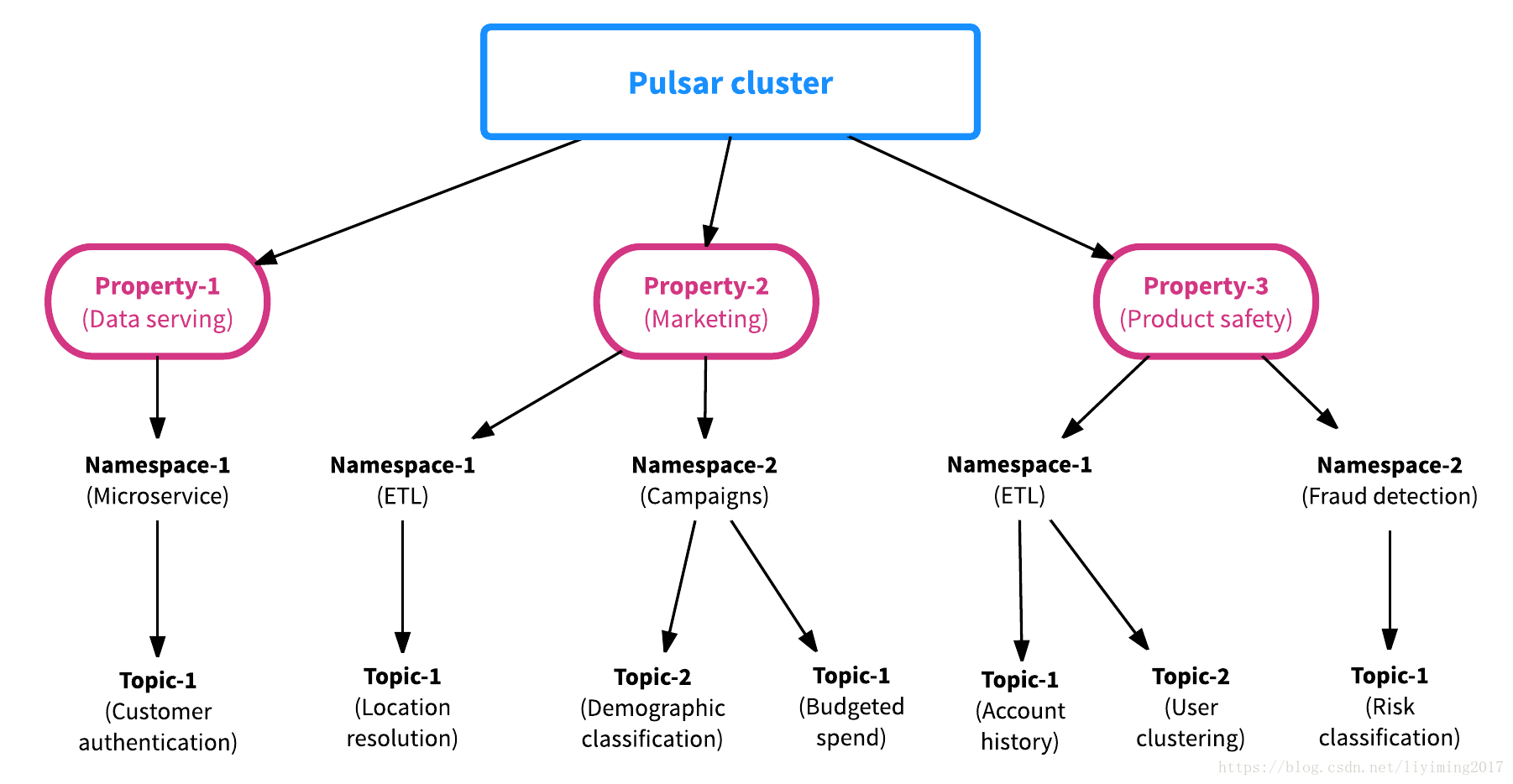
pulsar和kafka最显而易见的区别是,pulsar支持多租户,有着资产和命名空间的概念,资产代表系统里的租户。假设有一个Pulsar集群用于支持多个应用程序(就像Yahoo那样),集群里的每个资产可以代表一个组织的团队、一个核心的功能或一个产品线。一个资产可以包含多个命名空间,一个命名空间可以包含任意个主题。
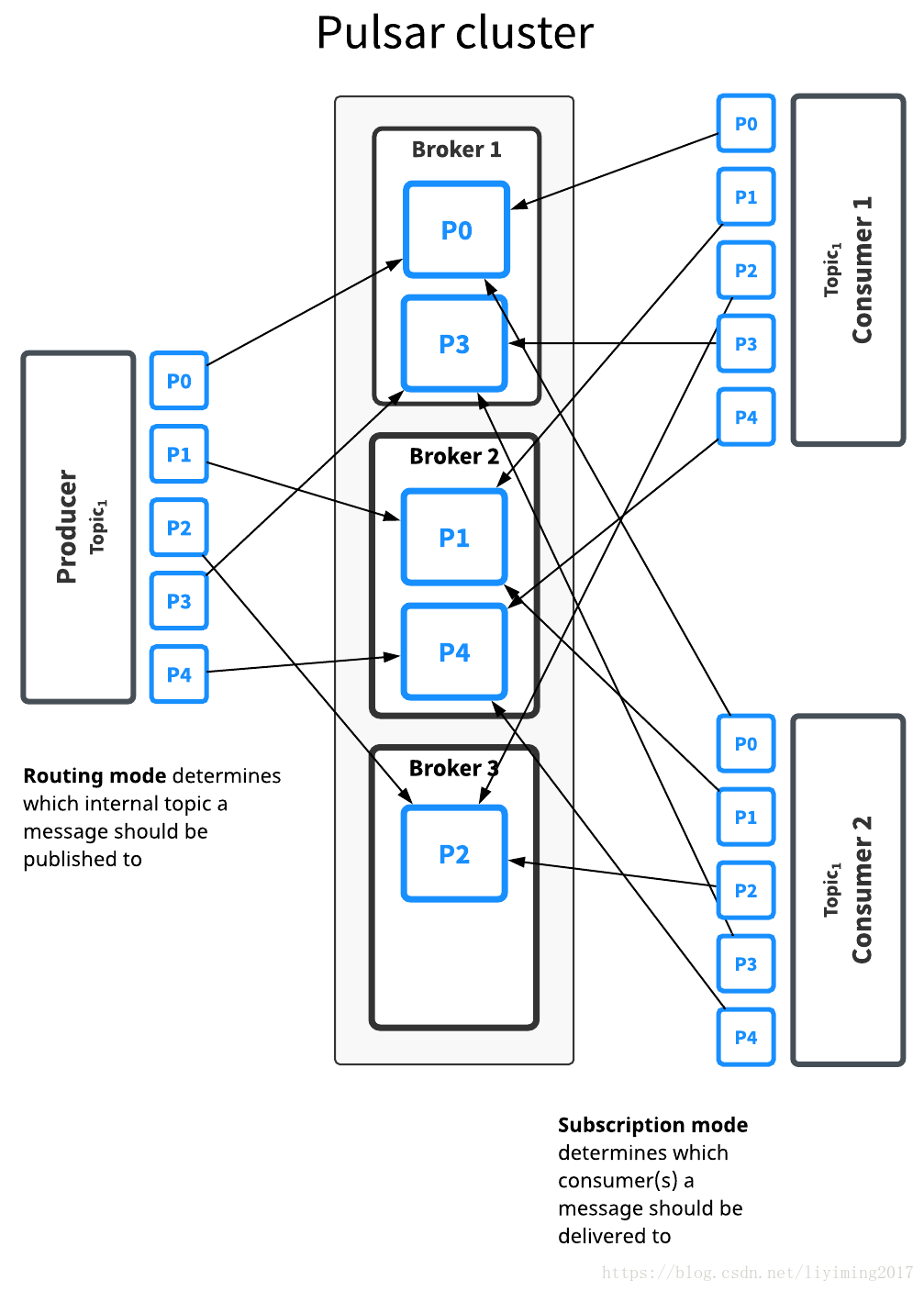
分区:pulsar和kafka一样都支持主题的多分区。
持久化:kafka文件存储,pulsar采用Apache BookKeeper存储。这也是pulsar的一个显著优点,kafka文件存储分布在集群的各个broker上,一旦broker挂掉或者新的broker加入就会进行副本的leader选举或者分区平衡操作,这样做会消耗kafka的性能。而pulsar的broker是无状态的,数据存储在BookKeeper中,服务和数据是分离的。所以它并不会面临这种问题,可以随意进行集群的调整。此外kafka的broker还要关心存储量是否超出了自己硬盘的空间。而pulsar不存在这个问题。
发布的 2.2 版本中,Pulsar 将会引入了 SQL,方便对存储在 Pulsar 里面的数据进行 SQL 查询和分析。Pulsar SQL 借助 Presto,为用途提供了高效可扩展的查询。这种高效的查询,主要得益于 Pulsar 底层的存储系统 Apache BookKeeper。
《Pulsar(挑战kafka新一代消息系统)官方文档翻译-入门和实战-搭建本地独立集群环境
《Pulsar(挑战kafka新一代消息系统)官方文档翻译-入门必看-概念和架构-(二)消息核心概念(Messaging Concepts)》
Apache bookkeeper是一个分布式,可扩展,容错(多副本),低延迟的存储系统,其提供了高性能,高吞吐的存储能力。Bookkeeper实现了append方式的写操作。
Bookkeeper有一个非常成功的应用案例:apache pulsar,是近年雅虎开源的一个MQ,pulsar相对于kafka来说,在存储上有优势,kafka的单个partition的存储容量受到了部署kafka的broker的硬盘容量限制,当有大量的数据需要MQ支持时,partition可能会遇到瓶颈而无法扩展。当然可以预先增加partition的数量和broker的数量来满足MQ的存储需求,但是当消息需要存储的时候相对较长或者数据量非常多之后,比如存储一个月,需要按月做数据的回拉跑计算任务,这种场景对kafka的集群来说是有非常大的浪费的,因为我们需要的是更多的存储,不是更多了broker的能力,bookkeeper为pulsar提供了存储计算分离的架构支持,存储和pulsar的broker能分别扩展,这是kafka不具备的
基本概念
-
Entry:Entry是存储到bookkeeper中的一条记录
-
Ledger:可以认为ledger是用来存储Entry的,多个Entry序列组成一个ledger
-
Bookie:一个Bookie就是bookkeeper的一台存储服务器,用于存储ledger,一般来说存储的是ledger的一段,因为存储是分布式的,每个ledger会存储在多个bookie上
-
MetaData Storage:元数据存储,是用于存储bookie相关的元数据,比如bookie上有哪些ledger,bookkeeper目前使用的是zk存储,所在在部署bookkeeper前,要先有zk集群
-
数据存储文件与缓存:
-
Journal:其实就是bookkeeper的WAL(write ahead log),用于存bookkeeper的事务日志,journal文件有一个最大大小,达到这个大小后会新起一个journal文件
-
Entry log:存储entry的文件,我理解ledger是一个逻辑上的概念,不同ledger中的entry会先按ledger聚合,然后写入entry log文件中。同样,entry log会有一个最大大小,达到最大大小后会新起一个新的entry log文件
-
Index file:ledger的索引文件,ledger中的entry被写入到了entry log文件中,索引文件用于邓颖超entry log文件中每一个ledger做索引,记录每个ledger在entry log中的存储位置以及数据在entry log文件中的长度
-
Ledger cache:用于缓存索引文件的,加快查找效率
-
数据落盘:内存中会存储一个LastLogMark,其中包含txnLogId(journal文件的id)和txnLogPos(journal文件中的位置),entry log文件和index文件都会先在内存中被缓存,当内存达到一定值或者离上一次刷盘过期了一段时间(定时线程)后,会触发entry log文件和index文件的刷盘,之后再将LastLogMark持久化,当lastLogMark被持久化后,表示在lastLogMark之前的entry和索引都已经写到了磁盘上,这个时候可以将lastLogMark之前的journal文件清掉,如果LastLogMark在持久化前出现了宕机,可以通过journal文件做恢复,保证了数据不丢
-
Data Compaction:数据的合并,有点类似于hbase的compact过程。在bookie上,虽然entry log在刷盘前会按ledger做聚合,但是因数数据会不断的新增,每个leadger的数据会交差存储在entry log文件中,而bookie上有一个用于做垃圾回收的线程,该线程会将没有关联任何ledger的entry文件进行删除,以便回收磁盘空间,而compaction的目的则是为了避免entry log中只有少数的记录是有关联的ledger的情况,不能让这样的entry log文件一直占用磁盘空间,所以垃圾收集线程会将这样的entry log中有关联ledger的entry复制到一个新的entry log文件中(同时修改索引),然后将老的entry log文件删除。与hbase类似,bookkeeper的compaction也分为两种:
-
Minor compaction:当entry log中有效的entry只占20#以下时做compaction
-
Major compaction:当entry log中有效的占到80%以下时就可开始做compaction
提供的API
Bookkeeper提供了两个层次的api:
- Ledger API:用于直接操作ledger,相对比较复杂,是bookkeeper提供的底层api
- Distributed Log:分布式log,是基于ledger api的高层次api,相对更简单易用
分布式Log架构:
分布式log api写入的log,会以写入相同的顺序存储在bookkeeper上:
Bookkeeper的适用场景
- WAL:bookkeeper可作为wal方案
- 流存储:比如pulsar通过bookkeeper存储消息
- 对象/Blob存储
Presto是一个facebook开源的分布式SQL查询引擎,适用于交互式分析查询,数据量支持GB到PB字节。presto的架构由关系型数据库的架构演化而来。presto之所以能在各个内存计算型数据库中脱颖而出,在于以下几点:
- 清晰的架构,是一个能够独立运行的系统,不依赖于任何其他外部系统。例如调度,presto自身提供了对集群的监控,可以根据监控信息完成调度。
- 简单的数据结构,列式存储,逻辑行,大部分数据都可以轻易的转化成presto所需要的这种数据结构。
- 丰富的插件接口,完美对接外部存储系统,或者添加自定义的函数。
本文从外到内,依次来介绍presto。
架构
Presto采用典型的master-slave模型:
- coordinator(master)负责meta管理,worker管理,query的解析和调度
- worker则负责计算和读写。
- discovery server, 通常内嵌于coordinator节点中,也可以单独部署,用于节点心跳。在下文中,默认discovery和coordinator共享一台机器。
在worker的配置中,可以选择配置:
- discovery的ip:port。
- 一个http地址,内容是service inventory,包含discovery地址。
- 一个本地文件地址
{
"environment": "production",
"services": [
{
"id": "ffffffff-ffff-ffff-ffff-ffffffffffff",
"type": "discovery",
"location": "/ffffffff-ffff-ffff-ffff-ffffffffffff",
"pool": "general",
"state": "RUNNING",
"properties": {
"http": "http://192.168.1.1:8080"
}
}
]
}2和3的原理是基于service inventory, worker 会动态监听这个文件,如果有变化,load出最新的配置,指向最新的discovery节点。
在设计上,discovery和coordinator都是单节点。如果有多个coordinator同时存活,worker 会随机的向其中一个汇报进程和task状态,导致脑裂。调度query时有可能会发生死锁。
discovery和coordinator可用性设计。由于service inventory的使用,监控程序可以在发现discovery挂掉后,修改service inventory中的内容,指向备机的discovery。无缝的完成切换。coordiantor的配置必须要在进程启动时指定,同一个集群中无法存活多个coordinator。因此最好的办法是和discovery配置到一台机器。 secondary机器部署备用的discovery和coordinator。在平时,secondary机器是一个只包含一台机器的集群,在primary宕机时,worker的心跳瞬间切换到secondary。
数据模型
presto采取三层表结构:
- catalog 对应某一类数据源,例如hive的数据,或mysql的数据
- schema 对应mysql中的数据库
- table 对应mysql中的表
presto的存储单元包括:
- Page: 多行数据的集合,包含多个列的数据,内部仅提供逻辑行,实际以列式存储。
- Block:一列数据,根据不同类型的数据,通常采取不同的编码方式,了解这些编码方式,有助于自己的存储系统对接presto。
不同类型的block:
- array类型block,应用于固定宽度的类型,例如int,long,double。block由两部分组成
- boolean valueIsNull[]表示每一行是否有值。
- T values[] 每一行的具体值。
2. 可变宽度的block,应用于string类数据,由三部分信息组成
-
- Slice : 所有行的数据拼接起来的字符串。
- int offsets[] :每一行数据的起始便宜位置。每一行的长度等于下一行的起始便宜减去当前行的起始便宜。
- boolean valueIsNull[] 表示某一行是否有值。如果有某一行无值,那么这一行的便宜量等于上一行的偏移量。
3. 固定宽度的string类型的block,所有行的数据拼接成一长串Slice,每一行的长度固定。
4. 字典block:对于某些列,distinct值较少,适合使用字典保存。主要有两部分组成:
-
- 字典,可以是任意一种类型的block(甚至可以嵌套一个字典block),block中的每一行按照顺序排序编号。
- int ids[] 表示每一行数据对应的value在字典中的编号。在查找时,首先找到某一行的id,然后到字典中获取真实的值。
插件
了解了presto的数据模型,就可以给presto编写插件,来对接自己的存储系统。presto提供了一套connector接口,从自定义存储中读取元数据,以及列存储数据。先看connector的基本概念:
- ConnectorMetadata: 管理表的元数据,表的元数据,partition等信息。在处理请求时,需要获取元信息,以便确认读取的数据的位置。Presto会传入filter条件,以便减少读取的数据的范围。元信息可以从磁盘上读取,也可以缓存在内存中。
- ConnectorSplit: 一个IO Task处理的数据的集合,是调度的单元。一个split可以对应一个partition,或多个partition。
- SplitManager : 根据表的meta,构造split。
- SlsPageSource : 根据split的信息以及要读取的列信息,从磁盘上读取0个或多个page,供计算引擎计算。
插件能够帮助开发者添加这些功能:
- 对接自己的存储系统。
- 添加自定义数据类型。
- 添加自定义处理函数。
- 自定义权限控制。
- 自定义资源控制。
- 添加query事件处理逻辑。
Presto提供了一个简单的connector : local file connector ,可用于参考如何实现自己的connector。不过local file connector中使用的遍历数据的单元是cursor,即一行数据,而不是一个page。 hive 的connector中实现了三种类型,parquet connector, orc connector, rc file connector。
上文从宏观上介绍了presto的一些原理,接下来几篇文章让我们深入presto 内部,了解一些内部的设计,这对性能调优会有比较大的用处,也有助于添加自定义的operator。
内存管理
Presto是一款内存计算型的引擎,所以对于内存管理必须做到精细,才能保证query有序、顺利的执行,部分发生饿死、死锁等情况。
内存池
Presto采用逻辑的内存池,来管理不同类型的内存需求。
Presto把整个内存划分成三个内存池,分别是System Pool ,Reserved Pool, General Pool。
- System Pool 是用来保留给系统使用的,默认为40%的内存空间留给系统使用。
- Reserved Pool和General Pool 是用来分配query运行时内存的。
- 其中大部分的query使用general Pool。 而最大的一个query,使用Reserved Pool, 所以Reserved Pool的空间等同于一个query在一个机器上运行使用的最大空间大小,默认是10%的空间。
- General则享有除了System Pool和General Pool之外的其他内存空间。
为什么要使用内存池
System Pool用于系统使用的内存,例如机器之间传递数据,在内存中会维护buffer,这部分内存挂载system名下。
那么,为什么需要保留区内存呢?并且保留区内存正好等于query在机器上使用的最大内存?
如果没有Reserved Pool, 那么当query非常多,并且把内存空间几乎快要占完的时候,某一个内存消耗比较大的query开始运行。但是这时候已经没有内存空间可供这个query运行了,这个query一直处于挂起状态,等待可用的内存。 但是其他的小内存query跑完后,又有新的小内存query加进来。由于小内存query占用内存小,很容易找到可用内存。 这种情况下,大内存query就一直挂起直到饿死。
所以为了防止出现这种饿死的情况,必须预留出来一块空间,共大内存query运行。 预留的空间大小等于query允许使用的最大内存。Presto每秒钟,挑出来一个内存占用最大的query,允许它使用reserved pool,避免一直没有可用内存供该query运行。
内存管理
Presto内存管理,分两部分:
- query内存管理
- query划分成很多task, 每个task会有一个线程循环获取task的状态,包括task所用内存。汇总成query所用内存。
- 如果query的汇总内存超过一定大小,则强制终止该query。
- 机器内存管理
- coordinator有一个线程,定时的轮训每台机器,查看当前的机器内存状态。
当query内存和机器内存汇总之后,coordinator会挑选出一个内存使用最大的query,分配给Reserved Pool。
内存管理是由coordinator来管理的, coordinator每秒钟做一次判断,指定某个query在所有的机器上都能使用reserved 内存。那么问题来了,如果某台机器上,,没有运行该query,那岂不是该机器预留的内存浪费了?为什么不在单台机器上挑出来一个最大的task执行。原因还是死锁,假如query,在其他机器上享有reserved内存,很快执行结束。但是在某一台机器上不是最大的task,一直得不到运行,导致该query无法结束。