第一章 数据库
1.1 创建表空间
创建表空间:Create tablespace DATA
指定数据库安装路径下的dbf文件:datafile’E:\app\wang\oradata\orcl\DATA01.DBF’
分配大小:size 1024m;
--创建表空间 create tablespace DATA datafile '/oracle11g/app/oradata/hxv11/DATA01.DBF' size 1024m; --增加表空间数据文件 |
1.2 创建用户
打开plsql登录内置sys用户,连接类型为:sysdba
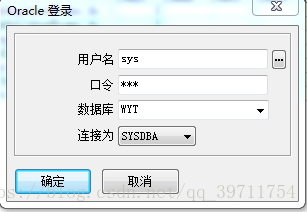

然后选中Users文件夹,右键创建用户
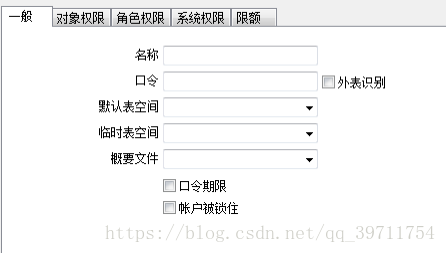
指定用户名、密码、表空间等信息,分配角色权限connect与dba,系统权限
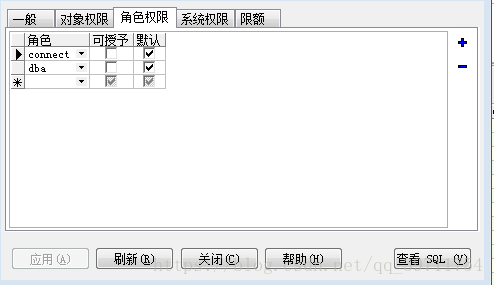
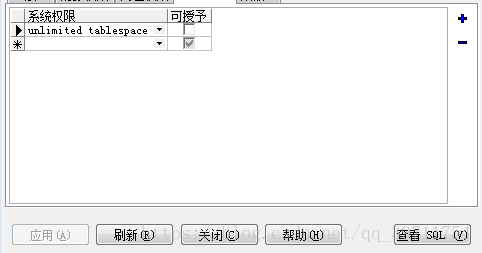
或用以下代码创建:
drop user cgpt cascade; |
1.3 导入导出
1.常用方法(最常用的,简单方便,不容易出错)
数据库导出 : 打开cmd,输入expusername/password@服务器地址/数据库实例file=E:\data.dmp用户名密码均为导出方的,file里面放的是导出文件与路径
Ex:expuser/[email protected]/czy file=E:\shuju.dmp
Exp userid=dzjjyf/dzjjyf@czy file=d:\dzjjyf_2016-07-04.dmp owner=dzjjyf log=d:\aaaa.log |
数据库导入 :打开cmd,输入impusername/password@数据库实例 file=E:\data.dmpfull=y ignore=y用户名密码为本地的,file里面放的是要导入的数据库路径与文件,full=y ignore=y表示有的表已经存在需要忽略
Ex:impusername/password@wyt file=E:\data.dmp full=y ignore=y
imp userid=dzjjyf/dzjjyf@cwd file=d:\dzjjyf_2016-07-04.dmp fromuser=dzjjyf touser=dzjjyf log=d:\aaaa.log |
2.其他方法
打开plsql→工具→导出用户对象→选择需要导出的用户
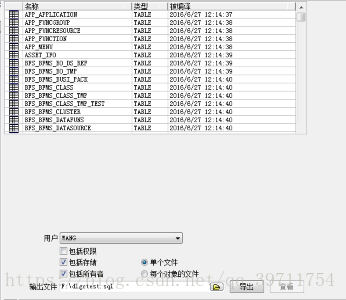
指定输出文件
或选中表点击鼠标右键→导出数据

导出需要的表,指定输出文件,指定用来导出的工具
导入数据也在工具里面与导出类似,需指定导入文件
1.4 cmd命令下新建数据库用户
#sqlplus /nolog
SQL>conn /as sysdba;
SQL>create user usernameindentified by password;
SQL>grant dba to username;
SQL>grant connect to username;
SQL>conn username/password;
1.5 oracle数据库常用操作代码
1.5.1 新建表
create table student(
id varchar2(128) primary key,
sno varchar2(16) not null,
name varchar2(32) not null,
);
1.5.2 添加注释
comment on column student.id is '主键';
comment on column student.sno is '学生学号';
comment on column student.name is '学生姓名';
1.5.3 添加数据
insert into student(id,sno,name)values(1,'S20180115','张三');
insert into student(id,sno,name)values(2,'S20180116','李四');
1.5.4 删除数据
①delete
delete from 表名 where 条件;
例:delete from student where id=2;
②truncate
truncate table 表名;
例:truncate table student;
③drop
drop table 表名;
例:drop table student;
区别:
delete属于DML,在没有commit时不会生效,truncate和drop是直接生效的,而且不可以回滚。
delete后不加where语句时和truncate一样,删除表中所有数据。
delete和truncate不删除表的结构,只针对表中的数据删除。
drop将会删除表的结构,被依赖的约束(constrain),触发器(trigger),索引(index)。依赖于该表的存储过程/函数将保留,但是变为invalid状态。
truncate会释放占用空间,drop和delete不会。
删除速度:drop>truncate>delete
相对来说,使用drop 和 truncate要比使用delete危险,当使用drop 和 truncate 时不能回滚。delete相对安全,可以回滚,需要commit以后才会提交,并且不会删除表结构,也不会释放表所占用的空间。
1.5.5 修改数据
update 表名 set 字段名1=值1,字段名2=值2,…… where 条件;
例:update student sno=’ S20180118’,name=’王五’ where id=1;
1.5.6 新增字段
alter table 表名 add(字段名字段类型默认值是否为空);
例:alter table student add(tiem number(14));
例:alter table student add(time number(14)default'空' not null);
1.5.7 删除字段
alter table 表名 drop column 字段名;
例:alter table student drop column time;
1.5.8 字段重命名
alter table 表名 rename column 列名 to 新列名;
例:alter table student rename column time tonew_time;
1.5.9 表的重命名
alter table 表名 rename to 新表名;
例:alter table student rename to new_student;
1.5.10 将表2的数据插入到表1
insert into 表1(字段名1,字段名2,……) select (字段名1,字段名2,……) from 表2;
1.6 聚合函数
平均值:avg
select avg(score) from student;
求和:sum
select sum(score) from student;
当有重复的数据时,重复数据只列出一次,用distinct
select avg(distinctscore) from student;
最大值:max
select max(max) from student;
最小值:min
select min(min) from student;
数据统计:count
select count(*) from student;