Dataloader 源码分析(二)
Dataloader 组件
Sampler 类
在看 Sampler 的具体实现之前,我们先看看 Dataloader 在什么时候产生 Sampler 对象:
class DataLoader(object):
def __init__(self, ...):
...
if sampler is None:
...
# 如果指定shuffle就使用随机采样,否则使用顺序采样
if shuffle:
sampler = RandomSampler(dataset, generator=generator)
else:
sampler = SequentialSampler(dataset)
if batch_size is not None and batch_sampler is None:
# 如果指定了batch_size又没有指定自定义的batch_sampler,就开启自动批采样
batch_sampler = BatchSampler(sampler, batch_size, drop_last)
...
我们可以看到 Sampler 对象的主要职责就是生成用于访问 Dataset 的 index。其中 Sampler 的子类如下:
- SequentialSampler 顺序采样
- RandomSampler 随机采样
- BatchSampler 批采样
实际上还有其他的采样方法,但是因为使用的不多,本文主要讲解上述的三种 Sampler。上述提到的几种采样类都是 Sampler 的子类,Sampler 中的__iter__方法定义为 raise NotImplementedError:
class Sampler(Generic[T_co]):
def __init__(self, data_source: Optional[Sized]) -> None:
pass
def __iter__(self) -> Iterator[T_co]:
raise NotImplementedError
SequentialSampler
SequentialSampler 实现:
class SequentialSampler(Sampler[int]):
data_source: Sized
def __init__(self, data_source: Sized) -> None:
self.data_source = data_source
def __iter__(self) -> Iterator[int]:
# 创建一个迭代器
return iter(range(len(self.data_source)))
def __len__(self) -> int:
return len(self.data_source)
这里主要关注__Iter__方法,实际上返回的 index 就是 range(len(self.data_source)) 顺序递增的结果:len(data_source) 实际上就是 Dataset 返回的 samples 的长度。创建迭代器之后,当对这个迭代器调用__next__方法,就会返回 0, 1, 2, 3, 4, … 顺序递增的 index。
RandomSampler
RandomSampler 实现:
class RandomSampler(Sampler[int]):
data_source: Sized
replacement: bool
def __init__(self, data_source: Sized, replacement: bool = False,
num_samples: Optional[int] = None, generator=None) -> None:
self.data_source = data_source
self.replacement = replacement
self._num_samples = num_samples
self.generator = generator
...
@property
def num_samples(self) -> int:
# dataset size might change at runtime
if self._num_samples is None:
return len(self.data_source)
return self._num_samples
def __iter__(self) -> Iterator[int]:
n = len(self.data_source)
if self.generator is None:
seed = int(torch.empty((), dtype=torch.int64).random_().item())
generator = torch.Generator()
generator.manual_seed(seed)
else:
generator = self.generator
# replacement 表示是否可以生成重复 index
if self.replacement:
# num_samples 表示一次性采样的数据量
for _ in range(self.num_samples // 32):
yield from torch.randint(high=n, size=(32,), dtype=torch.int64, generator=generator).tolist()
yield from torch.randint(high=n, size=(self.num_samples % 32,), dtype=torch.int64, generator=generator).tolist()
else:
for _ in range(self.num_samples // n):
yield from torch.randperm(n, generator=generator).tolist()
yield from torch.randperm(n, generator=generator).tolist()[:self.num_samples % n]
def __len__(self) -> int:
return self.num_samples
RandomSampler 的实现就是调用了 randperm 函数产生随机序列。同时需要注意到 replacement 参数,replacement 表示可否生成之前已经生成过的 index,True 表示可以,否则是不行。
BatchSampler
BatchSampler 不同于前面介绍的每次生成一个 index 的 SequentialSampler 和 RandomSampler,BatchSampler 一次生成一个包含 batch_size 个 index 的 list。同时,BatchSampler 内部调用了 SequentialSampler 和 RandomSampler,也就是生成的 list 中的 index 可能是有顺序的,也可能是随机的。以下是 BatchSampler 实现:
class BatchSampler(Sampler[List[int]]):
Example:
>>> list(BatchSampler(SequentialSampler(range(10)), batch_size=3, drop_last=False))
[[0, 1, 2], [3, 4, 5], [6, 7, 8], [9]]
>>> list(BatchSampler(SequentialSampler(range(10)), batch_size=3, drop_last=True))
[[0, 1, 2], [3, 4, 5], [6, 7, 8]]
"""
def __init__(self, sampler: Union[Sampler[int], Iterable[int]], batch_size: int, drop_last: bool) -> None:
...
# 需要指定内部调用 SequentialSampler 还是 RandomSampler
self.sampler = sampler
self.batch_size = batch_size
self.drop_last = drop_last
def __iter__(self) -> Iterator[List[int]]:
if self.drop_last:
sampler_iter = iter(self.sampler)
while True:
try:
batch = [next(sampler_iter) for _ in range(self.batch_size)]
yield batch
except StopIteration:
break
else:
batch = [0] * self.batch_size
idx_in_batch = 0
for idx in self.sampler:
batch[idx_in_batch] = idx
idx_in_batch += 1
if idx_in_batch == self.batch_size:
yield batch
idx_in_batch = 0
batch = [0] * self.batch_size
if idx_in_batch > 0:
yield batch[:idx_in_batch]
def __len__(self) -> int:
# Can only be called if self.sampler has __len__ implemented
# We cannot enforce this condition, so we turn off typechecking for the
# implementation below.
# Somewhat related: see NOTE [ Lack of Default `__len__` in Python Abstract Base Classes ]
if self.drop_last:
return len(self.sampler) // self.batch_size # type: ignore[arg-type]
else:
return (len(self.sampler) + self.batch_size - 1) // self.batch_size
从官方给出的注释可以看出,如果调用 drop_last=True,会将最后几个没法形成一个完整 batch_size 的 index 丢弃,否则也单独形成一个 list。从源码我们可以看出,BatchSampler 只是对 Sampler 的简单包装,最后生成一个 index list。
总而言之,SequentialSampler 和 RandomSampler 每次生成一个 index,BatchSampler 每次生成一个 batch 的 index。
Fetcher 类
Fetcher 类的功能很简单,实际上就是对 Dataset 做了一层封装,Fetcher 对象接收一个 index 参数,并且返回获取到的 tensor,在 DataloaderIter 中调用 Fetcher:
data = self._dataset_fetcher.fetch(index)
Fetcher 也分为 _IterableDatasetFetcher 和 _MapDatasetFetcher,这里只介绍 _MapDatasetFetcher:
class _BaseDatasetFetcher(object):
def __init__(self, dataset, auto_collation, collate_fn, drop_last):
self.dataset = dataset
self.auto_collation = auto_collation
self.collate_fn = collate_fn
self.drop_last = drop_last
def fetch(self, possibly_batched_index):
raise NotImplementedError()
class _MapDatasetFetcher(_BaseDatasetFetcher):
def __init__(self, dataset, auto_collation, collate_fn, drop_last):
super(_MapDatasetFetcher, self).__init__(dataset, auto_collation, collate_fn, drop_last)
def fetch(self, possibly_batched_index):
if self.auto_collation:
data = [self.dataset[idx] for idx in possibly_batched_index]
else:
data = self.dataset[possibly_batched_index]
return self.collate_fn(data)
其中的 auto_collation 定义在 DataLoader 中:
class DataLoader(object):
...
@property
def _auto_collation(self):
return self.batch_sampler is not None
...
在 Fetcher 中调用的 collate_fn 功能实际上就是简单地将 Numpy 数组转换为 Pytorch Tensor。而 possibly_batched_index 在设置了 batch_size 时是一个 index list,而在其他情况下是一个 list。因此,Fetcher 实现的功能实际上就是:
- 通过 index 拉去 Dataset 中的数据
- 对数据进行 collate_fn 函数得到对应的 Pytorch Tensor
Dataloader 核心代码
介绍完了上面的各个 Dataloader 组件,终于可以介绍 Dataloader 的源码了,Dataloader 实现迭代的功能主要就是依靠 _SingleProcessDataLoaderIter 和 _MultiProcessingDataLoaderIter 类。我们再回顾一下训练脚本中使用 Dataloader 的方法:
train_loader = torch.utils.data.Dataloader(dataset, ...)
# 写法1
for input, target in train_loader:
# 前向计算
output = model(input)
# 计算损失
loss = loss_fn(output, target)
# 反向传播
optimizer.zero_grad()
loss.backward()
# 梯度更新
optimizer.step()
# 写法2
for i, data in enumerate(train_loader):
input, target = data
# 前向计算
output = model(input)
# 计算损失
loss = loss_fn(output, target)
# 反向传播
optimizer.zero_grad()
loss.backward()
# 梯度更新
optimizer.step()
当对 Dataloader 对象调用 for 循环或 enumerate 时,Dataloader 对象会返回__iter__中定义的迭代器。在使用迭代器时,会根据 Sampler 产生的 index 使用 Fetcher 类对象,Fetcher 对象使用 Dataset 的索引接口访问数据,也就是 sample 和 target 给 Dataloader 对象。
首先看 Dataloader 中的__iter__方法:
class DataLoader(Generic[T_co]):
...
def _get_iterator(self) -> '_BaseDataLoaderIter':
# 单线程场景
if self.num_workers == 0:
return _SingleProcessDataLoaderIter(self)
# 多线程场景
else:
self.check_worker_number_rationality()
return _MultiProcessingDataLoaderIter(self)
def __iter__(self) -> '_BaseDataLoaderIter':
# 调用 _get_iterator 方法
if self.persistent_workers and self.num_workers > 0:
if self._iterator is None:
self._iterator = self._get_iterator()
else:
self._iterator._reset(self)
return self._iterator
else:
return self._get_iterator()
于是我们需要关注的是_SingleProcessDataLoaderIter 和 _MultiProcessingDataLoaderIter 类,首先分析较为简单的_SingleProcessDataLoaderIter 类。
单线程场景
在这种场景下,num_workers 设置为0:
class _SingleProcessDataLoaderIter(_BaseDataLoaderIter):
def __init__(self, loader):
super(_SingleProcessDataLoaderIter, self).__init__(loader)
assert self._timeout == 0
assert self._num_workers == 0
# 调用 create_fetcher 创建 Fetcher 对象,create_fetcher 代码见下面
self._dataset_fetcher = _DatasetKind.create_fetcher(
self._dataset_kind, self._dataset, self._auto_collation, self._collate_fn, self._drop_last)
# _SingleProcessDataLoaderIter 继承自 _BaseDataLoaderIter,_
# BaseDataLoaderIter 中的__next__方法调用子类的 _next_data 方法
def _next_data(self):
index = self._next_index()
data = self._dataset_fetcher.fetch(index)
if self._pin_memory:
data = _utils.pin_memory.pin_memory(data, self._pin_memory_device)
return data
create_fetcher 方法:
class _DatasetKind(object):
Map = 0
Iterable = 1
@staticmethod
def create_fetcher(kind, dataset, auto_collation, collate_fn, drop_last):
if kind == _DatasetKind.Map:
return _utils.fetch._MapDatasetFetcher(dataset, auto_collation, collate_fn, drop_last)
else:
return _utils.fetch._IterableDatasetFetcher(dataset, auto_collation, collate_fn, drop_last)
由于我们使用的数据集是 map 风格的,这里会创建一个 _MapDatasetFetcher 对象,该类的定义我们已经在上文介绍 Fetcher 类时介绍过,可以回头看看。另外,_SingleProcessDataLoaderIter 中没有定义__iter__和__next__方法是因为这两个方法定义在基类中,_BaseDataLoaderIter 定义如下:
class _BaseDataLoaderIter(object):
def __init__(self, loader: DataLoader) -> None:
self._dataset = loader.dataset
self._dataset_kind = loader._dataset_kind
self._auto_collation = loader._auto_collation
self._num_workers = loader.num_workers
self._sampler_iter = iter(self._index_sampler)
self._collate_fn = loader.collate_fndtype=torch.int64).random_(generator=loader.generator).item()
...
# 返回自身,自身是一个迭代器
def __iter__(self) -> '_BaseDataLoaderIter':
return self
# _next_index 调用 Sampler 对象生成
def _next_index(self):
return next(self._sampler_iter) # may raise StopIteration
# _next_data 方法定义在子类中
def _next_data(self):
raise NotImplementedError
# 调用_next_data 方法生成数据
def __next__(self) -> Any:
with torch.autograd.profiler.record_function(self._profile_name):
data = self._next_data()
self._num_yielded += 1
return data
def __len__(self) -> int:
return len(self._index_sampler)
因此 _SingleProcessDataLoaderIter 的迭代器在被调用__iter__和__next__方法时可以返回一个 batch 的数据或者 一个数据。注意在这种场景下(单线程),所有的步骤都是串行的。
多线程场景
当 num_workers 设置为 > 0 的值,DataLoaderIter 会返回 _MultiProcessDataLoaderIter 对象。我们先从宏观角度看看 _MultiProcessDataLoaderIter 的工作原理。这里引用网上看到的一幅图,很形象地把这个数据流向表达了出来:
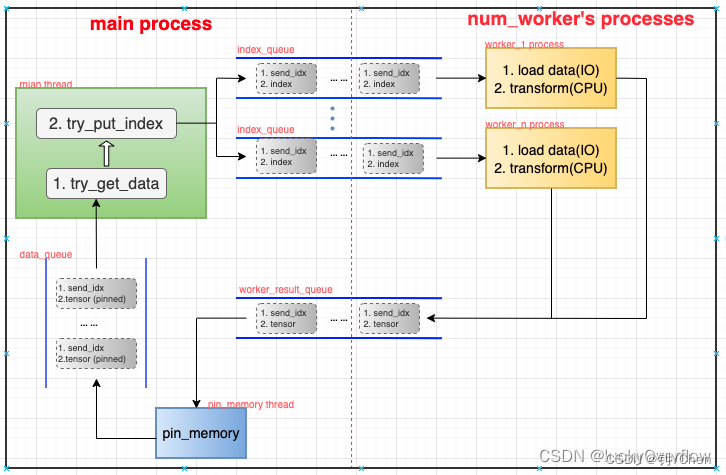
实际上,多线程场景下迭代器做的工作跟单线程场景下的迭代器是一样的,但是会在 Fetcher 和 pin_memory 处使用单独的线程进行。这是因为 Fetcher 处的操作涉及 I/O,这很容易在训练过程中成为瓶颈,因此设置多个线程进行 I/O 来与网络训练的计算 overlap,I/O 的问题可以参考我之前的文章:线程池大小选择:针对 I/O 密集型场景和 CPU 密集型场景。而 pin_memory 则涉及内存的拷贝,这是一个容易让 CPU 成为瓶颈的部分,所以也设置一个线程专门用于拷贝 Tensor。
构成_MultiProcessDataLoaderIter 对象的主要是多个线程和多个队列,这些队列充当缓冲区,用于存放生产者进程/线程的数据,并提供给消费者进程/线程消费。
- 主线程在 Dataloader 调用 __next__方法时,从 data_queue 中取一个/一组(batch)数据,然后通过 sampler 获得一个/一组(batch)index 并放入到提供给子线程消费的 index_queue 中。
- I/O 子线程负责每次从 index_queue 中取一个下标,并将其从磁盘加载到内存中,然后进行用户指定的 transform 操作(预处理,也可以不指定),之后将下标对应的数据送到 worker_result_queue 中。
- pin_memory 子线程负责将数据从 worker_result_queue 中取出并将其从 pageable_tensor 转化为 pinned_tensor,也就是将数据拷贝到锁页内存中,这样在训练时,GPU 才可以将内存中的 Tensor 拷贝到 GPU 的显存中(GPU 只能访问锁页内存)。
多个队列作为多个生产者和消费者线程的缓冲区:
- index_queue:存放(send_idx,index),其中的 index 为 Fetcher 去 dataset 中取数据的下标,send_idx 用于保证数据的有序性,后面会讲到。
- worker_result_queue:存放(send_idx, pageable_tensor)
- data_queue:存放(send_idx, pinned_tensor)
首先看看_MultiProcessDataLoaderIter 中的主要函数:
class _MultiProcessingDataLoaderIter(_BaseDataLoaderIter):
def __init__(self, loader):
# 调用时机:用户初始化 DataLoader 对象时,若num_worker > 0,便会构造_MultiProcessDataLoaderIter 对象,进入该__init__方法。
# 职责:从 DataLoader 对象中获得用户参数,初始化 numworker 个子进程、pin_memory线程以及多个队列queue,
# 并下发 2*num_worker 数量的任务(即index)。
def _try_get_data(self, timeout=_utils.MP_STATUS_CHECK_INTERVAL):
# 调用时机:由 _get_data 方法调用。
# 职责:从 data_queue 中取数据,并对各种异常进行处理。
def _get_data(self):
# 调用时机:由 _next_data 方法调用。
# 职责:调用 _try_get_data 方法获取数据,并检查数据是否获取成功。
def _next_data(self):
# 调用时机:用户每次对 DataLoader 对象进行for循环迭代时,都会进入该方法。
# 职责:作为迭代器的入口,该方法负责返回用户需要的数据,每次的工作流程如下:
# 1、检查本次需要获取的数据是否已在缓存中,若在则直接从缓存取。
# 2、若不在缓存中,则调用 _get_data 获取数据。
# 3、若该数据不是本次应该等待的数据(即该数据的 idx 不等于 recvd_idx),则存到缓存中,返回第一步,否则进入下一步。
# 4、获取数据后,调用 _process_data 做进一步处理并返回数据。
def _try_put_index(self):
# 调用时机:由 _process_data 方法调用。
# 职责:1、从 sampler 对象中获得 index (调用父类的 _next_index 方法)
# 2、将 (send_idx, index) 送入对应的 index_queue 中
# 3、send_idx 加一
def _process_data(self, data):
# 调用时机:由 _next_data 方法调用。
# 职责:先对 rcvd_idx 加一,再调用_try_put_index 方法,然后返回之前从 _get_data 中获取的数据。
接下来详细看看源码中的具体实现,中间仍旧省去了比较多保证鲁棒性的代码,我们主要看核心部分。
__init__方法
def __init__(self, loader):
super(_MultiProcessingDataLoaderIter, self).__init__(loader)
...
# 创建多进程/线程间用于维护数据顺序的数据结构
self._send_idx = 0 # idx of the next task to be sent to workers
self._rcvd_idx = 0 # idx of the next task to be returned in __next__
self._task_info = {
}
# 根据用户参数将 num_worker 个子进程和 pin_memory 线程创建并初始化
self._index_queues = []
self._workers = []
for i in range(self._num_workers):
index_queue = multiprocessing_context.Queue()
# index_queue.cancel_join_thread()
w = multiprocessing_context.Process(... ...)
w.daemon = True
w.start()
self._index_queues.append(index_queue)
self._workers.append(w)
if self._pin_memory:
self._data_queue = queue.Queue()
pin_memory_thread = threading.Thread(... ...)
pin_memory_thread.daemon = True
pin_memory_thread.start()
else:
self._data_queue = self._worker_result_queue
# 3、发送 2*num_worker 个 index,让多进程/线程工作起来
for _ in range(2 * self._num_workers):
self._try_put_index()
其中用到了 send_idx, rcvd_idx 和 task_info,这三个成员实际上是用于保证数据的有序性的。在单线程场景中,由于各个步骤都是串行执行,所以迭代器通过 sampler 对象得到 index,在去磁盘中取数据,那么每次取的数据顺序都和产生 index 的顺序保持一致。但是在多线程场景中,这个顺序一致性就难以保证了。因为 index 有可能会被放入多个 index_queue 中的任意一个,而且子线程在使用 CPU 的过程中(transform)也可能因为时间片用完而被中断,因此,我们没法保证 worker_result_queue 中的数据顺序和产生 index 时的顺序一致。那么,DataLoader 取数据时,顺序就有可能错乱,我们要解决这个问题。
因此引入了 send_idx,rcvd_idx 和 task_info。send_idx 标识主线程中产生 index 的序号,rcvd_idx 标识主线程成功获取到的数据的序号,而 task_info 是一个缓冲区,用于保存主线程从 data_queue 中获取到乱序的数据。所以__init__中主要是初始化这些成员,具体的使用逻辑将在后面的函数分析。
_next_data方法
_next_data 方法就是迭代器在调用__next__时实际调用的函数:
def _next_data(self):
while True:
...
# 检查本次要拿的数据是否已经在缓存中
if len(self._task_info[self._rcvd_idx]) == 2:
data = self._task_info.pop(self._rcvd_idx)[1]
return self._process_data(data)
# 数据不在缓存中,调用_get_data从queue中拿数据
idx, data = self._get_data()
# 检查刚拿的数据是否顺序一致
if idx != self._rcvd_idx:
# 不一致则放到缓存中
self._task_info[idx] += (data,)
else:
del self._task_info[idx]
# 一致则交给_process_data处理
return self._process_data(data)
上面的代码展示了保证下标顺序一致性的逻辑,其中 task_info 实现为一个哈希表,其中存放着 send_idx 和数据(Tensor)的映射。所以当迭代器需要返回一个数据时,先检查 task_info 中有没有这个数据,没有再从 data_queue 中取(调用_get_data 方法)。取出来之后,如果 send_idx 不等于 rcvd_idx,则仍旧需要把这个数据加入 task_info 缓存,否则则进行下一步处理(_process_data)。
_get_data 方法
def _get_data(self):
if self._timeout > 0:
success, data = self._try_get_data(self._timeout)
if success:
return data
else:
raise RuntimeError('DataLoader timed out after {} seconds'.format(self._timeout))
elif self._pin_memory:
while self._pin_memory_thread.is_alive():
success, data = self._try_get_data()
if success:
return data
else:
raise RuntimeError('Pin memory thread exited unexpectedly')
else:
while True:
success, data = self._try_get_data()
if success:
return data
_get_data 方法主要调用了_try_get_data 函数来从 data_queue 中获取数据,其他主要是用于保证鲁棒性的代码。
_try_get_data 方法
def _try_get_data(self, timeout=_utils.MP_STATUS_CHECK_INTERVAL):
try:
data = self._data_queue.get(timeout=timeout)
return (True, data)
except Exception as e:
...
if isinstance(e, queue.Empty):
return (False, None)
这个部分的逻辑很简单,如果队列中有数据,就返回(True,data),否则返回(False,None)。
_process_data 方法
def _process_data(self, data):
self._rcvd_idx += 1
self._try_put_index()
if isinstance(data, ExceptionWrapper):
data.reraise()
return data
该部分简单地调用 _try_put_index 并返回数据。
_try_put_index 方法
def _try_put_index(self):
try:
# 调用sampler获取index
index = self._next_index()
...
# 将 index 放入空闲活跃的线程对应的队列中
for _ in range(self._num_workers):
worker_queue_idx = next(self._worker_queue_idx_cycle)
if self._workers_status[worker_queue_idx]:
break
# 将获得和 index 和 send_idx 打包送到对应的_index_queue 中
self._index_queues[worker_queue_idx].put((self._send_idx, index))
# 更新用于保证数据顺序一致性的成员
# 因为已经生产并发送了 index,就把 send_idx 加 1 并在 task_info 中创建对象,此时len == 1
self._task_info[self._send_idx] = (worker_queue_idx,)
self._send_idx += 1
其中涉及的逻辑如注释,_try_put_index 方法由 _process_data 调用,该部分负责将 index 送入队列中,并且为了保证顺序一致性,会更新 task_info 和 send_idx。
总结
总算写完了 DataLoader 部分,总结这一块的源码主要是因为公司最近用到了相关的业务,需要对 Dataset 和 DataLoader 进行改造,因此认真读了这一部分的源码。
总而言之,Dataset 和 DataLoader 模块为整个 Pytorch 提供了通用的数据加载和预处理接口,整体代码有很高的鲁棒性。如果说这个模块还有什么可以改进的地方,主要就在于 I/O 的部分,Dataset 在实现 shuffle 操作时,加载数据使用的是随机 I/O,这会大幅降低 I/O