一、引言
线上出现了服务之间调用存在延时,从链路追踪可以看到X服务发出请求,1s左右Y服务才收到请求,虽然最终排查出是TCP丢包重试,但是过程中还是有许多阶段性排查方向的,而且最终确定结论的抓包实验也挺有意思。
二、排查
1、Hystrix
怀疑的第一个方向是Hystrix线程池打满了,执行时间又比较长,队列等待所以产生延时。
仔细考虑下现象,是x发出和y接收直接间隔1s,那就不会是在队列等待了。而且如果真的是线程池打满,队列等待这么久,这种大概率会导致后续请求被熔断告警。
Hystrix排除。
2、Eurkea
eurkea获取目标ip也被怀疑过,x缓存的注册表过期,从eurkea取ip慢了,但是和Hystrix类似,也可以被排除。
3、服务网格
到了这一步就只能抓包了,抓包需要运维操作,抓包还是滚动覆盖的,所以开发人员需要盯着链路追踪,发生的时候及时让运维把文件拷下来。
如果能在代码和中间件维度定位原因,基本是不会选择抓包,太麻烦。
服务网格是服务之间通信的控制器。Istio由Google、IBM和Lyft创建的服务网络的开源实现。
Istio可以:流量管理。获取服务之间的依赖、服务调用的流量走向。验证身份服务,并提供保护服务流量的能力。
从x到127.0.0.1本地,其实就是通信服务网格的过程。
所以服务请求x->y,实际上是x-> x. Istio-> y. Istio->y,那么有没有可能是服务网格之间通信或者服务与本地网格之间通信的问题,但是从tcp包看起来不是。接下来就是仔细查看tcp的消息,寻找原因。
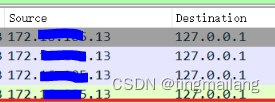
4、丢包
从x发送请求图中可以看到最上面两条消息一个是44秒一个是45秒,间隔1s,达到tcp检测超时重传的标准。
tcp的三次握手,seq=0是第一次握手,可以看出两条消息都是第一次握手包,第二条消息显示Retransmission,丢包重传。
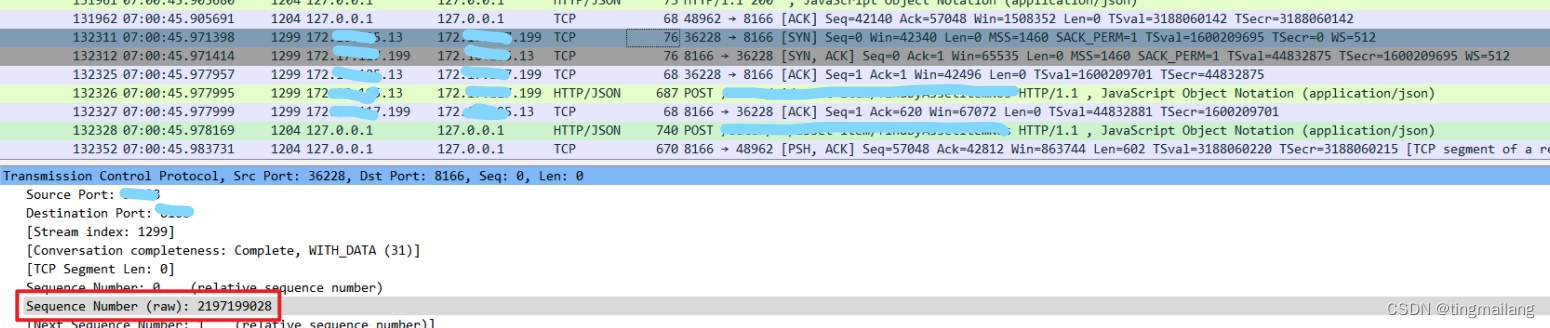
 打开具体的消息内容,这两条sequence number是一样,更加代表是同一个tcp链接发起的握手。
打开具体的消息内容,这两条sequence number是一样,更加代表是同一个tcp链接发起的握手。

接收方很明显是45秒才接收到第一条tcp握手包,包的sequence number与x发的一致。
三、总结
最终查出来是tcp丢包重试,那么接下来就是网络链路层的问题,研发就不参与了,交给it网络部就可以。