一、先安装KAFKA的环境
概念:
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
Kafka 的配置中会包含一些专有名词,在服务器的配置中我们会遇到这些名词,先来了解一下:
Broker:Kafka集群包含一个或多个服务器,这种服务器被称为broker;
Topic:每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic,在物理上不同的 Topic 消息是分开存储的,逻辑上一个 Topic 的消息虽然保存于一个或多个 broker 上但用户只需指定消息的 Topic 即可生产或消费数据而不必关心数据存在什么地方;
Partition:Partition是物理上的概念,其实就是和我们在 Hive 中见过的分区一样,每个 Topic 包含一个或多个Partition;
Producer:负责发布消息到 Kafka broker 的服务,我们也叫做生产者;
Consumer:消息消费者服务,从 Kafka broker 读取数据的客户端。
现在我们开始搭建 Kafka 服务器
先准备JAVA环境和kafka的安装包:

kafka我使用的是 kafka_2.12-3.2.0.tgz 版本,另外kafka需要有zookeeper集群环境,但是kafka有自带一个zookeeper服务,这里就没有另外安装了。
1. 解压kafka,并且切换到kafka目录
tar -zxvf kafka_2.12-3.2.0.tgz
cd kafka_2.12-3.2.0/2. 启动zookeeper服务,这里是后台启动,并且将服务器打印的日志重定向写入了 zookeeper.log 文件中
./bin/zookeeper-server-start.sh config/zookeeper.properties >> zookeeper.log &3. 修改kafka配置文件
vim config/server.properties修改文件的服务地址为本地ip
![]()
并且在分区设置开关后面加上对topic的创建和删除设置,在项目组的生产环境中,这里是false的设置

4. 在后台启动kafka服务
./bin/kafka-server-start.sh ./config/server.properties &5. 可以通过ps命令检查kafka的服务是否启动
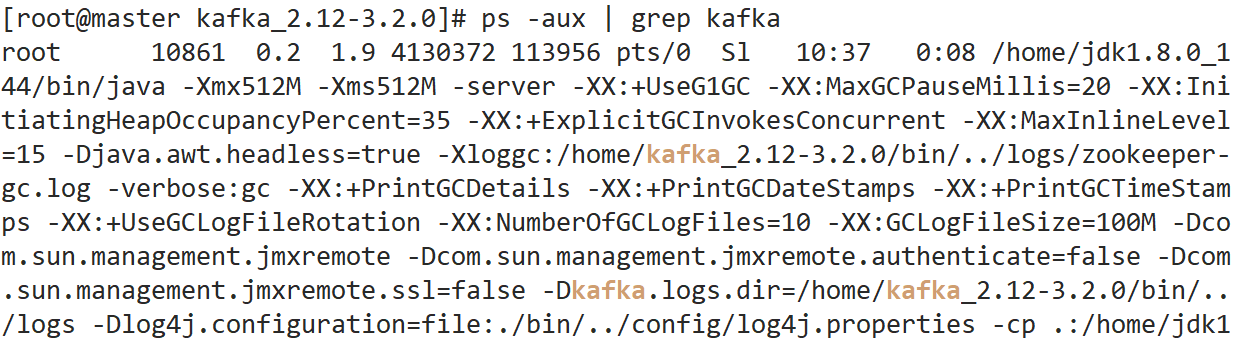
6. 创建kafka的topic,创建一个名为lucifer-topic的topic,只有一个副本,一个分区
sh bin/kafka-topics.sh --create --topic lucifer-topic --replication-factor 1 --partitions 1 --bootstrap-server 192.168.222.132:90927. 可以通过 sh bin/kafka-topics.sh --bootstrap-server 192.168.222.132:9092 --describe --topic lucifer-topic 命令检查 topic 是否创建成功
sh bin/kafka-topics.sh --bootstrap-server 192.168.222.132:9092 --describe --topic lucifer-topic
8. 然后我们分别在两个不同的新窗口中,去测试kafka的服务和通讯是否正常
先启动一个生产者窗口:
sh bin/kafka-console-producer.sh --broker-list 192.168.222.132:9092 --topic lucifer-topic然后再启动一个消费者窗口:
sh bin/kafka-console-consumer.sh --bootstrap-server 192.168.222.132:9092 --topic lucifer-topic --from-beginning9. 在生产者窗口中输入的信息,会显示在消费者窗口中
生产者窗口展示:

消费者窗口展示:

10. 删除 kafka 的消费数据
kafka的消费数据日志默认在 /tmp/kafka-logs 文件夹中,我们只需要删除这个文件夹里面的所有数据就可以了。
![]()
二、安装Logstash的环境
概念:
Logstash 是一个功能强大的工具,可与各种平台和工具进行集成, 它提供了大量插件帮助你解析数据,可以通过 Filter 数据进行解析和转换等,并且能够动态地采集、转换和传输数据,不受格式或复杂度的影响,能够以连续的流式传输方式,轻松地从日志、指标、Web 应用、数据存储以及各种服务采集数据。最后,它可以把自己的数据输出到各种需要的数据储存地,例如file、kafka、ElasticSearch等等

1. 上传logstash的压缩包,并且进行解压操作,这里使用的是logstash-7.9.2.tar.gz版本的文件
tar -zxf logstash-7.9.2.tar.gz2. 进入到 logstash 文件夹,通过logstash工具进行调试和验证
./logstash-7.9.2/bin/logstash -e ""等待logstash启动之后,可以输入数据查看返回内容

要退出当前模式的话,用 ctrl + c 就可以了。
3. 或者编辑一个 conf 文件,例如 test.conf,在文件中写入下面的内容
input { stdin { } }
output { stdout { codec => rubydebug } }
然后通过带 -f 选项的命令来运行:
./logstash-7.9.2/bin/logstash -f test.conf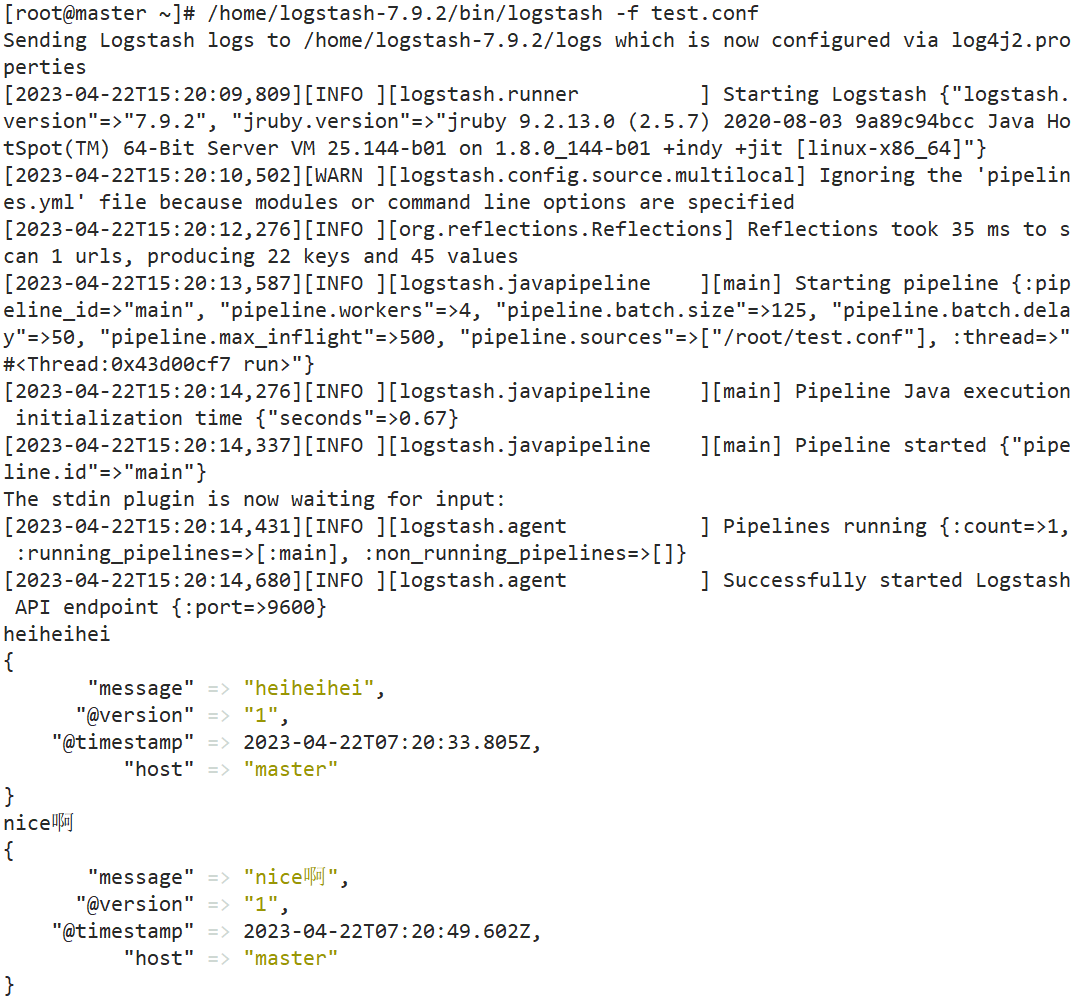
4. 接着尝试使用logstash生产数据,然后用kafka来消费数据
准备一个文件,/usr/u.txt
1001,aa
1002,bb
1003,cc
编辑一个文件,例如 test.conf:

5. 然后使用logstash的命令来运行这个 test.conf 文件
运行结束后,可以同时在当前命令行窗口和kafka消费者窗口看到输出的数据。
./logstash-7.9.2/bin/logstash -f test.conf
这个时候,如果往文件中添加新的数据:
![]()
那么kafka会实时的获取到更新的数据部分:
![]()
这里我们要知道,logstash 分为三个部分:输入、过滤和输出,我们在上面写的,是读取数据

input的一些主要数据来源包括:
- jdbc:关系型数据库:mysql、oracle等
- file:从文件系统上的文件读取
- syslog:在已知端口514上侦听syslog消息
- redis:redis消息
- beats:处理 Beats发送的事件
- kafka:kafka实时数据流
filter过滤器是Logstash管道中的中间处理设备,我们理解成它就是数据处理的ETL环节就好了,一些有用的过滤包括:
- grok:解析并构造任意文本,Grok是目前Logstash中将非结构化日志数据解析为结构化和可查询内容的最佳方式
- mutate:对事件字段执行常规转换。您能够重命名,删除,替换和修改事件中的字段
- drop:彻底删除事件,例如调试事件
- clone:制做事件的副本,可能添加或删除字段
- geoip:添加有关IP地址的地理位置的信息
output输出是Logstash管道的最后阶段,经常使用的输出包括:
- elasticsearch:将事件数据发送到Elasticsearch数据库
- file:将事件数据写入磁盘上的文件
- kafka:将事件写入Kafka
三、使用Logstash获取数据库表格同步到kafka消费
1. 现在mysql数据库上创建库、表格,准备几行数据
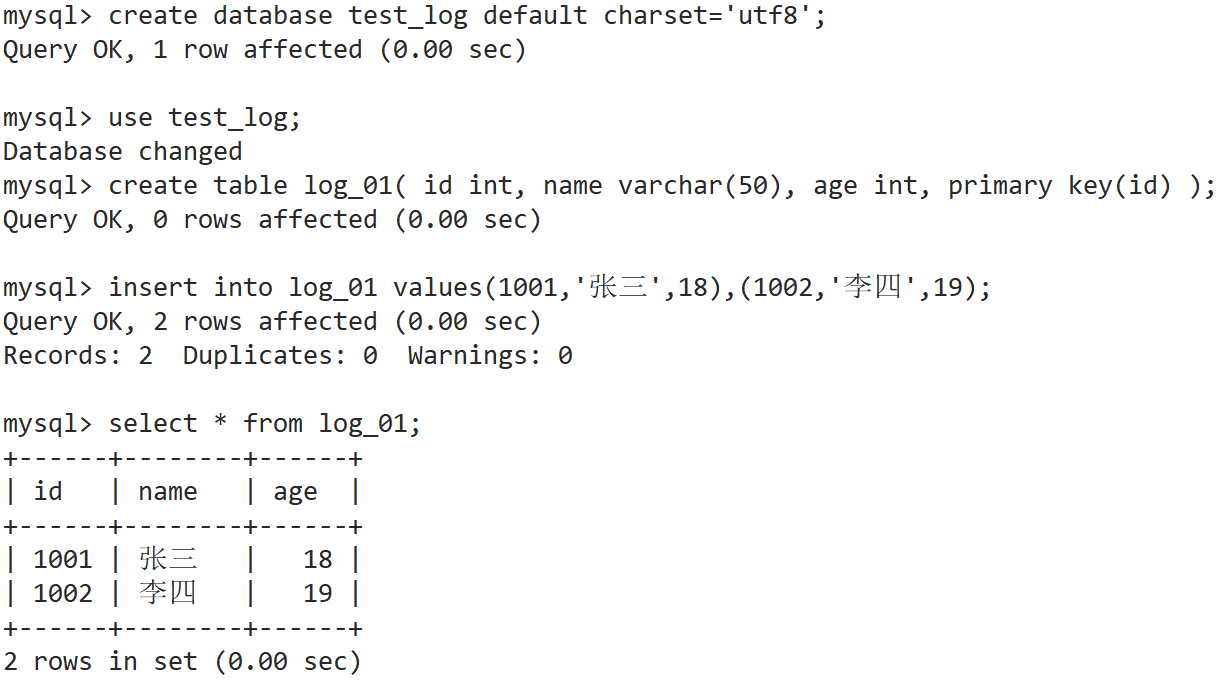
2. 将 mysql 的驱动 jar 包复制到 logstash 的 lib 文件夹中
cp /home/mysql-connector-java-5.1.42.jar /home/logstash-7.9.2/lib/3. 编辑一个 mysql.conf 文件,尝试读取数据库表格内容用于 kafka 的消费
input {
stdin{ }
jdbc {
jdbc_connection_string => "jdbc:mysql://192.168.222.132:3306/test_log?characterEncoding=UTF-8&autoReconnect=true"
jdbc_user => "root"
jdbc_password => "123456"
jdbc_driver_library => "/home/mysql-connector-java-5.1.42.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
statement => "select id,name,age from log_01"
# schedule => "* * * * *"
}
}
filter{
mutate{
remove_field => ["@version"]
remove_field => ["@timestamp"]
}
}
output {
kafka {
bootstrap_servers => "192.168.222.132:9092"
topic_id => "lucifer-topic"
codec => json_lines
}
stdout{ }
}这里我同时添加了 kafka 和 stdout 两种输出方式,是为了让自己获取数据的时候对比查看的,只用到 kafka() 也是可以的。
如果想要定时抽取的话,我们还可以在 jdbc{} 里面添加上 schedule => "* * * * *" 来设置定时获取的任务,操作方式和 crontab 是一样的。
四、使用python对kafka的数据进行消费
现在我们再通过 python,实现对 kafka 数据的消费,同时将获取的数据写入到 hdfs,用于hive数据库的存储和展示。
1. 先在hive数据库中创建表格

2. 使用 Python 消费 kafka 数据,并且格式化之后写入到 hdfs 中,现在 kafka 获取的源数据库数据是以 json 来显示行的,所以我们需要的是对 json 进行解析,然后转换成 dataframe 写入 csv 文件。
这里需要用到的 python 库有 pykafka 和 pyhdfs:
#coding=utf-8
from pykafka import KafkaClient
from pyhdfs import HdfsClient
import json
from pandas import DataFrame
import time
# 先连接kafka
client = KafkaClient(hosts="192.168.222.132:9092")
topic=client.topics['lucifer-topic']
# 创建kafka消费者窗口
consumer = topic.get_simple_consumer(consumer_timeout_ms=5*1000)
# 创建列表准备存储表格数据
datas=[]
# 一行行读取kafka的数据
for record in consumer:
# 设置读取的数据为utf8格式
a=record.value.decode('utf8')
# 将json数据转换成字典
row=json.loads(a)
print(row)
# 将行信息添加到列表中
datas.append(row)
# 转换数据成 dataframe 格式,并且写入 csv 文件
df=DataFrame(datas)
# 指标表格字段的顺序
df=df[['id','name','age']]
print(df)
df.to_csv("E:/log01.csv",header=False,index=False)
# 连接 hdfs
client=HdfsClient(hosts='192.168.222.132:50070',user_name='root')
# 将csv文件写入到表格对应的文件夹路径中,判断当前文件是否存在,存在则覆盖
try:
client.delete("/user/hive/warehouse/bigdata.db/my_log_01/log01.csv")
finally:
client.copy_from_local("E:/log01.csv",'/user/hive/warehouse/bigdata.db/my_log_01/log01.csv')3. 查看 hive 数据库,发现数据已经写入到表格中了
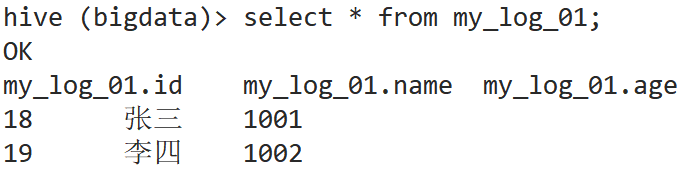
4. 现在为止,我们实现的是全量抽取数据的操作,也就是每次都是完整的读取 mysql 表格中的数据,如果想要进行数据的增量抽取,就需要在每次读取表格的时候对字段内容进行记录,目前能够记录的数据是数字类型的numeric和时间类型的timestamp两种。
我们可以根据关系型数据库的主键字段或者时间字段进行新数据的判断,在logstash的配置文件中添加

在sql语句中也要加上id值的范围判断。
运行完logstash语句之后,会看到log01文件中有最后值的记录:
![]()
5. 再次运行 logstash 的命令来读取 mysql 的 log_01 表格,就只会看到新增的数据了


五、实现logstash+kafka+python的分钟级实时数据抽取
在logstash的文件中启动定时任务关键字,使用 schedule 设置定时规则
input {
stdin{ }
jdbc {
jdbc_connection_string => "jdbc:mysql://192.168.222.132:3306/test_log?characterEncoding=UTF-8&autoReconnect=true"
jdbc_user => "root"
jdbc_password => "123456"
jdbc_driver_library => "/home/mysql-connector-java-5.1.42.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
schedule => "* * * * *"
statement => "select id,name,age from log_01 where id > :sql_last_value"
use_column_value => true
tracking_column => "id"
tracking_column_type => "numeric"
record_last_run => true
last_run_metadata_path => "/home/logstash-7.9.2/sync_data/log01"
}
}
filter{
mutate{
remove_field => ["@version"]
remove_field => ["@timestamp"]
}
}
output {
kafka {
bootstrap_servers => "192.168.222.132:9092"
topic_id => "lucifer-topic"
codec => json_lines
}
stdout{ }
}修改python消费kafka的代码如下:通过while+sleep的方式对时间周期的数据进行等待和抽取
#coding=utf-8
from pykafka import KafkaClient
from pyhdfs import HdfsClient
import json
from pandas import DataFrame
import time
import datetime
# 先连接kafka
client = KafkaClient(hosts="192.168.222.132:9092")
topic=client.topics['lucifer-topic']
# 创建kafka消费者窗口
consumer = topic.get_simple_consumer(consumer_timeout_ms=5*1000)
# 为了避免同时写入数据文件,先造一个自增数字
f = 0
# 使用while循环每隔60秒取数一次
while True:
# 一行行读取kafka的数据
for record in consumer:
# 修改成每次循环都生成一个新的列表,创建列表准备存储表格数据
datas = []
# 设置读取的数据为utf8格式
a=record.value.decode('utf8')
# 将json数据转换成字典
row=json.loads(a)
# 将行信息添加到列表中
datas.append(row)
# 转换数据成 dataframe 格式,并且写入 csv 文件
df=DataFrame(datas)
# 指标表格字段的顺序
df=df[['id','name','age']]
print(df)
# 通过时间给文件名字进行命名
n=datetime.datetime.now().strftime("%Y%m%d%H%M%S")
filename="log{}.csv".format(n)
df.to_csv("E:/"+filename,header=False,index=False)
# 连接 hdfs
client=HdfsClient(hosts='192.168.222.132:50070',user_name='root')
# 每次拿到当前数据,都直接往hdfs中进行当前时间命令的数据文件的写入
try:
client.copy_from_local("E:/"+filename,'/user/hive/warehouse/bigdata.db/my_log_01/'+filename)
except Exception as e:
filename=filename+'_'+str(f)
f+=1
df.to_csv("E:/" + filename, header=False, index=False)
client.copy_from_local("E:/"+filename, '/user/hive/warehouse/bigdata.db/my_log_01/'+filename)
# 等待60秒
time.sleep(60)可以看到启动定时之后,logstash的抽取变为了每分钟一次:

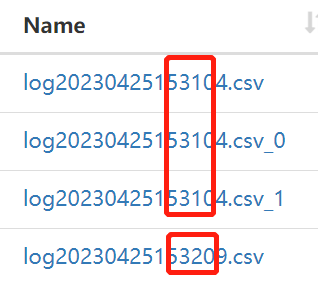
通过python往hdfs中导入的数据文件命令也可以看出,python实现了每分钟级别的数据导入:
六、Logstash的优化
调优和分析Logstash性能,是通过Logstash配置文件来设置的。配置文件的位置在
logstash-7.9.2/config 文件夹中,名字是 logstash.yml
Logstash提供了以下选项来优化管道性能,pipeline.workers,pipeline.batch.size 和pipeline.batch.delay。

pipeline.workers
此设置确定要运行多少个线程以进行过滤和输出处理。如果发现事件正在备份或者CPU没有饱和可以考虑增加此参数以更好的利用可用的处理能力。
pipeline.batch.size
此设置定义单个工作线程在尝试执行过滤器和输出之前收集的最大事件数。这个值通常来说越大越有效,但会增加很多的内存开销,因此容易导致JVM进程崩溃。
pipeline.batch.delay
很少需要调整。此设置调整Logstash管道的延迟。管道批处理延迟是Logstash在当前管道工作线程中接收到事件后等待新消息的最长时间(以毫秒为单位)。经过这段时间后,Logstash开始执行过滤器和输出。我们可以理解为这是程序设置的等待时间。