简介
MockingBird:
英文翻译:反舌鸟,也可能来自《杀死一只知更鸟》(英语:To Kill a Mockingbird),台译“梅冈城故事”,中国大陆译“杀死一只知更鸟”,直译应为“杀死一只反舌鸟”[注 1],是一部于1960年出版的小说,由美国作家哈珀·李创作,荣获当年度普利策奖
功能介绍
- 可以实现文本、语音的互转
- 可以实现通过语音内容实现语音克隆
安装方法
1.安装Python环境
注意:安装Python 选择3.8 或更高版本
1. 进入官网
https://www.python.org/downloads/
2. 下载安装包
3.进行安装
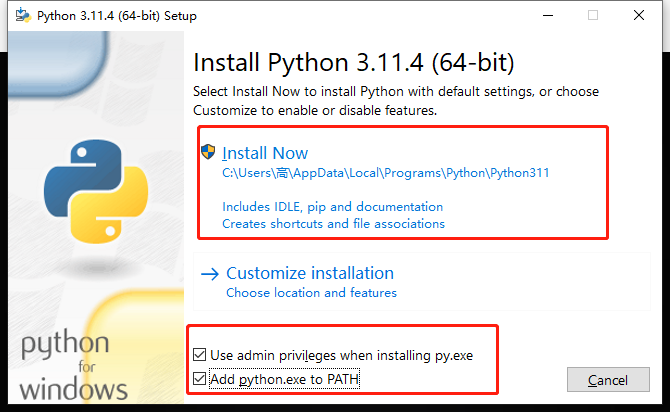
说明你电脑对python的一些限制,点击它然后确定权限就可以了
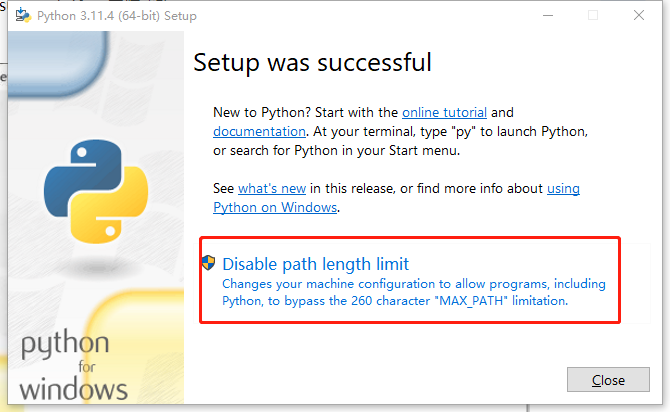
出现这个就安装完成了
4.测试验证
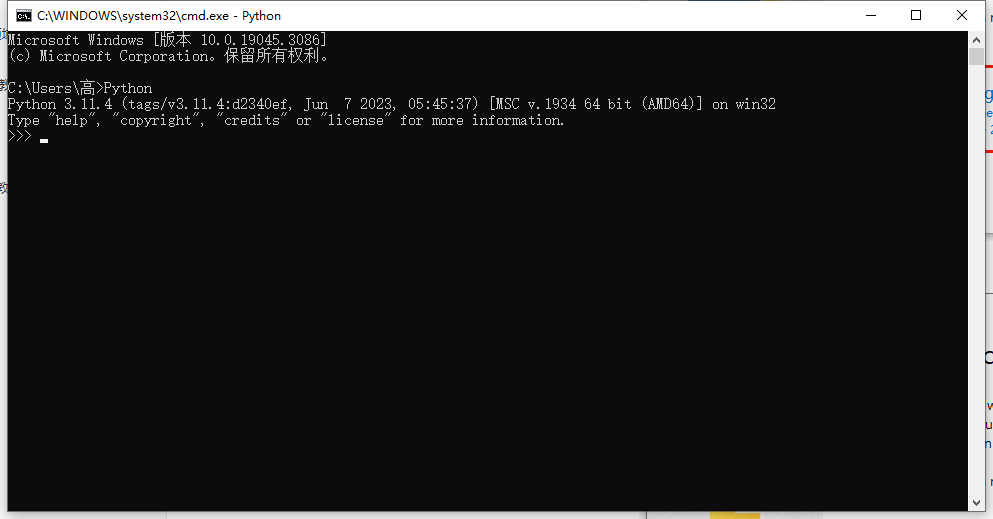
出现这个就代表安装完成,如果要退出:exit() 或者 Ctrl+Z 回车即可
2.安装PyTorch
打开链接:https://pytorch.org/get-started/locally/ 进入官网进行下载
界面如下:

1.如果你的电脑没有独立显卡或者AMD显卡选择如下

2.如果你的电脑是有独显的选择如下

3.选择完成复制安装命令
我的电脑案例是RTX2060显卡,所以我选择的是CUDA11.8
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
新建一个文件夹:

然后用CMD窗口打开,使用管理员权限执行上面的代码:
粘贴后过程是完全自动的,可能需要一点点时间
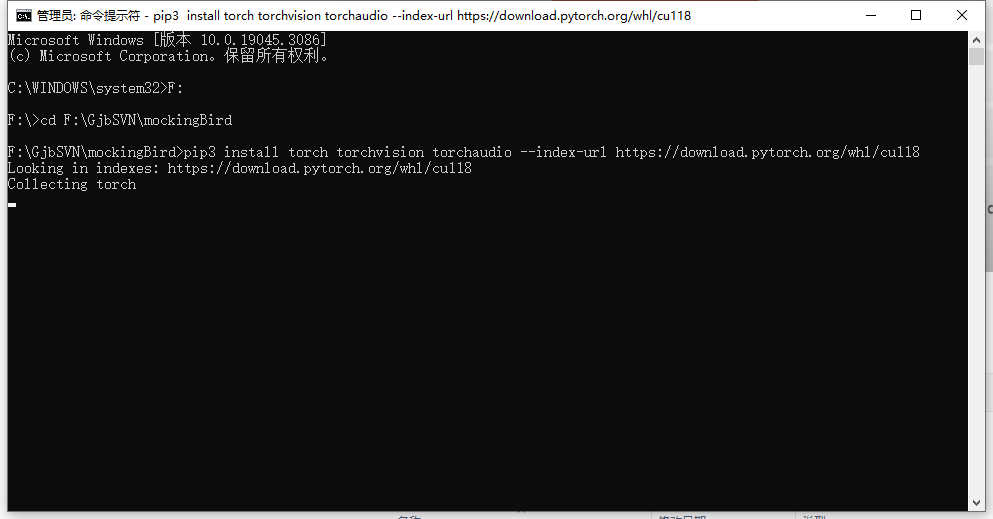
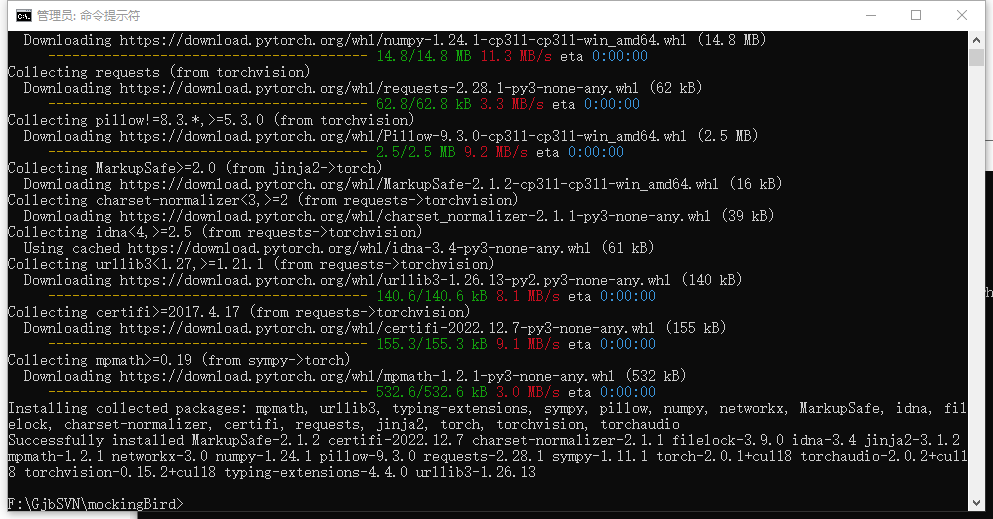
安装完成效果:
3.下载FFmpeg
下载官网:http://ffmpeg.org/download.html#build-windows
1.选择windows
选择左上角:gyan.dev
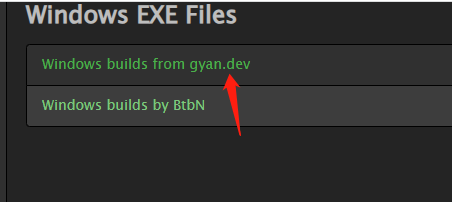
跳转到新页面选择:
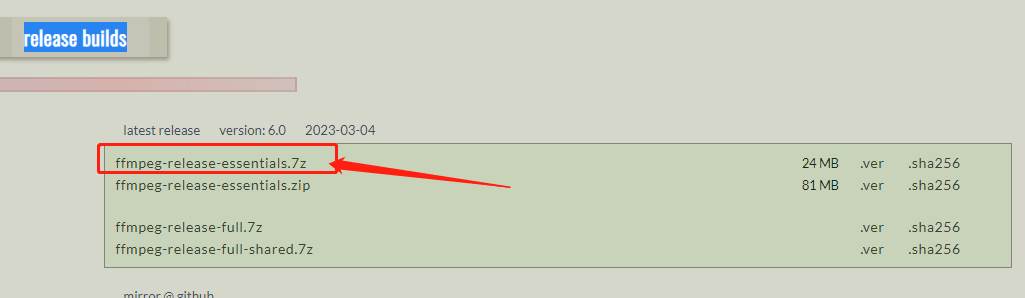
等待下载完成,下载完成后将文件解压到除C盘之外的盘符路径:
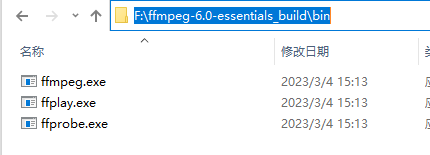
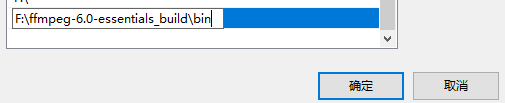
紧接着,将所指的bin路径配置到计算机系统环境变量path中:
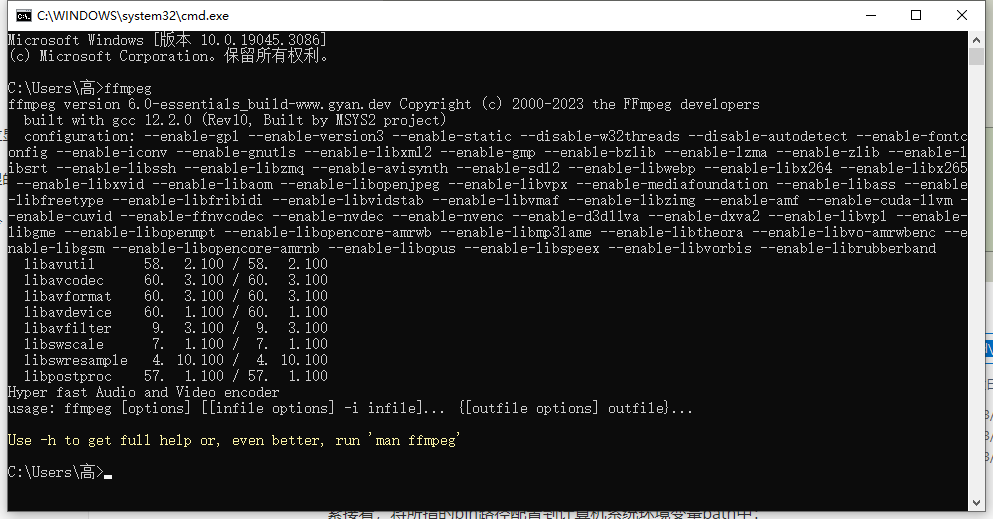
配置后打开cmd窗口,输入ffmpeg如下有输出则说明环境配置成功:
4.下载MockingBird工具
下载github地址:https://github.com/babysor/MockingBird
附上git地址:
https://github.com/babysor/MockingBird.git
[email protected]:babysor/MockingBird.git
解压完成后,打开Mockingbird目录,找到requirements.txt文件
将:monotonic-align==0.0.3
改为
monotonic-align==1.0.0
1.进入MockingBird安装过程
在mockingBird目录打开cmd窗口运行一下命令
在终端下安装剩余的必备环境包:
python -m pip install --upgrade pip
pip install -r requirements.txt
pip install webrtcvad-wheels
2.下载对应的语言训练模型
| 作者 | 下载链接 | 效果预览 | 信息 |
|---|---|---|---|
| 作者 | https://pan.baidu.com/s/1iONvRxmkI-t1nHqxKytY3g 百度盘链接 4j5d | 75k steps 用3个开源数据集混合训练 | |
| 作者 | https://pan.baidu.com/s/1fMh9IlgKJlL2PIiRTYDUvw 百度盘链接 提取码:om7f | 25k steps 用3个开源数据集混合训练, 切换到tag v0.0.1使用 | |
| @FawenYo | https://drive.google.com/file/d/1H-YGOUHpmqKxJ9FRc6vAjPuqQki24UbC/view?usp=sharing 百度盘链接 提取码:1024 | input output | 200k steps 台湾口音需切换到tag v0.0.1使用 |
| @miven | https://pan.baidu.com/s/1PI-hM3sn5wbeChRryX-RCQ 提取码:2021 | 150k steps 注意:根据issue修复 并切换到tag v0.0.1使用 |
下载好的模型保存在以下目录
3.确保模型正确放置后启动程序
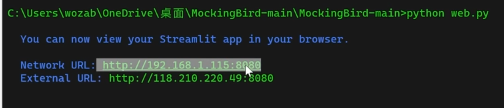
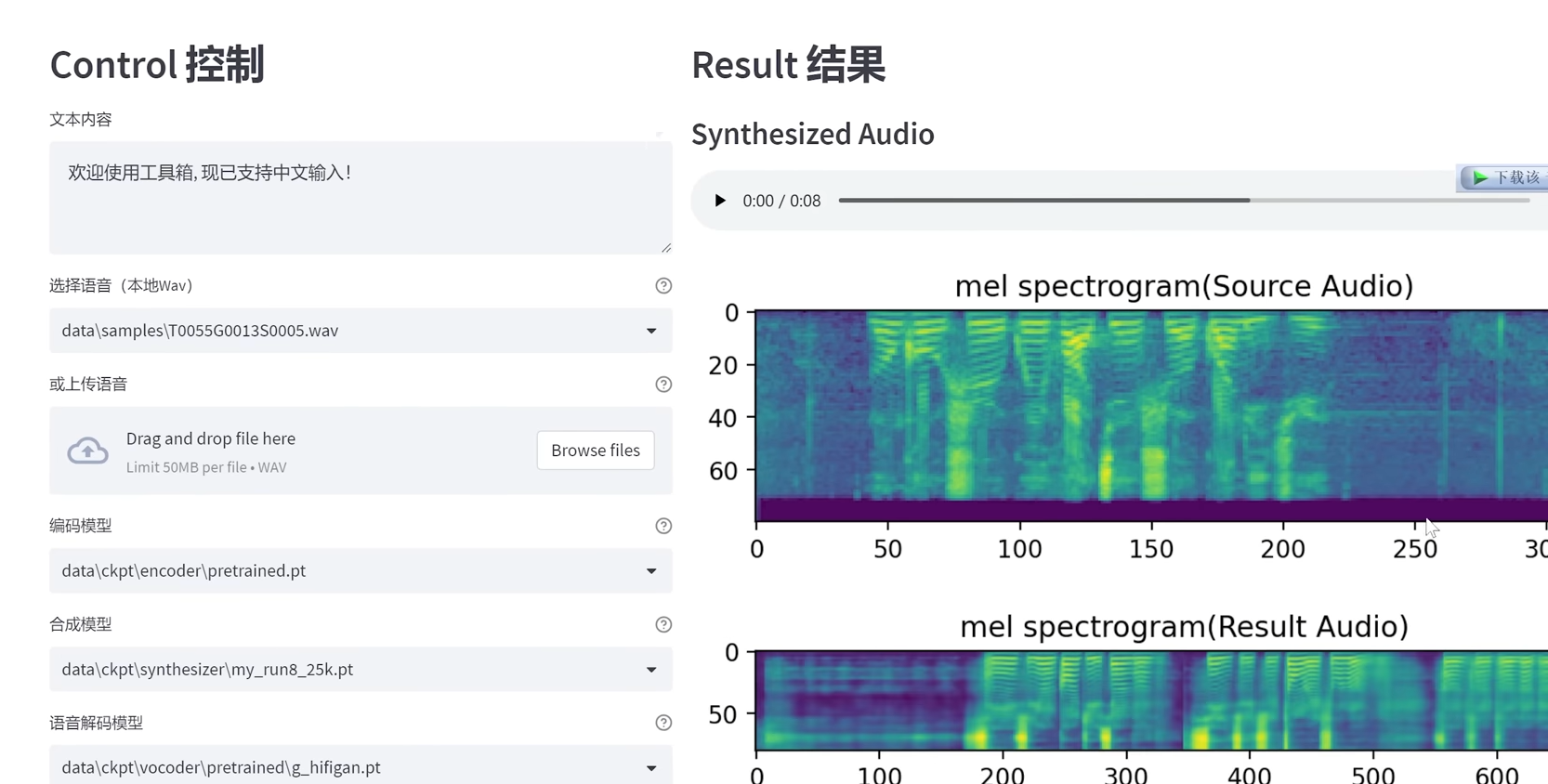
出现这行代表程序已经驱动在8080端口,使用浏览器访问出现以下界面:
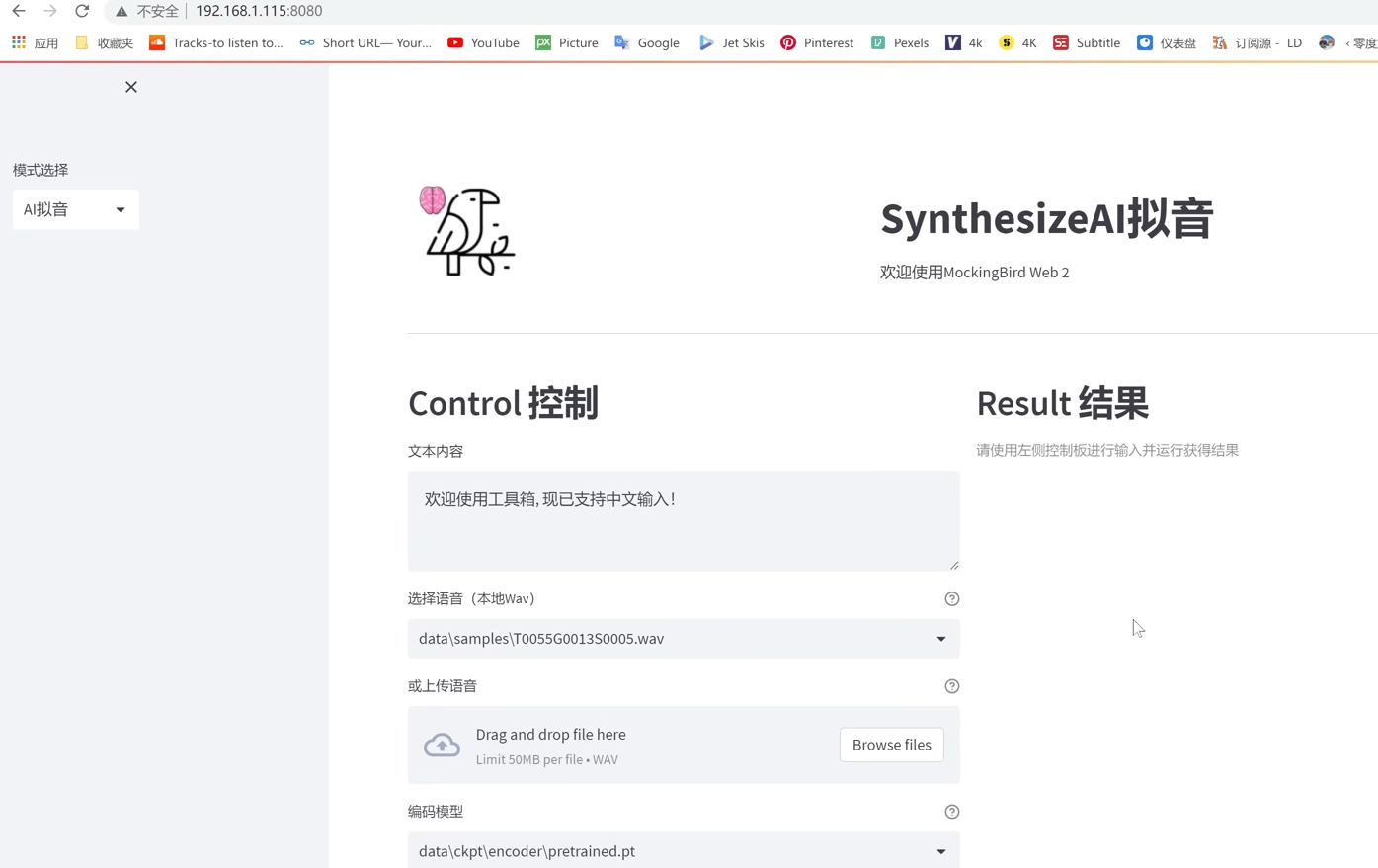
在控制界面输入文字内容,点击生成,在右侧就可以按照特定的语音模型生成出我们要的文字内容了