表示获取不到数据了,下面使用 JS 脚本将 flag 的值更新为 false ,下面流转到检验字段的值由于 flag 为 false 直接流转到成功结束作业了。
如果转换的结果不是 [] ,那表示还有数据,对 page 进行 +1 操作,然后通过 baseUrl 拼接一个完整的访问接口,替换到原来的 url 变量,实现逻辑如下:
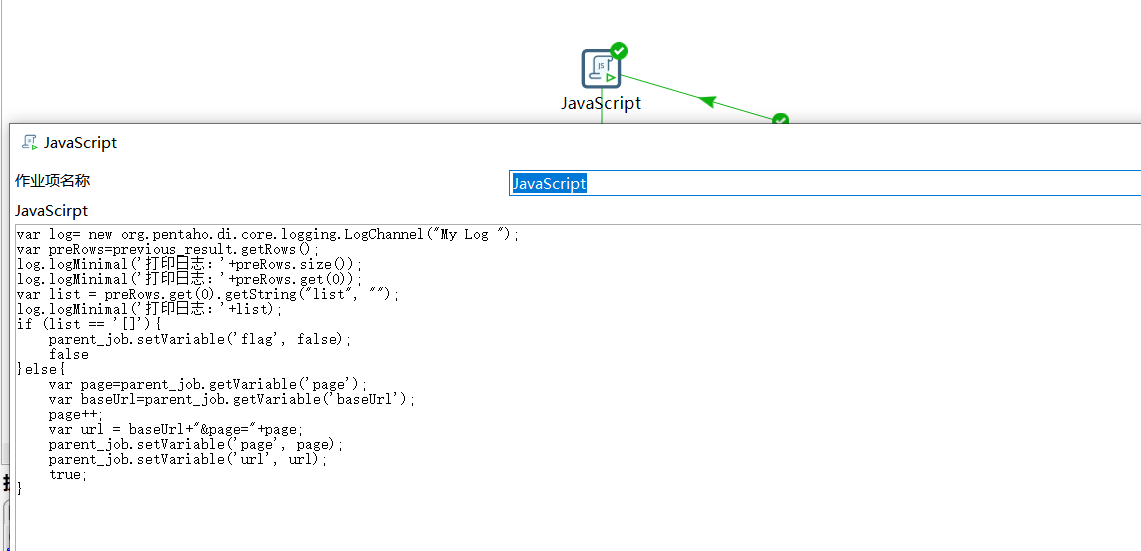
var log= new org.pentaho.di.core.logging.LogChannel("My Log ");
var preRows=previous_result.getRows();
log.logMinimal('打印日志:'+preRows.size());
log.logMinimal('打印日志:'+preRows.get(0));
var list = preRows.get(0).getString("list", "");
log.logMinimal('打印日志:'+list);
if (list == '[]'){
parent_job.setVariable('flag', false);
false
}else{
var page=parent_job.getVariable('page');
var baseUrl=parent_job.getVariable('baseUrl');
page++;
var url = baseUrl+"&page="+page;
parent_job.setVariable('page', page);
parent_job.setVariable('url', url);
true;
}
2.2 转换设计过程
在转换中首先获取到作业中设定的 url 变量:
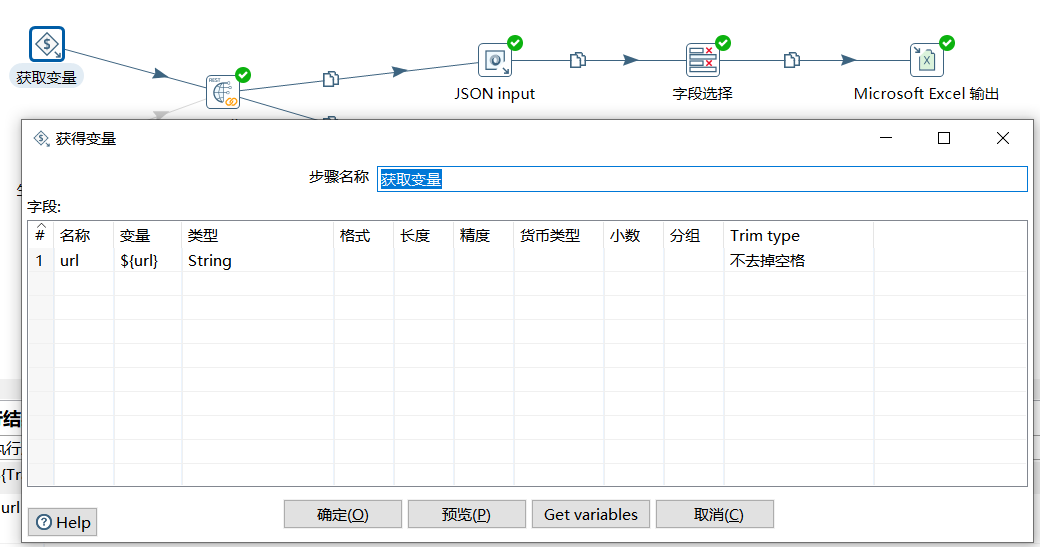
下面使用 REST client 请求接口获取到 JSON 结果集:
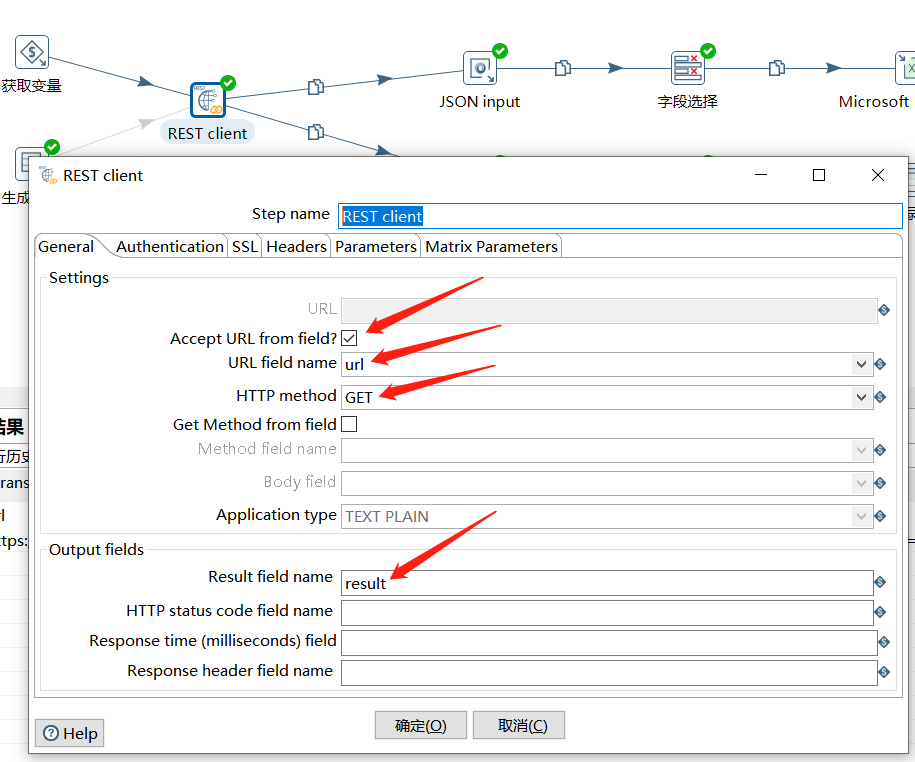
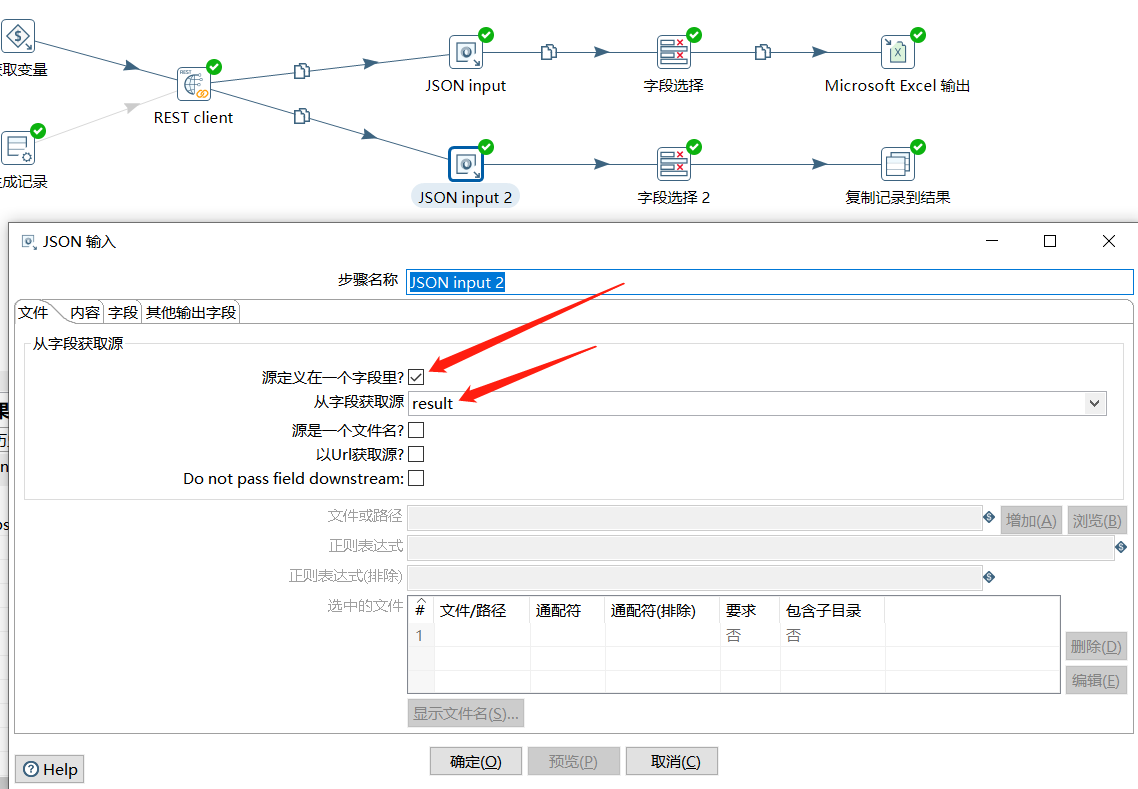
下面使用 JSON input 对结果集进行解析,这里分了两个链路,上面的解析 $.data.list 中具体的字段信息,然后存入到 Excel 中,下面的直接将 $.data.list 值作为转换的结果给到作业:
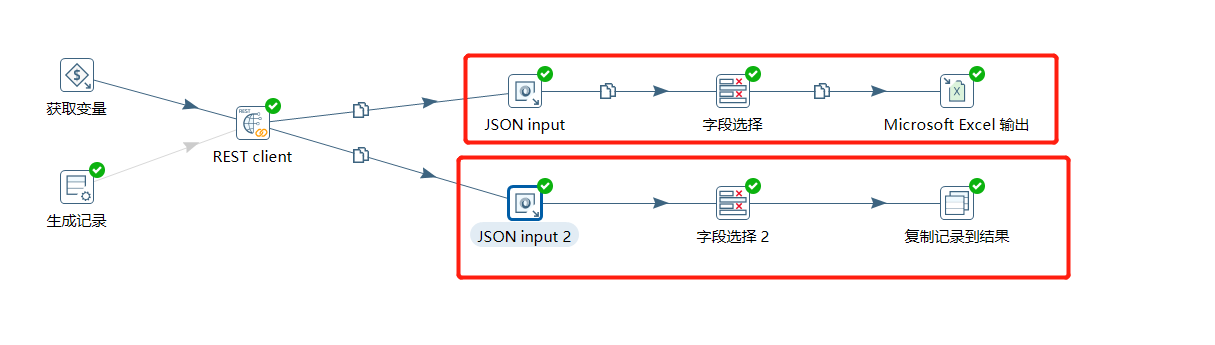
2.2.1 存入 Excel 的过程
首先对结果数据进行解析:
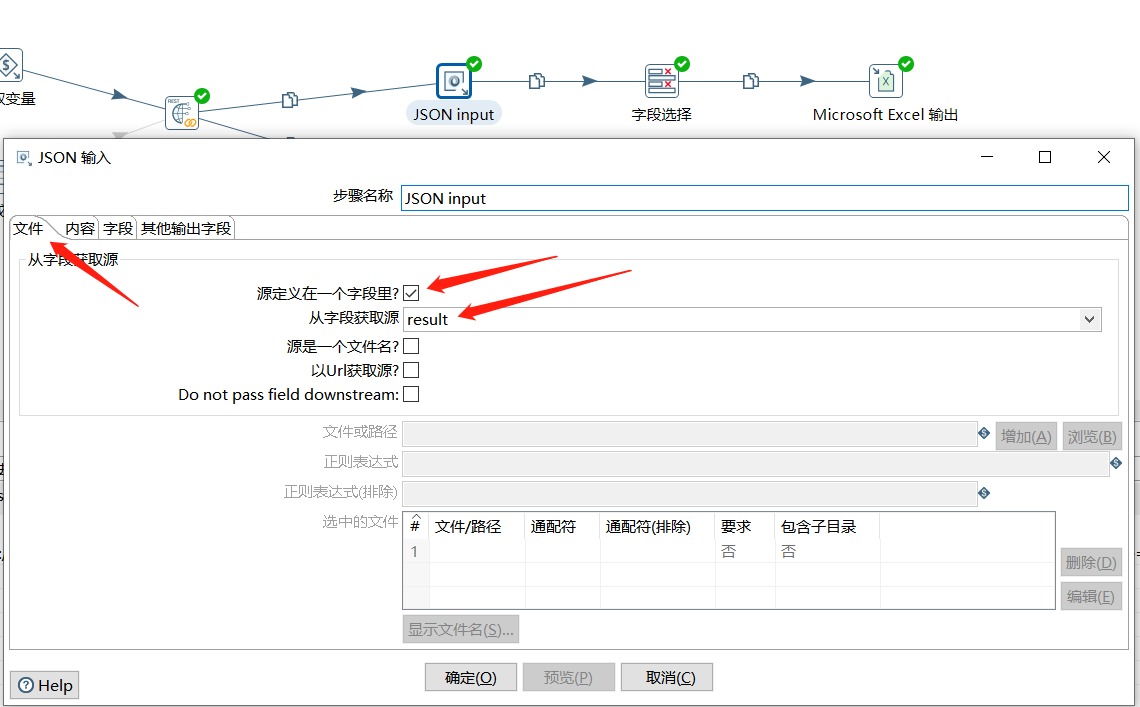
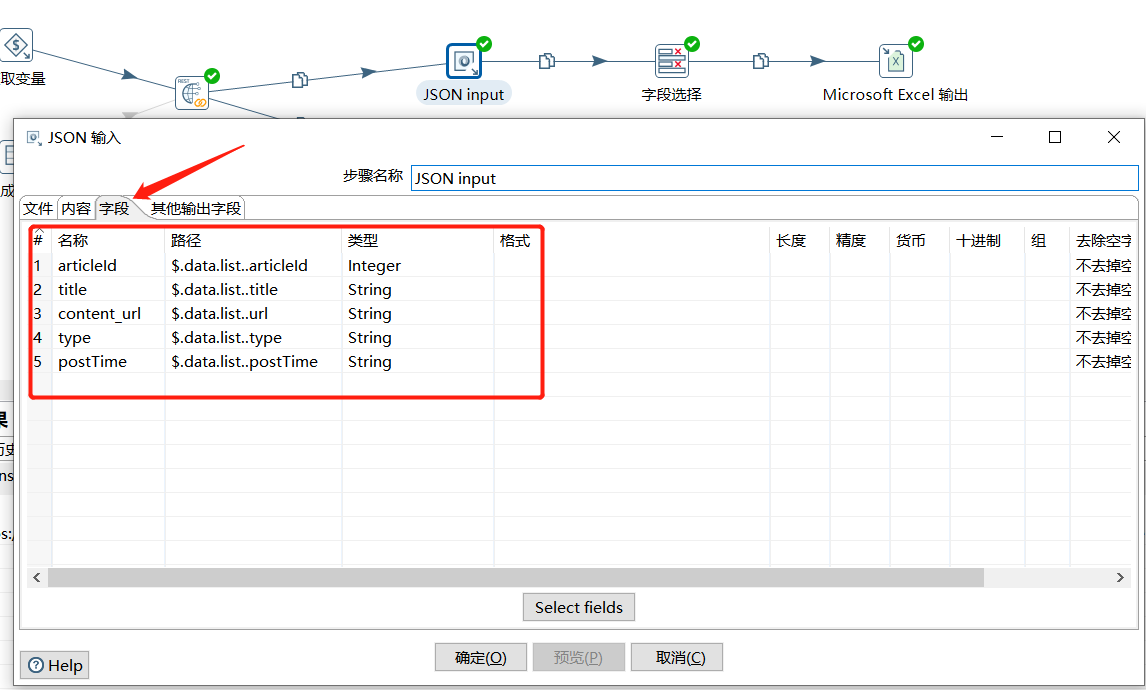
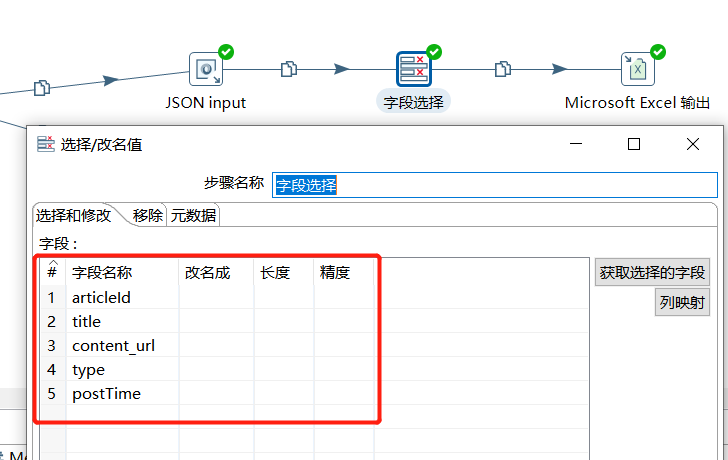
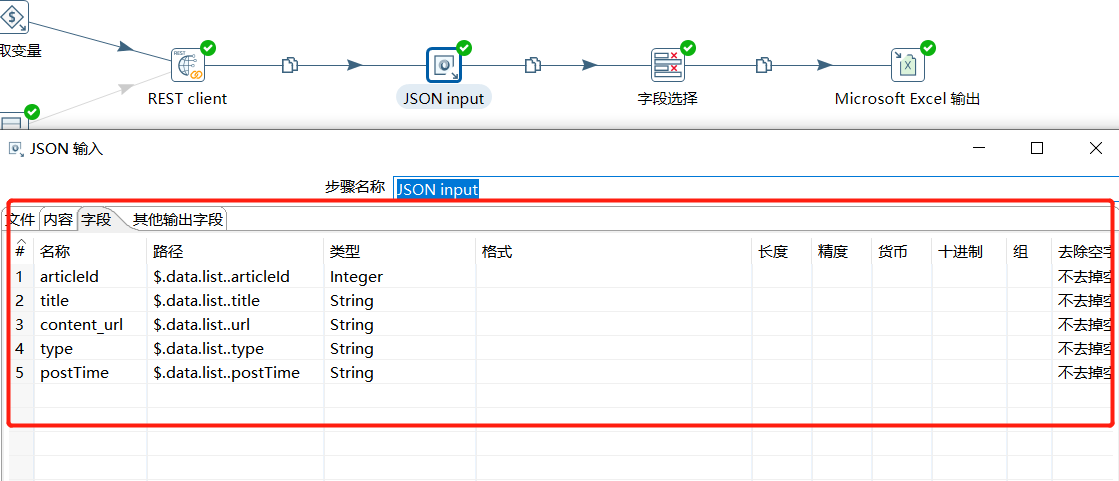
字段这里就对 articleId、title、url、type、postTime 这几个字段进行存储:
| 名称 | 路径 |
|---|---|
| articleId | $.data.list…articleId |
| title | $.data.list…title |
| content_url | $.data.list…url |
| type | $.data.list…type |
| postTime | $.data.list…postTime |
解析出关键字段后,使用字段选择过滤下字段:
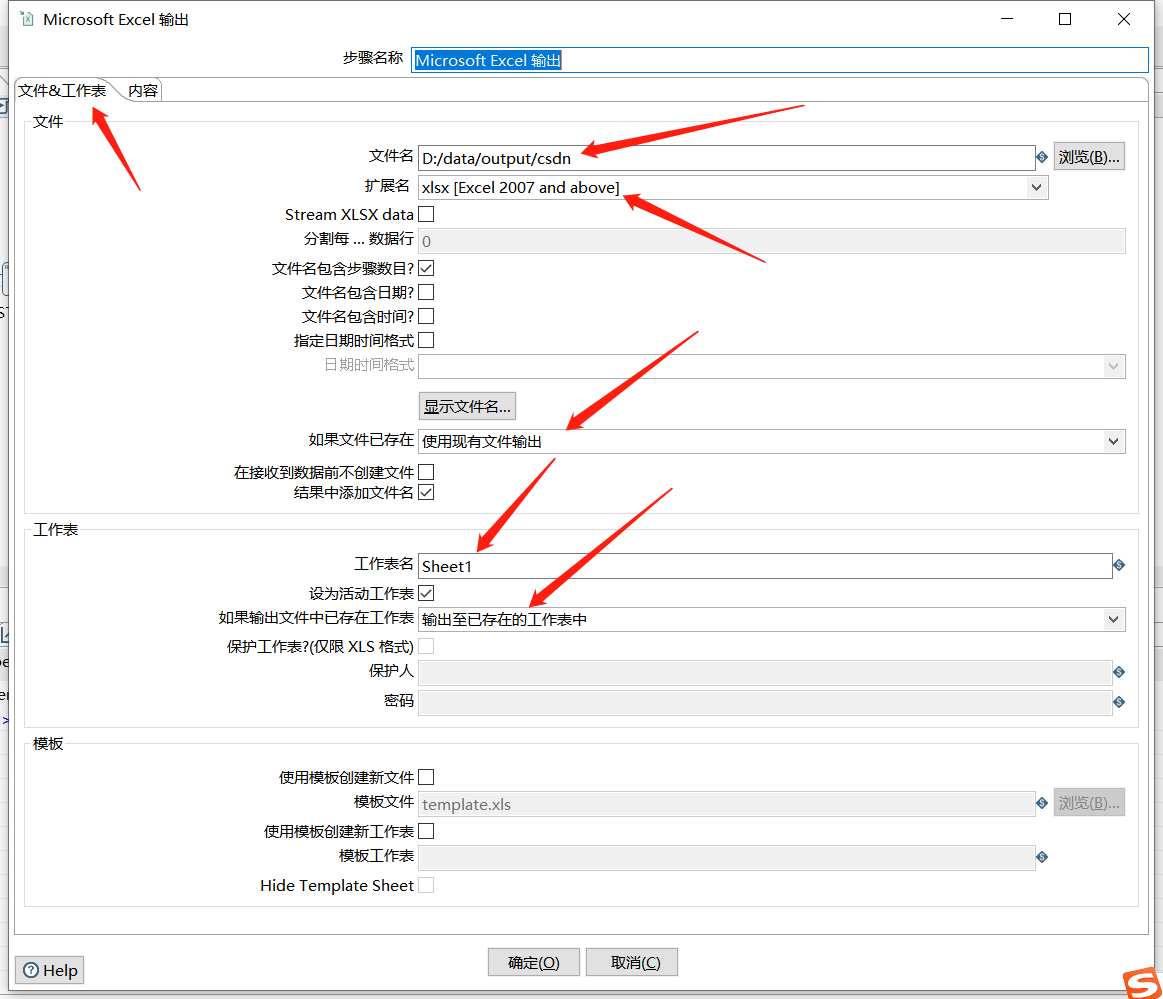
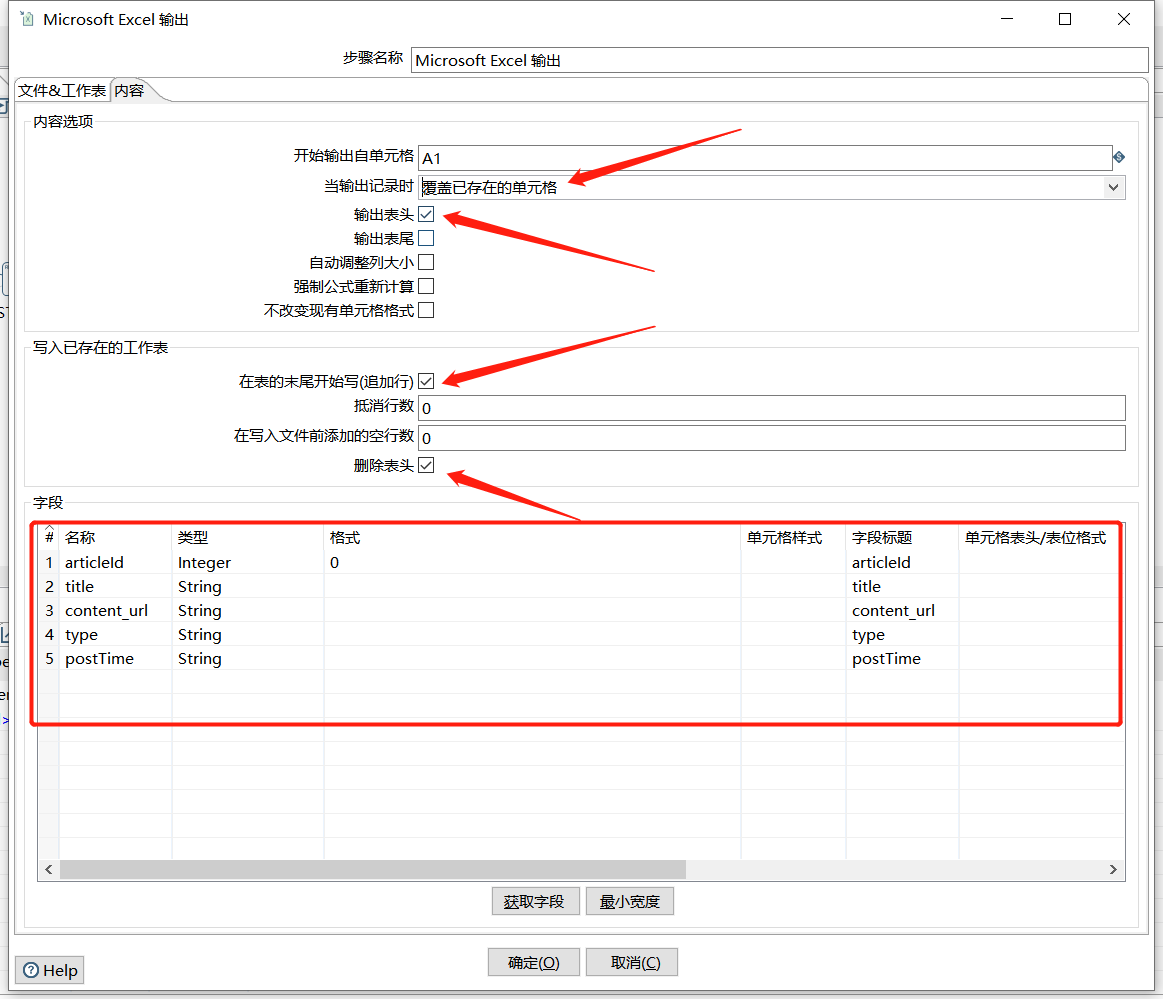
最后写入 Excel 中:
2.2.2 返回作业结果的过程
解析出 $.data.list 的值:
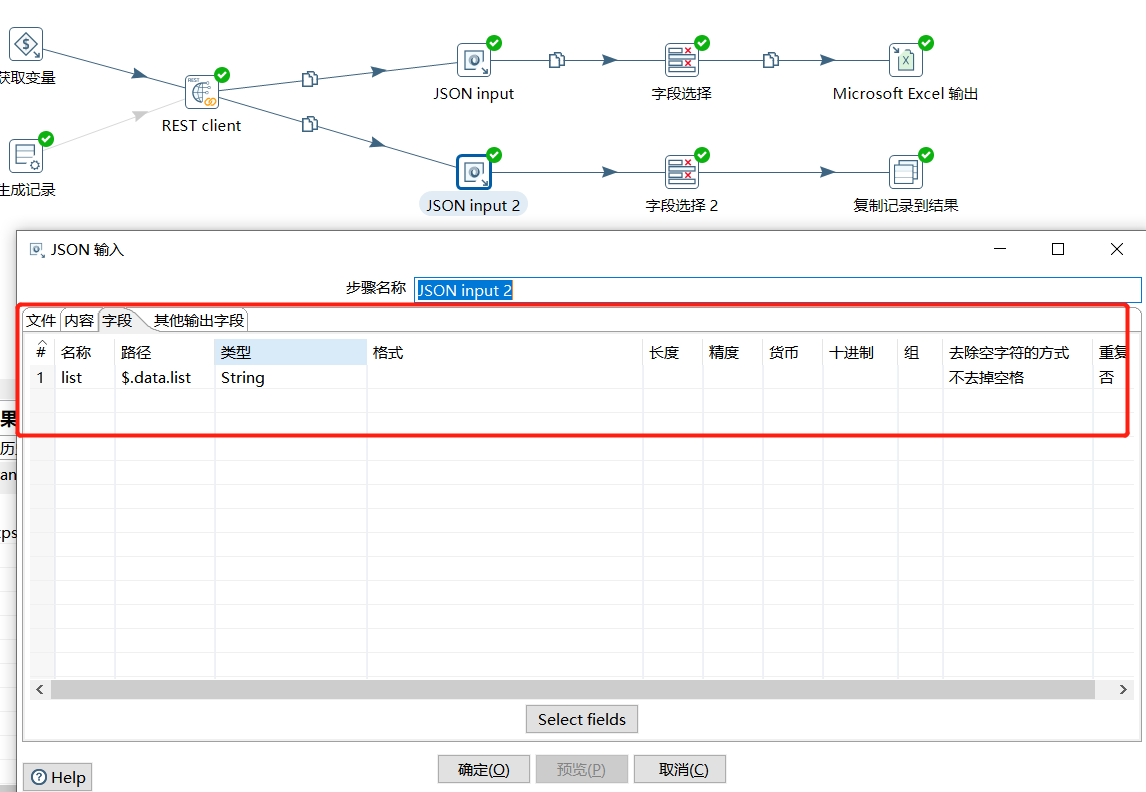
选择字段信息:
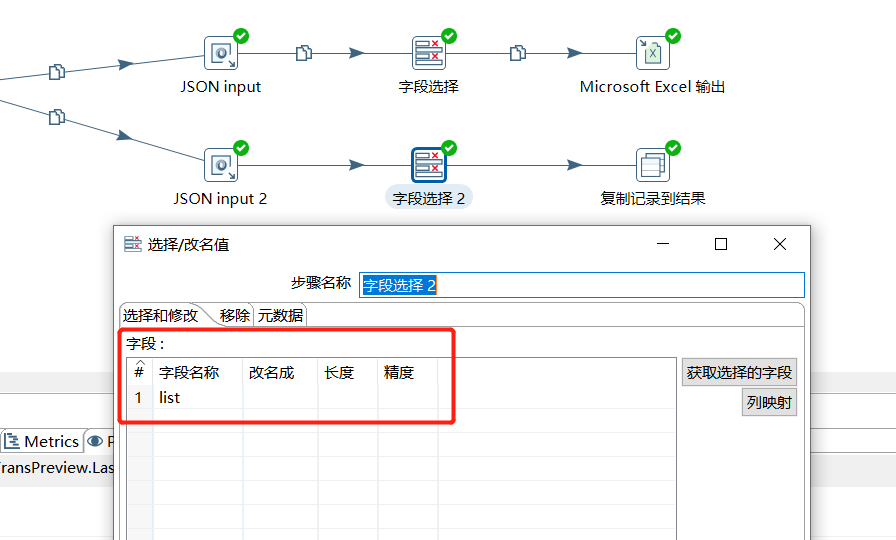
2.2.3 运行结果
运行作业:
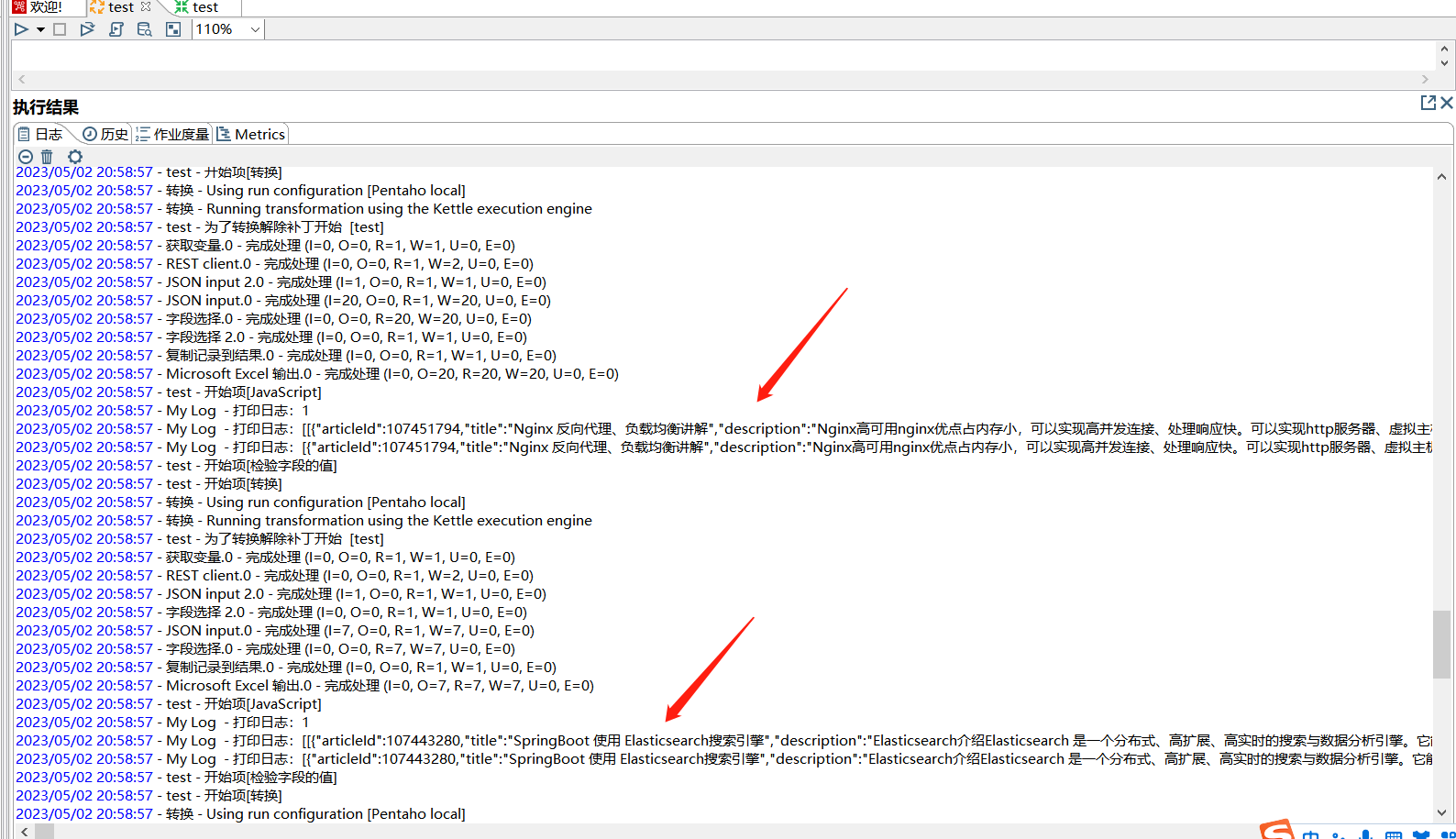
从日志中可以看到迭代的效果,下面看下输出的结果:
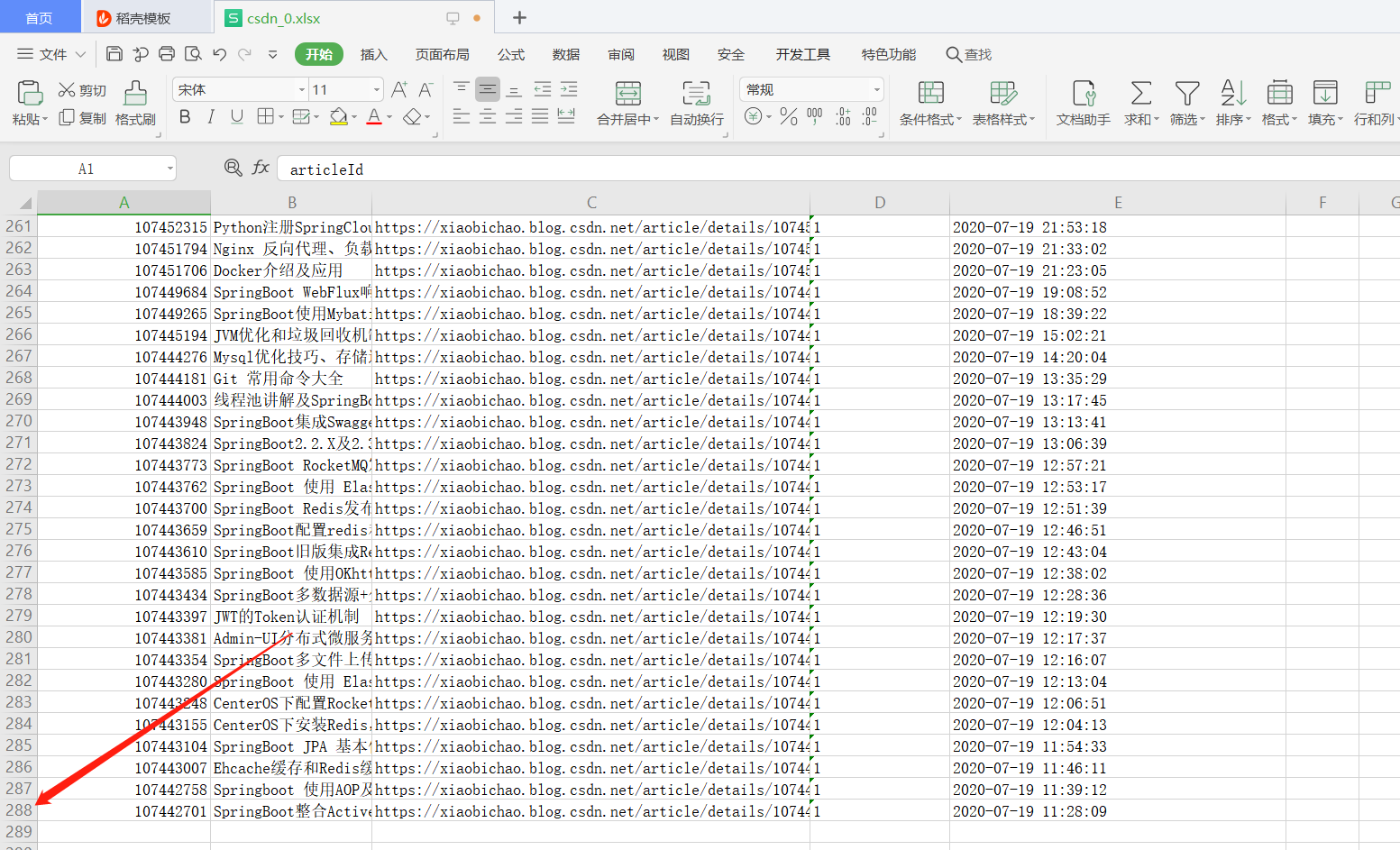
可以看到已经获取到了全部的数据。
三、计算出总页数,递归对页数进行 +1 直到等于最大页 方案
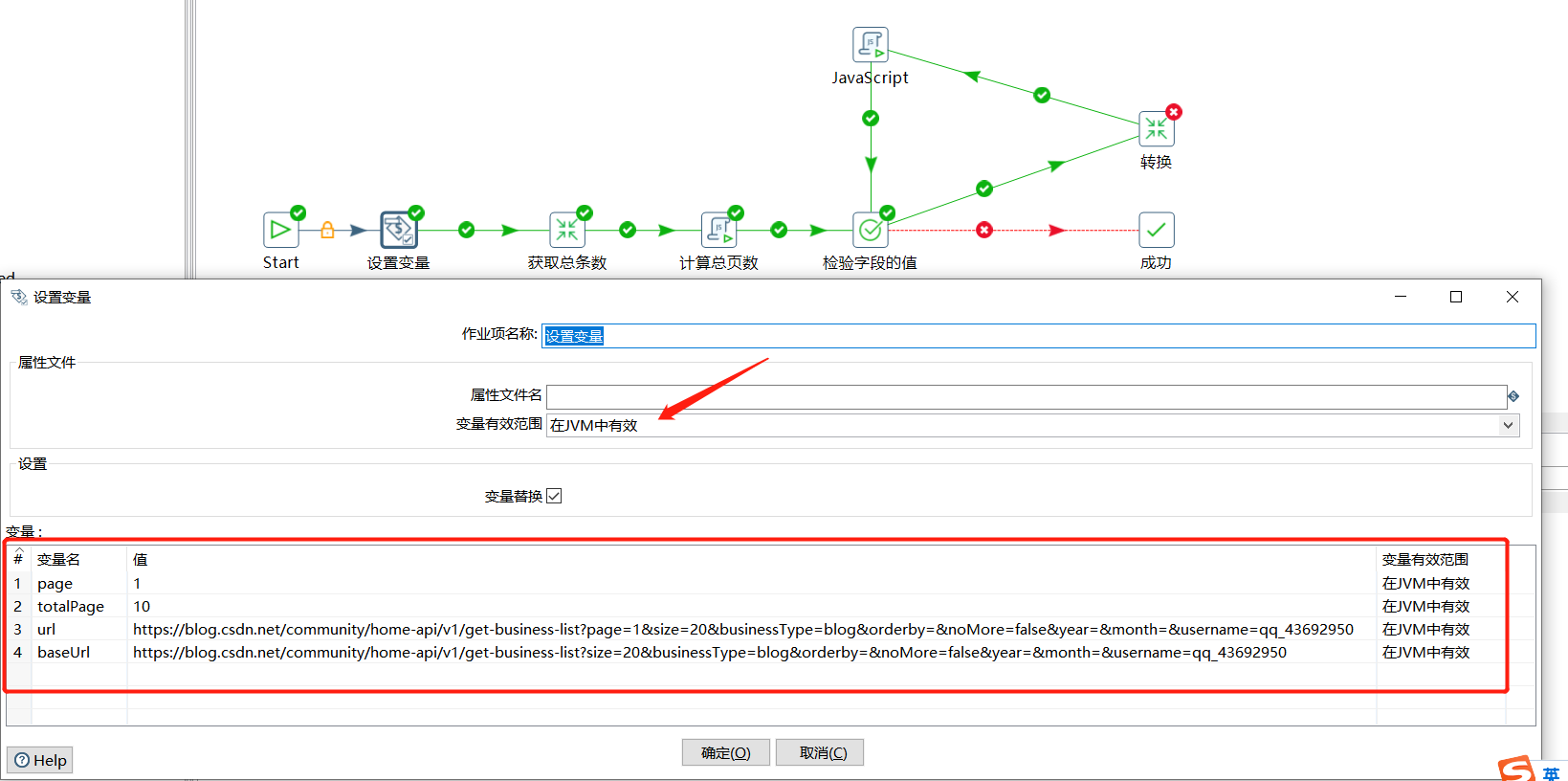
这种方案相较于上一个方案多一步计算总页数的操作,这里需要定义四个变量,分别如下:
| 变量 | 初始值 | 说明 |
|---|---|---|
| page | 1 | 第几页 |
| totalPage | 10 | 总页数 |
| url | https://blog.csdn.net/community/home-api/v1/get-business-list?page=1&size=20&businessType=blog&orderby=&noMore=false&year=&month=&username=qq_43692950 |
每次请求的url |
| baseUrl | https://blog.csdn.net/community/home-api/v1/get-business-list?size=20&businessType=blog&orderby=&noMore=false&year=&month=&username=qq_43692950 |
去除分页参数后的url |
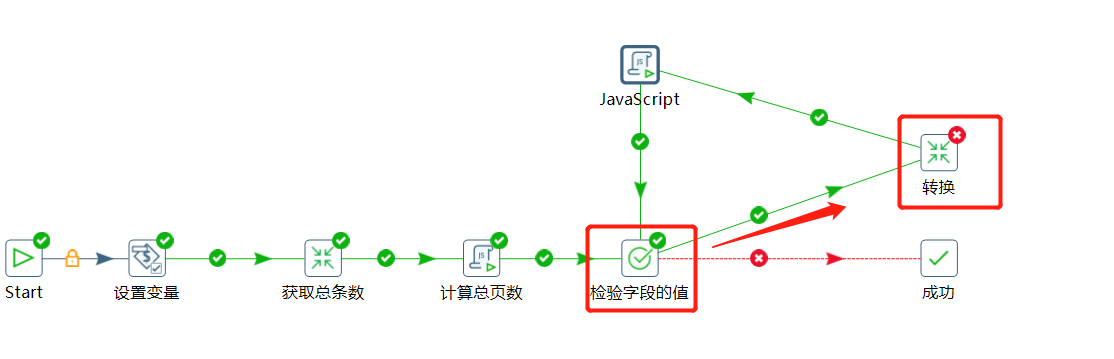
先看一下总的作业设计图:
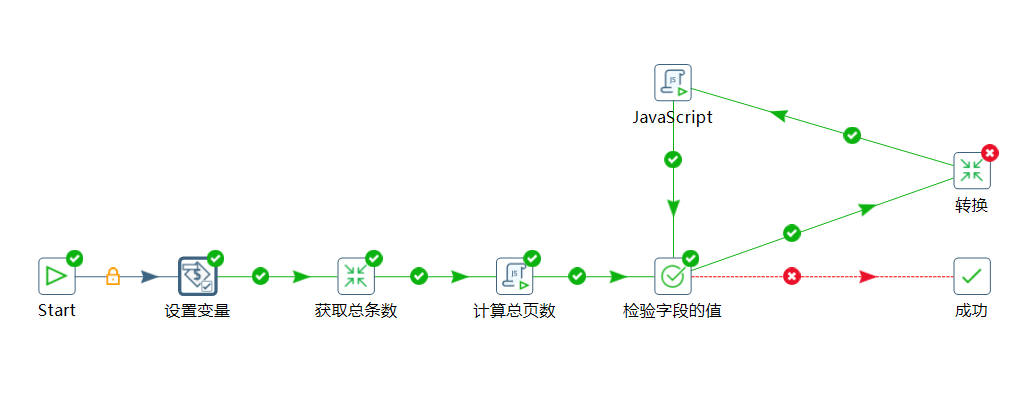
获取总条数转换:
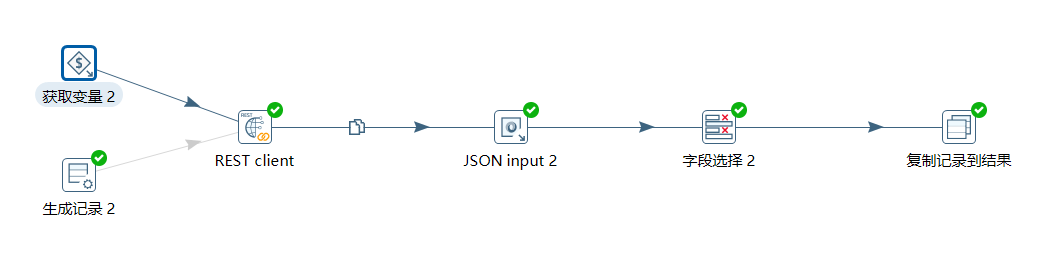
存储数据转换:
3.1 作业设计过程
使用设置变量添加上面几个变量信息:
下面通过计算总条数转换获取到总数,实际就是取的返回中的 $.data.total 参数:

下面通过 JS 脚本计算出总页数,将总页数覆盖变量 totalPage 的值:
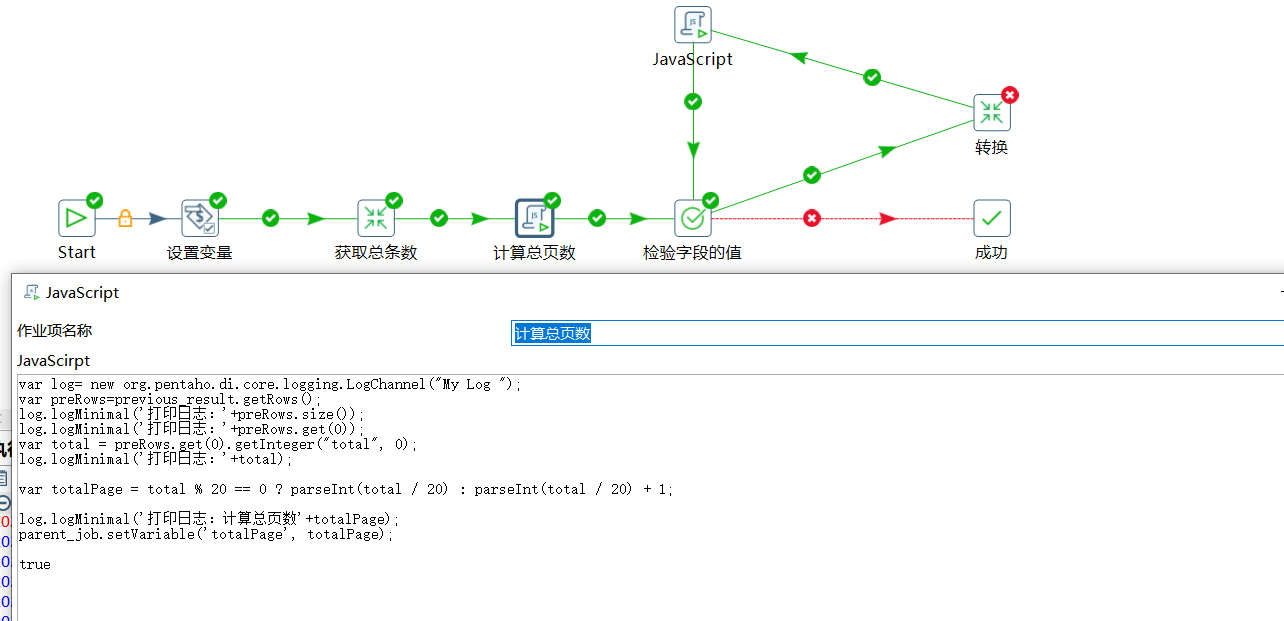
var log= new org.pentaho.di.core.logging.LogChannel("My Log ");
var preRows=previous_result.getRows();
log.logMinimal('打印日志:'+preRows.size());
log.logMinimal('打印日志:'+preRows.get(0));
var total = preRows.get(0).getInteger("total", 0);
log.logMinimal('打印日志:'+total);
var totalPage = total % 20 == 0 ? parseInt(total / 20) : parseInt(total / 20) + 1;
log.logMinimal('打印日志:计算总页数'+totalPage);
parent_job.setVariable('totalPage', totalPage);
true
下面直接判断如果 page 的值小于 totalPage 则就可以执行存储数据的转换操作:
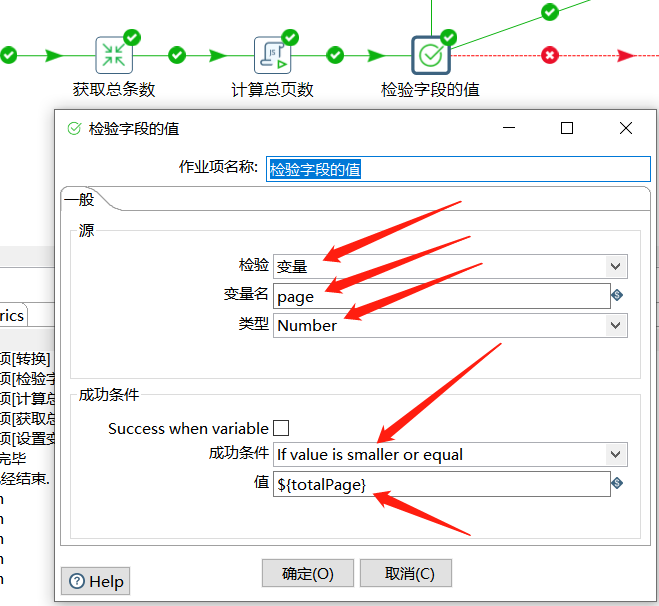
在转换执行后,无需拿到转换的结果,直接对 page 进行 +1 操作,并重新生成一个完整的 url 覆盖变量中 url 的值,这里通过 JS 脚本实现:
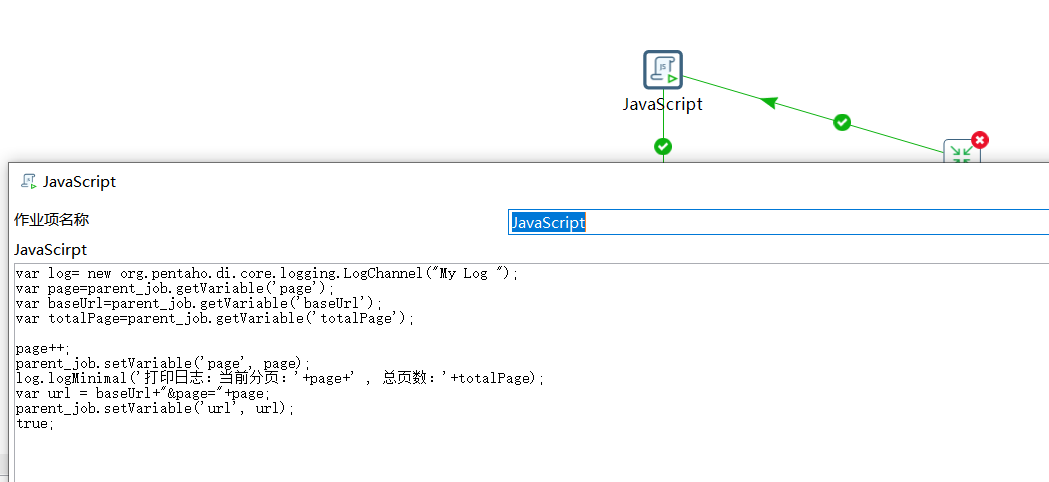
var log= new org.pentaho.di.core.logging.LogChannel("My Log ");
var page=parent_job.getVariable('page');
var baseUrl=parent_job.getVariable('baseUrl');
var totalPage=parent_job.getVariable('totalPage');
page++;
parent_job.setVariable('page', page);
log.logMinimal('打印日志:当前分页:'+page+' , 总页数:'+totalPage);
var url = baseUrl+"&page="+page;
parent_job.setVariable('url', url);
true;
下面又指向检验字段的值,一直递归计算。
3.2 获取总条数转换
首先获取到变量的值:
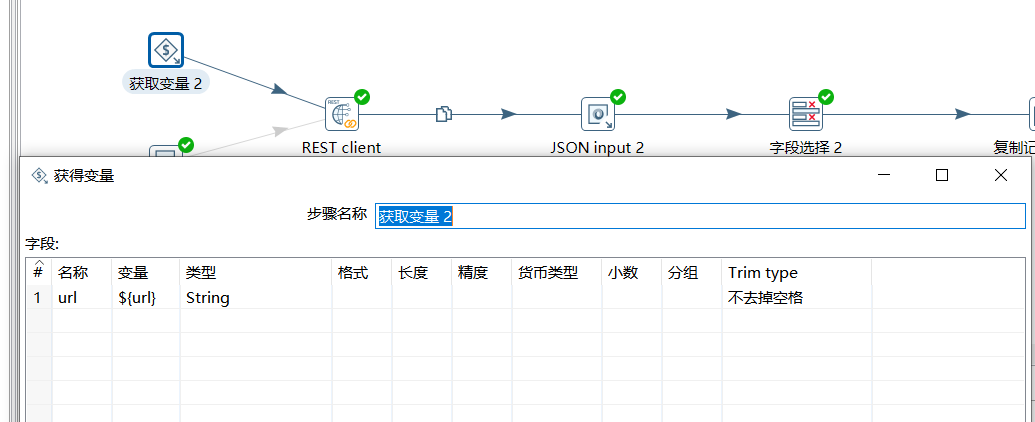
然后通过 REST client 获取到接口数据:
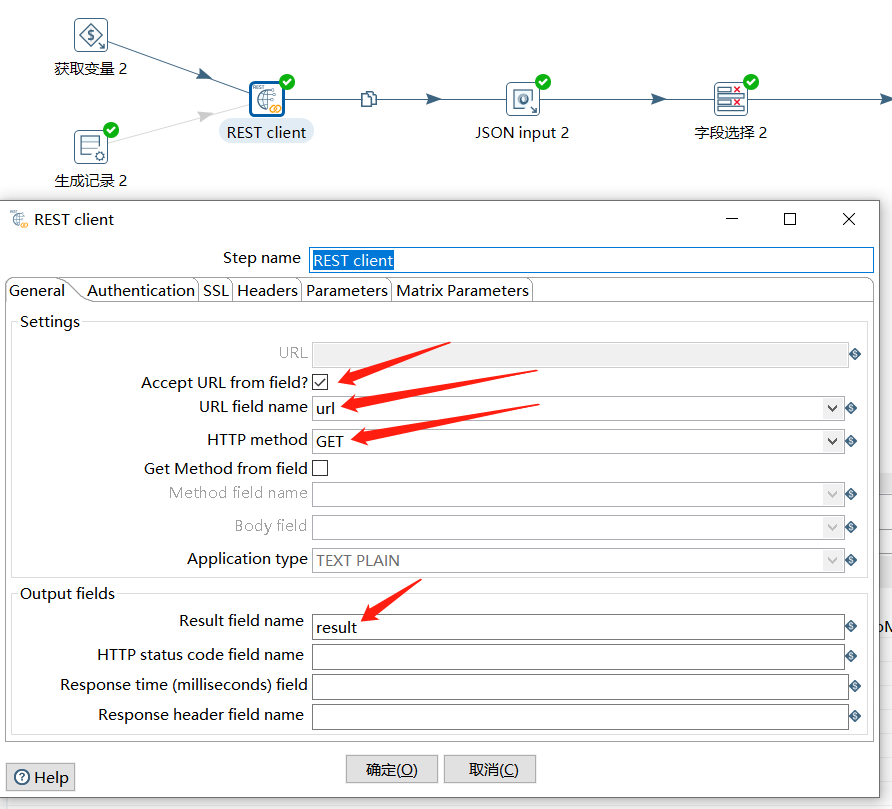
下面使用 JSON input 对结果数据进行解析,取出 $.data.total 值:
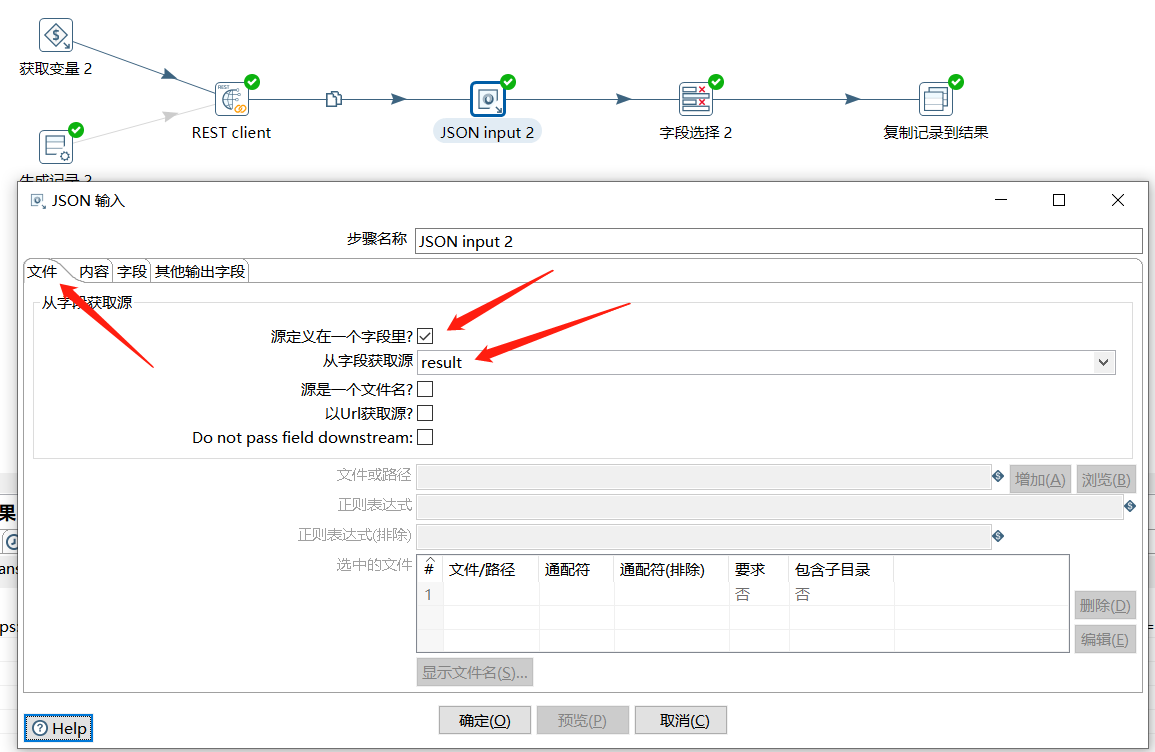
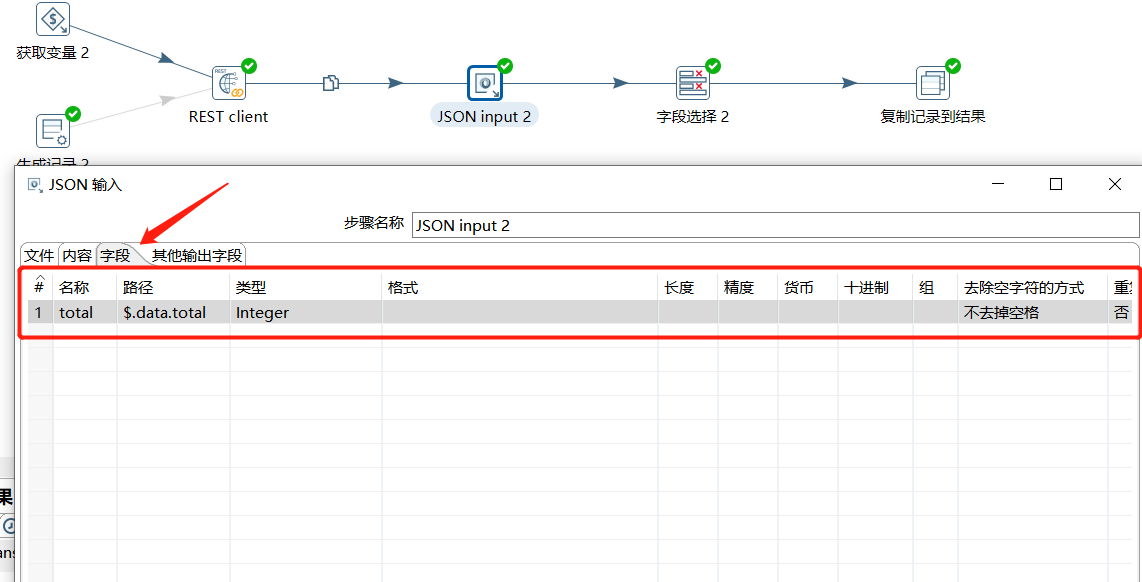
下面通过字段选择,只保留 total 字段:
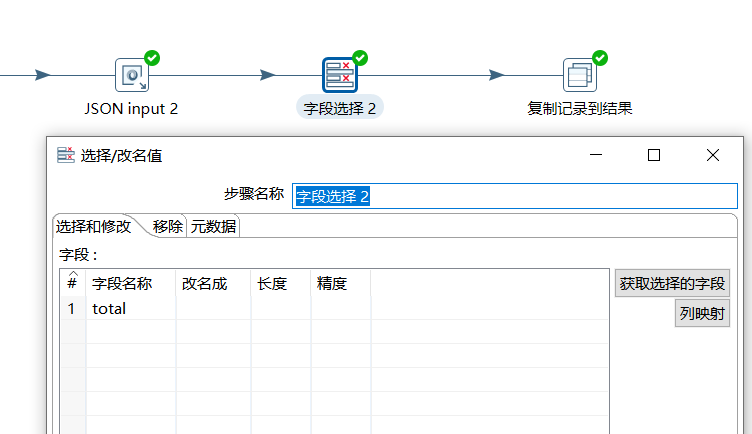
最后将该结果作为转换的结果给到作业。
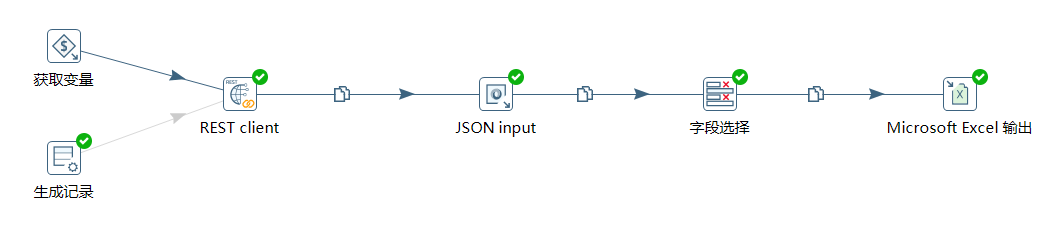
3.3 存入 Excel 过程转换
首先同样获取变量:
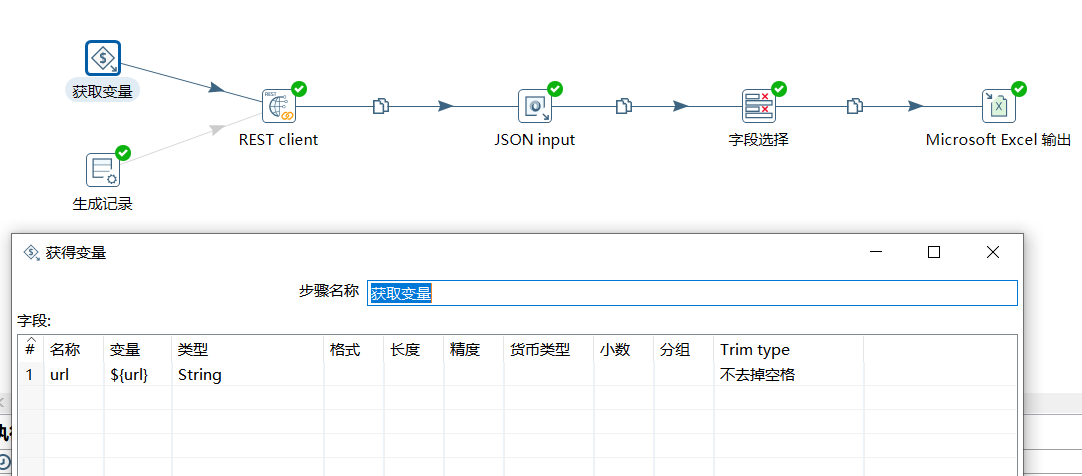
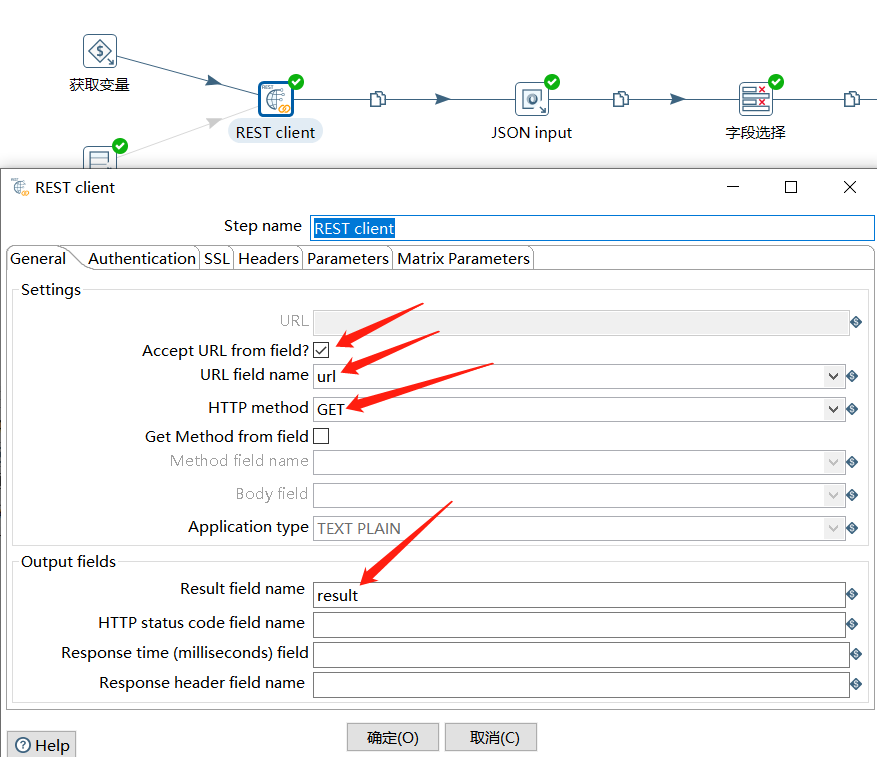
然后通过 REST client 拿到接口数据:
接着使用 JSON input 拿到关键字段,同样对 articleId、title、url、type、postTime 这几个字段进行存储:
最后写入到 Excel 中:
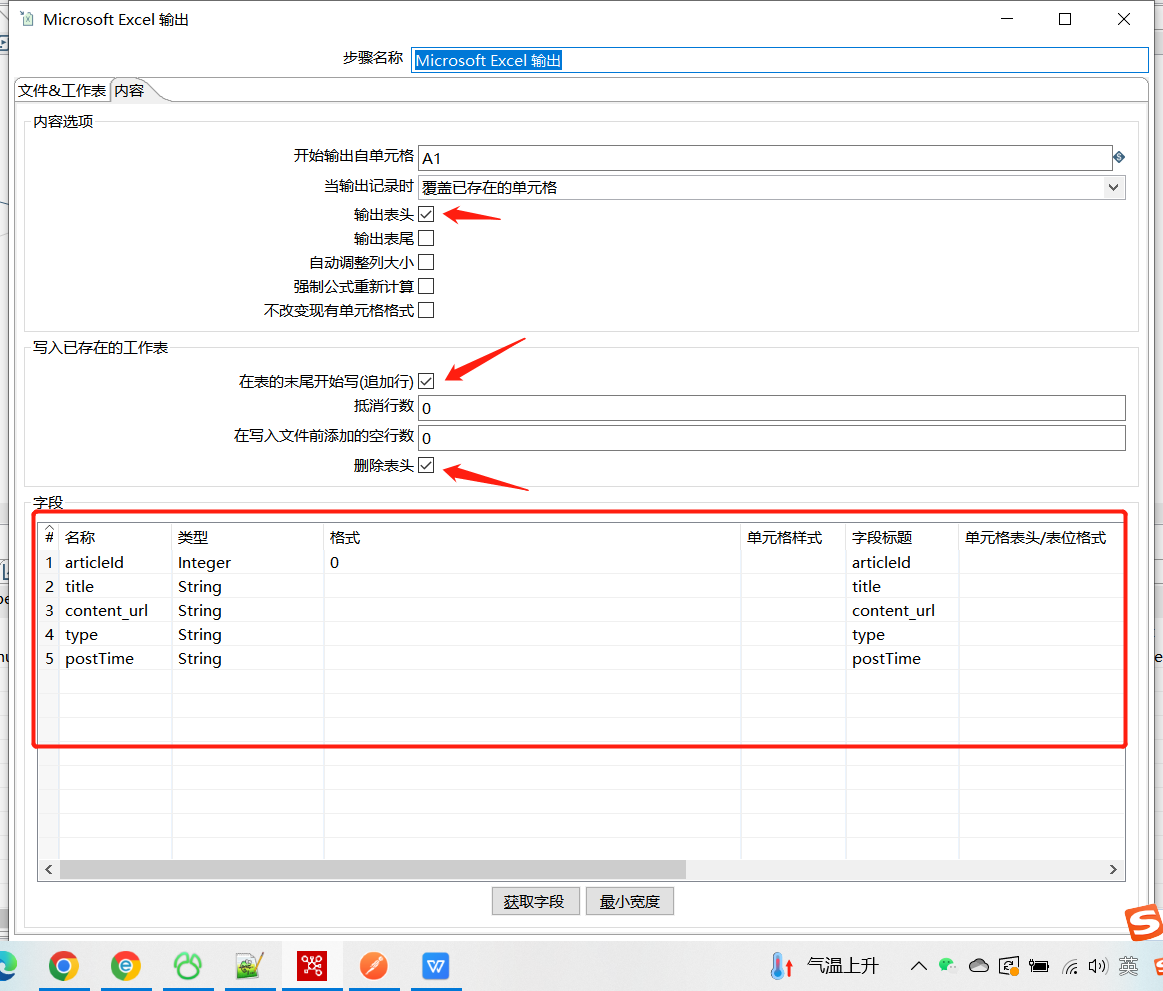
3.4 运行结果
运行作业:
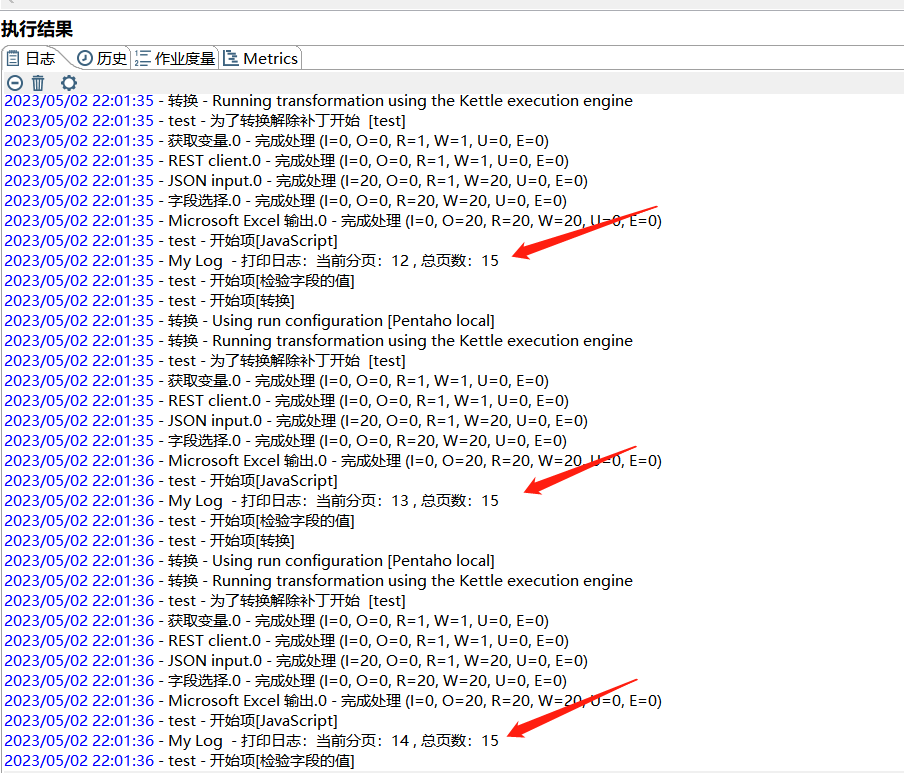
从日志中可以看到迭代的效果,下面看下输出的结果:
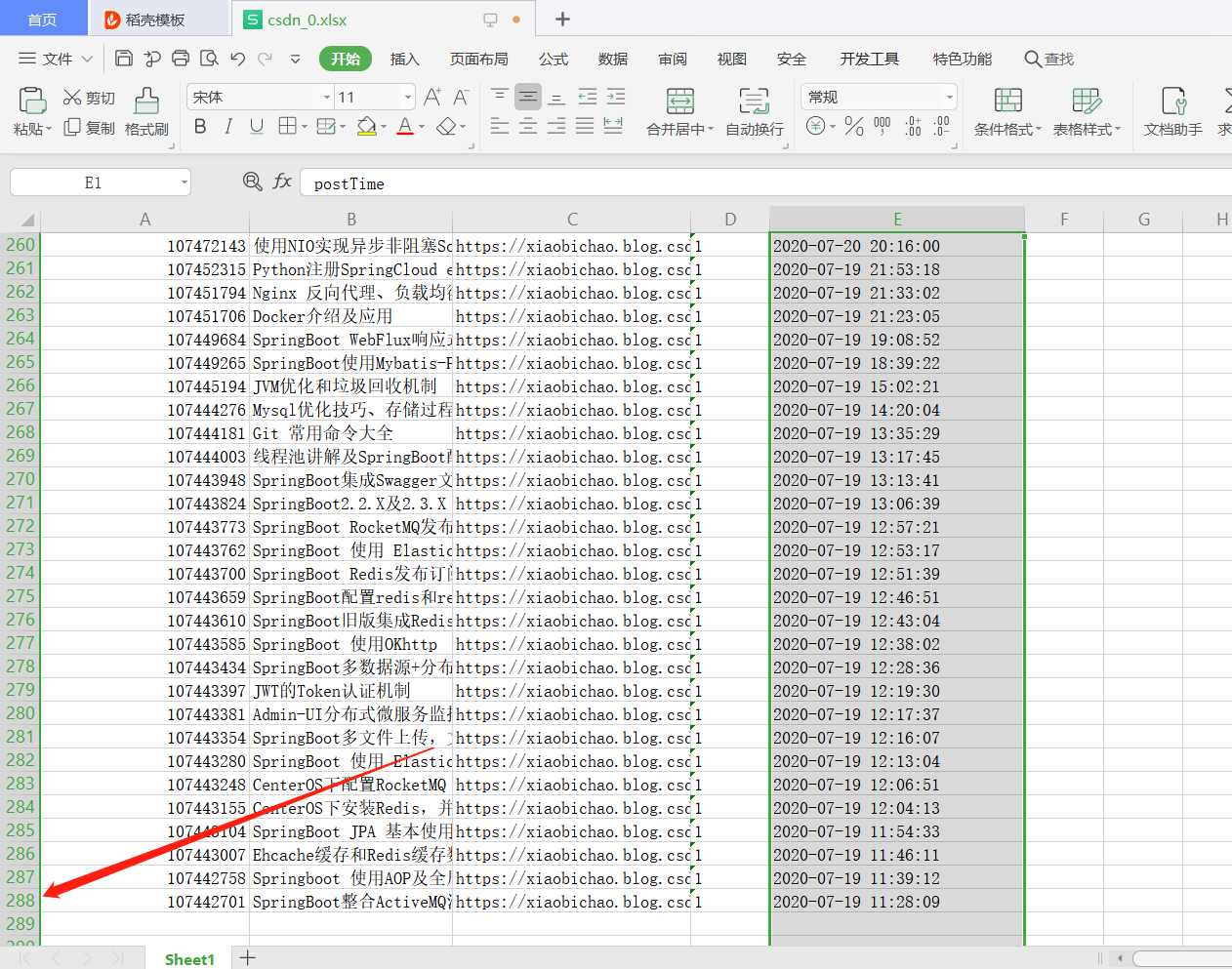
可以看到同样获取到了全部的数据。