DrQA模型主要分为两部分,第一部分Retriever和第二部分Reader,Retriever根据问题检索出维基百科语料库中最相关的5篇候选文章,Reader则从候选的5篇文章中提取出问题的答案。系统的示意图如下:
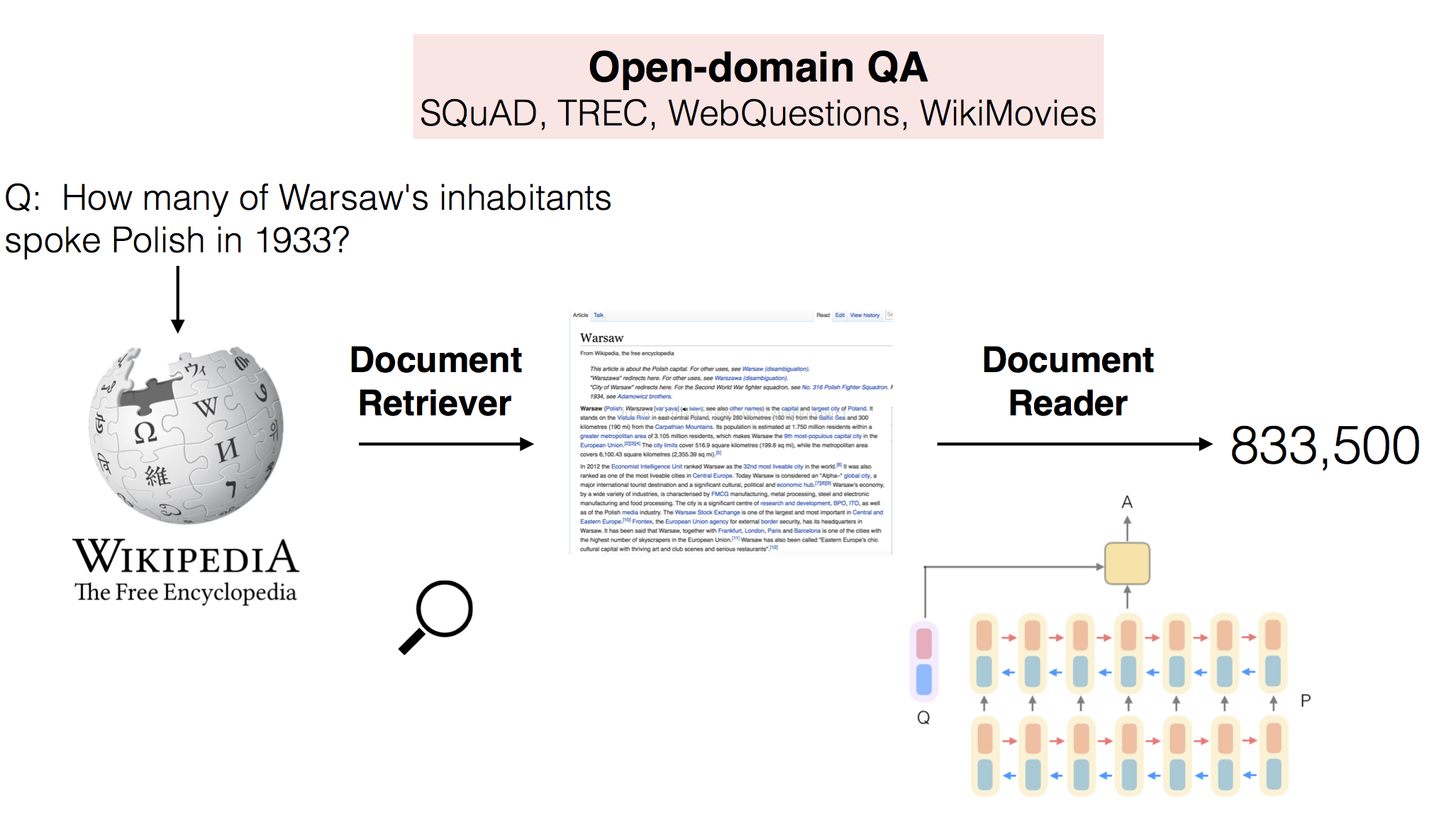
Retriever 直接利用简单的TF-IDF加权的词袋模型来检索出最合适的5篇文章,又使用考虑了局部词序的n元特征对系统进行了改进。
Reader分为paragraph encoding,question encoding和prediction部分。paragraph encoding使用一个双向LSTM网络将各段落中的每一个token转化为一个向量,question encoding再使用另一个双向LSTM网络将每个问题转化为一个向量,得到各段落中各token和问题的向量表示即可以将它们作为分类器的输入来判断答案区间的起止位置,具体地,使用双线性项来捕获token pi和问题q之间的相似性,并计算每个token作为的开始或结束项的概率,如下所示:

下面结束DrQA的安装过程:
DrQA的安装要求linux/OSX系统以及Python 3.5以上的版本,首先需要安装pytorch,可以按照http://pytorch.org/给出的命令直接安装,再使用如下命令来安装DrQA:
git clone https://github.com/facebookresearch/DrQA.git cd DrQA; pip install -r requirements.txt; python setup.py developDrQA默认的tokenizer为CoreNlp,首先使用如下命令下载
./install_corenlp.sh再将下载的jar文件引入classpath环境变量或在调用的程序代码,比如pipeline中的interactive中加入如下代码:
import drqa.tokenizers drqa.tokenizers.set_default('corenlp_classpath', '/your/corenlp/classpath/*')至此DrQA安装完毕。
最后运行python scripts/pipeline/interactive.py来尝试DrQA的demo,截屏如下:
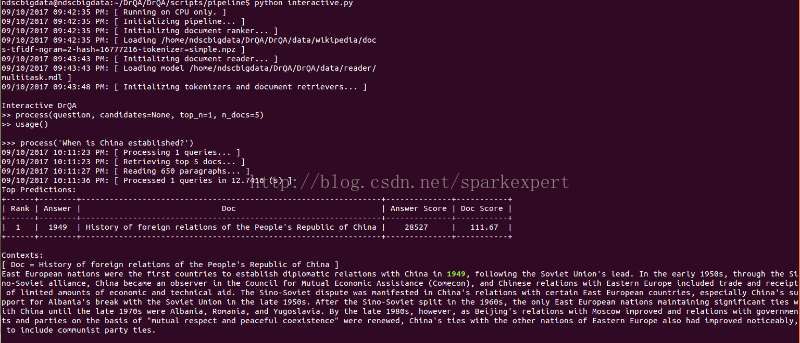
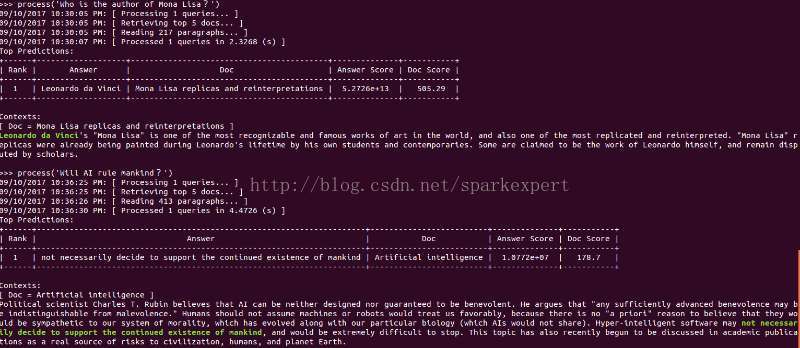

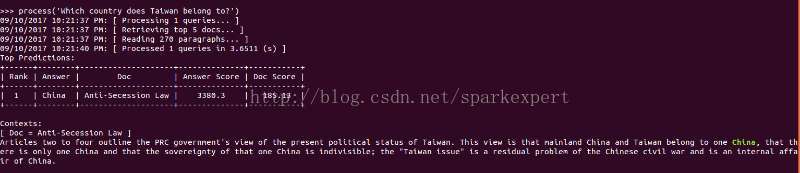
可见DrQA系统对于事实型问题的回答还是具有比较高的质量的。问题是对于所提问的问题,如果其答案需要推理才能得出,DrQA便无法正确回答了,因此个人认为DrQA如果与具备推理能力的知识图谱结合,会具有更高的性能。