1. Oracle数据库的安装
1.安装步骤详见《oracle11g安装图解.doc》
2.安装过程中,遇到所有警告,都忽略.进入下一步
3.windows10的同学,会提示.net的库没有.直接忽略.
4.安装总结
4.1.选择安装目录最好是非系统盘
4.2.安装是可以直接创建数据库,也可以选择创建数据库
4.3.服务器的主机名不能有特殊字符
4.4.数据库安装完毕,建议不要更改主机名
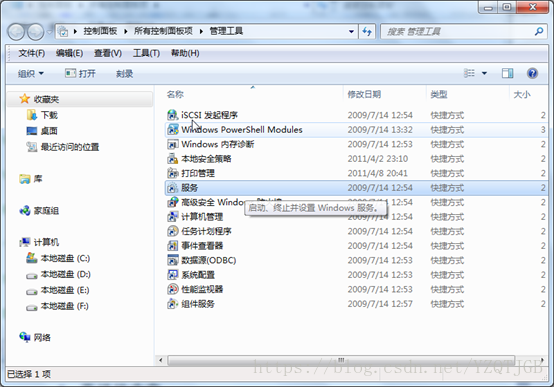
1.1. Oracle数据库服务的介绍
1.1.1. 打开系统服务
1.方式1:控制面板-->管理工具-->服务
2.方式2:使用命令打开

在运行下-->services.msc
1.2. Oracle服务
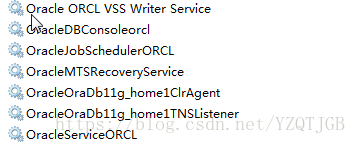
1.OracleVssWriterORCL:卷映射拷贝服务,作用,在分布式安装Oracle,统一管理(如:磁盘阵列)映射的服务.(DBA)
2.OracleDBConsoleorcl:Oracle企业控制台服务:用于监控Oracle数据库的CPU,连接数,会话数,内存使用情况.(DBA)
3.OracleJobSchedulerORCL:Oracle调度服务,作用指定一个时间点,执行操作数据库.(DBA)
4.OracleMTSRecoveryService:Oracle微软事务服务,作用,的windows下分布式安装,用于,统一管理管理同步,提交,回滚事务.(DBA)
5.OracleOraDb11g_home1ClrAgent:Oracle对.net平台(C#)的支持.
--------只要启动下面这两服务,其他服务可以关闭
6.OracleOraDb11g_home1TNSListener:第三方连接监听服务.如果不打开这个服务,除了内置的命令行客户端sqlplus(),其他的连接都连接不上.(必须启动)
7.OracleServiceORCL:数据库主服务.作用,关闭就等同关闭数据库.(必须启动)
每一个数据库对应一个服务
详见《Oracle用到的服务.pdf》
2. Oracle简介
Oracle数据库管理系统
Oracle数据库是当今最主流数据库之一
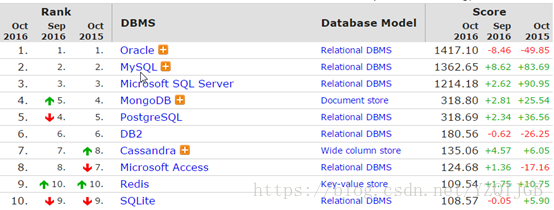
2.1. 应用场景
Oracle是一个最贵的数据库.安全性,稳定性,也是最优秀的.
国内主要使用者:政府,国企,银行,大型企业.
3. Oracle数据库连接
Oracle主要分为两种.
命令行客户端连接\图形客户端连接
3.1. Oracle命令行客户端(sqlplus)
方式1:在菜单打开
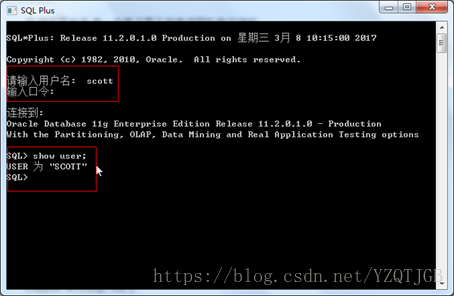
这个打开方式有缺陷,就是不能复制里面数据.怎么办?
使用cmd打开.
方式2:使用cmd命令行打开
输入: sqlplus 根据提示输入用户名密码
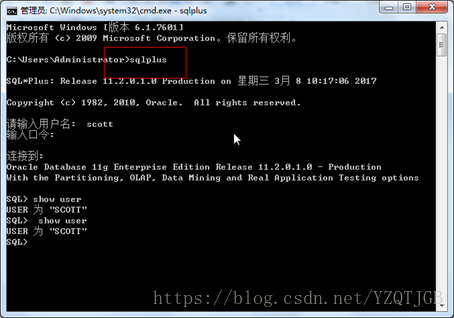
或者:直接使用 sqlplus 用户名/密码
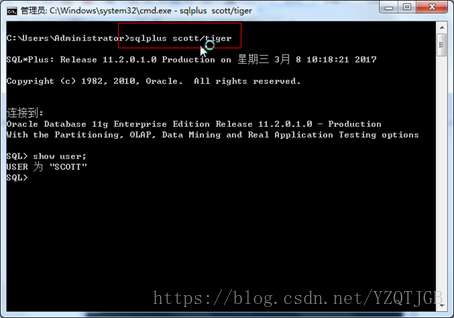
退出当前登录的用户:
quit/exit/ctrl+c强制退出
3.1.1. sqlplus的连接类型
1.普通用户名登录, sqlplus 用户名/密码
2.超级管理员登录
Oracle只有一个超级管理员sys.所以只有sys需要这样登录.
使用: sqlplus 用户名/密码 as sysdba
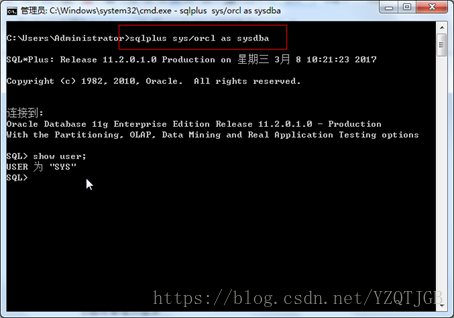
或者,先写sqlplus,在提示的用户名键入: sys as sysdba
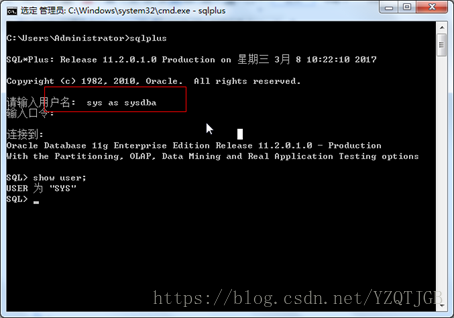
3.无用户登录,进入到SQL命令行下,再连接用户
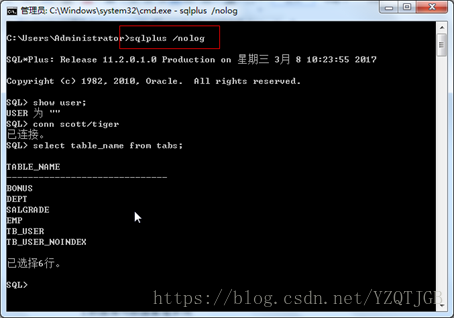
3.2. sql developer
SQL developer是Oracle官方开发的工具,从4.0以后就非常好用.
但4.0的SQL developer必须需要jdk1.8支持
没有jre的版本
1.第一步,选中jdk1.8的根目录
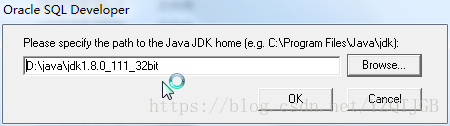
2.第二步,直接”否”
第三步,配置连接信息
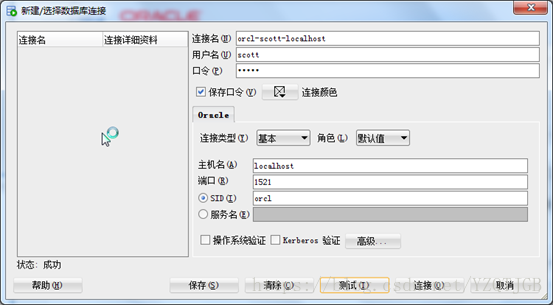
连接名:随便写.建议(数据库名-用户名-IP)
用户名:
口令:密码
主机名:IP
端口:默认1521
sid:数据库名
如果看到数据表,连接成功
3.3. plsql sqldeveloper

用户名:键入用户名
口令:键入密码
数据库:使用的是数据库的对应的网络连接名,这个名字可以去Net Manager查看
plsql sqldeveloper登录界面是没有IP的,如果远程连接.如何连接
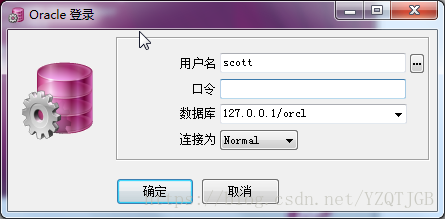
注意事项:(坑)
本地连接使用的是网络名,而远程连接的数据库名为:IP/数据库名,而不是网络名
格式:
数据库名:IP/数据库名
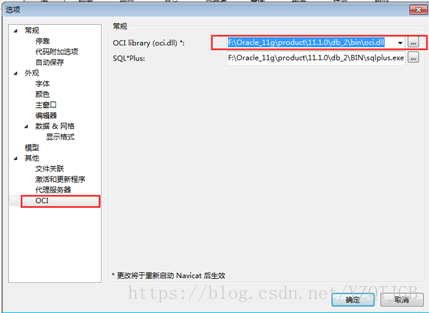
3.4. 使用navicat for oracle连接oracle
1. 下载navicat fororacle并进行安装
2. 进行连接
3. 出现错误进行如下设置
工具》》选项》》OCI
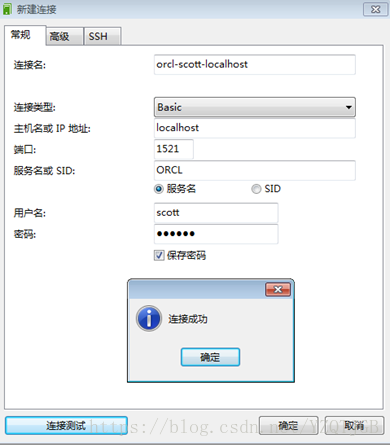
测试连接成功,如下图:
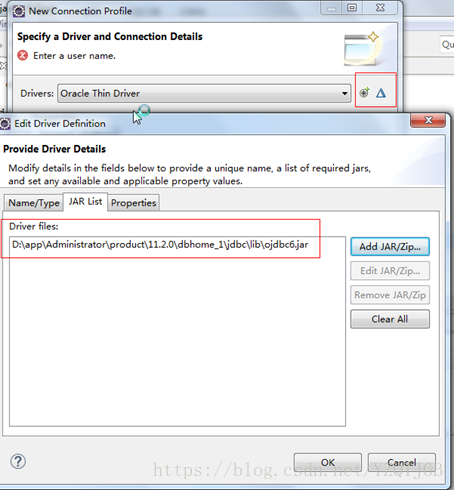
3.5. 使用jdbc连接数据库
开发步骤
1.导入包
包放在的位置
$ORACLE_HOME\dbhome_1\jdbc\lib
如:D:\app\Administrator\product\11.2.0\dbhome_1\jdbc\lib\ojdbc6.jar
2.生成连接的url
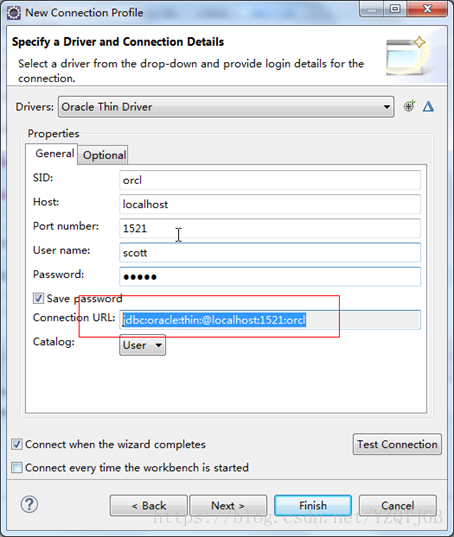
3.编写测试代码
package com.ys.test;
import java.sql.Connection; import java.sql.DriverManager; import java.sql.PreparedStatement; import java.sql.ResultSet;
/** * jdbc连接oracle * @author Administrator * */ publicclass OracleJdbcTest {
publicstaticvoid main(String[] args) throws Exception { //加载驱动 Class.forName("oracle.jdbc.driver.OracleDriver"); //获取数据库连接 String url = "jdbc:oracle:thin:@localhost:1521:orcl"; String username ="scott"; String password = "123456"; Connection connection = DriverManager.getConnection(url, username, password);
//sql语句 String sql = "select * from dept"; //获取预编译对象 PreparedStatement ps = connection.prepareStatement(sql); //获取结果集 ResultSet rs = ps.executeQuery(); //解析结果集 while(rs!=null && rs.next()){ String dname = rs.getString("dname"); System.out.println("dname: "+dname); } //关闭资源 rs.close(); ps.close(); connection.close();
} } |
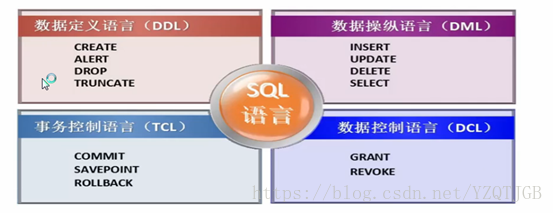
4. Sql分类
5. 数据操作语言(DML)
数据操作语言就是操作的是数据表的记录.
对表数据的操作只有增删改查(dql)
5.1. 增加-Insert
--指定字段 insert into emp(EMPNO,ENAME,job,MGR,SAL,COMM,DEPTNO,HIREDATE) values(1238,'小明','搬砖',7788,200,222,10,to_date('2017-12-12','yyyy-mm-dd')); --插入所有的字段,不用指定字段 --注意事项,就是值顺序必须与表一样. |
5.2. 删除-Delete
--需求:指定员工编号,删除该编号的员工. delete from emp where EMPNO=1234; --需求,删除所有的数据 --删除所有的数据,截断表(truncate).截断表比delete的效率高 truncate table emp; |
Truncate和delete的区别;
效率:truncate效率高
truncate 数据库定义语言
delete 数据库操作语言
5.3. 更新-Update
--需求:指定一个员工编号,更新他的工资为2000 update emp set SAL = 2000 where EMPNO =7788; |
5.4. 查询-Select
select * from emp;
5.4.1. 别名
数据库在查询的时候,可以给表或字段定义一个别名
5.4.1.1. 别名的作用
1.可以缩短表的长度
--给表定义一个别名 select e.empno,e.ename from emp e; --给字段定义一个别名 select e.empno as 员工编号 ,e.ename as 员工姓名 from emp e; select e.empno 员工编号 ,e.ename 员工姓名 from emp e; |
5.4.1.2. 注意事项:
给字段加别名可以使用as 也可以不使用
给表加别名,不能使用as关键字
一般习惯:如果是字段,那么使用as关键字
--在oracle中给字段加别名,可以使用as也可以不使用 |
5.4.2. 连接表查询
5.4.2.1. 什么是连接表查询
连接表查询就是查询SQL语句包括两个表的查询就是连接表查询.
连接表查询分为:等值连接\内连接\外连接\自连接.
5.4.2.2. 等值连接查询
等值连接查询定义:
同时查询两个表,通过条件筛选两个表对应的记录.
示例代码:
--连接表查询 --需求:查询员工的信息,包括部门的名称 --1.查询员工的信息 select * from emp; --2.查询部门表 Select * from dept; Select * from emp,dept; Oracle里面,如果同时查询两个表,系统会将a表的每一条记录,一一匹配b每一条记录.这个现象称为笛卡尔积. select e.ENAME,d.DNAME from emp e,dept d where e.deptno = d.DEPTNO; |
总结:
等值查询解决了多表连接,如何找到两个表对应的记录.
同时查询两个表,通过条件找到两个表对应对应字段相同的记录.
如果条件相同,返回记录.如果条件不相同(两个表的记录不匹配),就过滤掉
5.4.2.3. 内连接
内连接功能等同于等值查询.只是语法不同
语法
select * from 表1 inner join表2 on 条件
--内连接 --需求:查询员工的信息,包括部门的名称 --select * from 表1 inner join 表2 on 条件 select * from emp e inner join dept d on e.DEPTNO=d.DEPTNO; |
5.4.2.4. 外连接
外连接分为左外连接和右外连接
1.左外连接,连接两个表.如果,左表有的记录,但右表查不到,右表对应字段设置为null(以左表为主表)
--左外连接 --需求:查询员工的信息,包括部门的名称,如果员工对应部门找不到,部门信息为null --select * from 表1 left outer join 表2 on 条件 select * from emp e LEFT JOIN dept d on e.DEPTNO=d.DEPTNO; |
2.右外连接,连接的两个表,如果左表没有对应右表记录,那么左表的字段设置为null
--右外连接 --需求:查询员工的信息,包括部门的名称,如果部门对应的员工信息没有,那么员工字段设置为null select * from emp e right join dept d on d.DEPTNO=e.DEPTNO; |
5.4.2.5. 外连接Oracle的特殊写法
Oracle支持的等值查询风格的外连接.使用(+)符合.将连接的两个表,条件没有(+)符合的作为主表.(没有+作为主表)
| --左外连接 --需求:查询员工的信息,包括部门的名称,如果员工对应部门找不到,部门信息为null select * from emp e,dept d where e.DEPTNO=d.DEPTNO(+); --右外连接 --需求:查询员工的信息,包括部门的名称,如果部门对应的员工信息没有,那么员工字段设置为null select * from emp e,dept d where e.DEPTNO(+)=d.DEPTNO; |
5.4.2.6. 自连接
自连接是一种特殊的连接表查询.连接的两个表是相同的.
应用场景
无限分类.
--需求:查询员工上司的名字 select e.*,s.ENAME as 上司名称 from emp e inner join emp s on e.MGR=s.EMPNO |
5.4.3. 分组查询
--查询每个岗位的平均工资
select job,round(avg(sal),2) from emp GROUPBY job;
注:round获取对应精度的数值。
--分组查询是结合聚合函数来统计数据的. --avg 平均值 --max 最大值 --min 最小值 --count 记录数 --sum 总和 |
--查询每个岗位的平均工资,不包含CLERK
注意:where关键字优先于group by
| --查询每个岗位的平均工资,不包含CLERK select job,avg(sal) from emp where job!='CLERK' GROUP BY job; |
--查询每个岗位的平均工资,不包含CLERK,并且平均工资大于2000
注意:平均工资在分组之后,所以使用having
使用聚合函数作为搜索条件是,需要使用having
| select job,avg(sal) from emp where job!='CLERK' GROUP BY job having avg(sal)>2000; |
注意事项:
1.select查询语句,关键字优先级别
--from > where > group by >having>select >order by
2.分组后的返回字段必要与分组的要一样的.其他字段只能通过聚合函数返回.
5.4.4. 组合查询
由两个select以上组成的查询语句,我们称为组合查询.
嵌套在另一个select的查询叫子查询.
5.4.4.1. 子查询的三种情况
1.作为一个条件在where后面
--需求:查询部门编号与SCOTT用户相同的员工信息 select * from emp where deptno =(select deptno from emp where ename='SCOTT'); |
2.作为一个表在from后面
--需求,查询每个部门最多工资的员工 select * from emp e,(select deptno,max(sal) maxsal from emp group by deptno) t where e.DEPTNO=t.DEPTNO and e.sal=t.maxsal; |
3.作为一个返回结果在select后面
--查询员工的信息,包括部门的名称,不能使用连接表. select emp.*,(select dname from dept where DEPT.DEPTNO=EMP.DEPTNO) from emp; |
5.4.4.2. 子查询的总结
--不管遇到再需求,首先将所有的查询一个一个先写出来.
--如果,查询的两个结果都是表,那么使用连接表.
--如果,查询的两个结果,只要有一个是一值得话,那么将这个值作为另一个结果的条件.
6. 伪表,伪列(rownum/rowid)
6.1. 伪表
在Oracle里面,查询都是使用select关键字的.
而select关键字的语法是: select 结果 from 表
但有这么一些情况.查询系统的函数,或运算结果,或关键字的时候,这个时候是没有表的,这个时候可以使用一个临时表来记录这些数据.
那么这个临时表就是,我们要讲的伪表dual
伪表dual的作用:就是为了临时储存函数,运算结果,关键字等没有表的查询的结果的.
| --查询系统日期 select sysdate from dual; --查询当前用户 select user from dual; --查询运算结果 select 7+9,7-9 from dual; |
6.2. 伪列rowid
Oracle数据库在插入数据的时候,会为每一条数据增加一个唯一标识符.这个唯一标识符就是伪列rowid
问题:我们一般创建表的时候,就显示的声明的ID标识符,为什么还要rowid呢?
伪列rowid一般用于唯一标示没有声明主键表.
--伪列rowid select rowid,emp.* from emp; select rowid,emp.* from emp where rowid='AAASf3AAEAAAACmAAF'; |
6.3. 伪列rownum
Oracle在每一次查询的时候,会为每一条记录增加一个序号.这个序号就是伪列rownum.
select rownum,emp.* from emp; |
Rownum的查询结果
rownum等于某个值 |
rownum=1可以查询,但是rownum=2无法查询 |
rownum小于某个值 |
rownum<11能获得10条记录 |
rownum大于某个值 |
rownum>n 不成立 |
伪列rownum的作用:
Oracle没有像MySQL的limit关键字分页.是通过rownum来实现分页的.
需求:查询员工表1-9条的数据.
--需求:查询1-9条的数据. select rownum,emp.* from emp where rownum <=9; |
需求:查询员工表5-10的数据
--rownum不能直接使用>或>=号. --如果要使用>或>=号,需求先查出来,再使用子查询来使用. --这种是错误的写法 --select rownum,emp.* from emp where rownum <=10 and rownum>=5; --先取上线 select rownum as r,emp.* from emp where rownum <=10; --使用子查询再去下限 select * from (select rownum as r,emp.* from emp where rownum <=10) tmp where tmp.r>=5; |
需求:查询员工的信息,先按部门排序,再取5-10条的数据.
1.解决乱号问题
问题:如果排序后,rownum就乱号了.
--如何解决.
思路,先排序,后产生rownum.
--如何做到
可以使用先排序,再使用子查询来产生rownum
select rownum, tmp.* from (select * from emp order by deptno) tmp; |
2.取数据上下限
select * from (select rownum as r, tmp.* from (select * from emp order by deptno) tmp) tmp2 where tmp2.r<=10 and tmp2.r>=5; |
7. 运算符
7.1. 数学运算符
+ - * /
--运算 select 8+9,8-9,8*9,8/9 from dual; --需求:增加SCOTT用户的工资500元 update emp set sal=sal+500 where ename='SCOTT'; |
7.2. 对比运算符
符号 |
说明 |
= |
等于 |
> |
大于 |
< |
小于 |
>= |
大于等于 |
<= |
小于等于 |
!=,<> |
不等于,!=与<>功能是一样,<>是SQL标准不等于,所有数据库都支持,!=非标准不等于,并不是所有数据库支持的. |
in |
包含 |
like |
模糊匹配 |
between .. and .. |
范围 |
--in运算符
--需求:查询员工的的部门编号包含10,或者20的员工 --in, select * from emp where deptno in (10,20); |
--betweet .. and .. 范围运算符
1.判断数值的范围
--需求:查询员工的工资在2000-3000的员工,包括2000与3000 select * from emp where sal>=2000 and sal<=3000; --between.. and .. select * from emp where sal between 2000 and 3000; |
2.判断日期的范围
--需求:查询员工的入职日期1981-04-01至1981-10-10 select * from emp where hiredate between to_date('1981-04-01','yyyy-mm-dd') and to_date('1981-10-10','yyyy-mm-dd'); |
7.3. 逻辑运算符
运算符 |
说明 |
and |
与 |
or |
或 |
not |
非 |
--and --需求:查询员工的工资在2000-3000的员工,包括2000与3000 select * from emp where sal>=2000 and sal<=3000; --or --需求:查询员工的的部门编号包含10,或者20的员工 select * from emp where deptno=10 or deptno=20; --需求:查询奖金非空的员工 select * from emp where comm is not null; |
7.4. 集合运算符
并集:union
并所有:union all
交集:intersect 取得两个查询的公共部分
减集:minus 1集合减去 1集合2集合的交集
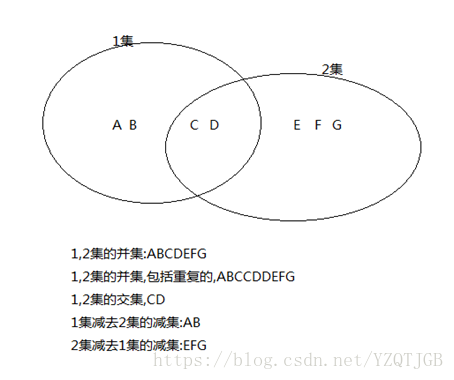
1.需求:查询员工的工资1000-3000的员工信息,并集员工的工资2000-5000的员工信息
--分析,查询的范围,1000-5000; --并集,union select * from emp where sal between 1000 and 3000 union select * from emp where sal between 2000 and 5000; |
2.需求:查询员工的工资1000-3000的员工信息,并集员工的工资2000-5000的员工信息,有重复.
分析:查询的范围1000-5000,重复的是2000-3000
重复的是交集
--有重复的并集 union all select * from (select * from emp where sal between 1000 and 3000 union all select * from emp where sal between 2000 and 5000) order by ename; |
3.需求:查询员工的工资1000-3000的员工信息,交集员工的工资2000-5000的员工信息
| --分析:范围2000-3000 --交集 intersect select * from emp where sal between 1000 and 3000 intersect select * from emp where sal between 2000 and 5000; |
4.需求:查询员工的工资1000-3000的员工信息减集员工的工资2000-5000的员工信息
--减集:范围是1000-1999, --减集要减去交集的数据,2000是交集里面的值所以要减掉 --减集:minus select * from emp where sal between 1000 and 3000 minus select * from emp where sal between 2000 and 5000; |
集合运算符,效率很低,一般不是没有办法,是不会用的.
8. 常用函数
常用函数就是Oracle数据库内置的函数.
8.1. 主要分类
数值函数,处理数值的
字符函数,处理字符串
日期时间函数,处理日期时间
转换函数,实现时间\数值\字符的转换
其他函数,乱七八糟的,没有分类的函数
聚合函数,用于统计
8.2. 数值函数
round(p,s):四舍五入函数
p:原值
s:精度
注意:
精度不写,默认为0,精确到个位.
如果是正数:保留小数位多少位
如果是负数:从个位开始,往左保留多位.
-1精确到十位,-2精确到百位。
需求:求每个工作岗位的平均工资,保留两位小数点.四舍五入 --保留小数 select job,avg(sal),round(avg(sal),2) from emp group by job; --忽略正数部分,从个位开始,往左. select job,avg(sal),round(avg(sal),-2) from emp group by job; |
trunc(p,s):截取函数
p:原值
s:精度
注意:
精度不写,默认为0,精确到个位.
如果是正数:保留小数位多少位
如果是负数:从个位开始,往左保留多位.
需求:求每个工作岗位的平均工资,保留两位小数点 --保留小数,截取多余的小数位 select job,avg(sal),trunc(avg(sal),2) from emp group by job; --忽略正数部分,从个位开始,往左截取. select job,avg(sal),trunc(avg(sal),-2) from emp group by job; |
8.3. 字符函数
length(p):计算长度
--p:原值
--需求:求员工名字的长度 select ename,length(ename) from emp; --需求:求’北大青鸟’的长度 --不管中英文,都是按字符的个数来算 select length('北大青鸟') from dual; |
填充函数lpad,rpad,
--左填充lpad,右填充,rpad
----左填充lpad(p,n,c)
--p:原值
--n:指定的长度
--c:如果长度不够,指定的填充字符,如果不写,默认是空字符
--左填充函数 --汉字,一个字符gbk占两位,utf-8占3位 select lpad('北大青鸟',10,'*') from dual; --字母,一个字符占一位. select lpad('abcd',10,'*') from dual; --右填充函数 select rpad('北大青鸟',10,'*') from dual; --字母,一个字符占一位. select rpad('abcd',10,'*') from dual; |
replace(p,c1,c2):替换函数
p:原值
c1:原值中,被替换的字符
c2:替换的新字符
--将原值中的my换成your select replace(‘mynameisitheima’,’my’,’your’) from dual; --如果不写,等于截取了字符串 select replace('mynameisitheima','my') from dual; |
substr(p,n1,n2):字符串截取函数
p:原值
n1:开始截取的位置,位置从1开始
n2:表示截取字符的个数,如果不写截到最后
--位置从1开始 select substr('mynameisitheima',1,5) from dual; --如果不写n2,截到最后 select substr('mynameisitheima',2) from dual; |
8.4. 日期时间函数
extract日期时间提取函数
--获得当前日期 select sysdate from dual; --日期提取函数 --日期 --extract(year from 日期) --时间 --extract(year from 时间) --extract(year from to_timestamp('字符串','格式')) --extract(year from timestamp '字符串') --年 select extract(year from sysdate) from dual; --月 select extract(month from sysdate) from dual; --日 select extract(day from sysdate) from dual; --时间提取 --时 select extract(hour from to_timestamp('2017-03-09 13:22:34','yyyy-mm-dd hh24:mi:ss')) from dual; select extract(hour from timestamp '2017-03-09 13:22:34') from dual; --分 select extract(minute from timestamp '2017-03-09 13:22:34') from dual; --秒 select extract(second from timestamp '2017-03-09 13:22:34') from dual; |
add_months(p,m)增加月份函数
p:原值,日期类型
m:增加的月份
--增加月份函数,正数为加 select add_months(sysdate,-3) from dual; --增加月份函数,负数为减 select add_months(sysdate,-3) from dual; |
months_between:月份对比函数,返回两个日期月份间隔
--months_between(d1,d2)
--如果d1小于d2,返回负数
--如果d1大于d2,返回正数
--如果d1等于d2,返回0
作用:可以用于两个时间的对比.
| select months_between (to_date('2017-03-01','YYYY-MM-DD'), to_date('2017-03-03','YYYY-mm-dd') ) from dual; |
8.5. 转换函数
to_char(p,f):时间日期转字符串
p:原值,日期或时间类型,数值
f:格式,如:’yyyy-mm-ddhh24:mi:ss’
--需求:将当前日期转成字符串 select to_char(sysdate,'yyyy-mm-dd') from dual; --转换时间 select to_char(to_timestamp('2017-03-09 13:22:34','yyyy-mm-dd hh24:mi:ss'),'yyyy-mm-dd hh24:mi:ss') from dual; |
to_timestamp(p,f):将字符串转换成时间
p:原值,字符串类型
f:时间格式
select to_timestamp('2017-03-09 13:22:34','yyyy-mm-dd hh24:mi:ss') from dual; |
to_date(p,f):将字符串转成日期
select to_date('2017-10-10','yyyy-mm-dd') from dual; |
8.6. 其他函数
nvl(p,c):null处理函数
如果p为null(空字符),将值自动转换为c
注意,c的值类型与字段一样.
--需求:查询没有奖金的员工 --如果使用空处理函数,可以直接将null修改为0判断0就可以 select emp.*,nvl(comm,0) from emp where nvl(comm,0)<>0; |
nvl2(p,c1,c2):null处理函数
如果p不为null,那么c1,为空c2
select emp.*,nvl2(comm,comm,0) from emp; |
decode(条件,值1,翻译值1,值2,翻译值2,...值n,翻译值n,缺省值)
判断函数
需求:查询员工的信息,如果部门的编号为10,那么输出’综合部’,如果部门编号20,输出’技术部’ 如果为30,输出’销售部’,否则输出’未知部’ select emp.*,decode(emp.deptno,10,'综合部',20,'技术部',30,'销售部','未知部') from emp; |
8.7. 聚合函数
max --统计最大值
min --统计最小值
sum --统计总数
count --统计记录数
avg --统计平均值
9. 创建数据库
参照《通过DBCA工具创建数据库.pdf》创建数据库
10.表(table)
表的功能,就是储存数据.所以表就是一个用于存储数据的数据库对象.
10.1. 创建表的语法
create table <表名>( 字段名 数据类型 [not null] [primary key], 字段名 数据类型 ... ... ); |
示例代码
--需求:创建一个用户表 |
查看当前用户的表
--查看当前用户表 select * from tabs; |
查看表结构
--查看表结构 --desc table_name; desc tb_users; |
10.2. 删除表
--删除用户表 drop table tb_users; |
10.3. 示例代码
| --删除表之前判断表是否存在,如果存在则删除 --drop table if exists tb_user; declare num number; begin select count(1) into num from user_tables where table_name=upper('tb_user'); if num>0 then execute immediate 'drop table tb_user'; end if; end; create table tb_user( user_id number(10) not null primary key, user_name varchar2(10) not null, user_pwd varchar2(20) not null ); -- 给表加注释 comment on table tb_user is '用户表'; --给对应的字段加注释 comment on column tb_user.user_id is '用户编号'; comment on column tb_user.user_name is '用户名'; comment on column tb_user.user_pwd is '用户密码'; |
10.4. 表的数据类型
数据类型 |
说明 |
varchar2 |
可变长度的字符串,最大长度4000字符. 英文字符占一个字节,中文如果是gbk占两个字节,如果是uft-8占三个字节 注意:varchar会自动转成varchar2 |
nvarchar2 |
可变长度的字符串,最大长度4000字符. gbk,不管中英文都是两个字节,uft-8,不管中英文都是三个字节 注意:varchar会自动转成varchar2 |
char |
固定长度的字符串,最大长度4000字符. 英文字符占一个字节,中文如果是gbk占两个字节,如果是uft-8占三个字节 |
nchar |
固定长度的字符串,长度4000字符. gbk,不管中英文都是两个字节,uft-8,不管中英文都是三个字节 |
number(p,s) |
p:表示长度,s表示精度,p的长度不能超38位 s:如果不写,或为0,为整数 s:正数,是一个小数,如: number(10,2):这个类型最多可以储存10位,其中8位是整数,两位是小数,99999999.99 number(8,0),这个类型为整数,最大,9999999 |
date |
日期类型,不能储存时间(不能存储时分秒) |
timestamp |
日期时间类型 |
clob |
大文本类型,最大储存4G的文本. |
blob |
二进制储存类型,一般储存图片,流数据 |
10.5. 修改表
语法:
--增加字段 alter table <表名> add (字段名 数据类型 [not null],....); --修改字段 alter table <表名> modify(字段名 数据类型 [not null],....); --删除字段 alter table <表名> drop(字段名,....); --修改字段名 alter table <表名> rename column <旧字段> to <新字段>; |
实例代码
--给表添加字段 alter table tb_user add(user_age number(3) not null); --修改表字段 alter table tb_user modify(user_age number(10) null); --删除表字段 alter table tb_user drop(user_age); --修改密码的字段名 alter table tb_user rename column user_pwd to user_password; |
10.6. 注意事项
问题:创建表时候,字段表名等都不区分大小写,那么内容区分大小写吗?
注意,任何的数据库内容区分大小写的.因为,我们要保证插入的数据与保存的一致.
Oracle除了内容区分大小写,其他的东西会自动转成大写.
11.表的约束
11.1. 约束的类型
--检查约束 check
--唯一约束 unique
--外键约束 foreign key(外键) references 外键表(字段);
11.2. 约束的语法
create table <表名>( 字段名 数据类型 [not null] [primary key], .... --检查约束,作用就是固定插入值是指定的. constraint <约束名> check (<字段名> in(‘值1’,’值2’....) ) --唯一约束,保证字段的值不会重复 constraint <约束名> unique (字段名) --外键约束,保证数据的完整性 constraint <约束名> foreign key(外键) references 外键表(<主键>); ); |
示例代码
创建用户类型表和用户表,性别只能插入男或者女,用户名不能重复,添加外键关联 --表的约束 |
12.表空间
为什么Oracle数据库管理系统,我们不像MySQL,一个数据库就分隔一个项目.因为Oracle一个数据库就是一个系统服务,占有的系统资源很大.
Oracle的管理模式,建议一个数据库管理系统一般就创建一个数据库,通过表空间来分隔数据.
12.1. 表空间是什么
表空间就是Oracle数据库里面最大的物理存储单元.
最大的物理存储单元:就是说,创建一个表空间肯定会产生对应文件.
12.2. 表空间的作用
表空间就是用于储存用户的数据的.
所以创建用户的时候,一定要指定数据放在哪个表空间.
方便对用户数据的管理操作,对对象模型的管理。
可以将不同的数据文件创建到不同的磁盘中,有利于磁盘管理,有利于提高I/O性能,有利于恢复和备份
12.3. 创建表空间语法
create tablespace <表空间> datafile ‘路径/文件名’ --指定生成的路径的,默认不指定路径只写文件名,放在dbhome_1\database size <大小> [auto_extends on|off] ,默认是on ,如果数据超过了初始化的大小,要不要自动扩大 [next] <大小> 如果支持自动扩大,每次扩大多大 [maxsize] <大小> 指定最大的大小,默认是 unlimit ,不限制. --查看表空间 --系统内置的信息表dba_data_files;查看表空间的文件的 select * from dba_data_files; |
示例代码
--创建表空间 --创建表空间 |
12.4. 修改表空间
--修改表空间 --需求:Oracle数据库发现数据存放的硬盘满了,如何保证数据可以继续存在这个表空间. --解决方案,可以给表空间在另外一个硬盘增加一个数据文件 --给表空间增加文件 alter tablespace ysjt_tablespace add datafile --表空间满的处理办法: 调整表空间的大小 --修改数据库文件的大小 alter database datafile 'D:/oracle11g/dataextend/ysjt_extend.dbf' resize 20M; --在原来的表空间中添加数据文件
|
12.5. 删除表空间
--删除表空间 --逻辑删除,不删文件 drop tablespace 表空间名称; --物理删除 drop tablespace 表空间名称including contents and datafiles; |
12.6. 设置表空间只读
--设置表空间只读 alter tablespace 表空间名 readonly; |
注意事项:
创建表空间,必须使用管理员,如system
13.oracle数据库用户
13.1. 常见系统内置的用户
用户名 |
说明 |
sys |
超级管理员,一般开发人员以及数据库的管理不用.用于数据库出了异常后维护(DBA) |
system |
系统管理员,有管理员权限普通用户.管理表空间,用户的创建..等数据库的管理 |
scott |
示例的普通用户,用于学习. |
注意:超级管理员与系统管理员的密码默认都是安装数据时的管理口令.
13.2. 创建用户
创建用户的语法 create user <用户名> identified by 密码 [default tablespace <表空间名称>] -- 默认表空间 [temporary tablespace <表空间名称>] --临时表空间 [quota {大小|unlimited} on tablespace] -- 限额 [password expired] -- 第一次登录的时候需要修改密码 |
示例代码
--创建ysjt用户 --查看用户 --查看用户信息 --all_users是一个内置信息表,所以只能记住 select * from all_users; --查看用户的详细信息 --dba_users,也是一个内置信息表. select * from dba_users; -- 查看表空间限额 select * from dba_ts_quota; |
13.3. 修改用户
--修改用户 --修改,锁定 --alter user <用户名> account lock; --解锁 --alter user <用户名> account unlock; --修改密码 --alter user <用户名> identified by <密码>; |
13.4. 删除用户
--删除用户 --cascade,表示删除用户也把用户数据删除 drop user <用户名> [cascade]; |
14.用户授权(DCL)
DCL:数据控制语言,用于数据库用户的授权撤权
Oracle是一个非常安全的数据库.所有用户没有授权都不能对数据库做任何操作,包括登录也不能.
grant/revoke;
14.1. 用户授权的分类
系统权限授权:授予系统的权限,就是用户本身访问自身表空间的权限.
如:创建一个新用户后,它有没有登录的权限,也没有操作表的权限.
对象权限授权:就是授权用户访问别的用户的访问权限.
如:创建一个新用户laomao,要不要给他授予访问scott用户的权限.
14.2. 系统权限授权
系统权限授权的语法:
grant 系统权限 to 用户名 |
示例代码:
| --给用户登录的权限 --登录的权限为create session grant create session to laomao; --授权创建表的权限 --有了创建的权限,就是这个数据库对象的所有者,create包括了alter,drop --反过来,有alter,获得drop的权限不一定有create的权限. grant create table to laomao; --查看Oracle系统有哪些系统权限 --在内置的表dba_sys_privs查看 select * from dba_sys_privs; --如果一个一个系统权限授权,很麻烦, --可以通过角色授权. --角色就是一个权限组,如果一个用户授权了一个角色,那么这个用户就拥有这个角色的所有权限 --常见的角色 --DBA,这个角色拥有管理员的权限,如果给用户授予这个角色,那么这个用户就是管理员 --CONNECT,拥有登录的权限.如果给用户授予这个角色,用户可以登录 --RESOURCE,拥有基础的操作权限,如果给用户授予这个角色,用户可以基础的操作权限. --查看RESOURCE的权限 select * from dba_sys_privs where grantee='RESOURCE'; --查看CONNECT的权限 --查看系统内置的角色 --使用内置信息表,dba_roles select * from dba_roles; --使用角色授予系统权限 grant connect,resource to laomao; |
14.3. 查看当前用户的系统权限
--查看用户当前权限 --查看用户的系统权限,user_sys_privs select * from user_sys_privs; --查看当前用户的角色 select * from user_role_privs; --查看当前用户的角色的权限 select * from role_sys_privs; |
14.4. 对象授权
对象权限授权:就是授权用户访问别的用户的访问权限.
对象权限授权的语法:
| grant insert,delete,update,select on 授权的用户名.表名 to 被授权的用户名 |
示例代码:
--需求:将scott用户的emp,dept,salgrande三个复制到<新用户> --1.让laomao访问scott的表 --给<新用户>用户授予访问scott用户的对象权限 grant select on scott.emp to <新用户>; grant insert,delete,update,select on scott.dept to <新用户>; grant select on scott.salgrade to <新用户>; --访问格式,用户名.表名 select * from scott.emp; select * from scott.dept; select * from scott.salgrade; --2.如何将数据拷贝到另外一个表 --create table <表名> as select 语句 --将scott用户的表复制到当前用户 create table emp as select * from scott.emp; create table dept as select * from scott.dept; create table salgrade as select * from SCOTT.salgrade; |
14.5. 查看当前用户的对象权限
--查看当前用户的对象权限 select * from user_tab_privs; |
15.用户撤权
用户撤权,就是撤销用户的权限
用户撤权包括的系统权限撤销还有对象权限撤销.
系统权限撤权:就是撤销用户的系统权限
对象权限撤权:就是撤销用户的对象权限
15.1. 系统权限撤销
系统权限语法:
| revoke 系统权限|角色 from <用户名> |
示例代码:
--撤销角色系统权限 revoke connect from laomao; --撤销系统权限 revoke create session from laomao; |
15.2. 对象权限的撤权
对象权限撤权语法:
revoke insert,delete,update,select on 授权用户名.表名 from 被授权的用户 |
示例代码:
--撤销laomao用户对scott的dept表的增删改的对象权限 revoke insert,delete,update on scott.dept from laomao; |
16.序列
16.1. 序列是什么
序列就是一个Oracle数据库实现计数器的数据库对象,该数据库对象是Oracle数据库特有的.
序列是用户生成唯一,连续序号的对象
序号可以是升序,也可以是降序
使用create sequence语句创建序列
16.2. 序列的作用
Oracle没有像MySQL实现ID自增长的关键字字,auto_increment.
它是通过序列来实现ID自增长.
16.3. 序列的语法
create sequence <序列名> increment by <大小> --表示步长,每次增加的数 start with <大小> --开始位置 maxvalue <大小> --最大大小 nomaxvlaues --不限制大小 minvalue <大小> --最小值 nocycle|cycle --是否在超过最大值时,重新开始. nocycle不支持,cycle 支持. cache <大小> --默认20,缓存多少个计数. ; --一般情况使用一下几个属性就够了 create sequence <序列名> increment by <大小> --表示步长,每次增加的数 start with <大小> --开始位置 nomaxvlaues --不限制大小 |
正序序列示例代码
--序列 create sequence seq_emp increment by 1 --表示步长,每次增加的数 start with 1 --开始位置 nomaxvalue minvalue 1 --最小值 nocycle --是否在超过最大值时,重新开始. nocycle不支持,cycle 支持. cache 20 -- 默认20,缓存多少个计数. ;
--查看序列 select * from user_sequences; --如何调用序列 --获得当前值 序列名.currval select seq_emp.currval from dual; --创建一个序列值 select seq_emp.nextval from dual; --使用序列插入emp表数据 insert into emp (empno,ename) values(seq_emp.nextval ,'seq1'); |
倒序倒序的示例代码
作用:一般用于程序需要计数器.
--倒序的序列 create sequence seq_1 increment by -1 --正数正序,负数倒序 start with 5000 minvalue 1 maxvalue 5000; --使用倒序 select seq_1.nextval from dual; |
16.4. 修改序列
--修改序列 alter sequence 序列名 修改的参数 |
注意事项:修改序列不能更改序列的start with参数
16.5. 删除序列
--删除序列 drop sequence seq_emp; |
16.6. sys_guid函数
16.6.1. sys_guid是什么
生成32位的唯一编码作为主键
源自不需要对数据库进行放回的时间戳和机器标识符组成
16.6.2. 序列与sys_guid的区别
在不需要并行或者远程的环境中使用序列作为主键
在并行的环境或者希望避免使用序列的情况下使用sys_guid
不同的数据库中但需要在后来合并到一起时候使用sys_guid函数
注意事项:
在单一环境中使用序列作为表的关键字
在并行或者远程环境中使用sys_guid函数作为表的主关键字
第一次使用序列的时候一定要使用nextval进行初始化
修改序列是不可以修改startwith参数
序列和sys_guid函数使用的不同场合
17.同义词
17.1. 什么是同义词
同义词就是数据库对象的一个别名.对同义词的所有操作,直接影响的都是同义词指向的表.
select * from B.表名
17.2. 同义词的作用
如果遇到数据库对象名(如:表名)很长的时候,可以使用同义词来缩短它的名称(简化sql语句
).
隐藏对象名称和所有者
提供对对象的公共访问
17.3. 同义词的分类
私有同义词
只能在其模式内访问使用,不能与当前模式的对象同名
公有同义词
可以被所有的数据库用户访问
17.4. 同义词的创建
同义词的创建语法:
create synonym <同义词名> for 数据库对象(如:表|视图) |
示例代码:
--需求:给emp表一个同义词,syn_emp grant create synonym to laomao; create synonym syn_emp for emp; --查看同义词 select * from user_synonyms; --使用同义词 select * from syn_emp; insert into syn_emp(empno,ename) values(100,'天天'); |
17.5. 删除同义词
--删除同义词 drop synonym <同义词名称>; |
18.公有同义词
18.1. 公有同义词的创建
公有同义词的创建语法:
语法: create public synonym <同义词名> for 表|视图 |
示例代码:
--公有同义词 --需求:给emp表一个公有同义词,p_syn_emp /* */ grant create public synonym to laomao; create public synonym p_syn_emp for emp; --使用公有同义词 select * from p_syn_emp; insert into p_syn_emp(empno,ename) values(1009,'gy'); |
18.2. 公有同义词与私有同义词的区别
公有同义词属于数据库系统,私有同义词属于数据库用户.
--使用system访问同义词 select * from laomao.syn_emp; --用户的同义词是属于用户的,所以其他用户必须使用用户名访问 --select * from syn_emp;,错误的 --使用system访问公有同义词 select * from p_syn_emp; --不管哪个用户创建的公有同义词,都是属于系统的.不能使用用户名访问 --select * from laomao.p_syn_emp;是错误的 --所以,所有的用户创建的公有同义词名字不能重复 |
公有同义词使用场景:如果你有希望成为系统表一样,让所有用户都可以查看时可以使用
18.3. 公有同义词的删除
--删除公有同义词 --因为公有同义词是属于系统的,所以create不包括drop的权限 grant drop public synonym to laomao; drop public synonym p_syn_emp; |
19.索引
19.1. 索引是什么
索引就是一个提高查询效率的数据库解决方案.
19.2. 索引的作用
索引的作用就是提高查询的效率
19.3. 索引创建
--唯一索引,字段的是唯一的 create unique index <索引名> on 表(字段名 asc|desc); --非唯一索引,字段是非唯一 create index <索引名> on 表(字段名 asc|desc); |
示例代码
--emp表的ename创建唯一索引 create unique index ind_emp_ename on emp(ename asc); --查看索引 select * from SYS.user_indexes; ----给工作岗位创建一个非唯一索引 create index ind_emp_job on emp(job asc); |
19.4. 索引的分类
B树索引, 反向键索引,位图索引,基于函数索引,组合索引
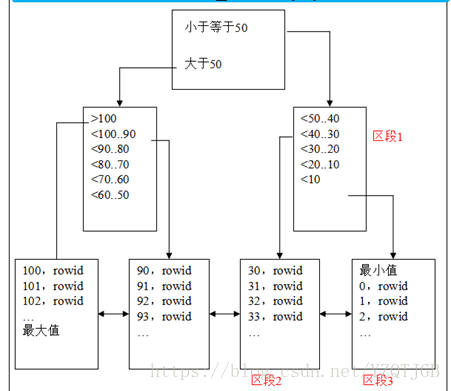
19.4.1. B树索引
语法:
create index 索引名 on 表名(parameter...);
树形结构--画图
双向链表
原理:
192.168.3.58 |
create index 索引名 on 表(字段名);
数据分布均匀
19.4.2. 反向键索引
反向键索引的语法:
create index 索引名 on 表名(parameter...)reverse;
反转索引列键值的每个字节
应用场景:连续增长的列作为索引可以创建反向键索引
主键列创建反向索引键索引
create unique index 索引名表名(字段名) reverse;
altertable employee add constraint 索引名称 primary key(主键名) using index 索引名;
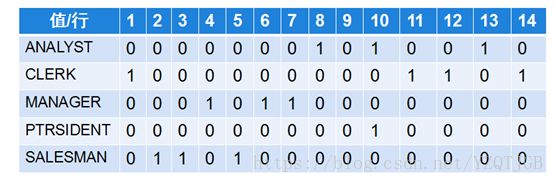
19.4.3. 位图索引
位图索引的语法:
create bitmap index 索引名 on 表(字段名);
位图索引不直接存储rowid,而是存储字节位到rowid的映射
减少响应时间,节省空间
应用场景:
适合创建在低基数列上(横纵列较少)
位图索引的原理图:
19.4.4. 基于函数索引
基于一个或者多个列上的函数或表达式创建的索引
表达式中不能出现聚合函数
不能在lob类型的列上创建
创建时必须具有query rewrite 权限
create index 索引名 on 表(lower(表名))
19.4.5. 组合索引
组合索引是在表的多个列上创建的索引
当某几个字段在sql语句的where子句中经常通过and操作符联合在一起使用作为过滤条件
语法:
create index 索引名 on 表名(字段1,字段2);
复合索引使用原则
最频繁使用的字段排在第一位
使用频率相同,则将最具选择性的字段(差别大的字段)排在最前面
19.5. 删除索引
| --删除索引 drop index 索引名称; drop index ind_emp_job; |
19.6. 什么时候的索引
1.数据表特别大的时候,小于10W不要创建
2.经常作为查询条件的字段
19.7. 什么时候不要创建索引
1.数据表很小
2.不经常查询的字段
3.类型是大文本类型的字段不要创建索引,clob,blob.MySQL的text
19.8. 索引使用的原则
1.表中导入数据后在创建索引。否则每次表中插入数据时都必须更新索引
2.在适当的表和字段上创建索引。如果经常检索的数据少于表中15%则需要创建索引
3.限制表中的索引的数目,索引越多,在修改表时对索引维护的工作量越大
20.分区表
20.1. 分区表是什么
分区表就是分了区的表.
分区表是将表分成多个区,那么就可以通过策略来指定分区的数据,从而减少了查询的数据来提高查询效率.
20.2. 分区表的作用
减少表查询的数据量来实现提高查询的效率.
20.3. 分区表的创建
| --列表分区,使用列表值来分区, --特征:使用一个字段值来分区 create table <表名> ( 字段名 类型名 ...
)partition by list(字段名)( partition <区名> values(值1), partition <区名> values(值2), partition <区名> values(值3), ... partition <区名> values(default) ); --范围分区,使用分区的字段对应的是一个范围 create table <表名> ( 字段名 类型名 ...
)partition by range(字段名)( partition <区名> values lesss than(值1), partition <区名> values lesss than(值2), partition <区名> values lesss than(值3), ... partition <区名> values(default) ); |
示例代码
需求:创建一个表,使用部门编号分区 --需求:创建一个表,使用部门编号分区 create table tb_emp( empno number(10) primary key, ename varchar(50) not null, deptno number(10) )partition by list(deptno)( partition p1 values(10), partition p2 values(20), partition p3 values(default) ); --插入数据 insert into tb_emp(empno,ename,deptno) values(1,'张三',10); insert into tb_emp(empno,ename,deptno) values(2,'李四',20); insert into tb_emp(empno,ename,deptno) values(3,'王五',30); insert into tb_emp(empno,ename,deptno) values(4,'赵六',20); insert into tb_emp(empno,ename,deptno) values(5,'陈七',10); --全表查询 select * from tb_emp; --全表查询 select * from tb_emp partition; --指定分区查询 select * from tb_emp partition(p3); --需求:创建一个表,使用员工的工资的范围分区 p1: 1-1999 p2: 2000-4999 p3: 5000以上
create table tb_emp_range ( empno number(10) primary key, ename varchar(50) not null, sal number(10) , deptno number(10) )partition by range(sal)( partition p1 values less than(2000), ---0-1999 partition p2 values less than(5000), --2000-4999 partition p3 values less than(maxvalue) ); --插入数据 insert into tb_emp_range(empno,ename,sal,deptno) values(1,'张三',1999,10); insert into tb_emp_range(empno,ename,sal,deptno) values(2,'李四',2000,20); insert into tb_emp_range(empno,ename,sal,deptno) values(3,'王五',4999,30); insert into tb_emp_range(empno,ename,sal,deptno) values(4,'赵六',5000,20); insert into tb_emp_range(empno,ename,sal,deptno) values(5,'陈七',20000,10); --测试 --全表查询 select * from tb_emp_range; --分区查询 select * from tb_emp_range partition(p1); select * from tb_emp_range partition(p2); select * from tb_emp_range partition(p3); |
注意事项:
1.列表分区,值可以是字符也可以是数值类型
2.范围分区,值可以是数字类型与时间类型.
21.其他
账号被锁定时的处理办法:

1.通过以dba的身份登录
sqlplus / as sysdba;
2.解锁
alter user scott accountunlock;
3.测试
conn scott/scott;
//修改用户密码

切换用户

连接时指定对应的数据库
