B2SFinder: Detecting Open-Source Software Reuse in COTS Software [ASE 2019]
Muyue Feng, Zimu Yuan, Feng Li, Gu Ban, Yang Xiao, Shiyang Wang, Qian Tang, He Su, Chendong Yu, Jiahuan Xu, Aihua Piao
Institute of Information Engineering, Chinese Academy of Sciences
COTS软件产品被广泛地开发在OSS项目之上,导致了OSS重用漏洞。为了检测这些漏洞,在COTS软件中发现OSS重用已经变得势在必行。虽然可扩展到成千上万的OSS项目,但现有的二进制到源代码匹配方法在分析COTS软件产品时严重不精确,因为它们只支持有限数量的代码特性,在测量OSS重用时仅近似地计算匹配分数,并且忽略了OSS项目中的代码结构。
为了解决这些限制,我们引入了一种新的二进制到源匹配方法,称为B2SFINDER。首先,B2SFINDER可以推断出七种代码特征,它们在二进制代码和源代码中都是可追踪的。为了精确计算匹配分数,B2SFINDER采用了加权特征匹配算法,该算法将三种匹配方法(用于处理不同的代码特征)和两种重要性加权方法(用于根据特定COTS软件应用中某个代码特征的特异性和出现频率计算其实例的权重)相结合。最后,B2SFINDER根据匹配分数和OSS项目的代码结构识别不同类型的代码重用。我们使用优化的数据结构实现了B2SFINDER。我们使用来自1000个流行的COTS软件产品和2189个候选OSS项目的21991个二进制文件对B2SFINDER进行了评估。实验结果表明,B2SFINDER不仅精度高,而且具有可扩展性。与现有技术相比,B2SFINDER平均在53.85秒内发现每个二进制文件最多2.15倍的重用案例。我们还讨论了在实践中如何利用B2SFINDER来检测OSS重用漏洞。
一句话:B2SFINDER 采用加权特征匹配算法对二进制到源进行匹配。
导论
Background
当将一些易受攻击的OSS代码集成到COTS软件中并在软件中重用时,可能会将OSS漏洞引入到COTS软件中。这种被称为OSS重用漏洞的OSS漏洞无处不在,并且会对COTS软件的安全性产生严重影响。例如,Adobe Reader[6]和Windows Defender[7]都被发现存在漏洞,因为它们都使用了一些易受攻击的开源项目Libxslt和UnRAR。事实上,大多数OSS重用漏洞仍然存在于COTS软件中,即使它们的漏洞版本已经被修补。根据一份Synopsis报告[8],96%被审计的COTS产品重用了OSS项目作为它们的组件,这些组件平均包含六年前发布的OSS项目中未修补的OSS漏洞。
为了检测OSS重用漏洞,必须尽可能精确地识别包含在COTS软件中的OSS项目。因此,在本文中,我们有动机解决COTS软件问题的底层OSS重用检测。在移动应用数量不断增加的同时,传统的运行在台式计算机和服务器上的COTS产品仍然被广泛使用。因此,本文的研究重点是COTS软件。COTS产品通常由数十个剥离的二进制文件组成,其中大多数是可移植可执行(PE)格式(用于Windows)或可执行和可链接格式(ELF)(用于Linux)。
给定目标COTS软件产品的二进制文件和一组候选OSS项目,有两种具有代表性的OSS重用检测方法。一种方法是计算给定目标COTS产品的二进制代码与候选OSS项目的编译二进制代码之间的相似性。我们看到了两个挑战。首先,所有候选OSS项目的全自动编译是非常重要的,通常需要手工工作来找到合适的编译器标志,以使其成功编译。在一项实验中,我们从Ubuntu软件包中抓取了2189个OSS项目[12],我们发现只有大约四分之一的项目可以自动编译。
Problems
(1) 如何选择尽可能多的代码特性,同时确保所有选择的特性在编译的二进制文件中都是可跟踪的?
二进制到源匹配的关键在于所考虑的代码特性。例如,BAT[1]只考虑字符串字面量,因此错过了与字符串字面量无关的39.7%的代码重用(稍后计算)。OSSPolice[2]不仅考虑字符串字面值,还考虑导出的函数名,它在elf格式的库中表现良好。然而,COTS软件的PE文件通常会剥离掉这些线索,这使得OSSPolice无法执行剥离后的二进制文件中所需的代码匹配。
(2) 如何精确地计算不同代码特征及其特征实例的匹配分数?
先前的工作[1,2,10,11,14]通常通过计算匹配分数来衡量特征匹配的程度。然而,由于两个原因,它们的分数计算不精确:(1)通常使用相同的过程匹配不同类型的特征;(2)假设同一特征的不同特征实例在特征匹配中的贡献相同。
(3) 如何利用OSS项目的代码结构来改进重用识别?
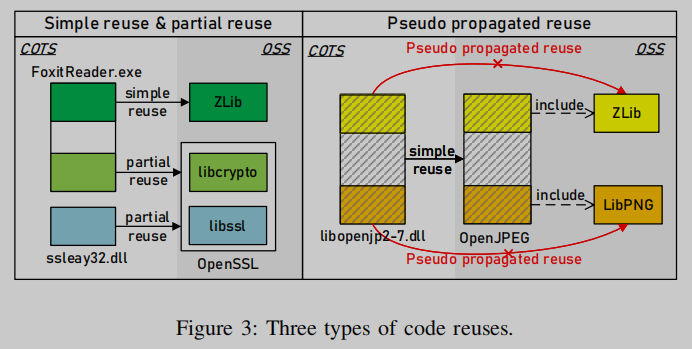
一般来说,更高的匹配分数并不总是意味着更高的代码重用可能性,反之亦然。例如,如图3右侧所示,LibPNG中的每个特性都与libopenjp2-7.dll的特性相匹配,因此匹配得分很高。然而,libopenjp2-7.dll只重用OpenJPEG而不是LibPNG。这表明,为了减少报告的错误重用标识的数量,增加发现的真实重用标识的数量,还应该考虑OSS项目的复杂代码结构。
Contributions
为了解决上述三个问题,我们提出了一种新的二进制到源匹配方法,B2SFINDER,用于检测OSS重用。如图1所示,B2SFINDER分为“匹配分数计算”和“重用类型识别”两个阶段。
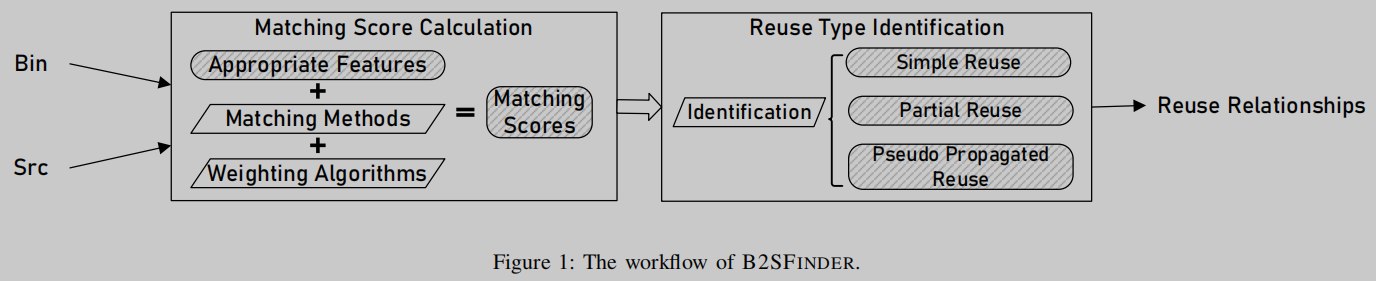
为了精确计算第一阶段的匹配分数,我们积极选择了7种稳定的代码特征,其中4种不受编译影响,3种在编译过程中受影响较小。通过将7种特征划分为字符串型、整型和控制流型3种类型,设计了相应的3种匹配方法:精确匹配、基于搜索的匹配和基于语义的匹配。为了描述不同匹配特征实例的相对重要性,我们引入了特异性和出现频率两个特征实例属性。特异性属性表明,一个特殊的匹配特征实例,例如0x6a09e667,比一个平凡的项目,例如0x0001,更有助于区分一个OSS项目。出现频率属性表示在所有候选OSS项目中匹配的特性实例的出现。出现频率越低,在识别重用的OSS项目中就越重要。通过结合比特流熵算法和类似tf - idf的加权算法,可以在权重计算中捕获这两个属性对代码重用的影响。总体而言,我们提出了一种新的特征匹配算法,该算法将三种匹配方法与两种重要性加权方法相结合。
为了识别不同类型的代码重用,我们考虑了OSS项目的代码结构,以识别两种类型的文件组,自实现组和从第三方项目导入的OSS组。通过利用这些信息,我们在目标COTS软件二进制文件和OSS项目之间构建了精确的重用关系。我们已经确定了三种类型的重用关系:简单重用、部分重用和伪传播重用。前两个是真正的重用案例,而最后一个是错误的重用案例,应该被消除。需要注意的是,BAT[1]和OSSPolice[2]由于匹配分数低,通常会忽略部分重用,而BAT[1]由于匹配分数高,通常会错误地识别伪传播重用。
总体而言,本文做出了以下贡献
(1) 我们提出了一种新的二进制到源匹配方法,通过采用加权特征匹配算法,该算法结合了三种匹配方法(用于处理不同的代码特征)和两种重要性加权方法(用于根据其特异性和出现频率计算给定软件应用程序中代码特征实例的权重)。
(2) 本文引入了重用类型的新概念,并利用该概念提高了代码重用检测的精度。
(3) 我们已经为B2SFINDER开发了一个原型开源实现,并使用来自1000个流行的COTS软件产品和2189个OSS项目的21991个二进制文件评估了它的效率和精度。与现有技术相比,B2SFINDER平均在53.85秒内发现每个二进制文件最多2.15倍的重用案例。B2SFINDER在实践中也被证明具有检测OSS重用漏洞的能力。
方法
Motivation
我们将介绍二进制到源代码的匹配方法,并通过使用两个现实世界的示例(Foxit Reader和GIMP)来说明我们对检测OSS重用的见解。Foxit Reader是一个著名的PDF文件查看和编辑工具。这两个二进制文件,即核心可执行文件FoxitReader.exe和动态链接库ssleay32.dll,都是从FoxitReader中选择的,它们都重用了OpenSSL,一个广泛使用的实现SSL的OSS项目。GIMP是一个流行的栅格图形编辑器,用于图像编辑。它的动态库libopenjp2-7.dll重用了一个OSS项目OpenJPEG。虽然这两个示例都是PE格式,但我们的方法能够以类似的方式处理所有其他本机二进制文件。
A. Matching Score Calculation
由于我们直接比较COTS软件应用程序的二进制代码与OSS项目的源代码,因此从两者中选择的代码特性必须是匹配的。字符串字面值和导出的函数名可以直接匹配,因为它们通常与编译器标志无关。然而,这些特性并不适用于COTS软件中的许多二进制文件。在我们的方法中,一个关键的观察是确定在编译过程中不太可能改变的代码特性范围。
如图2所示,FoxitReader.exe和OpenSSL之间没有通用的导出函数名。此外,两者共享的通用字符串字面值只有19.7%。鉴于这两个事实,BAT[1]和OSSPolice[2]在分析FoxitReader.exe时是无效的。为了利用二进制和源代码中存在的更稳定的代码特性,我们检查了FoxitReader.exe。除了.rdata段中的字符串文字和DOS头段中导出的函数名外,我们还发现了.rdata、.data和.text段中可选择的其他特性。
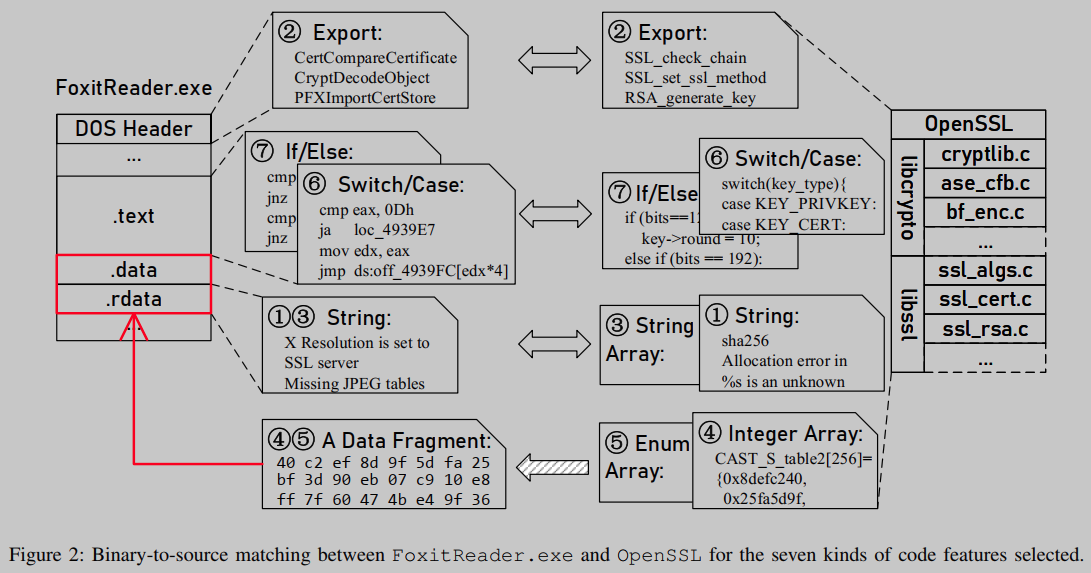
这些新选择的特征之一是数值数据。这些数据项通常是存储在.data段(用于非常量变量)和.rdata段(用于常量变量)中的全局变量的初始值。全局数值数组和全局枚举数组,例如,在图2中,OpenSSL中全局整数数组CAST_S_table2[256] = {0x8defc240,0x25fa5d9f,…};在FoxitReader.exe中,前缀为0x40c2ef8d9f5dfa25的比特流。
我们观察到,还可以在.text段中找到一些潜在的代码特性。虽然控制流信息可以通过一些编译器优化来改变,但是表示一些复杂逻辑的分支序列是相对稳定的。这是因为这样的序列通常是复杂的,因此不满足所需的底层优化标准。因此,对于给定的二进制文件,我们使用从其代码段中提取的编码复杂开关/case结构和连续if/else条件分支序列来搜索其数据或指令序列。例如,FoxitReader.exe有一个跳转表[0,9,16,17,20],它被发现包含与OpenSSL函数aes_ccm_ctrl()中的开关语句相同的标签。这表明FoxitReader.exe很有可能重用OpenSSL。
我们总共选择了七种代码特征,如图2所示。然而,如何将源代码中的特性与其编译后的二进制文件中出现的相同特性相匹配仍然具有挑战性,特别是对于那些在编译过程中可能略有变化的特性。
对于给定的代码特征,采用逆向工程的方法提取COTS软件应用程序二进制文件中的特征实例,采用程序分析的方法提取OSS项目源代码中的特征实例。特征实例是属于某一类特征的具体特征对象,如图2所示。对于不同的代码特征,我们将采用三种不同的匹配方法进行识别。对于代码特性的不同实例,我们将通过应用两种不同的重要性加权方法来识别它们的相对重要性。
对于字符串、字符串数组和导出函数,它们的特征实例都是字符串形式的,可以通过字符串匹配算法直接识别。具体来说,由于实际中存在大量的字符串,因此使用倒排索引来加速字符串匹配。
另一方面,两个数字特性的实例,即全局整数数组和全局枚举数组的处理方式不同。由于二进制文件中缺乏数据结构信息,我们将这些在二进制文件中找到的特征实例编码为特定数据类型中特定长度的位流。对于每个候选OSS项目,然后在其源代码中搜索每个比特流,以查找其按大或小端字节顺序排列的实例。
最后,匹配控制流类型的特性实例、switch/case特性中的常量和if/else特性中的常量更为复杂。我们将在语义上比较COTS软件应用程序二进制文件中控制流类型的一个特征实例和OSS项目源代码中控制流类型的另一个特征实例中对应的常量。
B. Reuse Type Identification
当我们在COTS软件应用程序和候选OSS项目之间进行特性匹配时,高匹配分数可能并不总是表明真正的重用,而低匹配分数可能并不总是表明错误的重用。为了提高重用检测的精度,我们通过利用OSS项目的代码结构来区分不同类型的代码重用。
在许多情况下,高匹配分数表示真正的重用。我们将这种重用定义为简单重用,它也可以通过现有的方法发现[1,2]。然而,我们发现了另外两种类型的重用,它们在实际的重用关系和获得的匹配分数之间表现出不一致,如图3所示。例如,libssl(又名ssleay), OpenSSL库之一,仅由7.6%的OpenSSL源文件生成。任何重用libssl的二进制文件,例如Foxit Reader中的ssleay32.dll,都会部分重用OpenSSL,尽管它们的匹配分数相对较低。相比之下,GIMP中的libopenjp2-7.dll与LibPNG中的匹配分数相当高,因为libopenjp2-7.dll中的代码片段与LibPNG中的代码片段相似。但是,这个代码片段实际上是由OpenJPEG的libpng模块编译的,它可能是原始libpng的变体。因此,应该消除libopenjp2-7.dll和LibPNG之间的重用,这被称为伪传播重用(pseudo propagated reuse)。
我们观察到,为了识别部分重用和伪传播重用,有必要考虑OSS项目的复杂代码结构。要做到这一点,我们首先将OSS项目分解为独立的库模块,通过分析其编译过程来构建从源文件到生成库的映射。这是通过比较两个OSS项目中匹配的特性实例集来建立的。如图3右侧所示,由于OpenJPEG中匹配的特征实例集包含LibPNG中匹配的特征实例集,因此添加了一条从OpenJPEG到LibPNG的包含边。这两种类型的代码结构有助于识别此类重用。
Selecting Code Features
在本节中,我们详细介绍用于检测COTS软件中OSS复用的B2SFINDER的设计。
由于源代码和二进制代码表示之间的显著差异,所选择的代码特征有望提供一种统一的方式来实现特征匹配。选择代码特性有两个标准。首先,代码特性必须同时出现在二进制代码和源代码中。其次,在编译过程中不应该对源代码中的代码特性进行大幅更改。表1共列出了10个候选代码特征,涵盖了现有二值相似度分析技术中使用的所有特征。所有10个特征都满足第一个标准,但10个特征中只有7个满足第二个标准。
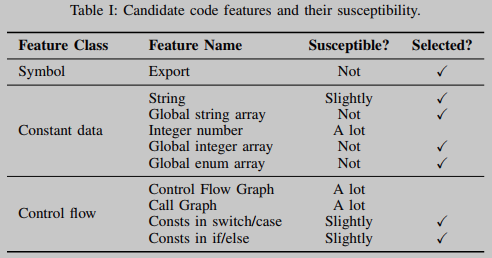
字符串字面值和导出的函数名是传统的代码特性,也适用于COTS软件。然而,一些OSS项目,如UnRAR和bzip2,可能不包含任何用于匹配目的的有用字符串,此外,COTS软件应用程序经常以字符串字面量剥离而结束,以隐藏其软件组成。在许多OSS项目中,当内部调用OSS项目中的代码时,导出的函数名经常被隐藏。因此,需要新的代码特性。
数值和控制流相关的功能可能是无价的。在之前的二进制分析工作[3,9,10,15,17]中,常量被广泛使用,但并不是所有的常量都适合我们的设置。我们发现,源代码中的数字常量在其编译的二进制代码的指令中作为直接值出现,在编译期间受到严重影响。相反,全局整数数组、全局枚举数组和全局字符串数组通常不受影响。此外,这些全局数组通常包含OSS项目中的一些关键信息。
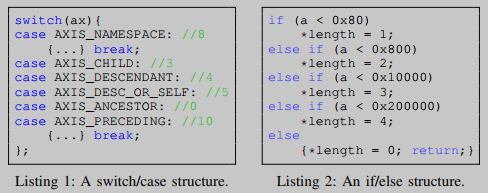
与数字特性相比,控制流相关的特性可以通过在编译过程中应用的编译器优化更容易地更改。在不同的编译器标志下,由同一源函数生成的二进制代码可能具有完全不同的控制流结构。程序的调用图也会受到函数内联的影响。因此,二进制代码和源代码之间的控制流图(CFGs)和调用图(CGs)不能直接比较。幸运的是,复杂的分支序列,比如复杂的 switch/case 和 if/else 语句结构,如清单1和2所示,在编译过程中是相对稳定的。这些结构中的常量也被选为代码特征。
Matching Code Features
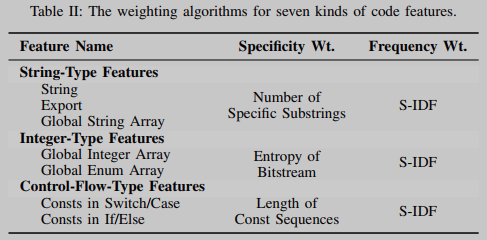
我们将七种代码特征分为字符串、整数和控制流三种不同的类型,如表2第1栏所示。将使用不同的方法来匹配不同类型的代码特征。
字符串类型特征的精确匹配。由于字符串在编译阶段总是保持不变,因此从二进制代码中提取的字符串和从源代码中提取的字符串如果相同,则被认为是等效的。
基于搜索的整型特征匹配。全局整数/枚举数组以可搜索的连续位流的形式存储在二进制文件的数据段中。
基于语义的控制流类型特征匹配。switch/case 结构和 if/else 序列在语义上的比较如下。对于OSS项目源代码中的开关/案例特性,我们将其表示为附加了默认分支的案例标签集的无序列表。
Determining the Importance-Weights of Feature Instances
随着OSS项目规模的增长,从这些OSS项目中提取的特性实例的数量将迅速增加。事实上,特征实例在特征匹配中的作用并不相同。因此,我们可以通过只考虑相对重要的特征实例来减少花在特征匹配上的时间。为了区分特征实例对特征匹配的贡献,每个特征实例被分配一个特异性权重和一个频率权重。这两个权重分别基于所携带的信息及其在OSS项目中的出现频率来度量特征实例的贡献。以CAST5密码中的S表({0x8defc240,0x25fa5d9f,…})为例。它是唯一的,不太可能与其他数据相似。因此,该S表将具有较大的特异性权重。然而,CAST5是一种流行的密码,至少有15个OSS项目包含这个S表。由于这种频繁的出现对重用检测没有太大帮助,因此将为这个S表分配一个相对较小的频率权重。
如表2(第2列和第3列)所示,所有代码特征都依赖于相同的算法S-IDF (TF-IDF的一种变体)来计算它们的频率权重。针对三种不同类型的特征,采用三种不同的方法计算特征的特异性权重。对于字符串类型的特性,我们使用其子字符串的数量,包括url和版权信息(以及其他)。对于整型特征,使用其比特流的熵。对于控制流类型的特征,使用其常量序列的长度。
1)计算比特流的特异性权重作为熵:尽管许多全局数组(例如CAST5密码的S表)是特异性的,但仍有许多其他数组包含很少有用的信息。例如,[0x0001,0x0010,0x0100,0x1000]作为一个标志位列表,与许多不相关的数据具有相同的位流,可能导致一些不正确的匹配。为此,我们提出了一种用于计算整型特征的特异性权重的比特流熵算法。

在特征匹配过程中,一个整数数组会被转换成一个比特流,如表III所示。具体来说,一个比特流被划分成一个比特片段列表,其中每个片段代表相同比特值(0或1)的最大序列。
计算频率权重的S-IDF:特征实例的出现频率是决定其在整个特征匹配过程中的贡献的另一个因素。例如,UnRAR项目中的常量表只存在于一个OSS项目中,而CAST5密码中的常量表至少存在于15个OSS项目中。如果前一个表是匹配的,我们可以很容易地确定UnRAR项目已经被重用。但是,如果找到后一张表,就不那么容易作出决定性的决定了。
Computing Matching Scores
匹配分数是根据匹配的加权特征实例计算的,随着匹配特征实例数量的增加而增加。因此,我们从上面用一个阈值来限定它,这个阈值是根据经验为每个特征确定的。如果任何特征的匹配分数大于其阈值,则认为目标二进制文件与相应的源代码具有重用关系。算法1展示了如何计算匹配分数。给定一个二进制文件b和一组候选OSS项目S,我们的方法根据七种代码特征F确定一组OSS重用R。

Identifying Reuse Types
对于给定的特征实例,重用关系的存在并不总是与其匹配分数正相关,如表4所示。在这三个例子中,简单的重用在代码相似度方面表现一致。相反,部分重用代表了真实的重用,但匹配分数较低;伪传播重用代表了虚假的重用,但匹配分数较高。

识别部分重用:部分重用是常见的,因为COTS软件应用程序通常只共享OSS项目的一部分。为了降低部分重用由于匹配分数低而导致的误报率,我们通过构建编译依赖层图(CDLG)来识别独立库,并将单个库而不是整个OSS项目作为代码匹配单元。
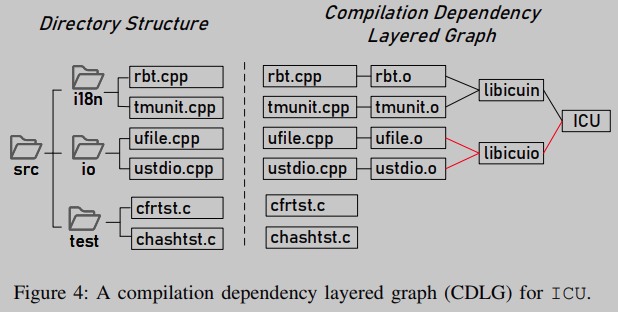
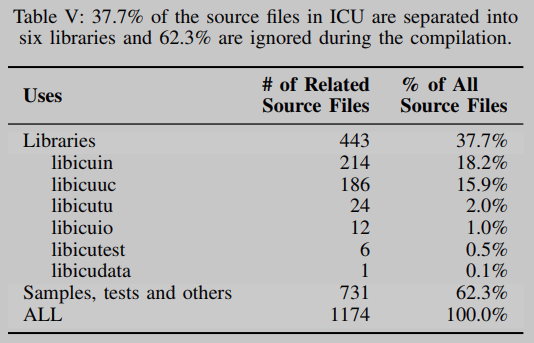
以支持unicode的项目ICU为例,其CDLG如图4所示。属于不同库的源文件在不同的组中分开。此外,不再分析与任何库无关的62.3%的源文件,如表5所示。
识别伪传播重用:这些是由候选OSS项目之间不相关重用关系的传播引起的虚假重用。例如,GIMP中的libopenjp2-7.dll重用OpenJPEG,其中包含LibPNG作为第三方库。libopenjp2-7.dll和LibPNG之间的匹配分数很高,但它们之间的关系是伪传播重用。

实验
IMPLEMENTATION
我们实现了一个文件级匹配框架,B2SFINDER,用于COTS软件中的OSS重用检测。
图5描述了B2SFINDER的体系结构。有三个模块,提取器,匹配器和检测器。Extractor从二进制代码和源代码中提取代码特征,然后使用有效的存储模型存储它们以提高效率。还解析了编译器和链接器命令行,以增强提取器的健壮性。Matcher通过应用我们的匹配方法和计算匹配分数来负责二进制代码和源代码之间的代码特征匹配。检测器根据匹配的特征实例集和OSS项目的CDLG识别重用,并为目标COTS软件生成重用关系列表。
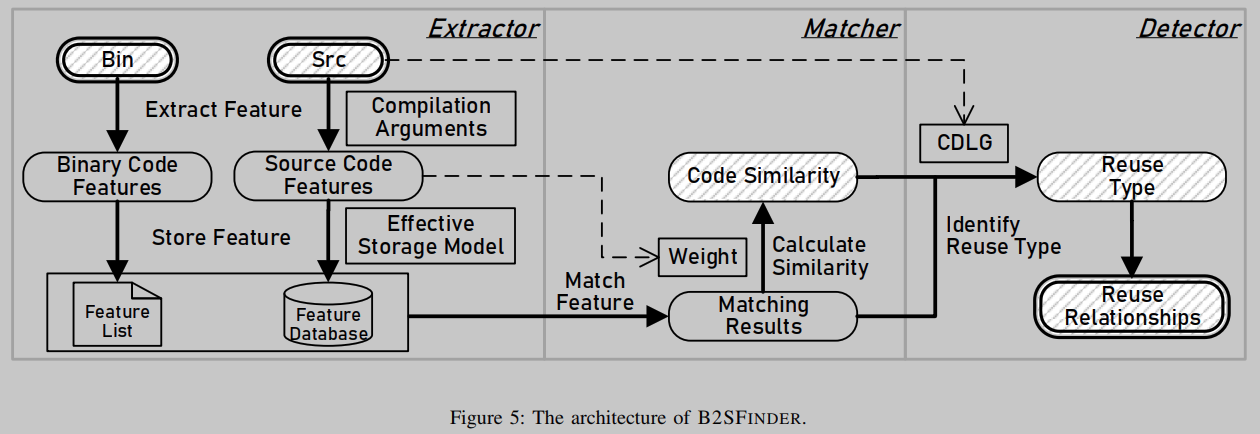
我们通过在LLVM和Clang上开发一些静态分析工具,从源代码中提取代码特性。然而,静态分析必须小心。在许多OSS项目中,头文件存储在一些独立的目录中,而不是存储在OSS项目所在的目录中,导致一些头文件丢失。同时,用于条件编译的特定版本的宏可能取决于所使用的环境和特定编译器,从而导致遗漏或错误地使用某些宏。
为了避免这些问题,我们分三步进行。首先,我们在OSS项目中搜索像CMAKELISTS.txt和autogen.sh这样的文件,以自动检测所使用的MAKEFILEs。其次,我们解析这些MAKEFILEs以获得所使用的gcc或libtool命令,而无需完全编译OSS项目。最后,我们从提供给编译器标志-I和-D的参数中定位包含路径和使用的宏。
特征匹配的时间复杂度与代码特征的存储模式密切相关。在一个简单的实现中,分析单个COTS产品可能需要花费一天的时间。为了缩短这个过程,我们使用了两个数据结构,一个倒排索引和一个Trie。
反向索引。为了加快字符串搜索速度,我们在键值数据库Cassandra中为字符串特征建立了一个倒排索引。由于Cassandra依赖于哈希树,检索字符串的平均时间复杂度已经从O(M)有效地减少到O(1),其中M是OSS项目中字符串字面量的数量。
单词查找树。我们为两个整型特征(全局整型数组和全局枚举数组)构建一个Trie。Trie是一种基于目标数据前缀的有序数据结构。在二进制文件中搜索数组时,如果前缀数组不存在,则遍历Trie并修剪它的子树。
Datasets
我们从精确度和效率两方面对B2SFINDER进行了评价。然后,我们给出了在大量真实的COTS软件产品中检测OSS重用漏洞的发现。我们使用下面描述的两个二进制代码数据集和一个源代码数据集。
数据集1:具有已知重用的二进制文件(B1)。该数据集包含从23个常用开源项目中编译的46个官方(剥离)二进制文件,涵盖不同的应用领域,包括视频解析(例如,VLC), PDF渲染(例如,SumatraPDF)和网络协议(例如,OpenSSL)。
数据集2:真实世界的COTS软件(B2)。该数据集包含从Web站点集合获得的1000个COTS软件产品中的21991个二进制文件。我们在https://github上给出了这些产品的散列列表。com/1dayto0day/B2SFinder/COTS list.txt。
数据集3:公共开源库(S)。该数据集包含2189个从Ubuntu软件包(Ubuntu的官方软件包存档)中抓取的开源库。
Precision
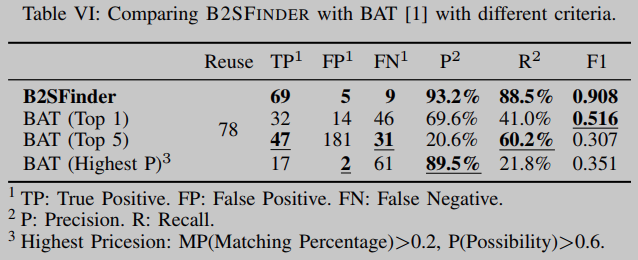
为了测量B2SFINDER的精度,使用了一个由46个官方二进制文件(数据集B1)和2189个OSS项目(数据集S)组成的基准套件。我们在基准测试套件中手动标记了总共78个真正的重用,包括简单重用、部分重用和伪传播重用。基于标记的重用,我们将B2SFINDER与BAT进行比较,BAT是唯一可以同时处理两者的二进制到源匹配工具PE和elf格式的可执行文件和动态库。我们将实验结果总结在表六中。
Efficiency
我们应用B2SFINDER在OpenStack云中的四个虚拟机上分析了来自1000个真实世界COTS软件产品(数据集B2)和2189个公共开源库(数据集S)的21991个二进制文件。每个虚拟机配备两个Intel至强E5-2603 V4的共享内核,4GB内存和128GB磁盘。
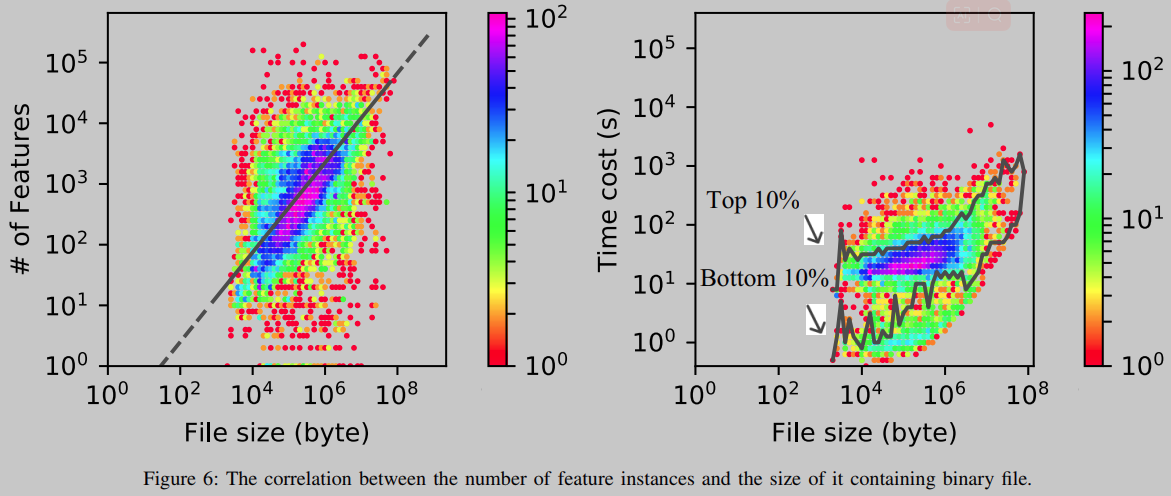
如图6所示,特性实例的数量与包含它的二进制文件的大小大致呈线性关系。分析所有二进制文件的91.4%需要不到100秒的时间,这对于离线部署来说已经足够快了。
Large-Scale Analysis
我们现在描述在大规模真实的COTS软件产品中检测OSS重用漏洞的发现。
OSS重用: 我们发现数据集B2中的21991个二进制文件和数据集s中的2189个OSS项目之间存在10208对重用关系。如表VII所示,19.2%的二进制文件(包含在所有COTS软件产品的63.4%中)被发现至少重用了一个开源库。这表明OSS重用在COTS软件中无处不在。

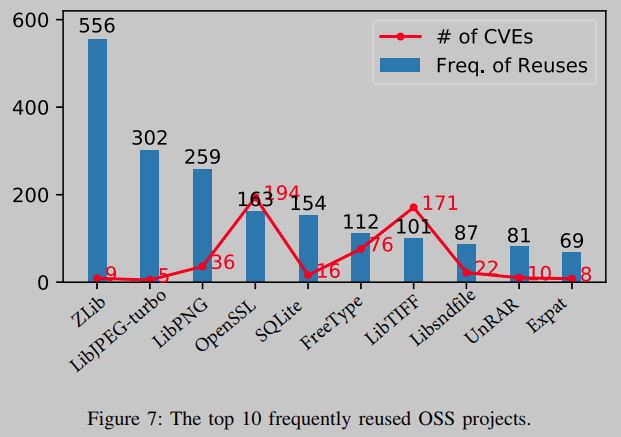
在研究的2189个OSS项目中,4.6%的项目被重复使用了10次以上。然而,这些OSS项目被重用的频率因项目而异。如图7所示
总结
RELATED WORK
Binary-to-Source Matching
在二进制到源匹配方面的研究相对较少,包括BAT[1]、OSSPolice[2]和FIBER[13]。BAT[1]将字符串字面值作为唯一的代码特性,并生成潜在的OSS重用排序列表。OSSPolice[2]不仅考虑字符串字面值,还将导出的函数名作为代码特征,并引入了分层索引方案来索引特征。FIBER[13]在假设目标函数已知的情况下,在函数的控制流上生成语义签名,以识别补丁引入的语法和语义变化。
References
[1] A. Hemel, K. T. Kalleberg, R. Vermaas, and E. Dolstra, “Finding software license violations through binary code clone detection,” in Proceedings of the 8th Working Conference on Mining Software Repositories. ACM, 2011, pp. 63–72.
[2] R. Duan, A. Bijlani, M. Xu, T. Kim, and W. Lee, “Identifying opensource license violation and 1-day security risk at large scale,” in Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security. ACM, 2017, pp. 2169–2185.
[3] Z. Li, D. Zou, S. Xu, H. Jin, H. Qi, and J. Hu, “Vulpecker: an automated vulnerability detection system based on code similarity analysis,” in Proceedings of the 32nd Annual Conference on Computer Security Applications. ACM, 2016, pp. 201–213.
[6] Transforming Open Source to Open Access in Closed Applications: Finding Vulnerabilities in Adobe Reader’s XSLT Engine, Zero Day Initiative (ZDI) Std., May 2017. [Online]. Available: https://static1.squarespace.com/static/5894c269e4fcb5e65a1ed623/t/592493f140261d8c41ae30c1/1495569406556/ZDI-Adobe_XSLT_Report.pdf
[7] mpengine contains unrar code forked from unrar prior to 5.0, introduces new bug while fixing others. [Online]. Available: https://bugs.chromium.org/p/project-zero/issues/detail?id=1543&desc=2#maincol
[8] Synopsys 2018 open source security and risk analysis report. [Online]. Available: https://www.synopsys.com/content/dam/synopsys/sig-assets/reports/2018-ossra.pdf
[9] S. Eschweiler, K. Yakdan, and E. Gerhards-Padilla, “discovre: Efficient cross-architecture identification of bugs in binary code.” in NDSS, 2016.
[10] X. Xu, C. Liu, Q. Feng, H. Yin, L. Song, and D. Song, “Neural networkbased graph embedding for cross-platform binary code similarity detection,” in Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security. ACM, 2017, pp. 363–376.
[11] B. Liu, W. Huo, C. Zhang, W. Li, F. Li, A. Piao, and W. Zou, “αdiff: cross-version binary code similarity detection with dnn,” in Proceedings of the 33rd ACM/IEEE International Conference on Automated Software Engineering. ACM, 2018, pp. 667–678.
[12] Ubuntu packages. [Online]. Available: https://packages.ubuntu.com/
[13] H. Zhang and Z. Qian, “Precise and accurate patch presence test for binaries,” in 27th {USENIX} Security Symposium ({USENIX} Security 18), 2018, pp. 887–902.
[14] Y. Xue, Z. Xu, M. Chandramohan, and Y. Liu, “Accurate and scalable cross-architecture cross-os binary code search with emulation,” IEEE Transactions on Software Engineering, 2018.
[15] Q. Feng, R. Zhou, C. Xu, Y. Cheng, B. Testa, and H. Yin, “Scalable graph-based bug search for firmware images,” in Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security. ACM, 2016, pp. 480–491.
[17] W. M. Khoo, A. Mycroft, and R. Anderson, “Rendezvous: A search engine for binary code,” in Proceedings of the 10th Working Conference on Mining Software Repositories. IEEE Press, 2013, pp. 329–338.
Insights
(1) 跳转分支序列可以作为.text段的特征之一