以下来自湖科大计算机网络公开课笔记及个人所搜集资料
目录
湖科大计网公开课的应用层这块讲的不够详细,尤其是HTTP相关的协议,在实际项目或者面试中,HTTP相关的协议是非常重要的,这里先记录课堂笔记,后续补更。
先回顾先TCP/IP网络体系教学的五层模型:

一. C/S方式和P2P对等方式
C/S方式中,服务器总是处于运行状态并等待客户服务请求。服务器具有固定的端口号(如HTTP服务器的默认端口号是80),运行服务器的主机也具有固定的IP地址。
C/S中,客户和服务器是两个应用进程,只是有时候我们往往把运行服务器的主机也简称为服务器。
万维网WWW(web服务器,www.xxx.com这种)、电子邮件、文件传输FTP这些网络应用都是C/S方式。
基于C/S方式的应用服务,通常是服务集中型的,并且构建服务器集群来构建虚拟服务器。
p2p(peer-to-peer)方式,没有固定的服务请求者和服务提供者。网络各端系统上的应用进程是对等的,被称为对等方,对等方之间直接通信,每个对等方即是服务请求者,又是服务提供者。应用:p2p文件共享、及时通信、p2p流媒体、分布式存储等。这些应用是分散型的。(QQ微信是C/S模式)
p2p最突出特点是可扩展性,系统性能不会因为规模的增大而降低。

二. 动态主机配置协议DHCP
作用:
自动给网络中的主机分配IP地址,子网掩码、默认网关、DNS服务器IP等网络配置,使得不需要手工挨个给那么主机配置(配置了这些他们才能上网)
在网络中添加一台DHCP服务器,在该服务器中设置好可为网络中其他各主机配置的网络配置信息。网络中各主机开机后自动启动DHCP程序,向DHCP服务器请求自己的网络配置信息,这样网络中的各主机就都可以从DHCP服务器自动获取网络配置信息,而不用手工参与。

工作过程:
下面只记录需注意的点:
DHCP报文在运输层会被封装成UDP用户数据报。
主机(DHCP客户)在寻找DHCP服务器的时候是发送广播,内容是DHCP发现报文。报文里包含事务ID和DHCP客户端的MAC地址(源IP地址是0.0.0.0,因为此时的主机都没被配置网络信息,所以也不知道自己的IP地址,就写的0.0.0.0)
DHCP服务器会使用ARP来确保所选的IP地址没被网络中其它主机占用。(ARP协议就是解析IP地址找到MAC地址)
三.域名系统DNS
Domain Name System。domain是域的意思
当我们在浏览器地址栏中输入某个WEB服务器的域名时,用户主机会首先在自己的DNS高速缓存中查找该域名所对应的IP地址。
如果没有找到,则会向网络中的某台DNS服务器查询,DNS服务器中有域名和IP地址映射关系的数据库。当DNS服务器收到DNS查询报文号,在其数据库中进行查询,之后将查询结果发送给用户主机。
DNS用的是分布在各地的域名服务器来实现域名到IP地址的转换
域名解析过程
分为递归查询、迭代查询。
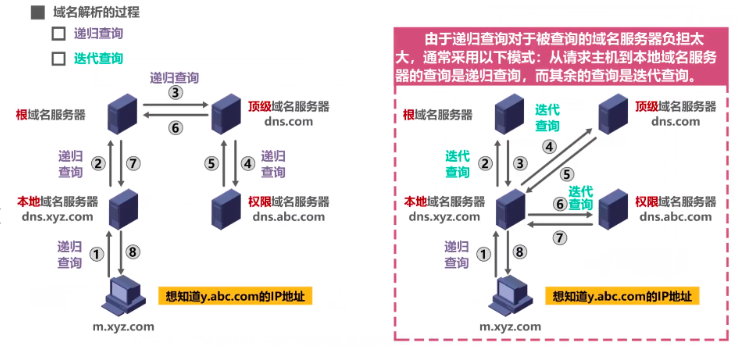
各个域名服务器:

在域名服务器中广泛的使用了高速缓存,高速缓存用来存放最近查询过的域名,以及从何处获得域名映射信息的记录。
作用:
-
提高DNS的查询效率
-
减轻根域名服务器的负担
-
减少因特网上的DNS查询报文数量
注意,用户主机里也有高速缓存
四.文件传输协议FTP
采用的是C/S模式。
FTP的常见用途是在计算机之间传输文件,尤其是用于批量传输文件,FTP的另一个常见用途是让网站设计者将构成网站内容的大量文件,批量上传到他们的web服务器。
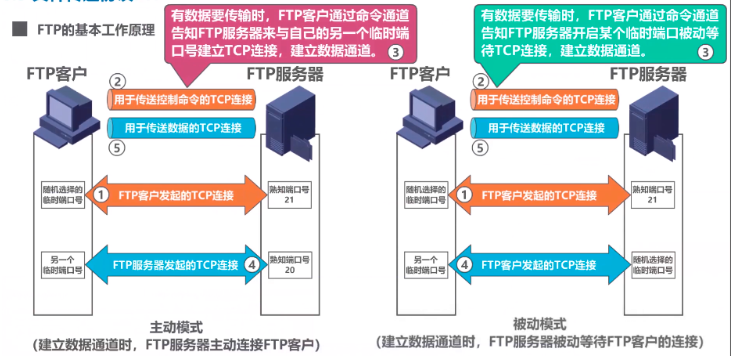
基本工作原理:
基于TCP协议。FTP客户和服务器之间要建立两个并行的TCP连接:一个是控制连接,一个是数据连接。
控制连接传送控制命令,数据连接传输文件。
五.电子邮件
也是采用C/S方式。
服务器分为发送方邮件服务器和接收方邮件服务器。即发送方需要使用邮件发送协议比如SMTP将邮件发送给发送方服务器,再由后者使用SMTP发送给接收方邮件服务器。
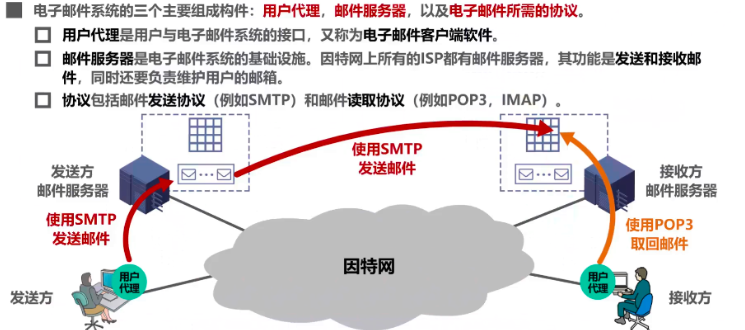
这些发送过程都需要建立TCP连接。
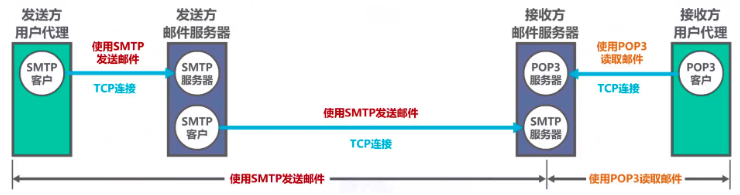
还介绍了 简单邮件传送协议SMTP(Simple Mail Transfer Protocol)的基本工作原理。
POP3和IMAP4都是邮件读取协议,它们都采用基于TCP的C/S模型。
现在QQ邮箱,163邮箱这种都是用浏览器登录邮件服务器的万维网网站,不需要下载软件。
这个时候发邮件和接收邮件都是使用http协议,过程如下图:
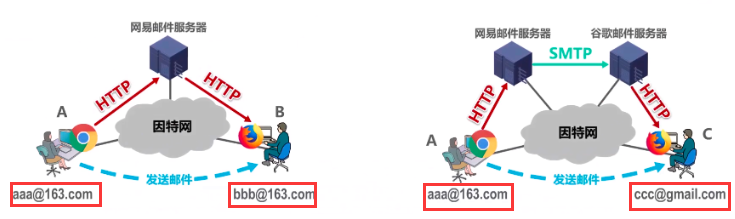
左图是用相同的邮件服务器,右图是不同的邮件服务器之间(需要SMTP协议发邮件)
六.万维网www
万维网是运行在因特网上的应用,而不是某种计算机网络。
万维网利用网页之间的超链接,将不同网站的网页链接成一张逻辑上的信息网。
为了访问在世界范围的文档,万维网使用统一资源定位符URL,来指明因特网上任何种类资源的位置。
格式如下:

如某网址首页(域名)www.hnust.cn对应的统一资源定位符为:http://www.hnust.cn:80/index.htm
点击网页上某个功能,跳转到下一个网页,此时网页的域名为www.hnust.cn/ggtz/11945.htm
对应的URL为:http://www.hnust.cn:80/ggtz/11945.htm
观察URL的变化可以看到,协议、主机、端口与网站首页相同,但是路径(/ggtz/)不同,网页文件也不同(index.htm和11945.htm)
万维网的文档
将网页保存成文件夹,里面有:HTML文件、JavaScript文件、CSS文件、一些jpg和png图片。
万维网服务器将这些东西发给浏览器进程,浏览器的内核会对其进行渲染,变成我们看到的网页。
HTML即超文本标记语言,使用多种标签来描述网页的结构和内容;CSS是层叠样式表,描述网页的样式(比如字体颜色大小,高亮…)HTML使用link标签将CSS文档引入(跟调用函数一样),JavaScript是描述网页的行为,比如点击按钮,在HTML文档中就是用button关键字,然后指定事件处理函数(这个函数由JavaScript编写),那么到时候网页按下按钮就会调用该函数。
那这些文档是怎样从万维网服务器中发送给浏览器的,浏览器又是怎样向万维网请求的?
就是用的HTTP,即超文本传输协议。
6.1 HTTP(HyperText Transfer Protocol)
HTTP定义了浏览器(即万维网客户进程),怎样向万维网服务器请求万维网文档,以及万维网服务器怎样把万维网文档传送给浏览器
HTTP/1.0,采用非持续连接方式,在该方式下,每次浏览器要请求一个文件都要与服务器建立TCP连接,当收到响应后就要立即关闭连接。
如下图:
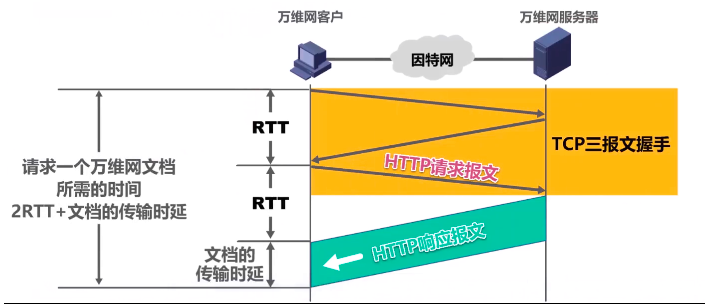
在第三次握手的报文中的数据载荷部分,携带有HTTP请求报文。服务器收到后就给客户发送HTTP响应报文。报文里的数据就是上面说的万维网文档。
HTTP/1.0的缺点:

这里的引用对象是说,比如在网站的首页点击按钮A,那么A背后的资源就得去请求,然后发送,这样又需要2RTT时间,点击按钮B,就需要请求B背后的资源。
http1.1也是这样,但是不需要再搞三次握手了。
HTTP/1.1采用持续连接方式(长连接)。在该方式下 ,万维网服务器在发送响应后,仍然保持这条连接,使同一个客户和该服务器可以继续在这条连接上传送后续的HTTP请求报文和响应报文,这并不局限于传送同一个页面上引用的对象,而是只要这些文档都在同一个服务器上就行。
因为是持续连接的,所以http/1.1还可以像流水线一样连续发送请求报文:

不是说HTTP/1.1就都是持续连接,是默认持续。如果请求报文首部行的Connection字段值为close就是告诉服务器发送完请求的文档后可以立即释放连接,若持续连接则其字段值应该为keep-alive
比如下题:

6.1.1 HTTP请求报文格式
HTTP是面向文本的,报文的每个字段都是一些ASCII码,并且每个字段的长度都是不确定的。
需要进行字符串解析。下面的示例中的http报文没有实体主体,实体主体通常不用。
回车换行是\r\n
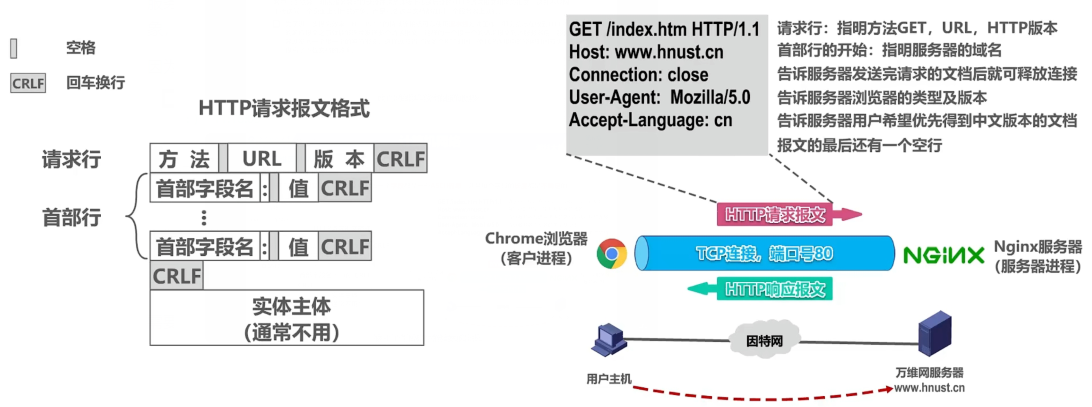
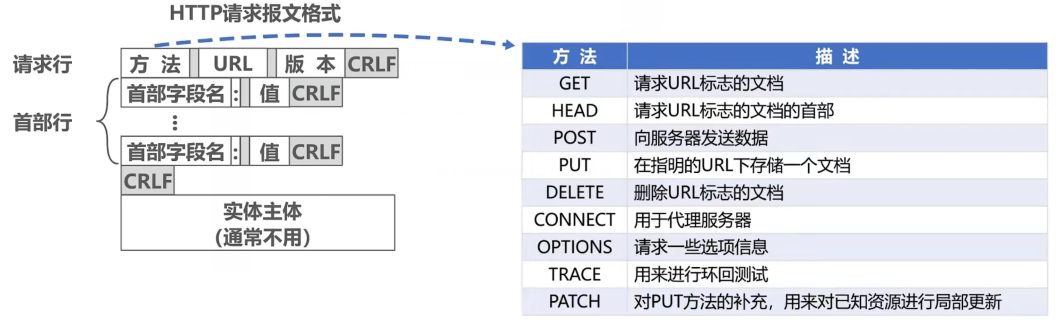
HTTP请求行的方法字段,常见的有以下:
灰色间隔是空格,CRLF是包括 回车符,换行符
GET方法的URL里,利用一个?符号表示URL的结尾与请求参数的开始: /index.jsp?id=100&op=bind
6.1.2 HTTP响应报文格式
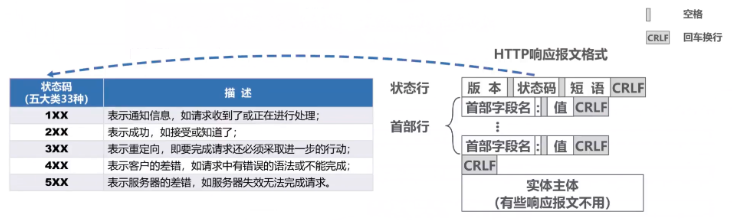
状态行包括:版本、状态码、短语。
版本就是http1.0,http1.1这种,状态码就是404这种,短语就是Not Found
前面说的万维网的那些文档就是在HTTP响应报文的实体主体里
6.2 Cookie技术
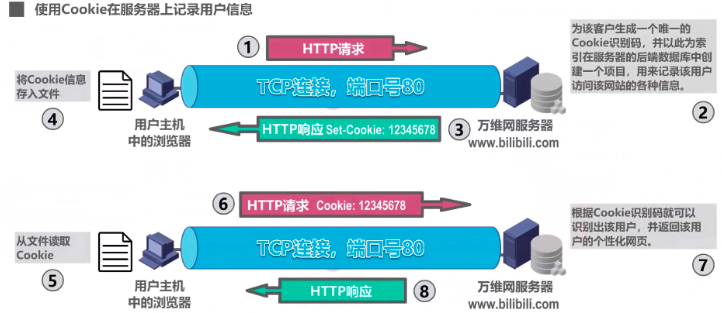
在我们访问网站时,浏览器通常会使用Cookie在服务器上记录用户信息。比如登录某网站,需要用户名和密码,可以点击 “记住我”,这样下一次不需要再输入用户名和密码了。
工作原理
用户主机中的浏览器进程,首先与万维网服务器中的服务器进程建立TCP连接,当用户的浏览器进程初次向服务器进程发送HTTP请求报文时,服务器进程就会为其产生一个唯一的Cookie识别码,并以此为索引,在服务器的后端数据库中创建一个项目,用来记录该用户访问该网站的各种信息;
接着就会给浏览器进程发回HTTP响应报文,在响应报文中包含有一个首部字段为 SET Cookie的首部行,该字段的取值就是Cookie识别码;
当浏览器进程收到该响应报文之后,就在一个特定的Cookie文件中添加一行,记录该服务器的域名和Cookie的识别码;
当用户再次使用浏览器访问这个网站时,每发送一个HTTP请求报文,浏览器都会从Cookie文件中取出该网站的Cookie识别码,并放到HTTP请求报文的Cookie首部行中,服务器根据Cookie识别码就可以识别出该用户并返回该用户的个性化网页——比如B站登录个人账户后,在里面的内容就是该用户特定的。
记住账号密码就是用的cookie技术。
6.3 web缓存
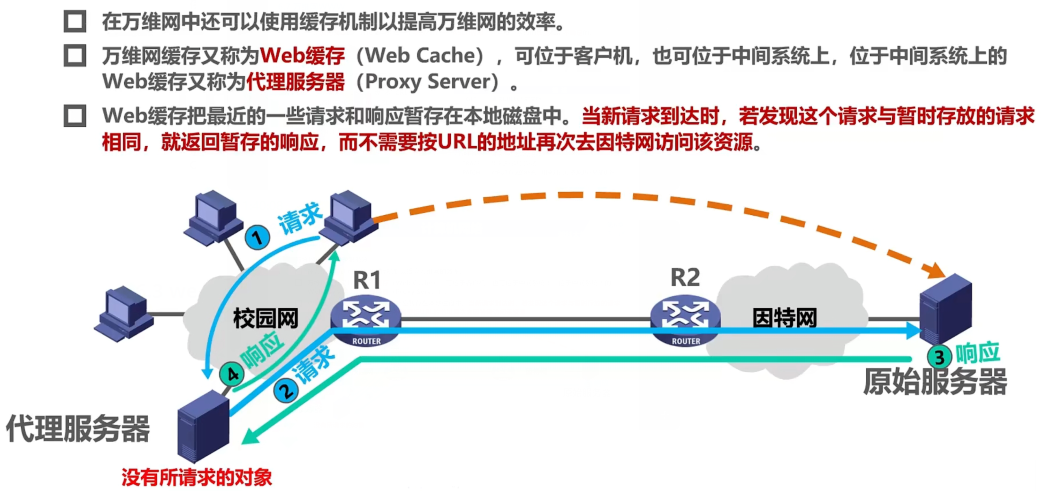
请求资源时,先看本地Web缓存或者代理服务器有没有,没有的话代理服务器就会去原始服务器请求,响应先发给代理服务器,它会缓存下来,再发给用户
如果web缓存的命中率比较高,则路由器R1和R2之间的链路上的通信量将大大减少,从而减少访问因特网的时延。
这里区别GET方法自动产生的响应报文缓存,后者是存储在客户端主机里。
问题:如果代理服务器上有某个文档,该文档实际在原始服务器中已被修改怎么办?
这样会造成用户请求得到的是未更新的文档。
其实原始服务器通常会为每个响应的对象设定一个修改时间字段和一个有效日期字段,没过期就能用,过期了的话,代理服务器会向因特网上的原始服务器发送请求,询问服务器是否修改过这个文档。
代理服务器发送的请求报文中包含有一个首部字段为if-modified -since的首部行,该字段的取值就是该文档的修改日期,原始服务器根据该文档的修改日期,就可判断出代理服务器中存储的该文档是否与自己存储的该文档一致,如果一致则给代理服务器发送,不包含实体主体的响应,状态码为304,短语为not modified代理服务器重新更新该文档的有效日期,然后将该文档封装在响应报文中发回给主机,如果不一致,则给代理服务器发送封装,有该文档的响应报文。