ChatGPT Plugins内幕、源码及案例实战
6.1 ChatGPT Plugins的工作原理
本节主要跟大家谈ChatGPT的插件(Plugins),这个内容非常重要。现在很多企业级的开发,一般都会基于ChatGPT插件进行一些服务的封装,相当于开发了一个代理(Agent),把一些服务或者API封装在里面,然后呼叫的时候,是直接使用代理,而不是直接去呼叫服务,代理会在内部把事情处理好。本节会围绕几个方面,第一个方面,跟大家分享ChatGPT插件内部到底是怎么工作的,这肯定是至关重要的,对一个开发者或者一个技术决策者而言,如果不知道它具体是怎么工作的,其他很多事情都无从谈起,这是跟大家谈的第一点;第二点,围绕检索(retrieval)插件,跟大家谈它的源码;第三点,从具体案例的角度,跟大家谈两个案例。
作者(Gavin大咖微信:NLP_Matrix_Space)在OpenAI官网主要使用GPT-4,已经安装了一些插件,点击的时候会看见这些插件,如图6-1所示。
图6- 1 ChatGPT插件示意图
如图6-2所示,如果点击插件存储(Plugin store),会进入插件商店。业界很多人对ChatGPT插件的评价非常高,他们的评价会从不同的切入点谈事情,但是底层有一个共同的逻辑,就是ChatGPT插件会成为新一代基于大模型驱动的应用商店。至于应用商店,例如:苹果的APP store或者Google的Google Play,拿ChatGPT插件和它们做对比,大家应该知道它的核心意义,更最重要的是你自己可以开发插件,而且开发插件非常容易。
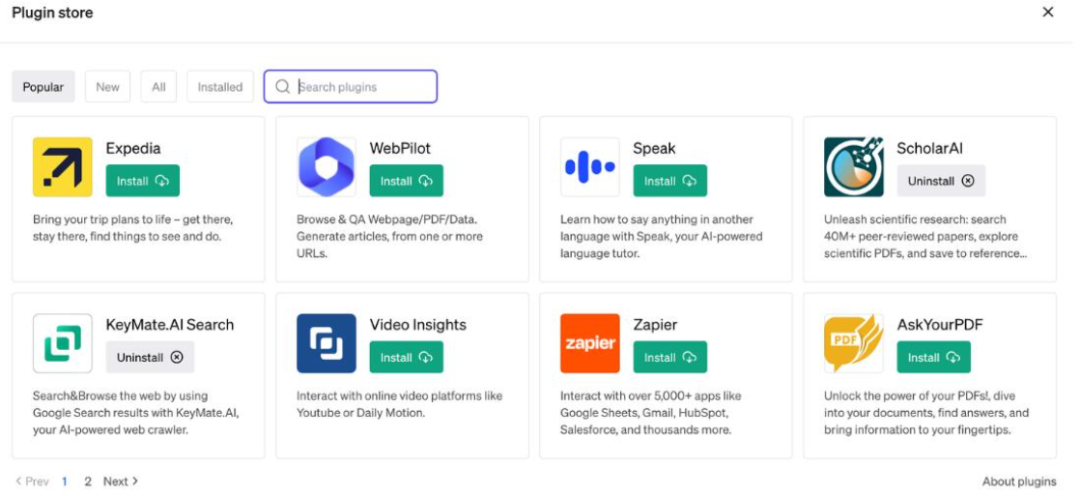
图6- 2 插件商店
回到OpenAI官网的页面,官网谈到关于ChatGPT插件,OpenAI公司已经在ChatGPT 中实现了对插件的初步支持,插件是为以安全为核心原则的语言模型而设计的工具,可帮助ChatGPT访问最新信息、运行计算或使用第三方服务。如今的语言模型虽然可用于各种任务,但仍然有限,它们唯一可以学习的信息是它们的训练数据,这些信息可能会过时,并且是一种适用于所有应用程序的信息。但插件可以成为语言模型的“眼睛和耳朵”,使它们能够访问最新及个性化的信息,这些信息没有包含在训练数据中。为了响应用户的明确请求,插件还可以使语言模型代表它们执行安全、受限的操作,从而提高系统整体的实用性。插件是特别为语言模型设计的,不用太关注它底层具体安全设计的内容。有了这个插件,可以访问已开发的服务,或者第三方库等。插件是整个OpenAI开放的对外服务,是一个里程碑的实现,这里有一句很经典的话:ChatGPT本身是魔法,但插件是更纯粹的魔法。ChatGPT的训练数据是2021年9月份以前的,要访问以后的数据,尤其是企业的私有数据,ChatGPT插件可以实现这一点;更进一步,ChatGPT跟用户交互的方式,用户要执行一些动作的话,可以在ChatGPT中对应用程序的图标采取行动,ChatGPT插件都可以实现,这看起来很激动人心,但如果从具体架构的角度,其实是非常简单的,从最上层的角度,域(domain)是URL或者服务访问的地址,代理(Agent)进程对API服务或者工具进行封装,还有Open API 定义(Open API Definition)和插件清单(Plugin Manifest),如图6-3所示。
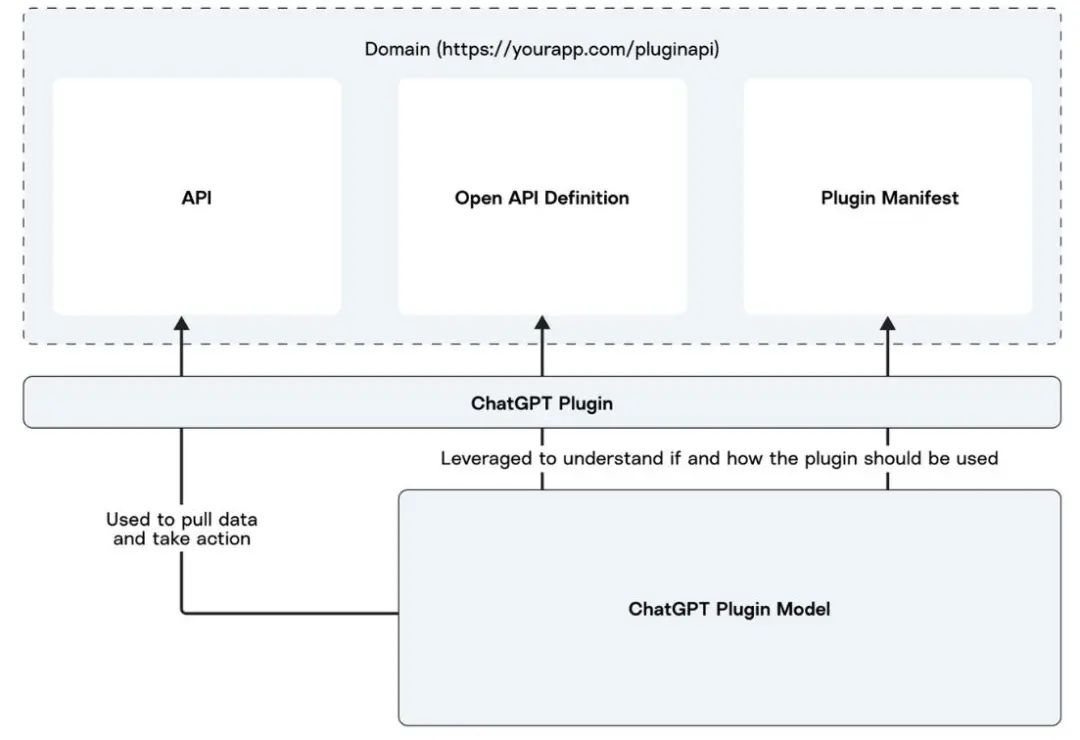
图6- 3 ChatGPT插件架构
6.2 ChatGPT Retrieval Plugin
源码解析之
Services
及
local server
如图6-4所示,是ChatGPT检索插件代码目录,大家稍微看一下这个代码。
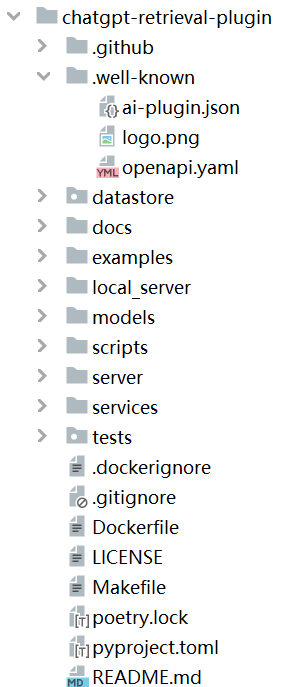
图6- 4 ChatGPT检索插件代码目录
ChatGPT检索插件库使用自然语言查询,为文档的语义检索提供了灵活的解决方案,ChatGPT检索插件代码的目录说明,如表6-1所示。
| 目录 |
描述 |
| datastore |
包含使用各种向量数据库提供存储和查询文档嵌入的核心逻辑。 |
| docs |
包括有关设置和使用每个向量数据库提供程序、webhook以及删除未使用的依赖项的文档。 |
| examples |
提供示例配置、身份验证方法和特定于提供程序的示例。 |
| local_server |
包含为localhost测试配置的检索插件的实现。 |
| models |
包含插件使用的数据模型,例如文档和元数据模型。 |
| scripts |
提供用于处理和上载来自不同数据源的文档的脚本。 |
| server |
包含主要的FastAPI服务器实现。 |
| services |
包含用于分块、元数据提取和检测等任务的实用程序服务。 |
| tests |
包括各种向量数据库提供程序的集成测试。 |
| .well-known |
存储插件清单文件和OpenAPI模式,定义插件配置和API规范。 |
表6- 1 ChatGPT检索插件的目录说明
ChatGPT插件是专门为大语言模型设计的聊天扩展,使它们能够访问最新信息、运行计算或与第三方服务交互以响应用户的请求。开发人员可以通过网站公开API,并提供描述API的标准化清单文件来创建插件。ChatGPT使用这些文件,并允许AI模型调用开发人员定义的API。
一个插件包括以下内容::
-
一个API接口
一个API模式(提供OpenAPI JSON或YAML格式)
定义插件相关元数据的清单(JSON文件)
本节讲解的ChatGPT检索插件,支持个人或组织文档的语义搜索和检索,允许用户通过提问或用自然语言表达需求,从数据源(例如文件、笔记或电子邮件)中获得相关的文档,企业可以使用这个插件通过ChatGPT向员工提供内部文档。ChatGPT检索插件使用OpenAI的text-embedding-ada-002嵌入模型,来生成文档块的嵌入式向量,在后端使用向量数据库存储和查询嵌入式向量。作为一个开源和自托管的解决方案,开发人员可以部署自己的检索插件并将其注册到ChatGPT,检索插件支持多个向量数据库提供程序,允许开发人员从列表中选择一个向量数据库。
FastAPI服务器部署检索插件的端点,用于更新、查询和删除文档。用户可以根据来源、日期、作者或其他标准使用元数据过滤器来优化搜索结果。检索插件可以托管在任何支持Docker容器的云平台上,比如Fly.io、Heroku、Render或Azure容器应用程序。为了使向量数据库保持最新文档的更新,检索插件可以连续地处理和存储来自各种数据源的文档,使用传入的webhook到upsert和delete端点。Zapier或Make之类的工具可以根据事件或日程安排帮助配置webhooks。检索插件的一个显著特点是它为ChatGPT提供内存的记忆能力。通过利用插件的upsert端点,ChatGPT可以将对话中的片段保存到向量数据库中,以供以后参考,允许ChatGPT记住和检索以前对话中的信息,该功能有助于提高上下文感知的聊天体验。检索插件允许ChatGPT搜索内容的向量数据库,然后将结果添加到ChatGPT会话中,可以选择不同的身份验证方法来保护插件。
检索插件是使用FastAPI构建的,FastAPI是一个用Python构建API的Web框架,FastAPI可以轻松地开发、验证和记录API端点。使用FastAPI的好处之一是使用Swagger UI自动生成交互式API文档。当API在本地运行时,可以使用位于<local_host_url即http://0.0.0.0:8000>/docs的Swagger UI与API端点进行交互,测试它们的功能,并查看预期的请求和响应模型。
检索插件公开了以下端点,用于从向量数据库中插入、查询和删除文档,所有请求和响应都是JSON格式,并且需要一个有效的承载令牌作为授权头。
/upsert:允许上传一个或多个文档,并将其文本和元数据存储在向量数据库中。文档被分成大约200个标记的块,每个标记都有一个唯一的ID。请求体中有一个文档列表,每个文档都有一个文本字段,以及可选的ID和元数据。元数据可以包含以下可选字段:source、source_id、url、created_at和author。端点返回插入文档的ID列表,如果最初没有提供ID,则生成ID。
/upsert-file:允许上传单个文件,例如:PDF、TXT、DOCX、PPTX或MD,并将文本和元数据存储在向量数据库中,文件被转换为纯文本,并分成大约200个标记的块,每个标记都有一个唯一的ID。端点返回一个包含插入文件生成的ID的列表。
/query:允许使用一个或多个自然语言查询和可选的元数据,过滤器查询向量数据库。端点需要请求体中的查询列表,每个查询都有一个查询和可选的过滤器及top_k个文本。过滤器包含:source、source_id、document_id、url、created_at和author等。top_k字段指定要为给定查询返回多少个结果,默认值是3个。端点返回一个对象列表,每个对象都包含给定查询最相关的文档块列表,以及它们的文本、元数据和相似度分数。
/delete:允许使用ID、元数据过滤器或delete_all标志从向量数据库中删除一个或多个文档。端点期望请求体中至少有以下参数之一:ids、filter或delete_all。ids参数是要删除的文档id列表,具有这些IDS文档的所有文档块都将被删除。过滤器参数包含以下内容:source、source_id、document_id、url、created_at和author。delete_all参数是一个布尔值,指示是否从向量数据库中删除所有文档。端点返回一个布尔值,指示删除是否成功。
OpenAPI架构只包含/query端点,因为这是ChatGPT需要访问的唯一函数。这样,ChatGPT只能使用该插件根据自然语言查询检索相关文档。然而,如果开发人员还想让ChatGPT能够记住以后的事情,可以使用/upsert端点将对话中的片段保存到向量数据库中。


